Neste artigo, mostrarei como abordamos a questão da tolerância a falhas do PostgreSQL, por que isso se tornou importante para nós e o que aconteceu no final.
Temos um serviço altamente carregado: 2,5 milhões de usuários em todo o mundo, mais de 50 mil usuários ativos todos os dias. Os servidores estão localizados na Amazone em uma região da Irlanda: existem constantemente mais de 100 servidores diferentes em operação, dos quais quase 50 estão com bancos de dados.
Todo o back-end é um grande aplicativo Java com estado monolítico que mantém uma conexão constante de websocket com o cliente. Com o trabalho simultâneo de vários usuários em um quadro, todos eles veem as alterações em tempo real, porque registramos cada alteração no banco de dados. Temos aproximadamente 10 mil consultas por segundo em nossos bancos de dados. No pico de carga no Redis, escrevemos de 80 a 100 mil consultas por segundo.

Por que mudamos de Redis para PostgreSQL
Inicialmente, nosso serviço trabalhava com o Redis, um repositório de valores-chave que armazena todos os dados na RAM do servidor.
Prós da Redis:
- Alta taxa de resposta, como tudo é armazenado na memória;
- Conveniência de backup e replicação.
Contras Redis for us:
- Não há transações reais. Tentamos simulá-los no nível do nosso aplicativo. Infelizmente, isso nem sempre funcionou bem e exigiu a criação de código muito complexo.
- A quantidade de dados é limitada pela quantidade de memória. À medida que a quantidade de dados aumenta, a memória aumenta e, no final, encontraremos as características da instância selecionada, que na AWS exige a interrupção de nosso serviço para alterar o tipo de instância.
- É necessário manter constantemente um baixo nível de latência, pois Temos um número muito grande de solicitações. O nível de atraso ideal para nós é de 17 a 20 ms. No nível de 30 a 40 ms, obtemos respostas longas para as solicitações de nosso aplicativo e a degradação do serviço. Infelizmente, isso aconteceu conosco em setembro de 2018, quando uma das instâncias do Redis, por algum motivo, recebeu uma latência 2 vezes maior que o normal. Para resolver o problema, paramos o serviço no meio do dia para manutenção não programada e substituímos a instância problemática do Redis.
- É fácil obter inconsistência de dados, mesmo com pequenos erros no código, e gastar muito tempo escrevendo código para corrigir esses dados.
Levamos em conta as desvantagens e percebemos que precisamos mudar para algo mais conveniente, com transações normais e menos dependência da latência. Realizou um estudo, analisou muitas opções e escolheu o PostgreSQL.
Estamos mudando para um novo banco de dados há 1,5 anos e transferimos apenas uma pequena parte dos dados. Agora, estamos trabalhando simultaneamente com Redis e PostgreSQL. Mais informações sobre os estágios da movimentação e troca de dados entre bancos de dados estão escritas em um
artigo do meu colega .
Quando começamos a nos mover, nosso aplicativo trabalhava diretamente com o banco de dados e recorria ao assistente Redis e PostgreSQL. O cluster do PostgreSQL consistia em um mestre e uma réplica de réplica assíncrona. É assim que o esquema de operação do banco de dados ficou:
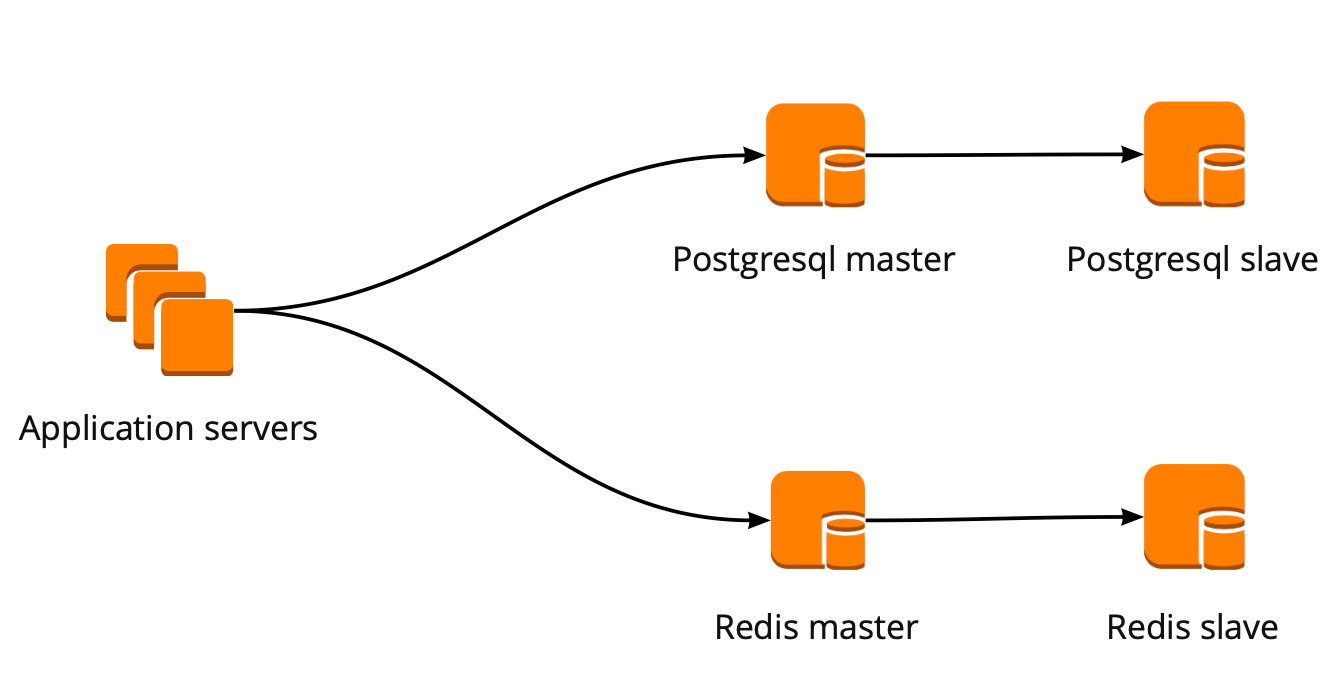
Implantação do PgBouncer
Enquanto estávamos em movimento, o produto também se desenvolveu: o número de usuários e o número de servidores que trabalhavam com o PostgreSQL aumentaram, e começamos a perder conexões. O PostgreSQL cria um processo separado para cada conexão e consome recursos. Você pode aumentar o número de conexões até um determinado ponto; caso contrário, há uma chance de obter uma operação não ideal do banco de dados. A opção ideal nessa situação seria a escolha de um gerenciador de conexões que ficará na frente da base.
Tínhamos duas opções para o gerenciador de conexões: Pgpool e PgBouncer. Mas o primeiro não suporta o modo transacional de trabalhar com o banco de dados, por isso escolhemos o PgBouncer.
Configuramos o seguinte esquema de trabalho: nosso aplicativo acessa um PgBouncer, seguido pelo Masters PostgreSQL e, por trás de cada mestre, uma réplica com replicação assíncrona.

Ao mesmo tempo, não podíamos armazenar toda a quantidade de dados no PostgreSQL, e a velocidade de trabalho com o banco de dados era importante para nós, por isso começamos a compartilhar o PostgreSQL no nível do aplicativo. O esquema descrito acima é relativamente conveniente para isso: ao adicionar um novo shard PostgreSQL, basta atualizar a configuração do PgBouncer e o aplicativo pode trabalhar imediatamente com o novo shard.
Tolerância a falhas do PgBouncer
Esse esquema funcionou até a única instância do PgBouncer morrer. Estamos localizados na AWS, onde todas as instâncias são executadas em hardware que morre periodicamente. Nesses casos, a instância simplesmente muda para o novo hardware e funciona novamente. Isso aconteceu com o PgBouncer, mas ficou indisponível. O resultado dessa queda foi a inacessibilidade de nosso serviço por 25 minutos. A AWS recomenda o uso de redundância no lado do usuário para essas situações, que não foram implementadas conosco naquele momento.
Depois disso, pensamos seriamente na tolerância a falhas dos clusters PgBouncer e PostgreSQL, porque uma situação semelhante poderia acontecer novamente com qualquer instância em nossa conta da AWS.
Criamos o esquema de tolerância a falhas do PgBouncer da seguinte maneira: todos os servidores de aplicativos acessam o Network Load Balancer, atrás do qual existem dois PgBouncer. Cada um dos PgBouncer analisa o mesmo mestre PostgreSQL de cada fragmento. Se a instância da AWS travar novamente, todo o tráfego será redirecionado por outro PgBouncer. Tolerância a falhas O Network Load Balancer fornece a AWS.
Este esquema permite adicionar facilmente novos servidores PgBouncer.

Criando um cluster de failover do PostgreSQL
Para solucionar esse problema, consideramos diferentes opções: failover auto-escrito, repmgr, AWS RDS, Patroni.
Scripts auto-escritos
Eles podem monitorar o trabalho do mestre e, em caso de queda, promover a réplica para o mestre e atualizar a configuração do PgBouncer.
As vantagens dessa abordagem são a simplicidade máxima, porque você mesmo escreve scripts e entende exatamente como eles funcionam.
Contras:
- O mestre pode não morrer, mas pode ocorrer uma falha na rede. O failover, sem saber isso, avançará a réplica para o mestre e o antigo mestre continuará funcionando. Como resultado, temos dois servidores na função de mestre e não sabemos qual deles possui os dados reais mais recentes. Essa situação também é chamada de cérebro dividido;
- Ficamos sem uma réplica. Em nossa configuração, a réplica principal e uma, depois de alternar a réplica, ela se move para a principal e não temos mais réplicas; portanto, precisamos adicionar manualmente uma nova réplica;
- Precisamos de monitoramento adicional da operação de failover, enquanto temos 12 shards PostgreSQL, o que significa que devemos monitorar 12 clusters. Se você aumentar o número de shards, ainda deverá se lembrar de atualizar o failover.
O failover auto-escrito parece muito complicado e requer suporte não trivial. Com um único cluster do PostgreSQL, essa será a opção mais fácil, mas não será dimensionada, portanto, não é adequada para nós.
Repmgr
Replication Manager para clusters do PostgreSQL, que podem gerenciar a operação de um cluster do PostgreSQL. Ao mesmo tempo, não há failover automático "pronto para uso", portanto, para o trabalho, você precisará escrever seu próprio "invólucro" sobre a solução finalizada. Portanto, tudo pode ficar ainda mais complicado do que com scripts auto-escritos, então nem tentamos o Repmgr.
AWS RDS
Ele suporta tudo o que você precisa para nós, sabe como fazer backup e suporta um pool de conexões. Possui comutação automática: após a morte do mestre, a réplica se torna o novo mestre e a AWS altera o registro de DNS para o novo mestre, enquanto as réplicas podem estar em AZs diferentes.
As desvantagens incluem a falta de configurações sutis. Como um exemplo de ajuste fino: em nossas instâncias existem restrições para conexões tcp, que, infelizmente, não podem ser feitas no RDS:
net.ipv4.tcp_keepalive_time=10 net.ipv4.tcp_keepalive_intvl=1 net.ipv4.tcp_keepalive_probes=5 net.ipv4.tcp_retries2=3
Além disso, o preço do AWS RDS é quase duas vezes superior ao preço da instância regular, que foi o principal motivo para rejeitar essa decisão.
Patroni
Este é um modelo python para gerenciar o PostgreSQL com boa documentação, failover automático e código fonte do github.
Prós de Patroni:
- Cada parâmetro de configuração é pintado, é claro como funciona;
- O failover automático funciona imediatamente;
- Está escrito em python e, como escrevemos muito em python, será mais fácil lidar com problemas e, possivelmente, até ajudar no desenvolvimento do projeto;
- Ele controla totalmente o PostgreSQL, permite alterar a configuração em todos os nós do cluster de uma só vez e, se for necessária uma reinicialização do cluster para aplicar a nova configuração, isso poderá ser feito novamente usando o Patroni.
Contras:
- Na documentação, não está claro como trabalhar com o PgBouncer. Embora seja difícil chamá-lo de menos, porque a tarefa do Patroni é gerenciar o PostgreSQL, e como serão as conexões com o Patroni é nosso problema;
- Existem poucos exemplos de implementação do Patroni em grandes volumes, enquanto muitos exemplos de implementação do zero.
Como resultado, para criar um cluster de failover, escolhemos o Patroni.
Processo de Implementação Patroni
Antes do Patroni, tínhamos 12 shards do PostgreSQL em configuração, um mestre e uma réplica com replicação assíncrona. Os servidores de aplicativos acessaram os bancos de dados através do Network Load Balancer, atrás do qual havia duas instâncias com o PgBouncer, e atrás deles havia todos os servidores PostgreSQL.
Para implementar o Patroni, precisamos selecionar um repositório de configuração de cluster distribuído. Patroni trabalha com sistemas de armazenamento de configuração distribuída, como etcd, Zookeeper, Consul. Temos apenas um cluster de cônsul completo em produtos que funciona em conjunto com o Vault e não o usamos mais. Um ótimo motivo para começar a usar o Consul para a finalidade a que se destina.
Como Patroni trabalha com o Consul
Temos um cluster Consul, que consiste em três nós, e um cluster Patroni, que consiste em um líder e uma réplica (em Patroni, um mestre é chamado líder de cluster e os escravos são chamados réplicas). Cada instância de um cluster Patroni envia constantemente informações de status do cluster ao Consul. Portanto, no Consul você sempre pode descobrir a configuração atual do cluster Patroni e quem é o líder no momento.

Para conectar o Patroni ao Consul, basta estudar a documentação oficial, que diz que você precisa especificar o host no formato http ou https, dependendo de como trabalhamos com o Consul e o esquema de conexão, opcionalmente:
host: the host:port for the Consul endpoint, in format: http(s)://host:port scheme: (optional) http or https, defaults to http
Parece simples, mas aqui começam as armadilhas. Com o Consul, estamos trabalhando em uma conexão segura via https e nossa configuração de conexão ficará assim:
consul: host: https://server.production.consul:8080 verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
Mas isso não funciona. No início, Patroni não pode se conectar ao Consul, porque tenta seguir o http de qualquer maneira.
O código fonte do Patroni ajudou a lidar com o problema. Ainda bem que está escrito em python. Acontece que o parâmetro host não é analisado e o protocolo deve ser especificado no esquema. Aqui está o bloco de configuração de trabalho para trabalhar com a Consul conosco:
consul: host: server.production.consul:8080 scheme: https verify: true cacert: {{ consul_cacert }} cert: {{ consul_cert }} key: {{ consul_key }}
Consul-template
Portanto, escolhemos o armazenamento para uma configuração. Agora você precisa entender como o PgBouncer mudará sua configuração ao alterar o líder no cluster Patroni. A documentação não responde a essa pergunta, porque lá, em princípio, o trabalho com o PgBouncer não é descrito.
Em busca de uma solução, encontramos um artigo (infelizmente não lembro o nome), onde estava escrito que o modelo do Consul ajudou bastante na conexão do PgBouncer e Patroni. Isso nos levou a estudar o trabalho do modelo do cônsul.
Aconteceu que o Consul-template monitora constantemente a configuração do cluster PostgreSQL no Consul. Quando o líder muda, ele atualiza a configuração do PgBouncer e envia um comando para reiniciá-lo.
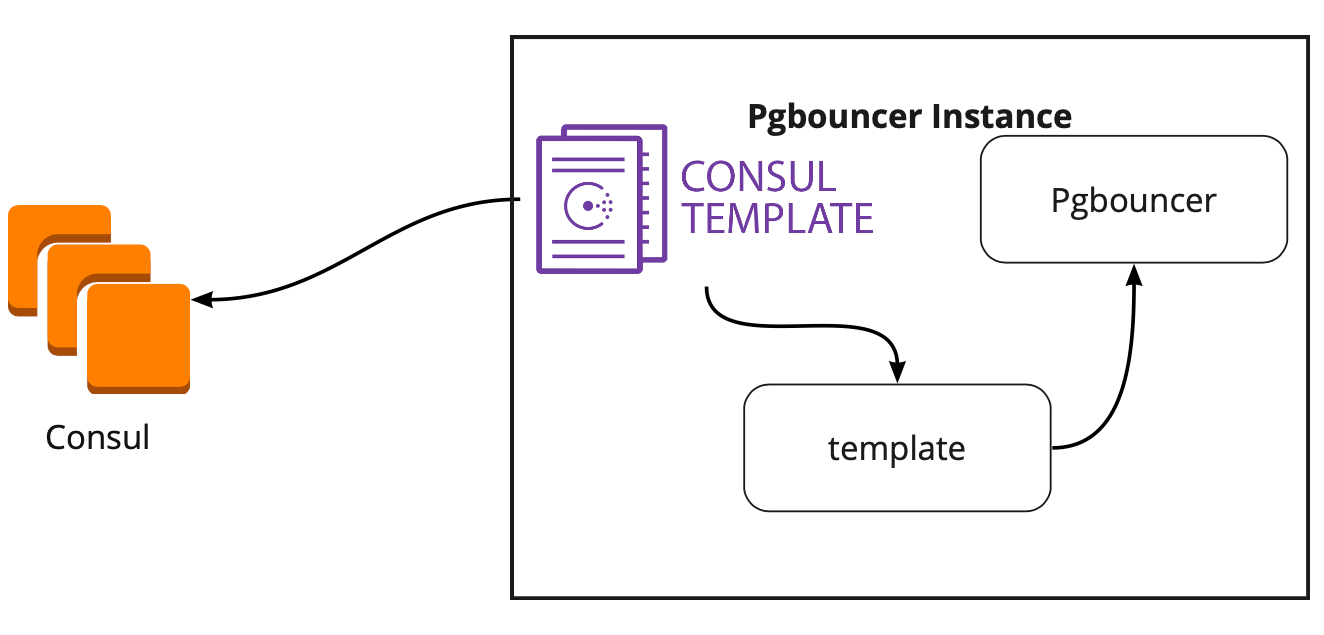
A grande vantagem do modelo é que ele é armazenado como código; portanto, ao adicionar um novo shard, basta fazer uma nova confirmação e atualizar o modelo no modo automático, suportando o princípio de Infraestrutura como código.
Nova arquitetura com Patroni
Como resultado, obtivemos este esquema de trabalho:

Todos os servidores de aplicativos recorrem ao balanceador → duas instâncias do PgBouncer estão por trás dele → em cada instância é iniciado um onsul-template, que monitora o status de cada cluster Patroni e monitora a relevância da configuração do PgBouncer, que envia solicitações ao líder atual de cada cluster.
Teste manual
Antes de iniciar o programa, lançamos esse circuito em um pequeno ambiente de teste e verificamos a operação da comutação automática. Eles abriram o quadro, moveram o adesivo e naquele momento "mataram" o líder do grupo. Na AWS, basta desativar a instância pelo console.

O adesivo retornou de 10 a 20 segundos e começou a se mover normalmente. Isso significa que o cluster Patroni funcionou corretamente: ele mudou o líder, enviou as informações ao Consul e o modelo do Consul imediatamente pegou essas informações, substituiu a configuração do PgBouncer e enviou o comando para recarregar.
Como sobreviver sob alta carga e manter um tempo de inatividade mínimo?
Tudo funciona muito bem! Mas surgem novas questões: como isso funcionará sob alta carga? Como lançar tudo com rapidez e segurança na produção?
O ambiente de teste no qual realizamos o teste de carga nos ajuda a responder à primeira pergunta. É completamente idêntico à produção em arquitetura e gerou dados de teste, que são aproximadamente iguais em volume à produção. Decidimos simplesmente "matar" um dos assistentes do PostgreSQL durante o teste e ver o que acontece. Porém, antes disso, é importante verificar a rolagem automática, porque nesse ambiente temos vários shards do PostgreSQL, para que possamos realizar excelentes testes de scripts de configuração antes da venda.
Ambas as tarefas parecem ambiciosas, mas temos o PostgreSQL 9.6. Talvez possamos atualizar imediatamente para 11.2?
Decidimos fazer isso em duas etapas: primeiro atualize para 11.2 e, em seguida, inicie o Patroni.
Atualização do PostgreSQL
Para atualizar rapidamente a versão do PostgreSQL, você deve usar a opção
-k , que cria um link físico no disco e não é necessário copiar seus dados. Em bases de 300 a 400 GB, a atualização leva 1 segundo.
Como temos muitos shards, a atualização precisa ser feita automaticamente. Para fazer isso, escrevemos o manual do Ansible, que executa todo o processo de atualização para nós:
/usr/lib/postgresql/11/bin/pg_upgrade \ <b>--link \</b> --old-datadir='' --new-datadir='' \ --old-bindir='' --new-bindir='' \ --old-options=' -c config_file=' \ --new-options=' -c config_file='
É importante observar aqui que, antes de iniciar a atualização, é necessário executá-la com o parâmetro
--check para garantir a possibilidade de uma atualização. Nosso script também faz a substituição de configurações pela atualização. O script que concluímos em 30 segundos, é um excelente resultado.
Lançamento Patroni
Para resolver o segundo problema, basta olhar para a configuração do Patroni. No repositório oficial, há um exemplo de configuração com o initdb, responsável por inicializar um novo banco de dados quando o Patroni é iniciado pela primeira vez. Mas como temos um banco de dados pronto, excluímos esta seção da configuração.
Quando começamos a instalar o Patroni em um cluster PostgreSQL pronto e o executamos, enfrentamos um novo problema: os dois servidores começaram como líderes. Patroni não sabe nada sobre o estado inicial do cluster e tenta iniciar os dois servidores como dois clusters separados com o mesmo nome. Para resolver esse problema, exclua o diretório de dados no escravo:
rm -rf /var/lib/postgresql/
Isso deve ser feito apenas no escravo!Ao conectar uma réplica limpa, Patroni cria um líder de base-backup e a restaura na réplica e, em seguida, atualiza o estado atual por wal-logs.
Outra dificuldade que encontramos é que todos os clusters do PostgreSQL são chamados de main por padrão. Quando cada cluster não sabe nada sobre o outro, isso é normal. Mas quando você deseja usar o Patroni, todos os clusters devem ter um nome exclusivo. A solução é alterar o nome do cluster na configuração do PostgreSQL.
Teste de carga
Lançamos um teste que simula o trabalho dos usuários nos painéis. Quando a carga atingiu nosso valor médio diário, repetimos exatamente o mesmo teste, desativamos uma instância com o líder PostgreSQL. O failover automático funcionou como esperávamos: Patroni mudou de líder, o Consul-template atualizou a configuração do PgBouncer e enviou o comando para recarregar. De acordo com nossos gráficos no Grafana, ficou claro que existem atrasos de 20 a 30 segundos e uma pequena quantidade de erros de servidores relacionados à conexão com o banco de dados. Essa é uma situação normal, esses valores são válidos para nosso failover e definitivamente melhores que o tempo de inatividade do serviço.
Produção de Patroni para produção
Como resultado, obtivemos o seguinte plano:
- Implante o Consul-template no servidor PgBouncer e inicie;
- Atualizações do PostgreSQL para a versão 11.2;
- Mudança de nome do cluster;
- Iniciando um cluster Patroni.
Ao mesmo tempo, nosso esquema permite que você faça o primeiro item quase a qualquer momento, podemos revezar a remoção de cada PgBouncer do trabalho e executar uma implantação nele e executar o consul-template. Então nós fizemos.
Para rolagem rápida, usamos o Ansible, pois já checamos todo o manual em um ambiente de teste, e o tempo de execução do script completo foi de 1,5 a 2 minutos para cada fragmento. Poderíamos lançar tudo alternadamente para cada shard sem interromper nosso serviço, mas teríamos que desativar todo PostgreSQL por alguns minutos. Nesse caso, os usuários cujos dados estão nesse fragmento não puderam funcionar totalmente no momento, e isso é inaceitável para nós.
A saída dessa situação foi a manutenção planejada, que ocorre a cada 3 meses. Essa é uma janela para o trabalho agendado quando desligamos completamente o serviço e atualizamos as instâncias do banco de dados. Faltava uma semana para a próxima janela e decidimos esperar e nos preparar. Durante a espera, também asseguramos: para cada shard do PostgreSQL, criamos uma réplica sobressalente em caso de falha para salvar os dados mais recentes e adicionamos uma nova instância para cada shard, que deve se tornar uma nova réplica no cluster Patroni para não executar um comando para excluir dados . Tudo isso ajudou a minimizar o risco de erro.

Reiniciámos o serviço, tudo funcionava como deveria, os usuários continuavam trabalhando, mas nos gráficos notamos uma carga anormalmente alta no servidor Consul.
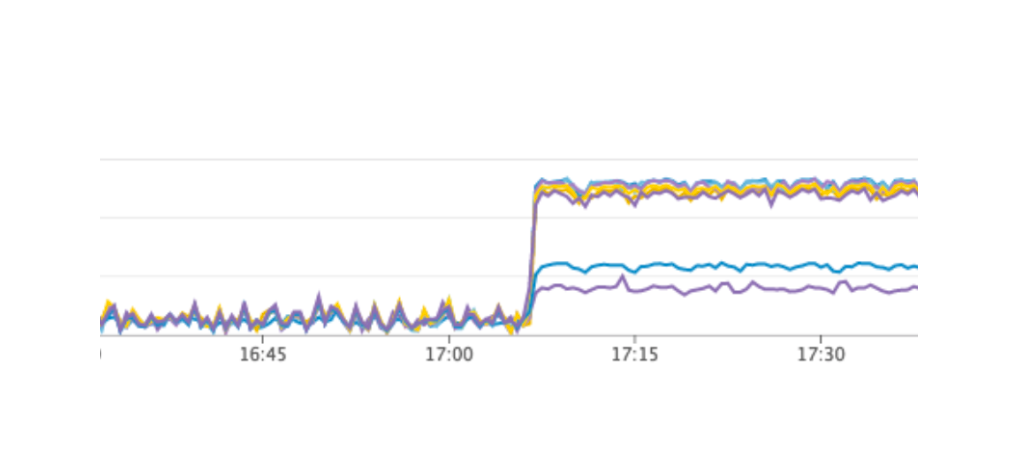
Por que não o vimos no ambiente de teste? Esse problema ilustra muito bem que é necessário seguir o princípio da infraestrutura como código e refinar toda a infraestrutura, iniciando nos ambientes de teste e finalizando na produção. Caso contrário, é muito fácil obter o tipo de problema que temos. O que aconteceu O Consul apareceu pela primeira vez na produção e, em seguida, nos ambientes de teste, como resultado, nos ambientes de teste, a versão do Consul era superior à produção. Apenas em uma das versões, um vazamento de CPU foi resolvido ao trabalhar com o consul-template. Portanto, acabamos de atualizar o Consul, resolvendo o problema.
Reinicie o cluster Patroni
No entanto, temos um novo problema que nem conhecíamos. Ao atualizar o Consul, simplesmente removemos o nó Consul do cluster usando o comando consul leave → Patroni se conecta a outro servidor Consul → tudo funciona. Mas quando chegamos à última instância do cluster Consul e enviamos o comando consul leave para ele, todos os clusters Patroni simplesmente foram reiniciados e, nos logs, vimos o seguinte erro:
ERROR: get_cluster Traceback (most recent call last): ... RetryFailedError: 'Exceeded retry deadline' ERROR: Error communicating with DCS <b>LOG: database system is shut down</b>
O cluster Patroni não pôde obter informações sobre o cluster e foi reiniciado.
Para encontrar uma solução, contatamos os autores do Patroni através da edição no github. Eles sugeriram melhorias nos nossos arquivos de configuração:
consul: consul.checks: [] bootstrap: dcs: retry_timeout: 8
Conseguimos repetir o problema em um ambiente de teste e testamos esses parâmetros lá, mas, infelizmente, eles não funcionaram.
O problema ainda não foi resolvido. Planejamos tentar as seguintes soluções:
- Use o Consul-agent em cada instância do cluster Patroni;
- Corrija o problema no código.
Entendemos o local em que o erro ocorreu: o problema provavelmente está usando o tempo limite padrão, que não é substituído pelo arquivo de configuração. Quando o último servidor Consul é removido do cluster, o cluster Consul inteiro congela por mais de um segundo, por causa disso, o Patroni não pode obter o estado do cluster e reinicia completamente o cluster inteiro.
Felizmente, não encontramos mais nenhum erro.
Resultados do uso de Patroni
Após o lançamento bem-sucedido do Patroni, adicionamos uma réplica adicional em cada cluster. Agora, em cada agrupamento, há um quorum: um líder e duas réplicas - para garantir o caso do cérebro dividido ao mudar.
Patroni trabalha na produção há mais de três meses. Durante esse período, ele já conseguiu nos ajudar. Recentemente, o líder de um dos clusters morreu na AWS, o failover automático funcionou e os usuários continuaram trabalhando. Patroni completou sua tarefa principal.
Um pequeno resumo do uso do Patroni:- Conveniência de modificação de uma configuração. Basta alterar a configuração em uma instância e ela será puxada por todo o cluster. Se for necessária uma reinicialização para aplicar a nova configuração, a Patroni reportará isso. O Patroni pode reiniciar todo o cluster com um único comando, o que também é muito conveniente.
- O failover automático funciona e já conseguiu nos ajudar.
- Atualização do PostgreSQL sem tempo de inatividade do aplicativo. Você deve primeiro atualizar as réplicas para a nova versão, depois alterar o líder no cluster Patroni e atualizar o líder antigo. Nesse caso, o teste necessário do failover automático ocorre.