
Primeiro, vamos definir o conceito de "fila".
Leve em consideração o tipo de fila
“FIFO” (primeiro a
entrar , primeiro a sair). Se você pegar o valor da
Wikipedia - "esse é um tipo de dados abstrato com a disciplina de acesso a elementos". Em resumo, isso significa que não podemos obter dados dele em uma ordem aleatória, mas apenas coletamos o que veio primeiro.
Em seguida, você precisa decidir por que eles são necessários?
1. Para operações diferidas. Um exemplo clássico é o processamento de imagens. Por exemplo, um usuário carregou uma imagem no site que precisamos processar, essa operação leva muito tempo, o usuário não quer esperar tanto. Portanto, carregamos a imagem e depois a transferimos para a fila. E será processado quando qualquer "trabalhador" conseguir.
2. Para lidar com cargas de pico. Por exemplo, há uma parte do sistema que às vezes causa muito tráfego e não requer uma resposta instantânea. Como opção, gerando quaisquer relatórios. Jogando esta tarefa na fila - damos a oportunidade de lidar com ela com uma carga uniforme no sistema.
3. Escalabilidade. E provavelmente o motivo mais importante, a fila torna possível
ampliar. Isso significa que você pode exibir vários serviços para processamento em paralelo, o que aumentará bastante a produtividade.
Agora, vamos examinar os problemas que enfrentaremos se criarmos a fila:
1. Acesso paralelo. Somente um manipulador pode receber uma mensagem de uma fila. Ou seja, se ao mesmo tempo dois serviços solicitarem mensagens, cada um deles deverá retornar um conjunto exclusivo de mensagens. Caso contrário, verifica-se que uma mensagem é processada duas vezes. O que poderia ser complicado.
2. O mecanismo da desduplicação. O serviço deve ter um sistema que proteja a fila de duplicatas. Pode haver uma situação em que o mesmo conjunto de dados seja enviado à fila por acaso duas vezes. Como resultado, processaremos a mesma coisa duas vezes. O que novamente é preocupante.
3. Mecanismo de tratamento de erros. Digamos que nosso serviço tenha recebido três mensagens da fila. Dois dos quais ele processou com êxito enviando solicitações de remoção da fila. E o terceiro ele não conseguiu processar e morreu. Uma mensagem que está no status de processamento não está disponível para outros serviços. E não deve permanecer para sempre no status de processamento. Essa mensagem deve ser passada para outro manipulador por alguma lógica. Um exemplo da implementação dessa lógica será considerado em breve usando o AWS SQS (Simple Queue Service) como exemplo.
Amazon Web Services - Serviço de fila simples
Agora vamos ver como o SQS resolve esses problemas e o que ele pode fazer.
1. Acesso paralelo. Na fila, você pode definir o parâmetro de
tempo limite da
visibilidade . Determina quanto tempo o processamento de uma mensagem pode levar o maior tempo possível. Por padrão, são
30 segundos. Quando um serviço recebe uma mensagem, ele é transferido para o status
"Em Vôo" por 30 segundos. Se durante esse período não houver um comando para remover esta mensagem da fila, ela retornará ao início e o próximo serviço poderá recebê-la novamente para processamento.
Trabalho shemka pequeno.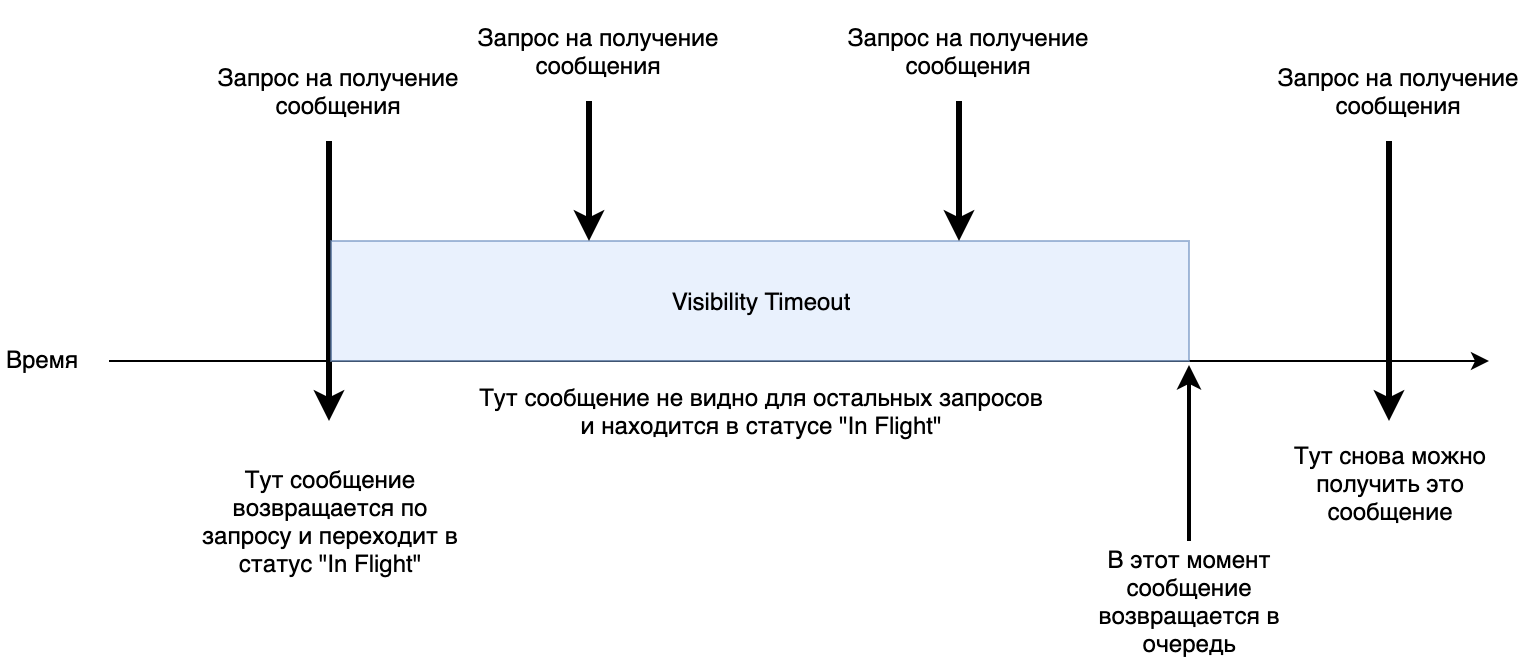
Aviso: Tenha cuidado. Em alguns casos, o SQS pode enviar uma mensagem duplicada (item "Entrega pelo menos uma vez"). Portanto, seu serviço deve ser idempotente para processamento.
2. Mecanismo de tratamento de erros. No SQS, você pode configurar a segunda volta para mensagens "inativas" (fila de devoluções). Ou seja, aqueles que não puderam processar nosso serviço serão enviados para uma fila separada, que você poderá descartar a seu critério. Você também pode definir após o qual o número de tentativas sem êxito que a mensagem entrará na fila "inoperante". Uma tentativa com falha é a expiração do "Tempo limite da visibilidade". Ou seja, se nenhuma solicitação de exclusão tiver sido enviada durante esse período, essa mensagem será considerada não processada e retornará à fila principal ou será direcionada para "morto".
3. Desduplicação de mensagens. O SQS também possui um sistema de proteção duplicado. Cada mensagem tem um
"ID de redução de redundância" , o SQS não enfileira uma mensagem com
repetido "ID de redução de redundância" por 5 minutos. Você deve especificar um "ID de redução de redundância" em cada mensagem ou ativar a geração de ID com base em conteúdo. Isso significa que um hash gerado com base no seu conteúdo será inserido no "ID de redução de redundância". O parâmetro
"Desduplicação com base em conteúdo". Mais sobre desduplicaçãoAviso: tenha cuidado se enviar duas mensagens idênticas dentro de 5 minutos e você tiver “Desduplicação baseada em conteúdo” ativada.O SQS não adicionará uma segunda mensagem à fila.
Aviso: tenha cuidado, por exemplo, se não houver conexão no dispositivo e ele não receber uma resposta e enviar uma segunda solicitação após 5 minutos, será criada uma duplicata.
4. Enquete longa. Pesquisa longa . O SQS suporta esse tipo de conexão com um tempo limite máximo de 20 segundos. O que nos permite economizar tráfego e "empurrões" do serviço.
5. Métricas. A Amazon também fornece métricas detalhadas da fila. Como o número de mensagens recebidas / enviadas / excluídas, o tamanho em KB dessas mensagens e assim por diante. Você também pode conectar o SQS ao serviço de log do CloudWatch. Lá você pode ver ainda mais. Também é possível configurar os chamados
“alarmes” e configurar ações para qualquer evento.
Saiba mais sobre a conexão com o SQS. E
documentação do CloudWatch
Agora vamos ver as configurações da fila:
Os principais:
Tempo limite de visibilidade padrão - o número de segundos / minutos / horas durante o qual a mensagem após o recebimento não ficará visível para o recebimento. O tempo máximo de processamento é de 12 horas.
Período de retenção de mensagens - o número de segundos / minutos / horas / dias, o que significa quanto tempo as mensagens não processadas serão armazenadas na fila. Máximo - 14 dias.
Tamanho máximo da mensagem - tamanho máximo da mensagem em KB. O valor é de 1 KB a 256 KB.
Atraso na entrega - você pode definir o tempo de atraso para entrega de uma mensagem na fila. De 0 segundos a 15 minutos (de fato, as mensagens estarão na fila, mas não estarão visíveis para receber).
Tempo de espera para recebimento de mensagens - tempo, quanto tempo a conexão permanecerá no caso de usarmos "Pesquisa longa" para receber novas mensagens.
Desduplicação com base em conteúdo - um sinalizador, se definido como true, um "ID de redução de redundância" será adicionado a cada mensagem na forma de um hash SHA-256 gerado a partir do conteúdo.
Configurações da fila inoperante
Use Redrive Policy - um sinalizador, se definido, as mensagens serão redirecionadas após várias tentativas.
Fila de mensagens não entregues
- o nome da fila "inativa" para a qual as mensagens brutas serão enviadas.
Número Máximo de Recebimentos - o número de tentativas malsucedidas de processamento, após as quais a mensagem será enviada para a fila "inoperante"
Aviso: Observe também que podemos enviar todos os parâmetros principais juntamente com cada mensagem separadamente. Por exemplo, cada mensagem individual pode ter seu próprio tempo limite de visibilidade ou atraso de entrega.
Agora, um pouco sobre as próprias mensagens e suas propriedades:
Uma mensagem possui vários parâmetros:
1. Corpo da mensagem - qualquer texto
2. O ID do grupo de mensagens é algo como uma tag, canal, necessário para todas as mensagens. É garantido que cada um desses grupos seja processado no modo FIFO.
3. ID de redução de redundância de
mensagens - string para identificar duplicatas. Se o modo "Desduplicação baseada em conteúdo" estiver definido, o parâmetro será opcional.
Também existem atributos de mensagem
Os atributos consistem em um nome, tipo e valor.
1. Nome - sequência
2. Tipo - existem vários tipos: sequência, número, binário. O tipo vem simplesmente como uma string e é possível adicionar um postfix ao tipo. Nesse caso, o tipo virá com esse postfix através do ponto, por exemplo, string.example_postfix
3. Valor - sequência
Aviso: Observe que o número máximo de atributos é 10 Detalhes
PS: Este artigo fornece uma breve descrição da fila, bem como um pouco sobre os recursos e a mecânica do SQS. O artigo a seguir será dedicado à
AWS Lambda e, em seguida, ao compartilhamento prático.