Os usuários do ClickHouse sabem que sua principal vantagem é a alta velocidade de processamento de consultas analíticas. Mas como podemos fazer essas afirmações? Isso deve ser suportado por testes de desempenho confiáveis. Hoje falaremos sobre eles.
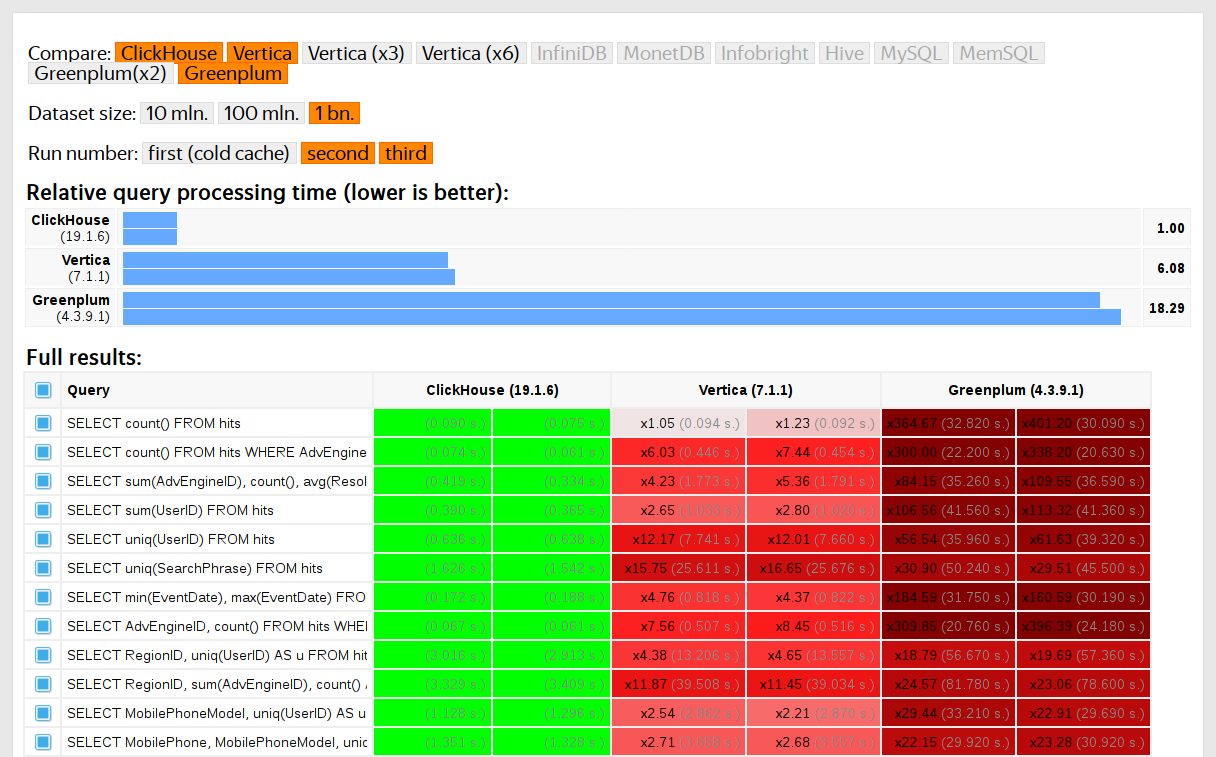
Começamos a realizar esses testes em 2013, muito antes de o produto ficar disponível em código aberto. Como agora, estávamos mais interessados na velocidade do serviço de dados Yandex.Metrica. Já armazenamos dados no ClickHouse desde janeiro de 2009. Parte dos dados foi gravada no banco de dados desde 2012 e parte - foi
convertida do
OLAPServer e Metrage - estruturas de dados que foram usadas no Yandex.Metrica anteriormente. Portanto, para os testes, fizemos o primeiro subconjunto disponível de 1 bilhão de dados de visualização de página. Ainda não havia consultas no Metric, e criamos as consultas que são mais interessantes para nós (todos os tipos de filtragem, agregação e classificação).
O ClickHouse foi testado em comparação com sistemas similares, por exemplo, Vertica e MonetDB. Para ser sincero, foi conduzido por um funcionário que não era desenvolvedor do ClickHouse e casos específicos no código não foram otimizados até que os resultados fossem obtidos. Da mesma forma, obtivemos um conjunto de dados para testes funcionais.
Depois que o ClickHouse entrou no código aberto em 2016, houve mais perguntas para os testes.
Desvantagens dos testes em dados proprietários
Testes de desempenho:
- Eles não são reproduzíveis de fora, porque para executá-los, você precisa de dados particulares que não podem ser publicados. Pelo mesmo motivo, alguns testes funcionais não estão disponíveis para usuários externos.
- Não desenvolva. Há uma necessidade de uma expansão significativa de seu conjunto, para que seja possível verificar de maneira isolada as alterações na velocidade de partes individuais do sistema.
- Eles não executam de forma comprometida as solicitações de pool, os desenvolvedores externos não podem verificar o código quanto à regressão de desempenho.
Você pode resolver esses problemas - faça testes antigos e faça novos com base em dados abertos. Entre os dados abertos, você pode coletar
dados de voos para os EUA , de
táxi em Nova York ou usar os benchmarks prontos TPC-H, TPC-DS,
Star Schema Benchmark . O inconveniente é que esses dados estão longe dos dados do Yandex.Metrica e eu gostaria de salvar as solicitações de teste.
É importante usar dados reais.
Você precisa testar o desempenho do serviço apenas em dados reais da produção. Vejamos alguns exemplos.
Exemplo 1Suponha que você preencha um banco de dados com números pseudo-aleatórios distribuídos igualmente. Nesse caso, a compactação de dados não funcionará. Mas a compactação de dados é uma propriedade importante para DBMSs analíticos. Escolher o algoritmo de compactação correto e a maneira correta de integrá-lo ao sistema é uma tarefa não trivial na qual não existe uma solução correta, porque a compactação de dados requer um compromisso entre a velocidade de compactação e descompactação e a taxa de compactação potencial. Os sistemas que não sabem como compactar dados perdem a garantia. Mas se usarmos números pseudo-aleatórios uniformemente distribuídos para testes, esse fator não será considerado e todos os outros resultados serão distorcidos.
Conclusão: os dados de teste devem ter uma taxa de compressão realista.
Sobre a otimização de algoritmos de compactação de dados no ClickHouse, sobre os quais falei em um
post anterior .
Exemplo 2Vamos nos interessar pela velocidade da consulta SQL:
SELECT RegionID, uniq(UserID) AS visitors FROM test.hits GROUP BY RegionID ORDER BY visitors DESC LIMIT 10
Essa é uma solicitação típica para o Yandex.Metrica. O que é importante para a sua velocidade?
- Como é realizado o GROUP BY ?
- Qual estrutura de dados é usada para calcular a função agregada uniq.
- Quantas RegionIDs diferentes são e quanta RAM cada estado da função uniq requer.
Mas também é muito importante que a quantidade de dados para diferentes regiões seja distribuída de maneira desigual. (Provavelmente, ele é distribuído de acordo com a lei da energia. Criei um gráfico na escala de log-log, mas não tenho certeza.) Quando existem muitas chaves de agregação diferentes, a contagem vai para unidades de bytes. Como obter os dados gerados que possuem todas essas propriedades? Obviamente, é melhor usar dados reais.
Muitos DBMSs implementam uma estrutura de dados HyperLogLog para o cálculo aproximado de COUNT (DISTINCT), mas todos funcionam relativamente mal porque essa estrutura de dados usa uma quantidade fixa de memória. E o ClickHouse possui uma função que usa uma
combinação de três estruturas de dados diferentes , dependendo do tamanho do conjunto.
Conclusão: os dados de teste devem representar as propriedades da distribuição dos valores nos dados - cardinalidade (o número de valores nas colunas) e cardinalidade mútua de várias colunas diferentes.
Exemplo 3Bem, vamos testar o desempenho não do DBMS analítico do ClickHouse, mas de algo mais simples, por exemplo, tabelas de hash. Para tabelas de hash, a escolha da função de hash correta é muito importante. Para std :: unordered_map, é um pouco menos importante, porque é uma tabela de hash baseada em cadeia e um número primo é usado como o tamanho da matriz. Na implementação da biblioteca padrão em gcc e clang, uma função de hash trivial é usada como a função de hash padrão para tipos numéricos. Mas std :: unordered_map não é a melhor opção quando queremos obter velocidade máxima. Ao usar tabelas de hash de endereçamento aberto, a escolha correta da função de hash se torna um fator decisivo e não podemos usar a função de hash trivial.
É fácil encontrar testes de desempenho da tabela de hash em dados aleatórios, sem considerar as funções de hash usadas. Também é fácil encontrar testes de função de hash com ênfase na velocidade de computação e em alguns critérios de qualidade, no entanto, isoladamente das estruturas de dados utilizadas. Mas o fato é que tabelas de hash e HyperLogLog exigem critérios de qualidade diferentes para funções de hash.
Leia mais sobre isso no relatório
"Como as tabelas de hash no ClickHouse são organizadas" . Está um pouco desatualizado, pois não considera
tabelas suíças .
Desafio
Queremos obter os dados para o teste de desempenho por estrutura, o mesmo que os dados do Yandex.Metrica, para os quais todas as propriedades importantes para benchmarks são armazenadas, mas para que nenhum vestígio de visitantes reais do site seja deixado nesses dados. Ou seja, os dados devem ser anonimizados e o seguinte deve ser armazenado:
- taxas de compressão
- cardinalidade (número de valores diferentes),
- cardinalidades mútuas de várias colunas diferentes,
- propriedades de distribuições de probabilidade com as quais você pode simular dados (por exemplo, se acreditamos que as regiões são distribuídas de acordo com uma lei de energia, o expoente - parâmetro de distribuição - para dados artificiais deve ser o mesmo que para real).
E o que é necessário para que os dados tenham uma taxa de compactação semelhante? Por exemplo, se LZ4 for usado, as substrings nos dados binários devem ser repetidas aproximadamente nas mesmas distâncias e as repetições devem ter aproximadamente o mesmo comprimento. Para o ZSTD, uma correspondência de entropia de bytes é adicionada.
O objetivo máximo: disponibilizar uma ferramenta para pessoas externas, com a qual todos podem anonimizar seu conjunto de dados para publicação. Para que depuremos e testemos o desempenho nos dados de outras pessoas semelhantes aos da produção. E eu gostaria que fosse interessante observar os dados gerados.
Esta é uma declaração informal do problema. No entanto, ninguém iria dar uma declaração formal.
Tentativas de resolver
A importância desta tarefa não deve ser exagerada para nós. Na verdade, nunca estava nos planos e ninguém iria fazê-lo. Eu simplesmente não perdi a esperança de que algo surgisse e, de repente, eu teria um bom humor e muitas coisas que poderiam ser adiadas para mais tarde.
Modelos probabilísticos explícitos
A primeira idéia é selecionar uma família de distribuições de probabilidade que a modele para cada coluna da tabela. Em seguida, com base nas estatísticas dos dados, selecione os parâmetros de ajuste do modelo e gere novos dados usando a distribuição selecionada. Você pode usar um gerador de números pseudo-aleatórios com uma semente predefinida para obter um resultado reproduzível.
Para campos de texto, você pode usar cadeias de Markov - um modelo compreensível para o qual você pode fazer uma implementação eficaz.
É verdade que alguns truques são necessários:
- Queremos preservar a continuidade das séries temporais - o que significa que, para alguns tipos de dados, é necessário modelar não o valor em si, mas a diferença entre os vizinhos.
- Para simular a cardinalidade condicional das colunas (por exemplo, que geralmente existem poucos endereços IP por identificador de visitante), você também precisará anotar explicitamente as dependências entre as colunas (por exemplo, para gerar um endereço IP, um hash do identificador de visitante é usado, mas também alguns outros dados pseudo-aleatórios são adicionados).
- Não está claro como expressar a dependência que um visitante, ao mesmo tempo, costuma visitar URLs com domínios correspondentes.
Tudo isso é apresentado na forma de um programa no qual todas as distribuições e dependências são codificadas - o chamado "script C ++". No entanto, os modelos de Markov ainda são calculados a partir da soma das estatísticas, suavização e desbaste usando ruído. Comecei a escrever esse script, mas, por algum motivo, depois que escrevi explicitamente o modelo para dez colunas, de repente ele se tornou insuportavelmente chato. E na tabela de hits no Yandex.Metrica em 2012, havia mais de 100 colunas.
EventTime.day(std::discrete_distribution<>({ 0, 0, 13, 30, 0, 14, 42, 5, 6, 31, 17, 0, 0, 0, 0, 23, 10, ...})(random)); EventTime.hour(std::discrete_distribution<>({ 13, 7, 4, 3, 2, 3, 4, 6, 10, 16, 20, 23, 24, 23, 18, 19, 19, ...})(random)); EventTime.minute(std::uniform_int_distribution<UInt8>(0, 59)(random)); EventTime.second(std::uniform_int_distribution<UInt8>(0, 59)(random)); UInt64 UserID = hash(4, powerLaw(5000, 1.1)); UserID = UserID / 10000000000ULL * 10000000000ULL + static_cast<time_t>(EventTime) + UserID % 1000000; random_with_seed.seed(powerLaw(5000, 1.1)); auto get_random_with_seed = [&]{ return random_with_seed(); };
Essa abordagem da tarefa foi um fracasso. Se eu a abordasse com mais diligência, com certeza o roteiro teria sido escrito.
Vantagens:
Desvantagens:
- a complexidade da implementação,
- a solução implementada é adequada para apenas um tipo de dados.
E eu gostaria de uma solução mais geral - para que possa ser aplicada não apenas aos dados do Yandex.Metrica, mas também para ofuscar outros dados.
No entanto, melhorias são possíveis aqui. Você não pode selecionar modelos manualmente, mas implementar um catálogo de modelos e escolher o melhor dentre eles (melhor ajuste + algum tipo de regularização). Ou talvez você possa usar os modelos de Markov para todos os tipos de campos, e não apenas para texto. Dependências entre dados também podem ser entendidas automaticamente. Para fazer isso, é necessário calcular as
entropias relativas (quantidade relativa de informações) entre as colunas ou, mais simplesmente, as cardinalidades relativas (algo como “quantos valores A diferentes, em média, para um valor B fixo”) para cada par de colunas. Isso deixará claro, por exemplo, que URLDomain é completamente dependente da URL, e não vice-versa.
Mas eu também recusei essa idéia, porque há muitas opções para o que precisa ser levado em consideração e levará muito tempo para ser escrito.
Redes neurais
Eu já disse como essa tarefa é importante para nós. Ninguém sequer pensou em fazer alguma ameaça à sua implementação. Felizmente, o colega Ivan Puzyrevsky trabalhou como professor no HSE e, ao mesmo tempo, estava desenvolvendo o núcleo do YT. Ele perguntou se eu tinha alguma tarefa interessante que pudesse ser oferecida aos alunos como um tópico de diploma. Ofereci-lhe este e ele me garantiu que era adequado. Então, entreguei essa tarefa a uma boa pessoa “da rua” - Sharif Anvardinov (a NDA está assinada para trabalhar com dados).
Ele contou a ele todas as suas idéias, mas, o mais importante, explicou que o problema pode ser resolvido de qualquer maneira. E apenas uma boa opção seria usar as abordagens que eu não entendo: por exemplo, gerar um despejo de dados de texto usando LSTM. Pareceu encorajador graças ao
artigo A eficácia irracional das redes neurais recorrentes , que depois me chamou a atenção.
O primeiro recurso da tarefa é que você precisa gerar dados estruturados, não apenas texto. Não era óbvio se uma rede neural recorrente seria capaz de gerar dados com a estrutura desejada. Existem duas maneiras de resolver isso. O primeiro é usar modelos separados para gerar a estrutura e para o "preenchedor": a rede neural deve gerar apenas valores. Mas essa opção foi adiada para mais tarde, após o que nunca o foram. A segunda maneira é simplesmente gerar um despejo de TSV como texto. A prática demonstrou que, no texto, parte das linhas não corresponde à estrutura, mas essas linhas podem ser descartadas no carregamento.
O segundo recurso - uma rede neural recorrente gera uma sequência de dados, e as dependências nos dados só podem seguir na ordem dessa sequência. Mas, em nossos dados, talvez a ordem das colunas seja revertida em relação às dependências entre elas. Não fizemos nada com esse recurso.
No verão, apareceu o primeiro script Python que gerou dados. À primeira vista, a qualidade dos dados é decente:
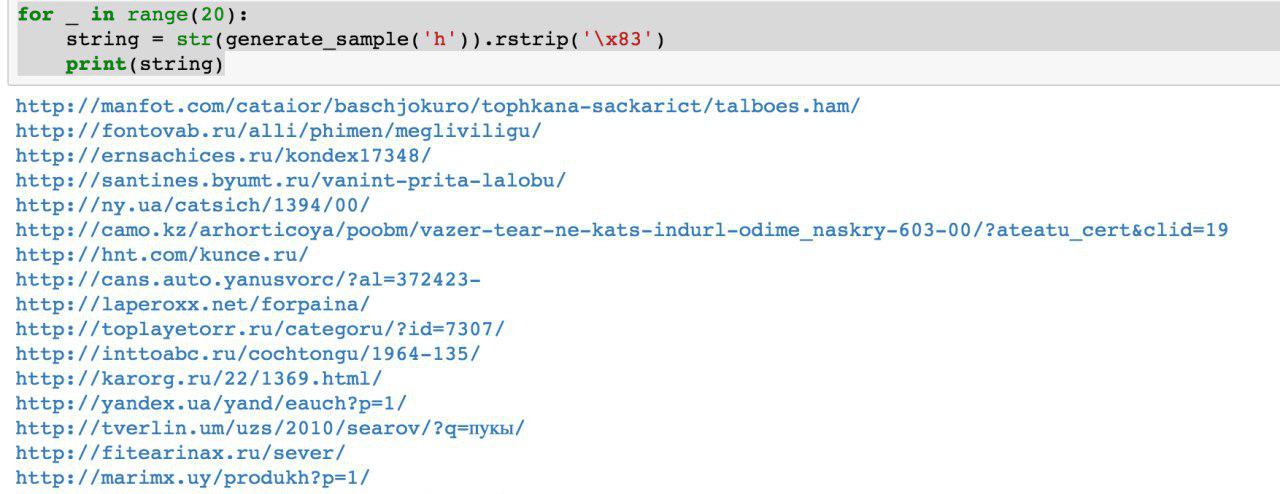
É verdade que as dificuldades foram reveladas:
- O tamanho do modelo é de cerca de um gigabyte. E tentamos criar um modelo para dados cujo tamanho estava na ordem de vários gigabytes (para iniciantes). O fato de o modelo resultante ser tão grande suscita preocupações: repentinamente será possível obter dados reais sobre os quais ele foi treinado. Provavelmente não. Mas eu não entendo aprendizado de máquina e redes neurais e não li o código Python dessa pessoa, então como posso ter certeza? Depois, havia artigos sobre como compactar redes neurais sem perder a qualidade, mas isso foi deixado sem implementação. Por um lado, isso não parece um problema - você pode se recusar a publicar o modelo e publicar apenas os dados gerados. Por outro lado, no caso de reciclagem, os dados gerados podem conter parte dos dados de origem.
- Em uma única máquina com uma CPU, a taxa de geração de dados é de aproximadamente 100 linhas por segundo. Tivemos uma tarefa - gerar pelo menos um bilhão de linhas. O cálculo mostrou que isso não poderia ser feito antes da defesa do diploma. E usar outro hardware não é prático, porque eu tinha um objetivo - disponibilizar a ferramenta de geração de dados para uso amplo.
Sharif tentou estudar a qualidade dos dados comparando estatísticas. Por exemplo, calculei a frequência com que símbolos diferentes aparecem na fonte e nos dados gerados. O resultado foi impressionante - os caracteres mais comuns são Ð e Ñ.
Não se preocupe - ele defendeu seu diploma perfeitamente, depois do qual esquecemos com segurança esse trabalho.
Mutação de dados compactados
Suponha que a declaração do problema seja reduzida a um ponto: você precisa gerar dados para os quais as taxas de compactação serão exatamente iguais aos dados originais, enquanto os dados devem ser expandidos exatamente na mesma velocidade. Como fazer isso? Precisa editar bytes de dados compactados diretamente! Em seguida, o tamanho dos dados compactados não será alterado, mas os dados em si serão alterados. Sim, e tudo funcionará rapidamente. Quando essa ideia apareceu, eu imediatamente quis implementá-la, apesar de resolver outro problema em vez do original. Isso sempre acontece.
Como editar um arquivo compactado diretamente? Suponha que estamos interessados apenas em LZ4. Os dados compactados usando LZ4 consistem em dois tipos de instruções:
- Literais: copie os próximos N bytes como estão.
- Correspondência (correspondência, o tamanho mínimo de repetição é 4): repita N bytes que estavam no arquivo a uma distância de M.
Dados de origem:
Hello world Hello .
Dados compactados (condicionalmente):
literals 12 "Hello world " match 5 12 .
No arquivo compactado, deixe match como está e, nos literais, alteraremos os valores dos bytes. Como resultado, após a descompressão, obtemos um arquivo no qual todas as seqüências repetidas de pelo menos 4 também são repetidas e repetidas nas mesmas distâncias, mas ao mesmo tempo consistem em um conjunto diferente de bytes (falando figurativamente, nenhum byte foi retirado do arquivo original no arquivo modificado )
Mas como mudar bytes? Isso não é óbvio porque, além dos tipos de coluna, os dados também têm sua própria estrutura implícita e interna, que gostaríamos de preservar. Por exemplo, o texto é frequentemente armazenado na codificação UTF-8 - e também queremos UTF-8 válido nos dados gerados. Fiz uma heurística simples para satisfazer várias condições:
- bytes nulos e caracteres de controle ASCII foram armazenados como estão,
- alguma pontuação persistiu,
- O ASCII foi convertido em ASCII e, para o resto, o bit mais significativo foi salvo (ou você pode escrever explicitamente um se configurado para diferentes comprimentos UTF-8). Entre uma classe de bytes, um novo valor é selecionado uniformemente aleatoriamente;
- e também para salvar fragmentos de
https:// e similares, caso contrário, tudo parece muito bobo.
A peculiaridade dessa abordagem é que os próprios dados iniciais atuam como um modelo para os dados, o que significa que o modelo não pode ser publicado. Permite gerar a quantidade de dados não mais do que o original. Para comparação, nas abordagens anteriores, foi possível criar um modelo e gerar uma quantidade ilimitada de dados em sua base.
Exemplo para URL:
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXeAyAx
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwpgafe/klwlpm&qw=962788775I0E7bs7OXe
http://ljc.she/kdoqdqwdffhant.am/wcpoyodjit/cbytjgeoocvdtclac
http://ljc.she/kdoqdqwdbknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu_qxht
http://ljc.she/kdoqdqw-bknvj.s/hmqhpsavon.yf#aortxqdvjja
http://ljc.she/kdoqdqwpdtu-Unu-Rjanjna-bbcohu-702130
O resultado me agradou - foi interessante olhar para os dados. Mas ainda assim, algo estava errado. Os URLs ainda estão estruturados, mas em alguns lugares era fácil adivinhar yandex ou avito. Fez uma heurística que às vezes reorganiza alguns bytes em alguns lugares.
Outras considerações preocupadas. Por exemplo, informações confidenciais podem ser representadas em uma coluna do tipo FixedString em formato binário e, por algum motivo, consistir em caracteres de controle ASCII e pontuação, que decidi salvar. E eu não considero tipos de dados.
Outro problema: se os dados do tipo "comprimento, valor" são armazenados em uma coluna (é assim que as colunas do tipo String são armazenadas), como garantir que o comprimento permaneça correto após a mutação? Quando tentei consertar, a tarefa imediatamente se tornou desinteressante.
Permutações aleatórias
Mas o problema não está resolvido. Realizamos várias experiências, e só piorou. Resta apenas não fazer nada e ler páginas aleatórias na Internet, porque o clima já está estragado. Felizmente, em uma dessas páginas havia uma
análise do algoritmo para renderizar a cena da morte do protagonista no jogo Wolfenstein 3D.

Bela animação - a tela se enche de sangue. O artigo explica que essa é realmente uma permutação pseudo-aleatória. Permutação aleatória - uma transformação individual selecionada aleatoriamente de um conjunto. Ou seja, a exibição de todo o conjunto no qual os resultados para diferentes argumentos não são repetidos. Em outras palavras, essa é uma maneira de iterar todos os elementos de um conjunto em uma ordem aleatória. É esse processo que é mostrado na figura - pintamos sobre cada pixel, selecionados aleatoriamente de todos, sem repetição. Se escolhermos um pixel aleatório a cada passo, levaremos muito tempo para pintar o último.
O jogo usa um algoritmo muito simples para permutação pseudo-aleatória -
LFSR (registro de deslocamento de feedback linear). Como geradores de números pseudo-aleatórios, permutações aleatórias, ou melhor, suas famílias, parametrizadas por uma chave, podem ser criptograficamente fortes - é exatamente isso que precisamos para a conversão de dados. Embora possa haver detalhes não óbvios. Por exemplo, a criptografia criptograficamente forte de N bytes a N bytes com uma chave pré-fixada e o vetor de inicialização, ao que parece, pode ser usada como uma permutação pseudo-aleatória de muitas seqüências de N bytes. De fato, essa transformação é individual e parece aleatória. Mas se usarmos a mesma transformação para todos os nossos dados, o resultado poderá ser analisado, porque o mesmo vetor de inicialização e valores-chave são usados várias vezes. É semelhante ao modo de cifra de bloco do
livro de códigos eletrônico .
Quais são as maneiras de obter uma permutação pseudo-aleatória? Você pode realizar transformações simples e individuais e montar uma função bastante complexa a partir delas que parecerá aleatória. Deixe-me dar um exemplo de algumas das minhas transformações individuais favoritas:
- multiplicação por um número ímpar (por exemplo, um grande primo) na aritmética do complemento de dois,
- xor-shift:
x ^= x >> N , - CRC-N, onde N é o número de bits do argumento.
Assim, por exemplo, a partir de três multiplicações e duas operações xor-shift, o finalizador
murmurhash é
montado . Esta operação é uma permutação pseudo-aleatória. Mas, apenas no caso, observo que as funções de hash, mesmo N bits em N bits, não precisam ser mutuamente exclusivos.
Ou aqui está outro
exemplo interessante
da teoria elementar dos números no site de Jeff Preshing.
Como podemos usar permutações pseudo-aleatórias para nossa tarefa? Você pode converter todos os campos numéricos usando-os. Então será possível preservar todas as cardinalidades e cardinalidades mútuas de todas as combinações de campos. Ou seja, COUNT (DISTINCT) retornará o mesmo valor que antes da conversão e com qualquer GROUP BY.
Vale ressaltar que a preservação de todas as cardinalidades é levemente contrária à afirmação do problema da anonimização dos dados. , , , 10 , . 10 — , . , , , — , , . . , , , Google, , - Google. — , , ( ) ( ). , ,
.
, . , 10, . ?
, size classes ( ). size class , . 0 1 . 2 3 1/2 1/2 . 1024..2047 1024! () . E assim por diante .
, . , -. , .
, , , .
— , . . . Fabien Sanglard c
Hackers News , .
Redis — . ,
.
. — , . , .
- :
arg: xxxxyyyy
arg_l : xxxx
arg_r : yyyy - . xor :
res: yyyyzzzz
res_l = yyyy = arg_r
res_r = zzzz = arg_l ^ F( arg_r )
, F 4 , .
: , , — , , !
. , , , . :
- , , Electronic Codebook mode of operation;
- ( ) , , .
. , LZ4 , , .
, , , . — . , , , . ( , ). ?
-, : , 256^10 10 , , . -, , .
, . , , . , . , - .
, — , N . N — . , N = 5, «» «». Order-N.
P( | ) = 0.9
P( | ) = 0.05
P( | ) = 0.01
.... ( vesna.yandex.ru). LSTM, N, , . — , . : , , .
Title:
— . — , . , , — .@Mail.Ru — — - . ) — AUTO.ria.ua
, , . () , — . 0 N, N N − 1).
. , 123456 URL, . . -. . , .
: URL, , -. :
https://www.yandex.ru/images/cats/?id=xxxxxx . , URL, , . :
http://ftp.google.kz/cgi-bin/index.phtml?item=xxxxxx . - , 8 .
https://www.yandex.ru/ images/c ats/?id=12345
^^^^^^^^
distribution: [aaaa][b][cc][dddd][e][ff][g g ggg][h]...
hash(" images/c ") % total_count: ^
http://ftp.google.kz/c g ..., . :
- | . -
- — .: Lore - dfghf — . - ) 473682 -
- ! » - —
- ! » ,
- . c @Mail.Ru -
- , 2010 | .
- ! : 820 0000 ., -
- - DoramaTv.ru - . - ..
- . 2013 , -> 80 .
- - (. , ,
- . 5, 69, W* - ., , World of Tanks
- , . 2 @Mail.Ru
- , .
Resultado
, - , - . , . clickhouse obfuscator, : (, CSV, JSONEachRow), ( ) ( , ). .
clickhouse-client, Linux. , ClickHouse. , MySQL PostgreSQL , .
clickhouse obfuscator \
--seed "$(head -c16 /dev/urandom | base64)" \
--input-format TSV --output-format TSV \
--structure 'CounterID UInt32, URLDomain String, \
URL String, SearchPhrase String, Title String' \
< table.tsv > result.tsv
clickhouse obfuscator --help
, . , ? , , . , , . , (
--help ) .
, .
clickhouse-datasets.s3.yandex.net/hits/tsv/hits_v1.tsv.xzclickhouse-datasets.s3.yandex.net/visits/tsv/visits_v1.tsv.xzClickHouse. , ClickHouse .