Percebemos o processador central como o "cérebro" de um computador, mas o que isso realmente significa? O que exatamente acontece dentro dos bilhões de transistores que fazem um computador funcionar? Em nossa nova minissérie de quatro artigos, consideraremos o processo de criação da arquitetura de equipamentos de computador e discutiremos os princípios de sua operação.
Nesta série, falaremos sobre arquitetura de computadores, design de placas de processador, VLSI (integração em grande escala), fabricação de chips e tendências futuras no campo da tecnologia de computadores. Se você estava interessado em entender os detalhes dos processadores, é melhor começar o estudo com esta série de artigos.
Começaremos com uma explicação de alto nível sobre o que o processador faz e como os blocos de construção se conectam a uma estrutura funcional. Em particular, consideraremos núcleos de processador, hierarquia de memória, previsão de ramificação e muito mais. Primeiro, precisamos dar uma definição simples do que a CPU faz. A explicação mais simples: o processador segue um conjunto de instruções para executar uma certa operação em muitos dados recebidos. Por exemplo, ele pode ler um valor da memória, adicioná-lo a outro valor e, finalmente, salvar o resultado na memória em um endereço diferente. Pode ser algo mais complicado, por exemplo, a divisão de dois números, se o resultado do cálculo anterior for maior que zero.
Programas, como um sistema operacional ou um jogo, são seqüências de instruções que a CPU deve executar. Essas instruções são carregadas da memória e executadas em um processador simples, uma após a outra, até o programa terminar. Os desenvolvedores de software escrevem programas em linguagens de alto nível, como C ++ ou Python, mas o processador não pode entendê-los. Ele entende apenas zeros e zeros, portanto, precisamos representar de alguma forma o código nesse formato.
Os programas são compilados em um conjunto de instruções de baixo nível chamado
linguagem assembly , que faz parte da arquitetura do conjunto de instruções (ISA). Este é um conjunto de instruções que a CPU deve entender e executar. Alguns dos ISAs mais comuns são x86, MIPS, ARM, RISC-V e PowerPC. Da mesma maneira que a sintaxe para escrever uma função em C ++ difere da função que executa a mesma ação em Python, cada ISA possui sua própria sintaxe diferente.
Esses ISAs podem ser divididos em duas categorias principais: comprimento fixo e variável. O ISA RISC-V usa instruções de comprimento fixo, o que significa que um número predeterminado de bits em cada instrução determina que tipo de instrução é. No x86, tudo é diferente, ele usa instruções de comprimento variável. No x86, as instruções podem ser codificadas de diferentes maneiras, com diferentes números de bits para diferentes partes. Devido a essa complexidade, o decodificador de instruções no processador x86 geralmente é a parte mais complexa de todo o dispositivo.
As instruções de comprimento fixo fornecem decodificação simples devido a uma estrutura constante, mas limitam o número total de instruções que podem ser suportadas pelo ISA. Embora as versões populares da arquitetura RISC-V possuam aproximadamente 100 instruções e todas sejam de código aberto, a arquitetura x86 é proprietária e ninguém sabe quantas instruções existem nela. Geralmente, acredita-se que existem vários milhares de instruções x86, mas ninguém publica o número exato. Apesar das diferenças entre os ISAs, todos eles têm a mesma funcionalidade básica.
Um exemplo de algumas instruções do RISC-V. O código de operação à direita tem 7 bits e determina o tipo de instrução. Além disso, cada instrução contém bits que definem os registradores utilizados e as funções executadas. Portanto, as instruções do assembler são divididas em código binário para que o processador o entenda.Agora estamos prontos para ligar o computador e começar a executar programas. A execução da instrução possui várias partes básicas, que são divididas em vários estágios do processador.
O primeiro estágio é a transferência de instruções da memória para o processador para iniciar a execução. Na segunda etapa, a instrução é decodificada para que a CPU possa entender que tipo de instrução é. Existem muitos tipos, incluindo instruções aritméticas, instruções de ramificação e instruções de memória. Depois que a CPU descobre que tipo de instrução está executando, os operandos da instrução são retirados da memória ou dos registros internos da CPU. Se você deseja adicionar o número A e o número B, não poderá adicioná-lo até conhecer os valores de A e B. A maioria dos processadores modernos são de 64 bits, ou seja, o tamanho de cada valor de dados é de 64 bits.
64 bits é a largura do registro do processador, canal de dados e / ou endereço de memória. Para usuários comuns, isso significa quanta informação um computador pode processar por vez, e isso é melhor compreendido em comparação com um parente de arquitetura mais jovem - um processador de 32 bits. A arquitetura de 64 bits pode processar o dobro de bits de informação por vez (64 bits versus 32).Depois de receber os operandos para a instrução, o processador os transfere para o estágio de execução, onde a operação é executada nos dados recebidos. Isso pode incluir números, executar manipulações lógicas com números ou simplesmente passar números sem alterá-los. Após calcular o resultado, pode ser necessário acessar a memória para armazená-lo ou o processador pode simplesmente armazenar o valor em um de seus registros internos. Depois de salvar o resultado, a CPU atualiza o estado dos vários elementos e prossegue para a próxima instrução.
Essa explicação, é claro, é bastante simplificada, e a maioria dos processadores modernos divide esses vários estágios em 20 ou até mais pequenos estágios para aumentar a eficiência. Isso significa que, embora o processador inicie e termine com várias instruções em cada ciclo, pode levar 20 ou mais ciclos para executar uma instrução do início ao fim. Esse modelo geralmente é chamado de gasoduto ("gasoduto", geralmente traduzido para o russo como "transportador"), porque leva tempo para encher o gasoduto com líquido e concluí-lo, mas após o preenchimento do fluxo (saída de dados) será constante.
Um exemplo de transportador de 4 estágios. Retângulos multicoloridos indicam instruções independentes entre si.Todo o ciclo pelo qual a instrução passa é um processo coordenado com muito cuidado, mas nem todas as instruções podem ser concluídas ao mesmo tempo. Por exemplo, a adição é muito rápida e a divisão ou carregamento da memória pode levar milhares de ciclos. Em vez de parar o processador inteiro até a conclusão de uma instrução lenta, a maioria dos processadores modernos os executa com uma mudança de ordem. Ou seja, eles determinam qual das instruções é mais vantajosa para executar no momento e armazenam em buffer outras instruções que ainda não estão prontas. Se a instrução atual ainda não estiver pronta, o processador poderá avançar no código para ver se alguma outra coisa está pronta.
Além de executar com uma sequência de alterações, os processadores modernos usam uma tecnologia chamada
arquitetura superescalar . Isso significa que a qualquer momento, o processador executa simultaneamente várias instruções em cada estágio do pipeline. Ele também pode esperar que outras centenas iniciem sua execução e, para poder executar várias instruções simultaneamente dentro dos processadores, existem várias cópias de cada estágio do pipeline. Se o processador vir que duas instruções estão prontas para execução e não houver dependência entre elas, não esperará até que sejam concluídas separadamente, mas as executará simultaneamente. Uma implementação popular dessa arquitetura é chamada SMT (Multithreading Simultâneo) e também é conhecida como Hyper-Threading. Os processadores Intel e AMD agora suportam SMT de dupla face, enquanto a IBM desenvolveu chips que suportam até oito SMTs.
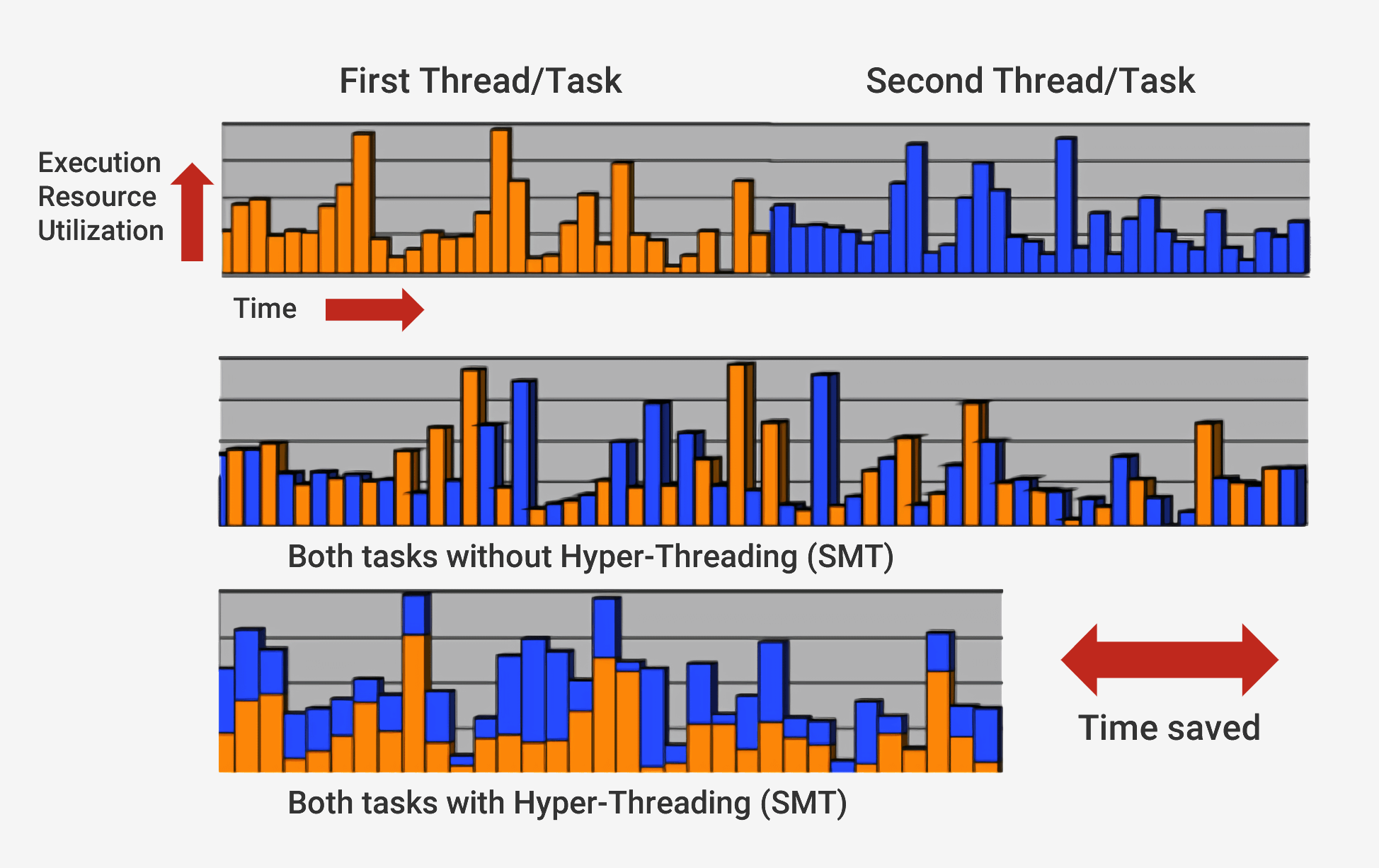
Para concluir esta execução cuidadosamente coordenada, o processador, além do núcleo básico, possui muitos elementos adicionais. O processador possui centenas de módulos separados, cada um com uma função específica, mas consideraremos apenas o básico. Os mais importantes e lucrativos são os caches e o preditor de transições. Existem outras estruturas adicionais que não consideraremos: reordenar buffers, registrar tabelas de renomeação e estações de backup.
Às vezes, a necessidade de caches pode ser confusa, porque eles armazenam dados, como RAM ou SSD. Mas os caches diferem em latência e velocidade de acesso. Embora a memória RAM seja extremamente rápida, é uma ordem de magnitude mais lenta do que a CPU precisa. Podem ser necessárias centenas de ciclos para responder com a transferência de dados de RAM e o processador não terá nada a fazer no momento. E se não houver dados na RAM, pode levar dezenas de milhares de ciclos para obter acesso a eles a partir do SSD. Sem caches, os processadores paravam constantemente.
Os processadores normalmente têm três níveis de cache que compõem a chamada
hierarquia de memória . O cache L1 é o menor e mais rápido, o L2 está no meio e o L3 é o maior e mais lento de todos os caches. Acima dos caches na hierarquia existem pequenos registros que armazenam o único valor de dados durante os cálculos. Em ordem de magnitude, esses registros são os dispositivos de armazenamento mais rápidos do sistema. Quando o compilador converte um programa de alto nível em linguagem assembly, ele determina a melhor maneira de usar esses registros.
Quando a CPU solicita dados da memória, primeiro verifica se esses dados já estão armazenados no cache L1. Nesse caso, você pode acessá-los em apenas alguns ciclos. Se eles não estiverem lá, o processador verificará L2 e, em seguida, o cache L3. Os caches são implementados de maneira que, em geral, sejam transparentes ao kernel. O kernel simplesmente solicita dados no endereço de memória especificado e o nível na hierarquia em que existe responde. Ao passar para níveis subseqüentes na hierarquia de memória, o tamanho e os atrasos geralmente aumentam em ordens de magnitude. No final, se a CPU não encontrar dados em nenhum dos caches, ela acessa a memória principal (RAM).
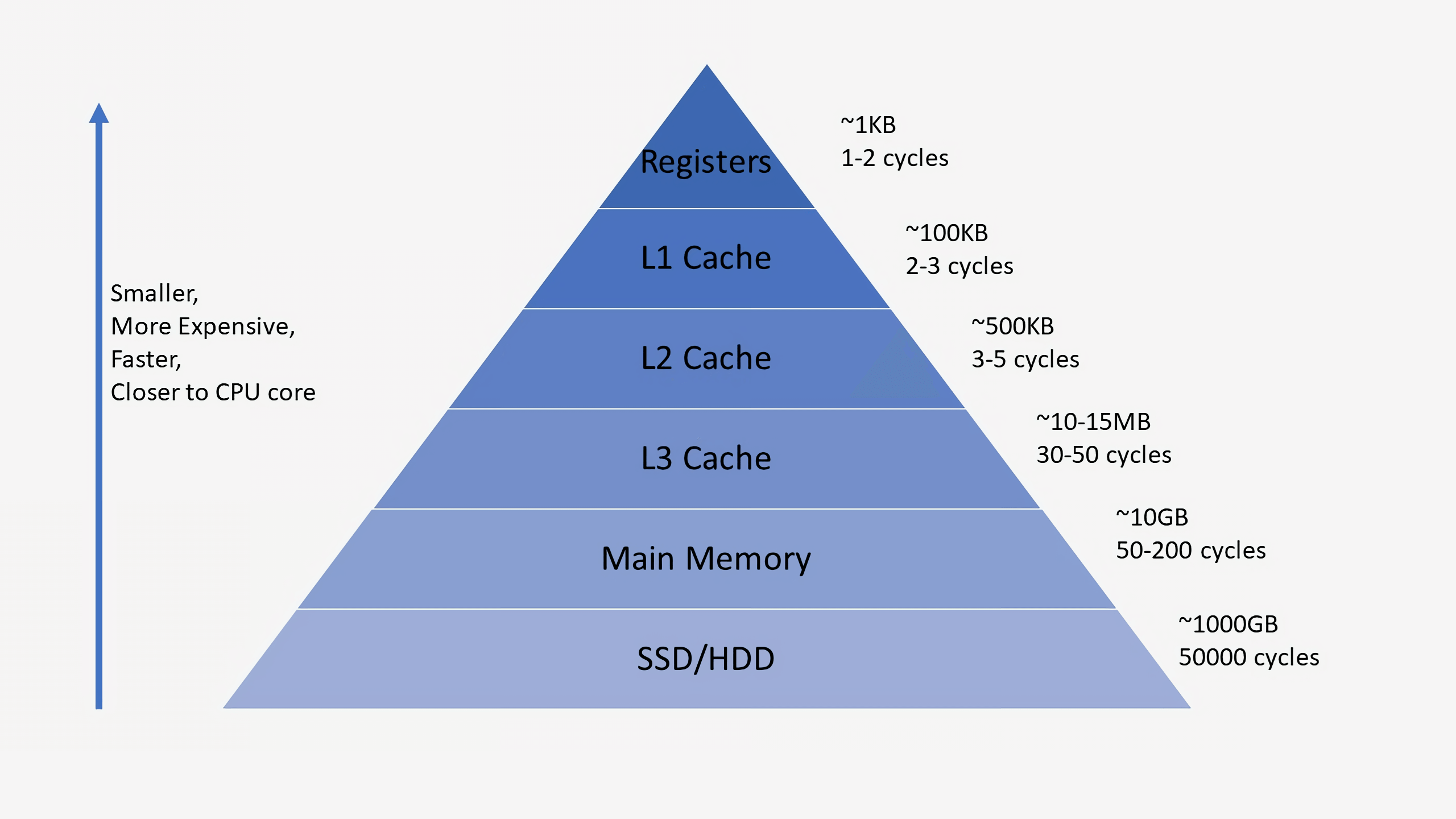
Em um processador comum, cada núcleo possui dois caches L1: um para dados e outro para instruções. Os caches L1 geralmente têm uma capacidade total de cerca de 100 kilobytes e o tamanho varia muito, dependendo da geração do chip e do processador. Além disso, geralmente cada núcleo possui seu próprio cache L2, embora em algumas arquiteturas seja comum a dois núcleos. Os caches L2 geralmente têm várias centenas de kilobytes de tamanho. Por fim, existe um único cache L3 comum a todos os núcleos, com um tamanho da ordem de dezenas de megabytes.
Quando o processador executa o código, as instruções e valores de dados usados com mais freqüência são armazenados em cache. Isso acelera significativamente a execução, porque o processador não precisa acessar constantemente a memória principal para obter os dados necessários. Na segunda e terceira partes da série, falaremos mais sobre como esses sistemas de memória são implementados.
Além dos caches, um dos componentes mais importantes de um processador moderno é um
preditor de transição preciso. As instruções de transição (ramificação) são semelhantes às construções if do processador. Um conjunto de instruções é executado se a condição for verdadeira e o outro se for falso. Por exemplo, precisamos comparar dois números e, se forem iguais, execute uma função e, se não forem iguais, execute outra. Essas instruções de ramificação são extremamente comuns e podem representar cerca de 20% de todas as instruções em um programa.
À primeira vista, parece que essas instruções de ramificação não devem causar problemas, mas sua execução adequada pode ser muito difícil para o processador. A qualquer momento, o processador pode estar executando simultaneamente dez ou vinte instruções; portanto, é muito importante saber
quais instruções executar. Pode levar 5 ciclos para determinar que a instrução atual é uma transição e outros 10 para determinar se a condição é verdadeira. No momento, o processador já pode começar a executar dezenas de instruções adicionais, sem nem mesmo saber se essas instruções são realmente adequadas para execução.
Para contornar esse problema, todos os processadores modernos de alto desempenho usam uma técnica chamada especulação. Isso significa que o processador controla as instruções da ramificação e se pergunta se a ramificação condicional será executada ou não. Se a previsão estiver correta, o processador já começou a executar as seguintes instruções, e isso fornece um aumento de desempenho. Se a previsão estiver incorreta, o processador interromperá a execução, excluirá todas as instruções incorretas que começaram a executar e iniciará novamente a partir do ponto correto.
Esses preditores de ramificação são alguns dos tipos mais simples de aprendizado de máquina, porque o preditor estuda o comportamento das ramificações durante a execução. Se ele predizer incorretamente com muita frequência, ele começa a aprender o comportamento correto. Décadas de pesquisas sobre técnicas de previsão de transição resultaram em mais de 90% de precisão de previsão nos processadores modernos.
Embora a antecipação ofereça um enorme aumento no desempenho, porque o processador pode executar instruções que já estão prontas, em vez de esperar na fila pela conclusão da execução, também cria vulnerabilidades de segurança. O famoso ataque Spectre explora bugs na previsão e antecipação de transições. O invasor usa código especialmente selecionado para forçar o processador a executar proativamente o código, o que resulta em um vazamento de valores da memória. Para evitar vazamento de dados, foi necessário refazer o design de certos aspectos da antecipação, o que levou a uma leve queda no desempenho.
Nas últimas décadas, a arquitetura usada nos processadores modernos percorreu um longo caminho. A inovação e o desenvolvimento de uma estrutura bem pensada levaram ao aumento da produtividade e ao uso mais otimizado do hardware. No entanto, os desenvolvedores dos processadores centrais mantêm cuidadosamente os segredos de suas tecnologias, para que não possamos descobrir exatamente o que está acontecendo dentro deles. No entanto, os princípios fundamentais dos processadores são padronizados para todas as arquiteturas e modelos. A Intel pode adicionar seus ingredientes secretos para aumentar o compartilhamento de hits do cache, e a AMD pode adicionar um preditor de transição aprimorado, mas os processadores de ambas as empresas executam a mesma tarefa.
Neste primeiro olhar e revisão, abordamos o básico de como os processadores funcionam. Na próxima parte, mostraremos como desenvolver os componentes que compõem os processadores, falar sobre elementos lógicos, frequências de clock, gerenciamento de energia, circuitos e muito mais.
Leitura Recomendada