O que é importante para uma equipe de desenvolvimento que está apenas começando a construir um sistema de aprendizado de máquina? Arquitetura, componentes, recursos de teste usando integração e testes de unidade, fazem um protótipo e obtêm os primeiros resultados. E além da avaliação da contribuição do trabalho, planejamento de desenvolvimento e implementação.
Este artigo se concentrará no protótipo. Que foi criado algum tempo depois de conversar com o Gerente de Produto: por que não tocamos no Machine Learning? Em particular, PNL e análise de sentimentos?
"Por que não?" Eu respondi. Ainda assim, estou envolvido no desenvolvimento de back-end há mais de 15 anos, gosto de trabalhar com dados e resolver problemas de desempenho. Mas eu ainda tinha que descobrir "quão profunda é a toca do coelho".
Selecionar componentes
Para delinear de alguma maneira o conjunto de componentes que implementam a lógica do nosso núcleo de ML, vejamos um exemplo simples da implementação da análise de sentimentos, uma das muitas disponíveis no GitHub.
Um exemplo de análise de sentimentos em Pythonimport collections import nltk import os from sklearn import ( datasets, model_selection, feature_extraction, linear_model ) def extract_features(corpus): '''Extract TF-IDF features from corpus'''
A análise desses exemplos é um desafio separado para o desenvolvedor.
Apenas 45 linhas de código e 4 (quatro, Karl!) Blocos lógicos de uma só vez:
- Fazendo Download de Dados para o Treinamento do Modelo (Linhas 25 a 26)
- Preparando dados carregados - extração de recursos (linhas 31 a 34)
- Criando e treinando um modelo (linhas 36-39)
- Testando um modelo treinado e produzindo resultados (linhas 41-45)
Cada um desses pontos merece um artigo separado. E certamente requer registro em um módulo separado. Pelo menos para as necessidades de teste de unidade.
Separadamente, vale destacar os componentes da preparação de dados e do treinamento do modelo.
Em cada uma das maneiras de tornar o modelo mais preciso, são investidas centenas de horas de trabalho científico e de engenharia.
Felizmente, para iniciar rapidamente a PNL, existe uma solução pronta - as
bibliotecas NLTK e
TextBlob . O segundo é um invólucro sobre o NLTK que realiza a tarefa - extrai os recursos do conjunto de treinamento e treina o modelo na primeira solicitação de classificação.
Mas antes de treinar o modelo, você precisa preparar dados para ele.
Preparando dados
Baixar dados
Se falamos sobre o protótipo, o carregamento de dados de um arquivo CSV / TSV é elementar. Você simplesmente chama a função
read_csv da biblioteca do pandas:
import pandas as pd data = pd.read_csv(data_path, delimiter)
Mas não haverá dados prontos para uso no modelo.
Primeiro, se ignorarmos um pouco o formato csv, é fácil esperar que cada fonte forneça dados com suas próprias características e, portanto, precisamos de algum tipo de preparação de dados dependentes da fonte. Mesmo no caso mais simples de um arquivo CSV, para analisá-lo, precisamos conhecer o delimitador.
Além disso, você deve determinar quais entradas são positivas e quais são negativas. Obviamente, essas informações são indicadas na anotação dos conjuntos de dados que queremos usar. Mas o fato é que, em um caso, o sinal de pos / neg é 0 ou 1, no outro, é um True / False lógico, no terceiro, é apenas uma sequência de pos / neg e, em alguns casos, uma tupla de números inteiros de 0 a 5 O último é relevante para o caso da classificação multiclasse, mas quem disse que esse conjunto de dados não pode ser usado para classificação binária? Você só precisa identificar adequadamente a fronteira de valores positivos e negativos.
Eu gostaria de experimentar o modelo em diferentes conjuntos de dados, e é necessário que, após o treinamento, o modelo retorne o resultado em um único formato. E, para isso, deve trazer seus dados heterogêneos para um único formulário.
Portanto, existem três funções que precisamos no estágio de carregamento de dados:
- A conexão com a fonte de dados é para CSV; no nosso caso, é implementada dentro da função read_csv;
- Suporte para recursos de formato;
- Preparação preliminar de dados.
É assim que parece no código.
import numpy as np
Foi
criada a classe
CsvSentimentDataLoader , que no construtor passa o caminho para csv, o separador, os nomes do texto e os atributos de classificação, além de uma lista de valores que aconselham o valor positivo do texto.
O carregamento em si ocorre no método
load_data .
Dividimos os dados em conjuntos de teste e treinamento
Ok, carregamos os dados, mas ainda precisamos dividi-los nos conjuntos de treinamento e teste.
Isso é feito com a função
train_test_split da biblioteca
sklearn . Essa função pode receber muitos parâmetros como entrada, determinando como exatamente esse conjunto de dados será dividido em treinamento e teste. Esses parâmetros afetam significativamente os conjuntos de treinamento e teste resultantes e provavelmente será conveniente criar uma classe (vamos chamá-lo de SimpleDataSplitter) que gerenciará esses parâmetros e agregará a chamada a esta função.
from sklearn.model_selection import train_test_split
Agora, essa classe inclui a implementação mais simples, que, quando dividida, levará em conta apenas um parâmetro - a porcentagem de registros que devem ser tomados como um conjunto de testes.
Conjuntos de dados
Para treinar o modelo, usei conjuntos de dados disponíveis gratuitamente no formato CSV:
E para torná-lo ainda mais conveniente, para cada um dos conjuntos de dados, criei uma classe que carrega dados do arquivo CSV correspondente e os divide em conjuntos de treinamento e teste.
import os import collections import logging from web.data.loaders import CsvSentimentDataLoader from web.data.splitters import SimpleDataSplitter, TdIdfDataSplitter log = logging.getLogger() class AmazonAlexaDataset(): def __init__(self): self.file_path = os.path.normpath(os.path.join(os.path.dirname(__file__), 'amazon_alexa/train.tsv')) self.delim = '\t' self.text_attr = 'verified_reviews' self.rate_attr = 'feedback' self.pos_rates = [1] self.data = None self.train = None self.test = None def load_data(self): loader = CsvSentimentDataLoader(self.file_path, self.delim, self.text_attr, self.rate_attr, self.pos_rates) splitter = SimpleDataSplitter(self.text_attr, self.rate_attr, test_part_size=.3) self.data = loader.load_data() x_train, x_test, y_train, y_test = splitter.split_data(self.data) self.train = [x for x in zip(x_train, y_train)] self.test = [x for x in zip(x_test, y_test)]
Sim, para o carregamento de dados, resultou um pouco mais de 5 linhas de código no exemplo original.
Mas agora é possível criar novos conjuntos de dados manipulando fontes de dados e algoritmos de preparação de conjuntos de treinamento.
Além disso, componentes individuais são muito mais convenientes para testes de unidade.
Treinamos o modelo
O modelo está aprendendo há algum tempo. E isso deve ser feito uma vez, no início do aplicativo.
Para esses fins, foi criado um pequeno invólucro que permite fazer o download e preparar dados, além de treinar o modelo no momento da inicialização do aplicativo.
class TextBlobWrapper(): def __init__(self): self.log = logging.getLogger() self.is_model_trained = False self.classifier = None def init_app(self): self.log.info('>>>>> TextBlob initialization started') self.ensure_model_is_trained() self.log.info('>>>>> TextBlob initialization completed') def ensure_model_is_trained(self): if not self.is_model_trained: ds = SentimentLabelledDataset() ds.load_data()
Primeiro, obtemos dados de treinamento e teste, depois realizamos a extração e, finalmente, treinamos o classificador e verificamos a precisão no conjunto de testes.
Teste
Na inicialização, obtemos um log, julgando pelo qual, os dados foram baixados e o modelo foi treinado com sucesso. E treinado com muito boa precisão (para iniciantes) - 0,8878.
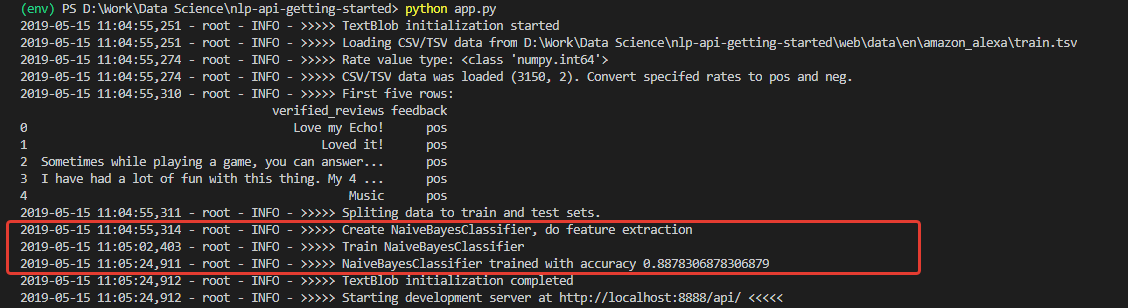
Tendo recebido esses números, fiquei muito entusiasmado. Mas minha alegria, infelizmente, não foi longa. O modelo treinado neste conjunto é um otimista impenetrável e, em princípio, não é capaz de reconhecer comentários negativos.
A razão para isso está nos dados do conjunto de treinamento. O número de críticas positivas no conjunto é superior a 90%. Consequentemente, com uma precisão de modelo de cerca de 88%, as análises negativas simplesmente caem nos 12% esperados de classificações incorretas.
Em outras palavras, com esse conjunto de treinamento, é simplesmente impossível treinar o modelo para reconhecer comentários negativos.
Para ter certeza disso, fiz um teste de unidade que executa a classificação separadamente para 100 frases positivas e 100 negativas de outro conjunto de dados - para o teste, fiz o
Conjunto de Dados de Sentenças Rotuladas de Sentimentos da Universidade da Califórnia.
@loggingtestcase.capturelogs(None, level='INFO') def test_classifier_on_separate_set(self, logs): tb = TextBlobWrapper() # Going to be trained on Amazon Alexa dataset ds = SentimentLabelledDataset() # Test dataset ds.load_data() # Check poisitives true_pos = 0 data = ds.data.to_numpy() seach_mask = np.isin(data[:, 1], ['pos']) data = data[seach_mask][:100] for e in data[:]: # Model train will be performed on first classification call r = tb.do_sentiment_classification(e[0]) if r == e[1]: true_pos += 1 self.assertLessEqual(true_pos, 100) print(str.format('\n\nTrue Positive answers - {} of 100', true_pos))
O algoritmo para testar a classificação de valores positivos é o seguinte:
- Faça o download dos dados de teste;
- Take 100 posts tagged 'pos'
- Executamos cada um deles através do modelo e contamos o número de resultados corretos
- Exiba o resultado final no console.
Da mesma forma, é feita uma contagem para comentários negativos.
Como esperado, todos os comentários negativos foram reconhecidos como positivos.
E se você treinar o modelo no conjunto de dados usado para o teste -
Sentiment Labeled ? Lá, a distribuição de comentários negativos e positivos é exatamente de 50 a 50.
Mude o código e teste, execute Algo já. A precisão real de 200 entradas de um conjunto de terceiros é de 76%, enquanto a precisão da classificação de comentários negativos é de 79%.
Obviamente, 76% servirão como protótipo, mas não o suficiente para a produção. Isso significa que serão necessárias medidas adicionais para melhorar a precisão do algoritmo. Mas este é um tópico para outro relatório.
Sumário
Primeiramente, obtivemos um aplicativo com uma dúzia de classes e mais de 200 linhas de código, o que é um pouco mais que o exemplo original em 30 linhas. E você deve ser honesto - essas são apenas dicas da estrutura, o primeiro esclarecimento dos limites da futura aplicação. Protótipo.
E esse protótipo tornou possível perceber até que ponto a distância entre as abordagens do código é do ponto de vista dos especialistas em Machine Learning e do ponto de vista dos desenvolvedores de aplicativos tradicionais. E essa, na minha opinião, é a principal dificuldade dos desenvolvedores que decidem experimentar o aprendizado de máquina.
A próxima coisa que pode colocar um iniciante em um estupor - os dados não são menos importantes que o modelo selecionado. Isso foi claramente mostrado.
Além disso, sempre existe a possibilidade de que um modelo treinado em alguns dados se mostre inadequado em outros, ou em algum momento sua precisão comece a se degradar.
Consequentemente, são necessárias métricas para monitorar o estado do modelo, flexibilidade ao trabalhar com dados, recursos técnicos para ajustar o aprendizado em tempo real. E assim por diante
Quanto a mim, tudo isso deve ser levado em consideração ao projetar a arquitetura e construir processos de desenvolvimento.
Em geral, o "buraco do coelho" não era apenas muito profundo, mas também extremamente inteligente. Mas ainda mais interessante para mim, como desenvolvedor, estudar este tópico no futuro.