
Há três anos, escrevi
um artigo sobre a biblioteca DI para a linguagem Swift. A partir desse momento, a biblioteca mudou muito e se tornou o
melhor concorrente digno de Swinject, superando-o em muitos aspectos. O artigo é dedicado aos recursos da biblioteca, mas também possui considerações teóricas. Então, quem está interessado nos tópicos de DI, DIP, IoC ou que faz uma escolha entre Swinject e Swinject, peço um corte:
O que é DIP, IoC e com o que ele come?
Teoria de DIP e IoC
A teoria é um dos componentes mais importantes da programação. Sim, você pode escrever código sem educação, mas, apesar disso, os programadores leem constantemente os artigos, estão interessados em várias práticas, etc. Ou seja, de uma forma ou de outra, obtenho conhecimento teórico para colocá-lo em prática.
Um dos tópicos que as pessoas gostam de pedir entrevistas é o
SOLID . Nenhum artigo não é sobre ele, não se assuste. Mas precisamos de uma letra, pois está intimamente relacionada à minha biblioteca. Esta é a letra `D` - Princípio da inversão de dependência.
O Princípio de Inversão de Dependência declara:
- Os módulos de nível superior não devem depender dos módulos de nível inferior. Ambos os tipos de módulos devem depender de abstrações.
- As abstrações não devem depender dos detalhes. Os detalhes devem depender de abstrações.
Muitas pessoas assumem erroneamente que, se usam protocolos / interfaces, aderem automaticamente a esse princípio, mas isso não é inteiramente verdade.
A primeira declaração diz algo sobre dependências entre módulos - os módulos devem depender de abstrações. Espere, o que é abstração? - É melhor se perguntar não o que é abstração, mas o que é abstração? Ou seja, você precisa entender qual é o processo e o resultado desse processo será uma abstração.
A abstração é uma distração no processo de cognição de partes não essenciais, propriedades e relacionamentos, a fim de destacar sinais regulares e essenciais.
O mesmo objeto, dependendo dos objetivos, pode ter abstrações diferentes. Por exemplo, a máquina do ponto de vista do proprietário possui as seguintes propriedades importantes: cor, elegância, conveniência. Mas, do ponto de vista do mecânico, tudo é um pouco diferente: marca, modelo, modificação, quilometragem, participação em um acidente. Duas abstrações diferentes para um objeto acabam de ser nomeadas - a máquina.
Observe que no Swift é habitual usar protocolos para abstrações, mas isso não é um requisito. Ninguém se preocupa em criar uma classe, alocar um conjunto de métodos públicos a partir dela e deixar os detalhes da implementação privados. Em termos de abstração, nada está quebrado. Devemos lembrar a importante tese - “a abstração não está ligada à linguagem” - este é um processo que acontece constantemente em nossa mente, e como isso é transferido para o código não é tão importante. Aqui também podemos mencionar o
encapsulamento , como um exemplo do que está associado ao idioma. Cada idioma tem seus próprios meios para fornecê-lo. No Swift, são classes, campos de acesso e protocolos; em interfaces Obj-C, protocolos e separação de arquivos he m.
a segunda afirmação é mais interessante, pois é ignorada ou mal compreendida. Ele fala sobre a interação de abstrações com detalhes, e o que são detalhes? Há um equívoco de que os detalhes são classes que implementam protocolos - sim, isso é verdade, mas não está completo. Você precisa entender que os detalhes não estão vinculados às linguagens de programação - a linguagem C não possui protocolos nem classes, mas esse princípio também atua. É difícil para mim explicar teoricamente qual é o problema, então darei dois exemplos e depois tentarei provar por que o segundo exemplo é mais correto.
Suponha que exista um carro de classe e um motor de classe. Aconteceu que precisamos conectá-los - a máquina contém um mecanismo. Nós, como programadores competentes, selecionamos o mecanismo de protocolo, implementamos o protocolo e passamos a implementação do protocolo para a classe da máquina. Tudo parece estar bom e correto - agora você pode substituir facilmente a implementação do mecanismo e não pensar que algo irá quebrar. Em seguida, um mecânico de motor é adicionado ao circuito. Ele está interessado no motor com características completamente diferentes do carro. Estamos expandindo o protocolo e agora ele contém um conjunto maior de recursos do que inicialmente. A história é repetida para o proprietário do carro, para a fábrica de motores, etc.
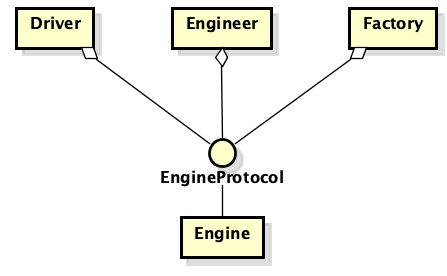
Mas onde está o erro de raciocínio? O problema é que a conexão descrita, apesar da disponibilidade de protocolos, é na verdade um "detalhe" - um "detalhe". Mais precisamente, em que nome e onde o protocolo está localizado o mecanismo.
Agora considere a outra opção
correta .
Como antes, existem duas classes - motor e carro. Como antes, eles devem estar conectados. Mas agora estamos anunciando o protocolo "Car Engine" ou "Heart of a Car". Colocamos nele apenas as características que o carro precisa do motor. E colocamos o protocolo não próximo à implementação do "mecanismo", mas ao lado da máquina. Além disso, se precisarmos de um mecânico, precisaremos criar outro protocolo e implementá-lo no mecanismo. Parece que nada mudou, mas a abordagem é radicalmente diferente - a questão não está tanto nos nomes, mas em quem os protocolos pertencem e o que é o protocolo - uma “abstração” ou um “detalhe”.
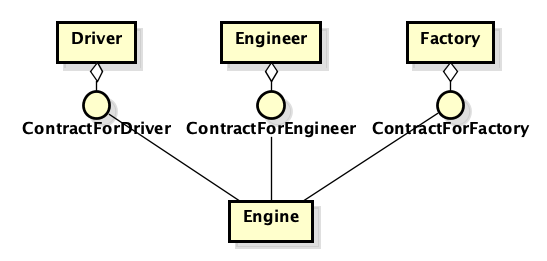
Agora vamos fazer uma analogia com outro caso, pois esses argumentos podem não ser óbvios.
Há um back-end e algumas funcionalidades são necessárias. O back-end fornece um método amplo que contém um monte de dados e diz: "você precisa desses 3 campos em 1000"
Pequena históriaMuitos podem dizer que isso não acontece. E eles estarão relativamente certos - acontece que o back-end é escrito separadamente para o aplicativo móvel. Aconteceu que eu trabalhei para uma empresa em que o back-end é um serviço com um histórico de 10 anos que, entre outras coisas, está vinculado à API do estado. Por muitas razões, não era costume a empresa escrever um método separado para o celular, e eu tive que usar o que era. E havia um método maravilhoso com cerca de cem parâmetros na raiz, e alguns deles eram dicionários aninhados. Agora imagine 100 parâmetros, dos quais 20% têm parâmetros aninhados, e dentro de cada um aninhado existem outros 20 a 30 parâmetros que têm o mesmo aninhamento. Não me lembro exatamente, mas o número de parâmetros excedeu 800 para objetos simples e, para objetos complexos, pode ser maior que 1000.
Não parece muito bom, certo? Normalmente, o back-end grava um método para tarefas específicas para o front-end, e o front-end é o cliente / usuário desses métodos. Hmm ... Mas se você pensar bem, o back-end é o motor e o front-end é o carro - a máquina precisa de algumas características do motor, e não o motor precisa receber as características do carro. Então, por que, apesar disso, continuamos a escrever o protocolo Engine e a colocá-lo mais perto da implementação do mecanismo, e não da máquina? É tudo uma questão de escala - na maioria dos programas iOS, é muito raro expandir tanto a funcionalidade que essa solução se torna um problema.
E então o que é DI
Há uma substituição de conceitos - DI não é uma abreviação de DIP, mas uma abreviação completamente diferente, apesar do fato de que ela se cruza muito de perto com o DIP. DI é uma injeção de dependência ou injeção de dependência, não Inversão. A inversão fala sobre como as classes e os protocolos devem interagir entre si, e a implementação mostra de onde obtê-los. Em geral, você pode implementá-lo de várias maneiras - começando de onde vêm as dependências: construtor, propriedade, método; terminando com quem os cria e como esse processo é automatizado. As abordagens são diferentes, mas, na minha opinião, as mais convenientes são os contêineres para injeção de dependência. Em resumo, todo o seu significado se resume a uma regra simples: dizemos ao contêiner onde e como implementá-lo e, depois disso, tudo é implementado de forma independente. Essa abordagem corresponde à “implementação real de dependências” - é quando as classes nas quais as dependências são incorporadas não sabem nada sobre como isso acontece, ou seja, são passivas.
Em muitos idiomas, a seguinte abordagem é usada para esta implementação: Em classes / arquivos individuais, as regras de implementação são descritas usando a sintaxe do idioma, após o que são compiladas e implementadas automaticamente. Não há mágica - nada acontece automaticamente, apenas as bibliotecas estão intimamente integradas aos meios básicos da linguagem e sobrecarregam os métodos de criação. Portanto, para Swift / Obj-C, geralmente é aceito que o ponto de partida é o UIViewController, e as bibliotecas podem se integrar facilmente ao ViewController criado a partir do Storyboard. É verdade que, se você não usar o Storyboard, precisará fazer parte do trabalho com canetas.
Ah, sim, eu quase esqueci - a resposta para a pergunta principal: "por que precisamos disso?" Sem dúvida, você pode cuidar da injeção de dependência, prescrever tudo com canetas. Mas surgem problemas quando os gráficos se tornam grandes - você precisa mencionar muitas conexões entre classes, o código começa a crescer muito. Portanto, as bibliotecas que implementam automaticamente dependências recursivamente (e mesmo ciclicamente) cuidam desse cuidado e, como bônus, controlam sua vida útil. Ou seja, a biblioteca não faz nada além do natural - simplesmente simplifica a vida do desenvolvedor. É verdade, não pense que você pode escrever uma biblioteca desse tipo em um dia - uma coisa é escrever com caneta todas as dependências de um caso específico, outra é ensinar um computador a implementar universal e corretamente.
História da biblioteca
A história não estaria completa se eu não a contasse brevemente. Se você seguir a biblioteca da versão beta, não será tão interessante para você, mas para quem a vê pela primeira vez, acho que vale a pena entender como ela apareceu e quais objetivos o autor seguiu (ou seja, eu).
A biblioteca foi meu segundo projeto, que eu decidi, para fins de auto-educação, escrever em Swift. Antes disso, consegui escrever um criador de logs, mas não o enviei para o domínio público - é cada vez melhor.
Mas com DI, a história é mais interessante. Quando comecei a fazer isso, consegui encontrar apenas uma biblioteca no Swift - Swinject. Naquela época, ela tinha 500 estrelas e erros que os ciclos normalmente não são processados. Eu olhei para tudo isso e ... Meu comportamento é melhor descrito pela minha frase favorita “E então Ostap sofreu” - eu passei por 5-6 idiomas, olhei o que há nessas línguas, li artigos sobre esse tópico e percebi que isso pode ser melhor. E agora, depois de quase três anos, posso dizer com confiança que o objetivo foi alcançado, no momento o DITranquillity é o melhor da minha visão de mundo.
Vamos entender o que é uma boa biblioteca de DI:
- Deve fornecer todas as implementações básicas: construtor, propriedades, métodos
- Não deve afetar o código comercial.
- Ela deve descrever claramente o que deu errado.
- Ela deve entender com antecedência onde há erros, não no tempo de execução.
- Ele deve ser integrado às ferramentas básicas (Storyboard)
- Deve ter uma sintaxe concisa e concisa.
- Ela deve fazer tudo de forma rápida e eficiente.
- (Opcional) Deve ser hierárquico
É a esses princípios que tento aderir ao longo do desenvolvimento da biblioteca.
Recursos e benefícios da biblioteca
Primeiro, um link para o repositório:
github.com/ivlevAstef/DITranquillityA principal vantagem competitiva, que é bastante importante para mim, é que a biblioteca fala sobre erros de inicialização. Após iniciar o aplicativo e chamar a função desejada, todos os problemas, existentes e potenciais, serão relatados. Esse é precisamente o significado do nome da biblioteca “calmo” - na verdade, após o início do programa, a biblioteca garante que todas as dependências necessárias existirão e que não há ciclos insolúveis. Em lugares onde há ambiguidade, a biblioteca avisa que pode haver problemas em potencial.
Parece ótimo para mim. Não há falhas durante a execução do programa; se o programador esqueceu alguma coisa, isso será imediatamente relatado.
Uma função de log é usada para descrever os problemas, que eu recomendo usar. O registro possui 4 níveis: erro, aviso, informações, detalhado. Os três primeiros são bastante importantes. O último não é tão importante - ele escreve tudo o que acontece - qual objeto foi registrado, qual objeto começou a ser introduzido, qual objeto foi criado etc.
Mas isso não é tudo o que a biblioteca possui:
- Segurança total da linha - qualquer operação pode ser feita a partir de qualquer linha e tudo funcionará. A maioria das pessoas não precisa disso; portanto, em termos de segurança de threads, foi realizado um trabalho para otimizar a velocidade da execução. Mas a biblioteca do concorrente, apesar das promessas, cai se você começar a se registrar e receber um objeto ao mesmo tempo
- Rápida velocidade de execução. Em um dispositivo real, o DITranquillity é duas vezes mais rápido que seu concorrente. Verdadeiro no simulador, a velocidade de execução é quase equivalente. Link de teste
- Tamanho pequeno - a biblioteca pesa menos que Swinject + SwinjectStoryboad + SwinjectAutoregistration, mas supera esse pacote de recursos
- Uma nota concisa e concisa, embora viciante
- Hierarquia. Para projetos grandes, que consistem em vários módulos, essa é uma vantagem muito grande, pois a biblioteca é capaz de encontrar as classes necessárias à distância do módulo atual. Ou seja, se você possui sua própria implementação de um protocolo em cada módulo, em cada módulo você obterá a implementação desejada sem fazer nenhum esforço
Demonstração
E então vamos começar. Como última vez que o projeto será considerado:
SampleHabr . Especificamente, não comecei a mudar o exemplo - para que você possa comparar como tudo mudou. E o exemplo exibe muitos recursos da biblioteca.
Por precaução, para que não haja mal-entendidos, uma vez que o projeto está em exibição, ele usa muitos recursos. Mas ninguém se preocupa em usar a biblioteca de maneira simplificada - baixou, criou um contêiner, registrou algumas classes, usa o contêiner.
Primeiro, precisamos criar uma estrutura (opcional):
public class AppFramework: DIFramework {
E no início do programa, crie seu próprio contêiner, com a adição desta estrutura:
let container = DIContainer()
Storyboard
Em seguida, você precisa criar uma tela básica. Normalmente, os Storyboards são usados para isso, e neste exemplo eu vou usá-lo, mas ninguém se incomoda em usar UIViewControllers.
Para começar, precisamos registrar um Storyboard. Para fazer isso, crie uma "parte" (opcional - você pode escrever todo o código na estrutura) com o Storyboard registrado nela:
import DITranquillity class AppPart: DIPart { static func load(container: DIContainer) { container.registerStoryboard(name: "Main", bundle: nil) .lifetime(.single)
E adicione uma peça ao AppFramework:
container.append(part: AppPart.self)
Como você pode ver, a biblioteca possui uma sintaxe conveniente para registrar o Storyboard, e eu recomendo usá-lo. Em princípio, você pode escrever um código equivalente sem esse método, mas será maior e não poderá oferecer suporte ao StoryboardReferences. Ou seja, este Storyboard não funcionará de outro.
Agora, a única coisa que resta é criar um Storyboard e mostrar a tela inicial. Isso é feito no AppDelegate, após verificar o contêiner:
window = UIWindow(frame: UIScreen.main.bounds)
Criar um Storyboard usando uma biblioteca não é muito mais complicado que o normal. Neste exemplo, o nome pode ser perdido, já que temos apenas um Storyboard - a biblioteca imaginaria que você o tinha em mente. Mas em alguns projetos existem muitos Storyboards, então não perca o nome novamente.
Apresentador e ViewController
Vá para a própria tela. Não carregaremos o projeto com arquiteturas complexas, mas usaremos o MVP usual. Além disso, sou tão preguiçoso que não vou criar um protocolo para um apresentador. O protocolo será um pouco mais tarde para outra classe, aqui é importante mostrar como registrar e vincular o Presenter e o ViewController.
Para fazer isso, adicione o seguinte código ao AppPart:
container.register(YourPresenter.init) container.register(YourViewController.self) .injection(\.presenter)
Essas três linhas nos permitirão registrar duas classes e estabelecer uma conexão entre elas.
Pessoas curiosas podem se perguntar - por que a sintaxe que Swinject possui em uma biblioteca separada é a principal no projeto? A resposta está nos objetivos - graças a essa sintaxe, a biblioteca armazena todos os links antecipadamente, em vez de calculá-los em tempo de execução. Essa sintaxe fornece acesso a muitos recursos que não estão disponíveis para outras bibliotecas.
Iniciamos o aplicativo e tudo funciona, todas as classes são criadas.
Dados
Bem, agora precisamos adicionar uma classe e um protocolo para receber dados do servidor:
public protocol Server { func get(method: String) -> Data? } class ServerImpl: Server { init(domain: String) { ... } func get(method: String) -> Data? { ... } }
E, por beleza, criaremos uma classe DI ServerPart separada para o servidor, na qual a registramos. Deixe-me lembrá-lo de que isso não é necessário e pode ser registrado diretamente no contêiner, mas não estamos procurando maneiras fáceis :)
import DITranquillity class ServerPart: DIPart { static func load(container: DIContainer) { container.register{ ServerImpl(domain: "https:
Nesse código, nem tudo é tão transparente quanto nos anteriores e requer esclarecimentos. Primeiramente, dentro do registro da função, uma classe é criada com um parâmetro passado.
Em segundo lugar, existe a função `as` - diz que a classe será acessível por outro tipo - o protocolo. O final estranho desta operação na forma de `{$ 0}` faz parte do nome `check:`. Ou seja, esse código garante que o ServerImpl seja um sucessor do Server. Mas há outra sintaxe: `as (Server.self)` que fará o mesmo, mas sem verificar. Para ver o que o compilador produzirá nos dois casos, você pode remover a implementação do protocolo.
Pode haver várias funções `as` - isso significa que o tipo está disponível por qualquer um desses nomes. Chamo a atenção de que este será um registro, o que significa que, se a classe for um singleton, a mesma instância estará disponível para qualquer tipo especificado.
Em princípio, se você deseja se proteger da possibilidade de criar uma classe por tipo de implementação, ou ainda não se acostumou a essa sintaxe, pode escrever:
container.register{ ServerImpl(domain: "https://github.com/") as Server }
O que será equivalente, mas sem a capacidade de especificar vários tipos separados.
Agora você pode implementar o servidor no Presenter. Para isso, corrigiremos o Presenter para que ele aceite o servidor:
class YourPresenter { init(server: Server) { ... } }
Iniciamos o programa e ele recai sobre as funções `validate` no AppDelegate, com a mensagem de que o tipo` Server` não foi encontrado, mas é exigido pelo `YourPresenter`. O que houve? Observe que o erro ocorreu no início da execução do programa, e não um pós-factum. E o motivo é bem simples - eles esqueceram de adicionar `ServerPart` ao` AppFramework`:
container.append(part: ServerPart.self)
Começamos - tudo funciona.
Logger
Antes disso, havia um conhecimento de oportunidades que não são muito impressionantes e muitas têm. Agora haverá uma demonstração de que outras bibliotecas no Swift não sabem como.
Um
projeto separado foi criado no logger.
Primeiro, vamos entender o que será um logger. Para fins educacionais, não faremos um sistema complicado, portanto o criador de logs é um protocolo com um método e várias implementações:
public protocol Logger { func log(_ msg: String) } class ConsoleLogger: Logger { func log(_ msg: String) { ... } } class FileLogger: Logger { init(file: String) { ... } func log(_ msg: String) { ... } } class ServerLogger: Logger { init(server: String) { ... } func log(_ msg: String) { ... } } class MainLogger: Logger { init(loggers: [Logger]) { ... } func log(_ msg: String) { ... } }
Total, temos:
- Protocolo público
- 3 implementações diferentes de registrador, cada uma das quais grava em um local diferente
- Um registrador central que chama a função de registro para todos os outros
O projeto criou `LoggerFramework` e` LoggerPart`. Não escreverei o código deles, mas escreverei apenas as partes internas do `LoggerPart`:
container.register{ ConsoleLogger() } .as(Logger.self) .lifetime(.single) container.register{ FileLogger(file: "file.log") } .as(Logger.self) .lifetime(.single) container.register{ ServerLogger(server: "http://server.com/") } .as(Logger.self) .lifetime(.single) container.register{ MainLogger(loggers: many($0)) } .as(Logger.self) .default() .lifetime(.single)
Já vimos os três primeiros registros, e o último levanta questões.
Um parâmetro é passado para a entrada. Um similar já foi mostrado quando o apresentador foi criado, embora houvesse um registro abreviado - o método `init` foi usado apenas, mas ninguém se incomoda em escrever assim:
container.register { YourPresenter(server: $0) }
Se houvesse vários parâmetros, seria possível usar `$ 1`,` $ 2`, `$ 3` etc. até 16.
Mas este parâmetro chama a função `many`. E aqui começa a diversão. Existem dois modificadores `many` e` tag` na biblioteca.
Texto ocultoExiste um terceiro modificador `arg`, mas não é seguro
O modificador `many` diz que você precisa obter todos os objetos correspondentes ao tipo desejado. Nesse caso, o protocolo Logger é esperado; portanto, todas as classes herdadas desse protocolo serão encontradas e criadas, com uma exceção - a própria, ou seja, recursivamente. Ele não será criado durante a inicialização, embora possa fazer isso com segurança quando implementado por meio de uma propriedade.
A tag, por sua vez, é um tipo separado que deve ser especificado durante o uso e durante o registro. Ou seja, as tags são critérios adicionais se não houver tipos básicos suficientes.
Você pode ler mais sobre isso:
ModificadoresA presença de modificadores, especialmente `many`, torna a biblioteca melhor que outras. Por exemplo, você pode implementar o padrão Observador em um nível completamente diferente. Devido a essas quatro letras, no projeto foi possível remover 30 a 50 linhas de código de cada Observador no projeto e resolver o problema com a pergunta - onde e quando os objetos deveriam ser adicionados ao Observável. Negócios claros não são a única aplicação, mas são significativos.
Bem, terminaremos a apresentação dos recursos introduzindo um criador de logs no YourPresenter:
container.register(YourPresenter.init) .injection { $0.logger = $1 }
Aqui, por exemplo, está escrito um pouco diferente do que antes - isso é feito para um exemplo de sintaxe diferente.
Observe que a propriedade logger é opcional:
internal var logger: Logger?
E isso não aparece na sintaxe da biblioteca. Diferentemente da primeira versão, agora todas as operações para o tipo usual, opcional e opcional forçado têm a mesma aparência. Além disso, a lógica interna é diferente - se o tipo for opcional e não estiver registrado no contêiner, o programa não falhará, mas continuará a execução.
Sumário
Os resultados são semelhantes à última vez, apenas a sintaxe se tornou mais curta e mais funcional.
O que foi revisado:
O que mais a biblioteca pode fazer:
Planos
Antes de tudo, está planejado mudar para a verificação do gráfico no estágio de compilação - ou seja, maior integração com o compilador. Há uma implementação preliminar usando o SourceKitten, mas essa implementação tem sérias dificuldades com a inferência de tipo; portanto, está planejado mudar para ast-dump - no swift5, ele começou a trabalhar em grandes projetos. Quero agradecer aqui a
Nekitosss pela enorme contribuição nessa direção.
Em segundo lugar, eu gostaria de integrar os serviços de visualização. Este será um projeto um pouco diferente, mas intimamente relacionado à biblioteca. Qual é o objetivo? Agora a biblioteca armazena todo o gráfico de conexões, ou seja, em teoria, tudo o que é registrado na biblioteca pode ser mostrado como um diagrama de classe / componente UML. E seria bom ver esse diagrama algumas vezes.
Essa funcionalidade é planejada em duas partes - a primeira parte permitirá adicionar uma API para obter todas as informações e a segunda já é integração com vários serviços.
A opção mais simples é exibir um gráfico de links na forma de texto, mas eu não vi opções legíveis - se assim for, sugira opções nos comentários.
WatchOS - Eu mesmo não escrevo projetos para eles. Por sua vida, ele escreveu apenas uma vez e depois pequeno. Mas eu gostaria de fazer uma forte integração, como no Storyboard.
Isso é tudo, obrigado por sua atenção. Eu realmente espero por comentários e respostas para a pesquisa.
Sobre mimIvlev Alexander Evgenievich - líder sênior / equipe da equipe do iOS. Trabalho no comércio há 7 anos, no iOS 4,5 anos - antes eu era desenvolvedor de C ++. Mas a experiência total em programação é de mais de 15 anos - na escola, conheci esse mundo incrível e fiquei tão empolgado que houve um período em que troquei jogos , comida, banheiro, um sonho para escrever código. De acordo com um dos meus artigos, você pode adivinhar que eu sou uma antiga Olimpíada - portanto, não foi difícil para mim escrever um trabalho competente com gráficos. Especialidade - sistemas de medição de informações e, ao mesmo tempo, fui obcecado por multithreading e paralelismo - sim, escrevo códigos nos quais faço suposições e erros em tópicos semelhantes, mas entendo as áreas problemáticas e entendo perfeitamente onde você pode negligenciar o mutex e onde não vale a pena.