Amigos, boa tarde!
Continuamos a série de publicações “sem cortes” sobre projetos relacionados ao desenvolvimento, geralmente com o prefixo “web”. Vamos falar hoje sobre o teste de estresse. O problema é que muitas vezes nem o cliente nem o gerente de projeto entendem por que é necessário, quais riscos podem reduzir, como organizá-lo e como, e isso, acho que é difícil, interpretar seus resultados para o benefício dos negócios. Servimos café e vamos embora ...
Por que carregar o teste de um projeto da web?
O fato é que, enquanto alguns auto-testes ainda estão sendo escritos em alguns projetos da Web para manter a qualidade, poucas pessoas estão envolvidas no controle de desempenho no estágio de desenvolvimento. É muito raro ver um projeto da web com autotestes e benchmarks de código. Com mais frequência e por razões razoáveis, as seguintes heurísticas são respeitadas durante o desenvolvimento, com uma boa relação custo-benefício:
- consultas ao MySQL (usaremos esse banco de dados popular como exemplo) passam por uma API bastante adequada que usa índices (embora não vejamos exatamente como os índices são usados pelo agendador, qual é a cardinalidade deles)
- os resultados da execução de consultas ao banco de dados e trechos pesados de código são armazenados em cache
- o desenvolvedor verificou 3,14 vezes a construção da página da web no navegador e, se não desacelerar, tudo está bem
As heurísticas geralmente funcionam bem, mas quanto maior e mais pesado o projeto, algo
pode dar errado com uma probabilidade exponencialmente crescente.
Tome cache. Ao desenvolver, geralmente não há tempo para pensar em quantas vezes o cache pode ser reconstruído. Mas em vão. Se a reconstrução de um cache, por exemplo, um catálogo de produtos, demorar muito e o cache for redefinido quando um produto for adicionado, o armazenamento em cache causará mais danos do que benefícios.
É por isso que, a propósito, não é recomendável usar o cache de consulta MySQL embutido, que sofre de um problema semelhante: se você alterar pelo menos um registro de tabela, o cache da tabela é completamente redefinido (imagine uma tabela de 100 mil linhas e o absurdo da situação se torna óbvio).
Uma situação semelhante com as consultas do MySQL. Se as consultas forem executadas por índices, em geral, as consultas serão executadas ... "mais rapidamente". Você pode acreditar que o tempo de execução dessas consultas depende logaritmicamente da quantidade de dados (O (log (n))). Mas, na prática, muitas vezes acontece que algumas consultas afetam outras, usando ao mesmo tempo os subsistemas gerais do banco de dados (classificação em um disco que começa a ficar lento) e você não pode prever isso imediatamente.
Além disso, geralmente durante o carregamento, recursos interessantes do sistema operacional são revelados, em particular, o estouro do intervalo de portas de cliente TCP / IP de saída durante um trabalho intensivo com o memcached. Ou o apache fica entupido com solicitações de processamento de imagem, porque durante a configuração, eles esqueceram de configurar seu processamento pelo servidor proxy de cache nginx.
Às vezes, eles esquecem de instalar no MySQL o caminho para tabelas temporárias em um disco que mapeia dados para a RAM ("/ dev / shm"), pelo que, quando a carga aumenta, o servidor de banco de dados estabelece a partir de classificações intensivas.
Além disso, quando os dados são adicionados ao projeto da web, em um volume próximo ao de combate, as consultas e os algoritmos começam a exibir agressivamente sua “notação O”: se o cartesiano estiver invisível para uma pequena quantidade de dados, quando o volume de combate aparecer, o servidor do banco de dados ficará vermelho devido à tensão.
Existem muitos outros exemplos, vamos nos concentrar nisso por enquanto. O principal a entender é que o teste de carga é necessário. Como é muito caro, muito longo e economicamente impraticável prever todas as opções possíveis para "frear" um sistema da Web de tamanho médio com antecedência.
Como identificar metas de teste de estresse?
Aqui é importante entender o que realmente mostra a você e ao cliente o nível de qualidade do sistema da web durante o teste de estresse. Não há nada melhor do que exemplos concretos de metas de teste de estresse, boas e ruins:
- Fez 1 milhão de acessos. Tempo médio de criação da página da web = 1 seg. O que isso mostra? Nada. Quanto tempo durou o teste de carga? O tempo de execução de uma única solicitação pode ser de 1 ms ou 600 segundos e não está claro quais proporções são maiores. E quantos erros houve (a resposta nginx no estilo de "Erro 50x") também não está clara :-)
- Fez 1 milhão de acessos. Tempo médio de criação de páginas da web = 1 segundo, o número de erros de HTTP é de 0,5% O que isso mostra? Até agora, um pouco útil, mas melhor. A parcela de erros inadequados que o cliente pode detectar, já sabemos que é ótimo e você pode começar a se preparar e ir à farmácia. A mediana é uma métrica mais resistente a "valores extremos" que a média (estimativa mais "robusta"); portanto, é sem dúvida melhor que a média aritmética. Mas vamos tornar as métricas ainda mais úteis.
- 1 milhão de acessos foram feitos por dia. 25% dos acessos realizados em menos de 10 ms, 50% dos acessos realizados em menos de 1 segundo (esta é a mediana ou o percentil 50), 75% dos acessos realizados em menos de 1,5 segundos, 95% dos acessos em menos de 1 segundo 5 segundos e o número de erros de HTTP é de 0,5% É isso aí! Vemos a proporção de erros inadequados que o cliente pode capturar, mas também vemos a proporção de solicitações que são executadas em um determinado limite.
Como você pode ver, a escolha de métricas adequadas para avaliar a velocidade de um projeto da Web durante o teste de carga é muito, muito importante. Há apenas um princípio - as métricas devem ser absolutamente claras tanto para o cliente quanto para você, e mostrar qualidade de maneira clara e clara. De fato, a métrica mais óbvia e correta é a distribuição da velocidade de processamento de ocorrências ao longo do tempo. Se você conseguir fazer isso nos testes de estresse, será super. Além disso, você pode comparar dois testes de estresse pela natureza da distribuição dos hits do tempo e ver como ficou melhor e onde. Visualização é poder!
Nada está claro: percentis, medianas, quantis, rascunhos, distribuição ...
Tudo é simples! Agora vou desenhar e mostrar em um ambiente bonito para análise de dados: Jupyter notebook / Python.
Digamos que 10 hits foram feitos no site com esse tempo em milissegundos:
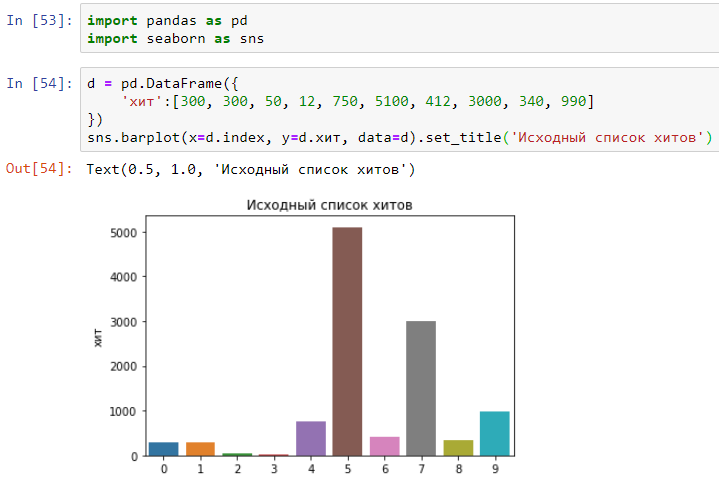
Agora, ordene o tempo necessário para concluir os hits em ordem crescente:

Estamos a um passo de entender a mediana dos percentis 25 e 75. Tudo é simples - dividimos o gráfico ao meio e no meio haverá uma "mediana" (número 1 no gráfico). O primeiro trimestre do gráfico corresponderá ao percentil 25 (número 2 no gráfico) e o terceiro trimestre corresponderá ao percentil 75 (número 3 no gráfico). Assim, outros percentis são obtidos (ou, como também são chamados, quantis) - 90, 95, 99, etc .:
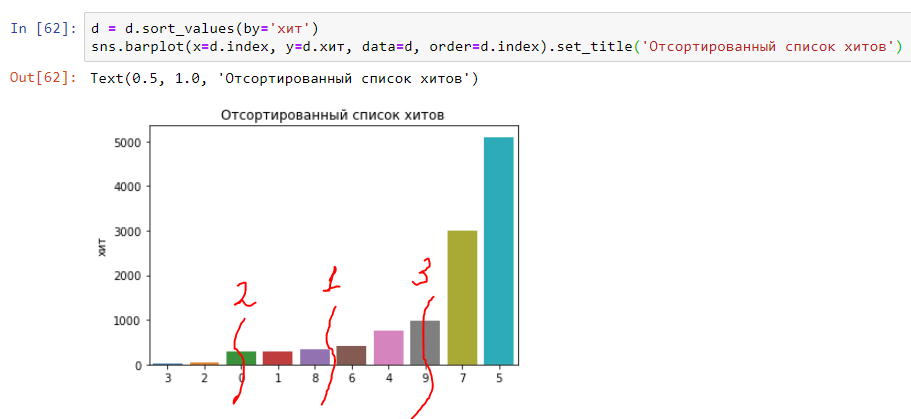
E parecerá com a distribuição (histograma) ao longo do tempo de execução das ocorrências acima. Como você pode ver, tudo é muito claro e simples:
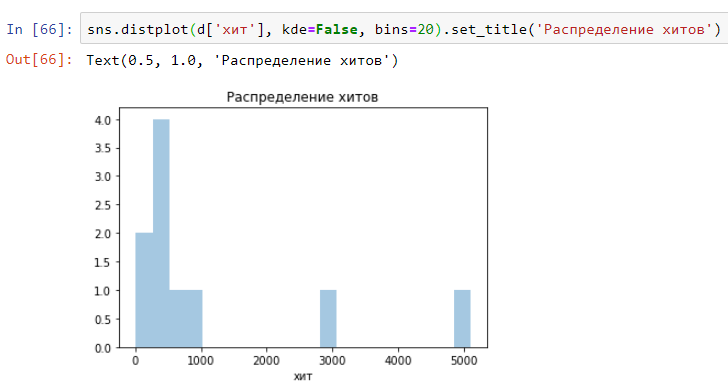
E é assim que você pode criar rapidamente uma distribuição (histograma) com base no log de solicitação de teste de carga. Modifique para o seu formato de log:
E você obtém algo assim:

Espero que agora tudo tenha ficado claro e no lugar. Caso contrário, pergunte nos comentários.
Tempo de teste de estresse
As pessoas costumam perguntar - quanto tempo deve durar o teste de carga de um projeto da web? Existe uma heurística simples - no sistema operacional, as tarefas agendadas são frequentemente executadas uma vez por dia: backups, rotação de logs etc. etc., portanto, o tempo para a realização de testes de carga não deve ser inferior a, corretamente, um dia. Se o projeto da Web for baseado no Bitrix, a plataforma também possui muitas tarefas agendadas e é recomendável carregar o sistema da Web por pelo menos um dia.
Balanceamento de carga
Se você já possui um site operado, pode, sim, fazer os registros de visita a partir daí e carregar o novo sistema da web usando-os. Mas muitas vezes eles resolvem o problema de carregar apenas o sistema web desenvolvido. Para planejar o balanceamento de carga, o modelo de divisão de cadeias potenciais de visita a um site em compartilhamentos geralmente é um bom ajuste. Por exemplo:
- Home - Notícias - Notícias detalhadas = 50%
- Página inicial - Visão geral do catálogo - Catálogo detalhado = 30%
- Catálogo detalhado - Visão geral do catálogo - Catálogo detalhado = 15%
- Resultados da pesquisa - catálogo detalhado = 5%
No software para criar uma carga (geralmente usamos o Jmeter), são criados tantos fluxos de carga para cada cadeia, de modo que, levando em consideração o intervalo entre as ocorrências na cadeia, o número total de ocorrências de cada cadeia por unidade de tempo é correlacionado como: 50%, 30%, 15%, 5% .
É fácil fazer cálculos de intervalos e fluxos de carga no Excel ou em uma folha com um lápis.
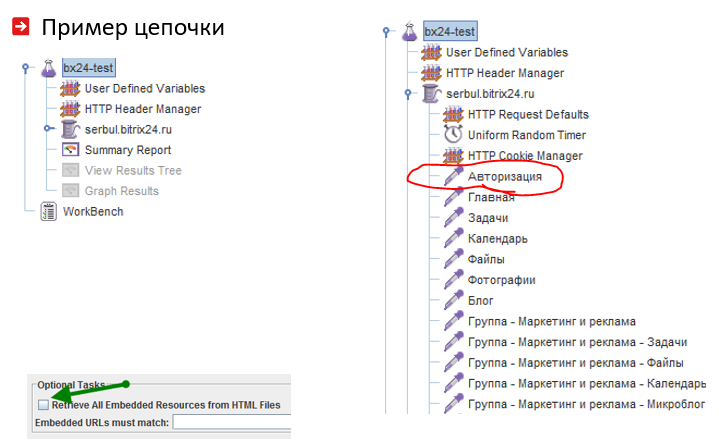
Estrutura da cadeia de carga
É importante considerar os recursos do ciclo de vida do usuário do sistema da web. Frequentemente, os usuários efetuam login e depois acessam o site. Para fazer isso, você precisa colocar as ações que levam à autorização no início da cadeia de carga:
Está claro para o cavalo que é impossível extrair apenas uma página detalhada do catálogo durante o teste de estresse; portanto, é útil ler e girar sua lista no arquivo CSV:

Entre os hits, é claro, você precisa fazer pausas aleatórias - para que nos aproximemos da carga criada por usuários reais. Não se esqueça de salvar e retornar valores de cookie para o servidor:

As variáveis globais das cadeias de carga, incluindo o número de threads, são fáceis de configurar. Certas variáveis globais podem ser usadas em diferentes locais nas cadeias de carga:


Como fazer o teste de estresse terminar com segurança?
Na prática, quase sempre, o teste de carga nos primeiros minutos ou horas trava o sistema web, tudo começa a fumar, depois queima, o site não abre, o MySQL entra em uma troca e não se permite conectar, LA nos servidores se aproxima de 100, os desenvolvedores começam a executar com as palavras "isso não deveria ter acontecido", e os administradores do sistema com um sorriso geralmente respondem "há justiça na vida!" e comece a beber cerveja na sala do servidor.
Mas, para entender por que tudo caiu e o que reparar, para mostrar ao cliente os resultados de um teste de carga "bem-sucedido" em um dia, você deve primeiro ativar o registro das principais métricas da vida do sistema operacional - isso é fácil de fazer nos produtos gratuitos da classe munun / cacti.
Vou listar o que acontece durante o colapso de um sistema da Web com mais freqüência e como isso pode ser corrigido.
Primeiro, o servidor web apache ou php-fpm está "entupido" com as solicitações:

Na maioria das vezes, isso ocorre devido ao colapso do MySQL - o número de fluxos de consulta suspensos está aumentando:

Qual o motivo disso? Frequentemente, eles esquecem de restringir o número de apache ou fluxos de consulta ao MySQL, o que faz com que os aplicativos abandonem a RAM em uma troca lenta com convulsões:
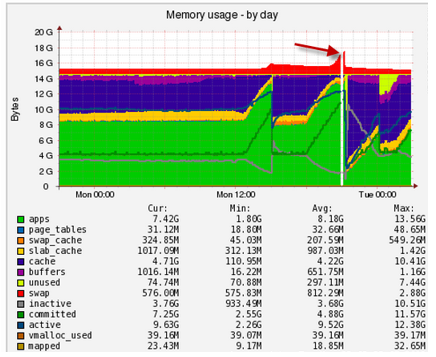
Aqui você pode ver a atividade repentina ao trabalhar com um swap, é necessário entender quem entrou no swap e onde:
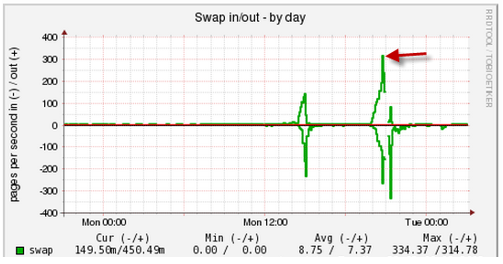
No entanto, às vezes o problema está do lado do subsistema de disco lento. Nesse caso, LA aumenta acentuadamente e a porcentagem de utilização de disco se aproxima de 100 (gráfico no canto inferior direito):


Obviamente, revelei apenas uma parte da coisa mais interessante que pode começar com um projeto da web durante o teste de estresse. Mas o principal é definir a direção certa e criar o processo certo. Pergunte nos comentários o que apareceu durante o carregamento, vou tentar ajudar.
Interpretação dos resultados dos testes de estresse
Geralmente, após 5 a 10 reinicializações e ajustes, o teste de carga inicia seu voo e é concluído com êxito. Como resultado, você deve ter um conjunto de aproximadamente esses logs para análises adicionais:
- log de solicitações ao nginx com a hora da solicitação do cliente (neste caso, será o carregamento do software), o tempo de proxy do nginx para o apache / php-fpm
- log de erro do nginx
- log de solicitação apache / php-fpm com tempo de processamento de solicitação e status de resposta HTTP
- log de erros do apache / php-fpm
- Registro lento do MySQL
- Registro de erros do MySQL
Além disso, deve haver gráficos analíticos nos últimos dias sobre o uso de CPU, discos, MySQL, RAM, trabalhadores apache, etc. (veja exemplos acima de gráficos munin).
Tendo esses artefatos, é possível, usando um script awk simples no início da postagem, criar distribuições (histogramas) sobre esses logs e calcular o número e os tipos de erros HTTP. De fato, você pode gerar um relatório sobre o sucesso dos testes de estresse sobre esse conteúdo, que é muito amplo e útil para negócios e tomada de decisão:
Durante o dia fez 1 milhão de acessos. 25% dos acessos foram feitos em menos de 50 ms, 50% dos acessos foram feitos em menos de 0,5 s (mediana), 75% dos acessos foram feitos em menos de 1 segundo, 95% dos acessos foram feitos em menos de 5 segundos, o número de erros HTTP - 0,01%. Dados do teste: catálogo, usuários, notícias, artigos foram inundados em um volume próximo ao esperado. Um desenvolvedor se matou.
Cadeias de carga:
Home - Notícias - Notícias detalhadas = 50%
Página inicial - Visão geral do catálogo - Catálogo detalhado = 30%
Catálogo detalhado - Visão geral do catálogo - Catálogo detalhado = 15%
Resultados da pesquisa - catálogo detalhado = 5%
Gráficos de uso de recursos do servidor:
...
Este é um relatório bom e compreensível sobre o teste de carga do sistema web. Para os amantes de dores agudas, você ainda pode recomendar durante o teste de carga a inclusão de cada minuto de importação e exportação de dados para um site de sistemas da classe SAP, 1C, etc. e conexões síncronas sobre soquetes TCP / IP com serviços de troca externa, por exemplo, criptomoedas :-)
Mas, para ser honesto, se a importação-exportação for feita com cuidado e honestidade, os testes de carga e nessas condições mostrarão valores aceitáveis para os negócios.
De onde vêm os testes de estresse?
A propósito, sim, não destacamos esse momento. Por razões triviais, a falta de equilíbrio entre os trabalhadores nginx - apache - mysql geralmente aparece. I.e. os trabalhadores não estão limitados acima, como resultado, 500 trabalhadores (cada um às vezes 100 MB cada) podem subir imediatamente no apache e 500 threads com solicitações chegarão ao MySQL imediatamente - o que causará um aumento nos erros HTTP 50x e um possível colapso.
Aqui, recomenda-se limitar o número de trabalhadores apache / php-fpm ao número que se encaixa na RAM e, da mesma forma, limitar o número de threads no MySQL para proteger contra o estouro da RAM disponível. A idéia é simples - deixe que os clientes esperem na frente do nginx, pois pode ficar um pouco mais lento nos soquetes TCP / IP assíncronos e sem bloqueio, que "quebram" imediatamente no apache / MySQL.
Das razões mais irritantes, pode haver um segfault PHP. Nesse caso, você precisa habilitar a coleção coredump e usar o gdb para ver por que isso acontece. Na maioria dos casos, o problema pode ser contornado através da atualização / configuração do PHP.
O que resta nos bastidores
Existem rumores persistentes de que o frontend moderno da Web viveu tão ativamente que o teste de carga clássico do backend apresentado neste post não cobre mais todos os riscos possíveis de congelar a construção de uma página da Web nas entranhas do Angular / React / Vue.js - portanto
não use um front end pesado e opaco e mal testado; é possível, se necessário, adaptar as cadeias de carga a essa situação.
De qualquer forma, se os resultados do teste de estresse do back-end mostrarem bons números e o site continuar a desacelerar no navegador, já está claro quem deve ser "atingido o rosto vermelho" :-)
Sério, nos próximos posts, esperamos abordar esse tópico importante.
Resumo e Conclusões
Total - não há nada complicado na organização e realização de testes de carga de um sistema da Web útil para desenvolvimento e negócios.
Os testes de carga, devidamente organizados, sempre devem ser realizados - caso contrário, existe o risco de ocorrer grandes problemas durante a operação de combate, que não podem ser eliminados em poucos dias.
Para realizar testes de estresse, é importante atrair não apenas desenvolvedores, mas também especialistas em sistemas operacionais e hardware - administradores de sistemas experientes e, em seguida, os problemas de "cair em uma troca" ou "exceder o intervalo local de endereços IP" não causarão sangramento nos olhos e desmaios.
Boa sorte amigos e faça perguntas nos comentários!