
Há algum tempo, realizamos monitoramento e alarmes sem agente. Este é um análogo do CloudWatch na AWS com uma API compatível. Agora estamos trabalhando em balanceadores e dimensionamento automático. Mas, embora não forneçamos esse serviço - oferecemos aos nossos clientes que eles mesmos o fazem, usando nosso monitoramento e tags (API da AWS Resource Tagging) como uma simples descoberta de serviço como fonte de dados. Vamos mostrar como fazer isso neste post.
Um exemplo de uma infraestrutura mínima de um serviço da web simples: DNS -> 2 balanceadores -> 2 back-end. Essa infraestrutura pode ser considerada o mínimo necessário para operação e manutenção tolerantes a falhas. Por esse motivo, não compactaremos ainda mais essa infraestrutura, deixando, por exemplo, apenas um back-end. Mas eu gostaria de aumentar o número de servidores back-end e reduzir novamente para dois. Esta será a nossa tarefa. Todos os exemplos estão disponíveis no repositório .
Infraestrutura básica
Não vamos nos deter em detalhes sobre a configuração da infraestrutura acima, apenas mostraremos como criá-la. Preferimos implantar infraestrutura usando o Terraform. Ajuda a criar rapidamente tudo o que você precisa (VPC, Sub-rede, Grupo de Segurança, VMs) e repita esse procedimento repetidamente.
Script para aumentar a infraestrutura básica:
main.tfvariable "ec2_url" {} variable "access_key" {} variable "secret_key" {} variable "region" {} variable "vpc_cidr_block" {} variable "instance_type" {} variable "big_instance_type" {} variable "az" {} variable "ami" {} variable "client_ip" {} variable "material" {} provider "aws" { endpoints { ec2 = "${var.ec2_url}" } skip_credentials_validation = true skip_requesting_account_id = true skip_region_validation = true access_key = "${var.access_key}" secret_key = "${var.secret_key}" region = "${var.region}" } resource "aws_vpc" "vpc" { cidr_block = "${var.vpc_cidr_block}" } resource "aws_subnet" "subnet" { availability_zone = "${var.az}" vpc_id = "${aws_vpc.vpc.id}" cidr_block = "${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}" } resource "aws_security_group" "sg" { name = "auto-scaling" vpc_id = "${aws_vpc.vpc.id}" ingress { from_port = 22 to_port = 22 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } ingress { from_port = 8080 to_port = 8080 protocol = "tcp" cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } } resource "aws_key_pair" "key" { key_name = "auto-scaling-new" public_key = "${var.material}" } resource "aws_instance" "compute" { count = 5 ami = "${var.ami}" instance_type = "${count.index == 0 ? var.big_instance_type : var.instance_type}" key_name = "${aws_key_pair.key.key_name}" subnet_id = "${aws_subnet.subnet.id}" availability_zone = "${var.az}" security_groups = ["${aws_security_group.sg.id}"] } resource "aws_eip" "pub_ip" { instance = "${aws_instance.compute.0.id}" vpc = true } output "awx" { value = "${aws_eip.pub_ip.public_ip}" } output "haproxy_id" { value = ["${slice(aws_instance.compute.*.id, 1, 3)}"] } output "awx_id" { value = "${aws_instance.compute.0.id}" } output "backend_id" { value = ["${slice(aws_instance.compute.*.id, 3, 5)}"] }
Todas as entidades descritas nesta configuração, ao que parece, devem ser entendidas pelo usuário médio das nuvens modernas. Variáveis específicas para nossa nuvem e para uma tarefa específica são movidas para um arquivo separado - terraform.tfvars:
terraform.tfvars ec2_url = "https://api.cloud.croc.ru" access_key = "project:user@customer" secret_key = "secret-key" region = "croc" az = "ru-msk-vol51" instance_type = "m1.2small" big_instance_type = "m1.large" vpc_cidr_block = "10.10.0.0/16" ami = "cmi-3F5B011E"
Lançamento Terraform:
aplicar terraform yes yes | terraform apply -var client_ip="$(curl -s ipinfo.io/ip)/32" -var material="$(cat <ssh_publick_key_path>)"
Configuração de monitoramento
As VMs lançadas acima são monitoradas automaticamente por nossa nuvem. Esses dados de monitoramento serão a fonte de informações para futuros dimensionamentos automáticos. Contando com determinadas métricas, podemos aumentar ou diminuir a potência.
O monitoramento em nossa nuvem permite configurar alarmes de acordo com diferentes condições para diferentes métricas. É muito conveniente Não precisamos analisar as métricas a qualquer momento e tomar uma decisão - isso será feito pelo monitoramento da nuvem. Neste exemplo, usaremos alarmes para métricas da CPU, mas em nosso monitoramento eles também podem ser configurados para métricas como: utilização da rede (velocidade / pps), utilização do disco (velocidade / iops).
cloudwatch put-metric-alarm export CLOUDWATCH_URL=https://monitoring.cloud.croc.ru for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm \ --alarm-name "scaling-low_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average \ --period 60 --evaluation-periods 3 --threshold 15 --comparison-operator LessThanOrEqualToThreshold; done for instance_id in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL \ cloudwatch put-metric-alarm\ --alarm-name "scaling-high_$instance_id" \ --dimensions Name=InstanceId,Value="$instance_id" \ --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average\ --period 60 --evaluation-periods 3 --threshold 80 --comparison-operator GreaterThanOrEqualToThreshold; done
Descrição de alguns parâmetros que podem ser incompreensíveis:
--profile - perfil de configurações do aws-cli, descrito em ~ / .aws / config. Normalmente, diferentes chaves de acesso são definidas em perfis diferentes.
--dimensions - o parâmetro determina para qual recurso o alarme será criado, no exemplo acima - para a instância com o identificador da variável $ instance_id.
--namespace - namespace a partir do qual a métrica de monitoramento será selecionada.
--metric-name - o nome da métrica de monitoramento.
--statistic - o nome do método de agregação de valor da métrica.
--period - intervalo de tempo entre o monitoramento de eventos de coleta de valor.
--avaluation-period - o número de intervalos necessários para acionar um alarme.
--threshold - valor do limiar métrico para avaliar o estado do alarme.
--comparison-operator - um método usado para avaliar o valor de uma métrica em relação a um valor limite.
No exemplo acima, dois alarmes são criados para cada instância de back-end. Escalonar-baixo- <ID da instância> entrará no estado Alarme quando a CPU carregar menos de 15% por 3 minutos. Escalar alto <ID da instância> entrará no estado Alarme quando a CPU carregar mais de 80% por 3 minutos.
Personalização de tags
Após a configuração do monitoramento, somos confrontados com a seguinte tarefa - a descoberta de instâncias e seus nomes (descoberta de serviço). De alguma forma, precisamos entender quantas instâncias de back-end lançamos agora e também precisamos saber seus nomes. Em um mundo fora da nuvem, por exemplo, o cônsul e o modelo do cônsul seriam uma boa opção para gerar uma configuração do balanceador. Mas há tags em nossa nuvem. As tags nos ajudarão a categorizar os recursos. Ao solicitar informações para uma tag específica (descreva-tags), podemos entender quantas instâncias temos atualmente no pool e qual ID elas possuem. Por padrão, um ID de instância exclusivo é usado como nome do host. Graças ao DNS interno que trabalha dentro da VPC, esses nomes de ID / host são resolvidos para as instâncias IP internas.
Definimos tags para instâncias de back-end e balanceadores:
tags de criação ec2 export EC2_URL="https://api.cloud.croc.ru" aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "<awx_instance_id>" \ --tags Key=env,Value=auto-scaling Key=role,Value=awx for i in <backend_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=backend ; done; for i in <haproxy_instance_ids>; do \ aws --profile <aws_cli_profile> --endpoint-url $EC2_URL \ ec2 create-tags --resources "$i" \ --tags Key=env,Value=auto-scaling Key=role,Value=haproxy; done;
Onde:
--resources - uma lista de identificadores de recursos nos quais as tags serão definidas.
--tags é uma lista de pares de valores-chave.
Um exemplo de descrição de tags está disponível na documentação do CROC Cloud.
Configuração de dimensionamento automático
Agora que a nuvem está monitorando e sabemos como trabalhar com tags, só podemos pesquisar o estado dos alarmes configurados para o acionamento. Aqui precisamos de uma entidade que participe do monitoramento periódico de monitoramento e inicie tarefas para criar / excluir instâncias. Várias ferramentas de automação podem ser aplicadas aqui. Vamos usar o AWX. O AWX é uma versão de código aberto da Ansible Tower comercial, um produto para gerenciar centralmente a infraestrutura da Ansible. A principal tarefa é lançar periodicamente nosso manual de instruções.
Um exemplo de implantação do AWX está disponível na página wiki no repositório oficial. A configuração do AWX também é descrita na documentação da Ansible Tower. Para que o AWX comece a executar playbooks personalizados, você deve configurá-lo criando as seguintes entidades:
- Segredos de três tipos:
- Credenciais da AWS - para autorizar operações relacionadas à nuvem CROC.
- Credenciais da máquina - chaves ssh para acessar instâncias recém-criadas.
- Credenciais SCM - para autorização no sistema de controle de versão. - Projeto é uma entidade que enviará o repositório git do manual.
- Scripts - script de inventário dinâmico para ansible.
- Inventário é uma entidade que chamará o script de inventário dinâmico antes de iniciar o manual.
- Modelo - a configuração de uma chamada específica do manual, consiste em um conjunto de credenciais, inventário e manual do Project.
- Fluxo de trabalho - uma sequência de chamadas para playbooks.
O processo de dimensionamento automático pode ser dividido em duas partes:
- scale_up - cria uma instância quando pelo menos um alarme alto é acionado;
- scale_down - finalização de uma instância se um alarme baixo funcionar para isso.
Dentro do escopo da parte scale_up, você precisará de:
- Interrogar o serviço de monitoramento em nuvem sobre a presença de alarmes altos no estado "Alarme";
- pare scale_up antes do previsto se todos os alarmes altos estiverem no estado "OK";
- crie uma nova instância com os atributos necessários (tag, sub-rede, security_group, etc.);
- crie alarmes altos e baixos para uma instância em execução;
- configure nosso aplicativo dentro de uma nova instância (no nosso caso, será apenas nginx com uma página de teste);
- atualize a configuração haproxy, faça um recarregamento para que os pedidos comecem a ir para a nova instância.
create-instance.yaml --- - name: get alarm statuses describe_alarms: region: "croc" alarm_name_prefix: "scaling-high" alarm_state: "alarm" register: describe_alarms_query - name: stop if no alarms fired fail: msg: zero high alarms in alarm state when: describe_alarms_query.meta | length == 0 - name: create instance ec2: region: "croc" wait: yes state: present count: 1 key_name: "{{ hostvars[groups['tag_role_backend'][0]].ec2_key_name }}" instance_type: "{{ hostvars[groups['tag_role_backend'][0]].ec2_instance_type }}" image: "{{ hostvars[groups['tag_role_backend'][0]].ec2_image_id }}" group_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_security_group_ids }}" vpc_subnet_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_subnet_id }}" user_data: | #!/bin/sh sudo yum install epel-release -y sudo yum install nginx -y cat <<EOF > /etc/nginx/conf.d/dummy.conf server { listen 8080; location / { return 200 '{"message": "$HOSTNAME is up"}'; } } EOF sudo systemctl restart nginx loop: "{{ hostvars[groups['tag_role_backend'][0]] }}" register: new - name: create tag entry ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc state: present resource: "{{ item.id }}" tags: role: backend loop: "{{ new.instances }}" - name: create low alarms ec2_metric_alarm: state: present region: croc name: "scaling-low_{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: "<=" threshold: 15 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}" - name: create high alarms ec2_metric_alarm: state: present region: croc name: "scaling-high_{{ item.id }}" metric: "CPUUtilization" namespace: "AWS/EC2" statistic: Average comparison: ">=" threshold: 80.0 period: 300 evaluation_periods: 3 unit: "Percent" dimensions: {'InstanceId':"{{ item.id }}"} loop: "{{ new.instances }}"
No create-instance.yaml, o que acontece é: criar uma instância com os parâmetros corretos, marcar essa instância e criar os alarmes necessários. O script de instalação e configuração do nginx também é passado pelos dados do usuário. Os dados do usuário são processados pelo serviço cloud-init, que permite a configuração flexível da instância durante a inicialização sem recorrer a outras ferramentas de automação.
No update-lb.yaml, o arquivo /etc/haproxy/haproxy.cfg é recriado na instância haproxy e no serviço de recarga haproxy:
update-lb.yaml - name: update haproxy configs template: src: haproxy.cfg.j2 dest: /etc/haproxy/haproxy.cfg - name: add new backend host to haproxy systemd: name: haproxy state: restarted
Onde haproxy.cfg.j2 é o modelo de arquivo de configuração do serviço haproxy:
haproxy.cfg.j2 # {{ ansible_managed }} global log /dev/log local0 log /dev/log local1 notice chroot /var/lib/haproxy stats timeout 30s user haproxy group haproxy daemon defaults log global mode http option httplog option dontlognull timeout connect 5000 timeout client 50000 timeout server 50000 frontend loadbalancing bind *:80 mode http default_backend backendnodes backend backendnodes balance roundrobin option httpchk HEAD / {% for host in groups['tag_role_backend'] %} server {{hostvars[host]['ec2_id']}} {{hostvars[host]['ec2_private_ip_address']}}:8080 check {% endfor %}
Como a opção httpchk está definida na seção de back-end da configuração do haproxy, o serviço haproxy pesquisará independentemente os estados das instâncias de back-end e equilibrará o tráfego apenas entre verificações de integridade anteriores.
Na parte scale_down você precisa:
- verifique o estado de alarme baixo;
- encerre prematuramente a reprodução se não houver alarmes baixos no estado "Alarme";
- encerre todas as instâncias para as quais o alarme baixo esteja na classe Alarme;
- proibir a finalização do último par de instâncias, mesmo que seus alarmes estejam no estado Alarme;
- remova as instâncias que removemos da configuração do balanceador de carga.
destroy-instance.yaml - name: look for alarm status describe_alarms: region: "croc" alarm_name_prefix: "scaling-low" alarm_state: "alarm" register: describe_alarms_query - name: count alarmed instances set_fact: alarmed_count: "{{ describe_alarms_query.meta | length }}" alarmed_ids: "{{ describe_alarms_query.meta }}" - name: stop if no alarms fail: msg: no alarms fired when: alarmed_count | int == 0 - name: count all described instances set_fact: all_count: "{{ groups['tag_role_backend'] | length }}" - name: fail if last two instance remaining fail: msg: cant destroy last two instances when: all_count | int == 2 - name: destroy tags for marked instances ec2_tag: ec2_url: "https://api.cloud.croc.ru" region: croc resource: "{{ alarmed_ids[0].split('_')[1] }}" state: absent tags: role: backend - name: destroy instances ec2: region: croc state: absent instance_ids: "{{ alarmed_ids[0].split('_')[1] }}" - name: destroy low alarms ec2_metric_alarm: state: absent region: croc name: "scaling-low_{{ alarmed_ids[0].split('_')[1] }}" - name: destroy high alarms ec2_metric_alarm: state: absent region: croc name: "scaling-high_{{ alarmed_ids[0].split('_')[1] }}"
Em destroy-instance.yaml, os alarmes são excluídos, a instância e sua tag são encerradas e as condições que proíbem o encerramento de instâncias recentes são verificadas.
Excluímos explicitamente as tags após excluir instâncias devido ao fato de que, após a exclusão de uma instância, as tags associadas a ela são excluídas adiadas e ficam disponíveis por mais um minuto.
AWX
Definindo tarefas, modelos
O seguinte conjunto de tarefas criará as entidades necessárias no AWX:
awx-configure.yaml --- - name: Create tower organization tower_organization: name: "scaling-org" description: "scaling-org organization" state: present - name: Add tower cloud credential tower_credential: name: cloud description: croc cloud api creds organization: scaling-org kind: aws state: present username: "{{ croc_user }}" password: "{{ croc_password }}" - name: Add tower github credential tower_credential: name: ghe organization: scaling-org kind: scm state: present username: "{{ ghe_user }}" password: "{{ ghe_password }}" - name: Add tower ssh credential tower_credential: name: ssh description: ssh creds organization: scaling-org kind: ssh state: present username: "ec2-user" ssh_key_data: "{{ lookup('file', 'private.key') }}" - name: Add tower project tower_project: name: "auto-scaling" scm_type: git scm_credential: ghe scm_url: <repo-name> organization: "scaling-org" scm_branch: master state: present - name: create inventory tower_inventory: name: dynamic-inventory organization: "scaling-org" state: present - name: copy inventory script to awx copy: src: "{{ role_path }}/files/ec2.py" dest: /root/ec2.py - name: create inventory source shell: | export SCRIPT=$(tower-cli inventory_script create -n "ec2-script" --organization "scaling-org" --script @/root/ec2.py | grep ec2 | awk '{print $1}') tower-cli inventory_source create --update-on-launch True --credential cloud --source custom --inventory dynamic-inventory -n "ec2-source" --source-script $SCRIPT --source-vars '{"EC2_URL":"api.cloud.croc.ru","AWS_REGION": "croc"}' --overwrite True - name: Create create-instance template tower_job_template: name: "create-instance" job_type: "run" inventory: "dynamic-inventory" credential: "cloud" project: "auto-scaling" playbook: "create-instance.yaml" state: "present" register: create_instance - name: Create update-lb template tower_job_template: name: "update-lb" job_type: "run" inventory: "dynamic-inventory" credential: "ssh" project: "auto-scaling" playbook: "update-lb.yaml" credential: "ssh" state: "present" register: update_lb - name: Create destroy-instance template tower_job_template: name: "destroy-instance" job_type: "run" inventory: "dynamic-inventory" project: "auto-scaling" credential: "cloud" playbook: "destroy-instance.yaml" credential: "ssh" state: "present" register: destroy_instance - name: create workflow tower_workflow_template: name: auto_scaling organization: scaling-org schema: "{{ lookup('template', 'schema.j2')}}" - name: set scheduling shell: | tower-cli schedule create -n "3min" --workflow "auto_scaling" --rrule "DTSTART:$(date +%Y%m%dT%H%M%SZ) RRULE:FREQ=MINUTELY;INTERVAL=3"
O snippet anterior criará um modelo para cada um dos playbooks ansible usados. Cada modelo configura o lançamento de um manual com um conjunto de credenciais e inventário definidos.
Criar um canal para chamadas para playbooks permitirá o modelo de fluxo de trabalho. A configuração do fluxo de trabalho para dimensionamento automático é apresentada abaixo:
schema.j2 - failure_nodes: - id: 101 job_template: {{ destroy_instance.id }} success_nodes: - id: 102 job_template: {{ update_lb.id }} id: 103 job_template: {{ create_instance.id }} success_nodes: - id: 104 job_template: {{ update_lb.id }}
O modelo anterior mostra o diagrama do fluxo de trabalho, ou seja, sequência de execução do modelo. Neste fluxo de trabalho, cada próxima etapa (success_nodes) será executada apenas se a anterior for concluída com êxito. Uma representação gráfica do fluxo de trabalho é mostrada na figura:
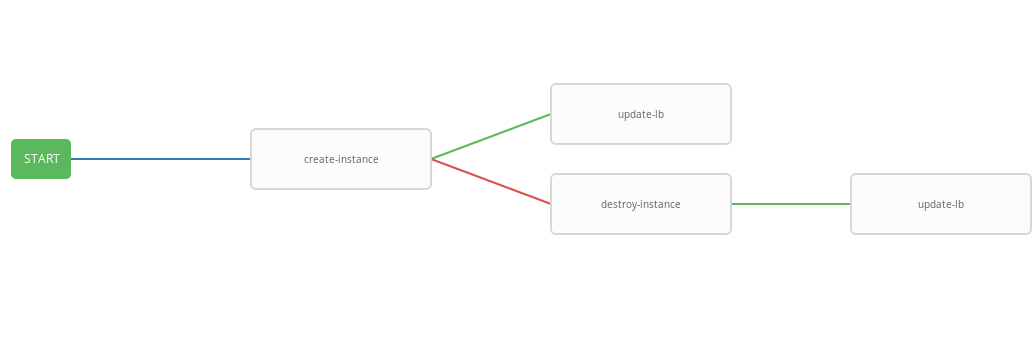
Como resultado, foi criado um fluxo de trabalho generalizado que executa o manual de criação de instâncias e, dependendo do status de execução, os manuais de instância de destruição e / ou atualização-lb. O fluxo de trabalho integrado é conveniente para executar em um determinado agendamento. O processo de dimensionamento automático será iniciado a cada três minutos, iniciando e encerrando instâncias, dependendo do estado do alarme.
Teste de trabalho
Agora verifique a operação do sistema configurado. Primeiro, instale o utilitário wrk para comparações http.
instalação do wrk ssh -A ec2-user@<aws_instance_ip> sudo su - cd /opt yum groupinstall 'Development Tools' yum install -y openssl-devel git git clone https://github.com/wg/wrk.git wrk cd wrk make install wrk /usr/local/bin exit
Usaremos o monitoramento em nuvem para monitorar o uso dos recursos da instância durante o carregamento:
monitoramento function CPUUtilizationMonitoring() { local AWS_CLI_PROFILE="<aws_cli_profile>" local CLOUDWATCH_URL="https://monitoring.cloud.croc.ru" local API_URL="https://api.cloud.croc.ru" local STATS="" local ALARM_STATUS="" local IDS=$(aws --profile $AWS_CLI_PROFILE --endpoint-url $API_URL ec2 describe-instances --filter Name=tag:role,Values=backend | grep -i instanceid | grep -oE 'i-[a-zA-Z0-9]*' | tr '\n' ' ') for instance_id in $IDS; do STATS="$STATS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch get-metric-statistics --dimensions Name=InstanceId,Value=$instance_id --namespace "AWS/EC2" --metric CPUUtilization --end-time $(date --iso-8601=minutes) --start-time $(date -d "$(date --iso-8601=minutes) - 1 min" --iso-8601=minutes) --period 60 --statistics Average | grep -i average)"; ALARMS_STATUS="$ALARMS_STATUS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch describe-alarms --alarm-names scaling-high-$instance_id | grep -i statevalue)" done echo $STATS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t echo $ALARMS_STATUS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t } export -f CPUUtilizationMonitoring watch -n 60 bash -c CPUUtilizationMonitoring
O script anterior, uma vez a cada 60 segundos, obtém informações sobre o valor médio da métrica CPUUtilization do último minuto e consulta o status dos alarmes para instâncias de back-end.
Agora você pode executar o wrk e verificar a utilização dos recursos das instâncias de back-end sob carga:
wrk run ssh -A ec2-user@<awx_instance_ip> wrk -t12 -c100 -d500s http://<haproxy_instance_id> exit
O último comando iniciará o benchmark por 500 segundos, usando 12 threads e abrindo 100 conexões http.
Com o tempo, o script de monitoramento deve mostrar que, durante o benchmark, o valor estatístico da métrica CPUUtilization aumenta até atingir 300%. 180 segundos após o início do benchmark, o sinalizador StateValue deve mudar para o estado de alarme. A cada dois minutos, o fluxo de trabalho de dimensionamento automático é iniciado. Por padrão, a execução paralela do mesmo fluxo de trabalho é proibida. Ou seja, a cada dois minutos, uma tarefa para executar um fluxo de trabalho será adicionada à fila e será iniciada somente após a conclusão do anterior. Portanto, durante o trabalho do wrk, haverá um aumento constante nos recursos até que os altos alarmes de todas as instâncias de back-end entrem no estado OK. Após a conclusão, o fluxo de trabalho wrk scale_down finaliza todas as instâncias, exceto duas.
Exemplo de saída de um script de monitoramento:
resultados de monitoramento # start test i-43477460 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # start http load i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 111.0 i-43477460 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok" # alarm state i-43477460 |i-AC5D9EE0 "Average": 267.0 | "Average": 282.0 i-43477460 |i-AC5D9EE0 "StateValue": "alarm"| "StateValue": "alarm" # two new instances created i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "Average": 185.0 | "Average": 215.0 | "Average": 245.0 | i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0 "StateValue": "insufficient_data"| "StateValue": "insufficient_data"| "StateValue": "alarm"| "StateValue": "alarm" # only two instances left after load has been stopped i-935BAB40 |i-AC5D9EE0 "Average": 0.0 | "Average": 0.0 i-935BAB40 |i-AC5D9EE0 "StateValue": "ok"| "StateValue": "ok"
Também na CROC Cloud, é possível visualizar os gráficos usados na postagem de monitoramento na página da instância na guia correspondente.
Exibir alarmes está disponível na página de monitoramento na guia Alarmes.
Conclusão
O dimensionamento automático é um cenário bastante popular, mas, infelizmente, ainda não está em nossa nuvem (mas apenas por enquanto). No entanto, temos muitas APIs poderosas para fazer coisas semelhantes e muitas outras coisas, usando ferramentas populares, quase padrão, como Terraform, ansible, aws-cli e outras.