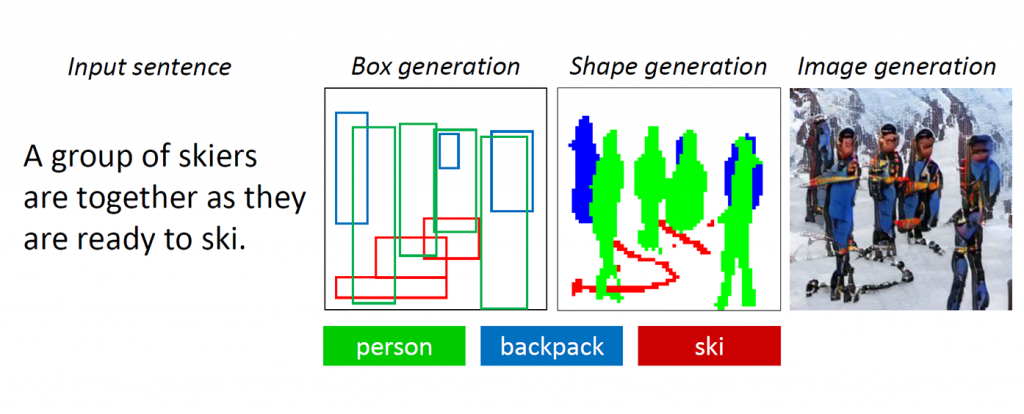
Se lhe pedissem para desenhar uma imagem de várias pessoas em equipamento de esqui, de pé na neve, é provável que você comece com um esboço de três ou quatro pessoas posicionadas razoavelmente no centro da tela, depois esboce nos esquis sob suas pés. Embora não tenha sido especificado, você pode optar por adicionar uma mochila a cada um dos esquiadores para combinar com as expectativas sobre o que os esquiadores estariam usando. Por fim, você preenche cuidadosamente os detalhes, talvez pintando suas roupas de azul, de cachecóis cor de rosa, tudo contra um fundo branco, tornando essas pessoas mais realistas e garantindo que os arredores correspondam à descrição. Finalmente, para tornar a cena mais vívida, você pode até desenhar em algumas pedras marrons projetadas na neve para sugerir que esses esquiadores estão nas montanhas.
Agora há um bot que pode fazer tudo isso.
A nova tecnologia de IA desenvolvida no Microsoft Research AI pode entender uma descrição de linguagem natural, esboçar um layout da imagem, sintetizar a imagem e refinar detalhes com base no layout e nas palavras individuais fornecidas. Em outras palavras, esse bot pode gerar imagens a partir de descrições de texto semelhantes às legendas das cenas do dia a dia. Esse mecanismo deliberado produziu um aumento significativo na qualidade da imagem gerada em comparação com a técnica mais avançada anterior para geração de texto em imagem para cenas cotidianas complicadas, de acordo com os resultados dos testes padrão da indústria relatados em “ Text-driven Text-driven síntese de imagem por meio de treinamento adverso ”, a ser publicado este mês em Long Beach, Califórnia, na Conferência IEEE de 2019 sobre visão computacional e reconhecimento de padrões (CVPR 2019). Este é um projeto de colaboração entre Pengchuan Zhang , Qiuyuan Huang e Jianfeng Gao da Microsoft Research AI , Lei Zhang da Microsoft, Xiaodong He da JD AI Research e Wenbo Li e Siwei Lyu da Universidade de Albany, SUNY (enquanto Wenbo Li trabalhou como estagiário na Microsoft Research AI).
Existem dois principais desafios intrínsecos ao problema do bot de desenho baseado em descrição. A primeira é que muitos tipos de objetos podem aparecer nas cenas cotidianas e o bot deve ser capaz de entender e desenhar todos eles. Os métodos de geração de texto para imagem anteriores usam pares de legenda de imagem que fornecem apenas um sinal de supervisão de granulação muito grossa para gerar objetos individuais, limitando sua qualidade de geração de objetos. Nesta nova tecnologia, os pesquisadores usam o conjunto de dados COCO que contém rótulos e mapas de segmentação para 1,5 milhão de instâncias de objetos em 80 classes de objetos comuns, permitindo que o bot aprenda o conceito e a aparência desses objetos. Esse sinal supervisionado de baixa granularidade para geração de objetos melhora significativamente a qualidade da geração para essas classes de objetos comuns.
O segundo desafio está na compreensão e geração dos relacionamentos entre vários objetos em uma cena. Foi obtido grande sucesso na geração de imagens que contêm apenas um objeto principal para vários domínios específicos, como rostos, pássaros e objetos comuns. No entanto, gerar cenas mais complexas contendo vários objetos com relacionamentos semanticamente significativos entre esses objetos continua sendo um desafio significativo na tecnologia de geração de texto em imagem. Esse novo bot de desenho aprendeu a gerar o layout de objetos a partir de padrões de co-ocorrência no conjunto de dados COCO para gerar uma imagem condicionada no layout pré-gerado.
Geração de imagem atenta e orientada a objetos
No centro do desenho bot da Microsoft Research AI está uma tecnologia conhecida como Generative Adversarial Network, ou GAN. O GAN consiste em dois modelos de aprendizado de máquina - um gerador que gera imagens a partir de descrições de texto e um discriminador que usa descrições de texto para julgar a autenticidade das imagens geradas. O gerador tenta obter imagens falsas além do discriminador; o discriminador, por outro lado, nunca quer ser enganado. Trabalhando juntos, o discriminador empurra o gerador para a perfeição.
O bot de desenho foi treinado em um conjunto de dados de 100.000 imagens, cada uma com rótulos de objetos salientes e mapas de segmentação e cinco legendas diferentes, permitindo que os modelos concebessem objetos individuais e relações semânticas entre objetos. O GAN, por exemplo, aprende como um cachorro deve ser ao comparar imagens com e sem descrições de cães.

Figura 1: Uma cena complexa com vários objetos e relacionamentos.
Os GANs funcionam bem ao gerar imagens contendo apenas um objeto saliente, como um rosto humano, pássaros ou cães, mas a qualidade fica estagnada com cenas cotidianas mais complexas, como a descrita como “Uma mulher usando capacete está montando um cavalo” (consulte a Figura 1.) Isso ocorre porque essas cenas contêm vários objetos (mulher, capacete, cavalo) e ricas relações semânticas entre eles (capacete de mulher, cavalo de passeio). O bot deve primeiro entender esses conceitos e colocá-los na imagem com um layout significativo. Depois disso, é necessário um sinal mais supervisionado capaz de ensinar a geração de objetos e a geração de layout para cumprir esta tarefa de compreensão de linguagem e geração de imagem.
À medida que os humanos desenham essas cenas complicadas, primeiro decidimos sobre os principais objetos a serem desenhados e fazemos um layout colocando caixas delimitadoras para esses objetos na tela. Em seguida, focamos em cada objeto, verificando repetidamente as palavras correspondentes que descrevem esse objeto. Para capturar essa característica humana, os pesquisadores criaram o que chamavam de GAN atento a objetos, ou ObjGAN, para modelar matematicamente o comportamento humano da atenção centrada no objeto. O ObjGAN faz isso dividindo o texto de entrada em palavras individuais e combinando essas palavras com objetos específicos na imagem.
Os seres humanos geralmente conferem dois aspectos para refinar o desenho: o realismo de objetos individuais e a qualidade dos patches de imagem. O ObjGAN também imita esse comportamento introduzindo dois discriminadores - um discriminador em termos de objetos e um discriminador em termos de patch. O discriminador em termos de objeto está tentando determinar se o objeto gerado é realista ou não e se o objeto é consistente com a descrição da sentença. O discriminador em relação ao patch está tentando determinar se esse patch é realista ou não e se esse patch é consistente com a descrição da sentença.
Trabalho relacionado: visualização de histórias
Modelos de geração de texto em imagem de última geração podem gerar imagens realistas de pássaros com base em uma descrição de frase única. No entanto, a geração de texto em imagem pode ir muito além da síntese de uma única imagem com base em uma frase. Em " StoryGAN: um GAN condicional seqüencial para visualização de histórias ", Jianfeng Gao, da Microsoft Research, junto com Zhe Gan, Jingjing Liu e Yu Cheng, do Microsoft Dynamics 365 AI Research, Yitong Li, David Carlson e Lawrence Carin, da Universidade Duke, Yelong Shen. da Tencent AI Research e Yuexin Wu, da Universidade Carnegie Mellon, dão um passo adiante e propõem uma nova tarefa, chamada Visualização de Histórias. Dado um parágrafo com várias frases, uma história completa pode ser visualizada, gerando uma sequência de imagens, uma para cada frase. Essa é uma tarefa desafiadora, pois o bot de desenho não é apenas necessário para imaginar um cenário adequado à história, modelar as interações entre os diferentes personagens que aparecem na história, mas também deve ser capaz de manter a consistência global entre cenas e personagens dinâmicos. Esse desafio não foi enfrentado por nenhum método de geração de imagem ou vídeo.
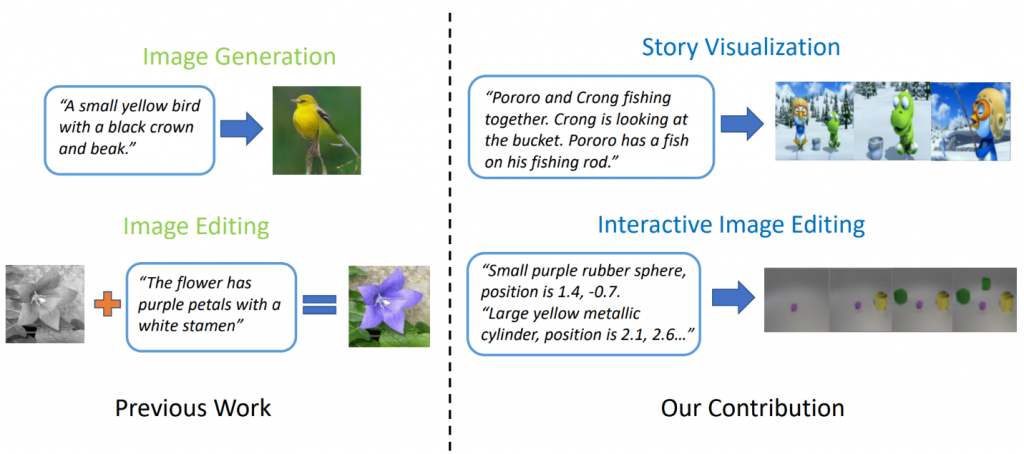
Figura 2: Visualização da história vs. geração simples de imagens.
Os pesquisadores criaram um novo modelo de geração de história para imagem-sequência, StoryGAN, baseado na estrutura GAN condicional seqüencial. Esse modelo é único, pois consiste em um codificador de contexto profundo que rastreia dinamicamente o fluxo da história e em dois discriminadores nos níveis da história e da imagem para melhorar a qualidade da imagem e a consistência das seqüências geradas. O StoryGAN também pode ser estendido naturalmente para edição interativa de imagens, onde uma imagem de entrada pode ser editada sequencialmente com base nas instruções de texto. Nesse caso, uma sequência de instruções do usuário servirá como entrada da "história". Dessa forma, os pesquisadores modificaram os conjuntos de dados existentes para criar os conjuntos de dados CLEVR-SV e Pororo-SV, conforme mostrado na Figura 2.
Aplicações práticas - uma história real
A tecnologia de geração de texto em imagem pode encontrar aplicações práticas que funcionam como uma espécie de assistente de esboço para pintores e designers de interiores, ou como uma ferramenta para edição de fotos ativada por voz. Com mais poder computacional, os pesquisadores imaginam a tecnologia que gera filmes de animação baseados em roteiros, aumentando o trabalho que os realizadores fazem removendo parte do trabalho manual envolvido.
Por enquanto, as imagens geradas ainda estão longe da foto realista. Objetos individuais quase sempre revelam falhas, como rostos desfocados e / ou ônibus com formas distorcidas. Essas falhas são uma indicação clara de que um computador, não um humano, criou as imagens. No entanto, a qualidade das imagens ObjGAN é significativamente melhor do que as melhores imagens GAN anteriores da categoria e serve como um marco no caminho em direção a uma inteligência genérica e humana que aumenta as capacidades humanas.
Para IAs e humanos compartilharem o mesmo mundo, cada um deve ter uma maneira de interagir com o outro. Linguagem e visão são as duas modalidades mais importantes para humanos e máquinas interagirem entre si. A geração de texto para imagem é uma tarefa importante que promove a pesquisa de inteligência multimodal com visão de linguagem.
Os pesquisadores que criaram este trabalho emocionante esperam compartilhar essas descobertas com os participantes da CVPR em Long Beach e ouvir o que você pensa. Enquanto isso, fique à vontade para conferir o código-fonte aberto do ObjGAN e StoryGAN no GitHub