Olá Habr! Meu nome é Sasha e sou desenvolvedor de back-end. No meu tempo livre, estudo ML e me divirto com os dados hh.ru.
Este artigo é sobre como automatizamos o processo de atribuição de tarefas de rotina para testadores que usam aprendizado de máquina.
O Hh.ru possui um serviço interno para o qual as tarefas são criadas no Jira (dentro da empresa, elas são chamadas de HHS) se alguém não trabalhar ou estiver trabalhando incorretamente. Além disso, essas tarefas são tratadas manualmente pelo líder da equipe de controle de qualidade Alexey e atribuídas à equipe cuja área de responsabilidade inclui a falha. Lesha sabe que tarefas chatas devem ser executadas por robôs. Portanto, ele se voltou para mim em busca de ajuda com relação à ML.

O gráfico abaixo mostra a quantidade de HHS por mês. Estamos crescendo e o número de tarefas está aumentando. As tarefas são criadas principalmente durante o horário de trabalho, algumas por dia, e isso deve ser constantemente distraído.
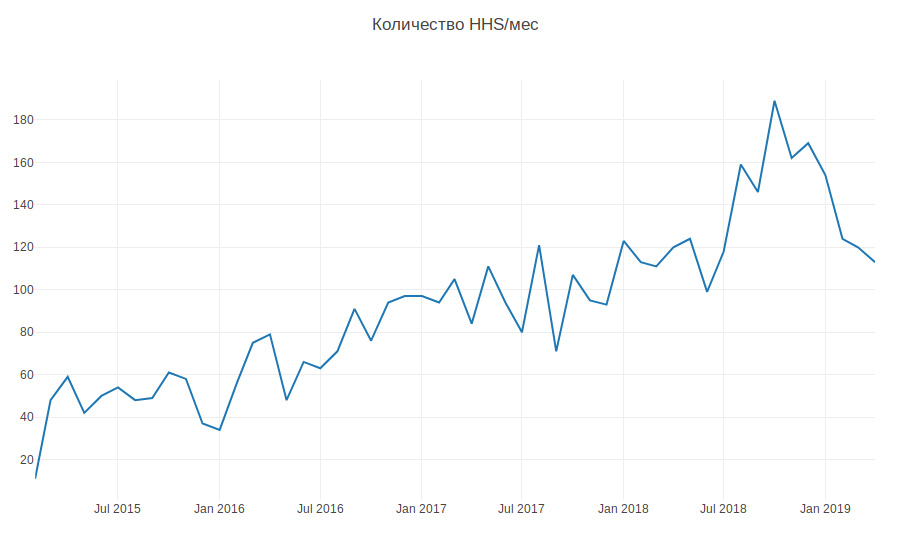
Portanto, de acordo com dados históricos, é necessário aprender a determinar a equipe de desenvolvimento à qual o HHS pertence. Esta é uma tarefa de classificação de várias classes.
Dados
Nas tarefas de aprendizado de máquina, o mais importante são os dados de qualidade. O resultado da solução para o problema depende deles. Portanto, qualquer tarefa de aprendizado de máquina precisa começar com o estudo dos dados. Desde o início de 2015, acumulamos cerca de 7000 tarefas que contêm as seguintes informações úteis:
- Resumo - Título, Descrição Breve
- Descrição - uma descrição completa do problema
- Etiquetas - uma lista de tags relacionadas ao problema
- Reporter é o nome do criador do HHS. Esse recurso é útil porque as pessoas trabalham com um conjunto limitado de funcionalidades.
- Criado - data de criação
- Responsável é a pessoa a quem a tarefa está atribuída. A variável de destino será gerada a partir deste atributo.
Vamos começar com a variável alvo. Em primeiro lugar, cada equipe tem áreas de responsabilidade. Às vezes eles se cruzam, às vezes uma equipe pode se cruzar em desenvolvimento com outra. A decisão será baseada no pressuposto de que o cessionário, que permaneceu com a tarefa no momento do encerramento, é responsável por sua solução. Mas precisamos prever não uma pessoa específica, mas uma equipe. Felizmente, todas as equipes em Jira são mantidas e podem ser mapeadas. Mas existem vários problemas com a definição de uma equipe por pessoa:
- nem todos os HHS estão relacionados a problemas técnicos, e estamos interessados apenas nas tarefas que podem ser atribuídas à equipe de desenvolvimento. Portanto, você precisa executar tarefas em que o responsável não é do departamento técnico
- às vezes as equipes deixam de existir. Eles também são removidos do conjunto de treinamento.
- Infelizmente, as pessoas não trabalham para sempre na empresa e, às vezes, mudam de equipe para equipe. Felizmente, conseguimos obter um histórico de mudanças na composição de todas as equipes. Tendo a data de criação do HHS e do responsável, é possível descobrir qual equipe estava envolvida na tarefa em um horário específico.
Após filtrar dados irrelevantes, a amostra de treinamento foi reduzida para 4900 tarefas.
Vejamos a distribuição de tarefas entre equipes:
As tarefas precisam ser distribuídas entre 22 equipes.
Sinais:
Resumo e Descrição são campos de texto.
Primeiro, eles devem ser limpos de caracteres em excesso. Para algumas tarefas, faz sentido deixar nas linhas caracteres que carregam informações, por exemplo + e #, para distinguir entre c ++ e c #, mas nesse caso eu decidi deixar apenas letras e números, porque não encontrou onde outros caracteres podem ser úteis.
As palavras precisam ser lematizadas. Lematização é a redução de uma palavra a um lema, sua forma normal (vocabulário). Por exemplo, gatos → gato. Eu também tentei stemming, mas com a lematização a qualidade foi um pouco maior. Stamming é o processo de encontrar a base de uma palavra. Esta base é devida ao algoritmo (em diferentes implementações são diferentes), por exemplo, por gatos → gatos. O significado do primeiro e do segundo é justapor as mesmas palavras de formas diferentes. Eu usei o wrapper python para o
Yandex Mystem .
Além disso, o texto deve ser limpo de palavras de parada que não carregam uma carga útil. Por exemplo, "era", "eu", "ainda". Interromper as palavras que normalmente
retiro do
NLTKOutra abordagem que tento nas tarefas de trabalhar com texto é uma fragmentação de palavras baseada em caracteres. Por exemplo, há uma "pesquisa". Se você o dividir em componentes de 3 caracteres, obterá as palavras "poi", "ois", "ação judicial". Isso ajuda a obter conexões adicionais. Suponha que exista a palavra "pesquisar". A lematização não leva a "pesquisar" e "pesquisar" de uma forma geral, mas uma partição de 3 caracteres destacará a parte comum - "reivindicação".
Eu fiz dois tokens. O tokenizador é um método que recebe texto na entrada e a saída contém uma lista de tokens - os componentes do texto. O primeiro destaca palavras e números lematizados. O segundo apenas destaca palavras lematizadas, que são divididas em três caracteres, ou seja, na saída, ele tem uma lista de tokens de três caracteres.
Os tokenizadores são usados no
TfidfVectorizer , que é usado para converter dados de texto (e não apenas) em uma representação vetorial baseada em
tf-idf . Uma lista de linhas é alimentada e, na saída, obtemos uma matriz M por N, onde M é o número de linhas e N é o número de sinais. Cada recurso é uma resposta de frequência de uma palavra em um documento, onde a frequência é multada se a palavra ocorrer muitas vezes em todos os documentos. Graças ao parâmetro ngram_range TfidfVectorizer, adicionei
bigrams e trigrams como atributos.
Também tentei usar palavras incorporadas obtidas com o Word2vec como recursos adicionais. Incorporar é uma representação vetorial de uma palavra. Para cada texto, calculei a média das incorporação de todas as suas palavras. Mas isso não deu nenhum aumento, então eu recusei esses sinais.
Para etiquetas, foi utilizado um
CountVectorizer . As linhas com tags são alimentadas na entrada e, na saída, temos uma matriz em que as linhas correspondem às tarefas e as colunas correspondem às tags. Cada célula contém o número de ocorrências da marca na tarefa. No meu caso, é 1 ou 0.
O LabelBinarizer surgiu para o Reporter. Ele binariza atributos um para todos. Só pode haver um criador para cada tarefa. Na entrada do LabelBinarizer, uma lista de criadores de tarefas é enviada e a saída é uma matriz, na qual as linhas são tarefas e as colunas correspondem aos nomes dos criadores de tarefas. Acontece que em cada linha há "1" na coluna correspondente ao criador, e no restante - "0".
Para Criado, a diferença de dias entre a data em que a tarefa foi criada e a data atual é considerada.
Como resultado, foram obtidos os seguintes sinais:
- tf-idf para Resumo em palavras e números (4855, 4593)
- tf-idf para Resumo em três partições de caracteres (4855, 15518)
- tf-idf para Descrição em palavras e números (4855, 33297)
- tf-idf para Descrição em partições de três caracteres (4855, 75359)
- número de entradas para etiquetas (4855, 505)
- sinais binários para Reporter (4855, 205)
- tempo de vida da tarefa (4855, 1)
Todos esses sinais são combinados em uma grande matriz (4855, 129478), na qual o treinamento será realizado.
Separadamente, vale a pena notar os nomes dos sinais. Porque alguns modelos de aprendizado de máquina podem identificar recursos que têm maior impacto no reconhecimento de classe, você precisa usá-lo. TfidfVectorizer, CountVectorizer, LabelBinarizer têm métodos get_feature_names que exibem uma lista de recursos cuja ordem corresponde a colunas de matrizes de dados.
Seleção do Modelo de Previsão
Muitas vezes, o
XGBoost fornece bons resultados. E ele começou com isso. Mas eu gerei um grande número de recursos, cujo número excede significativamente o tamanho da amostra de treinamento. Nesse caso, a probabilidade de reciclagem do XGBoost é alta. O resultado não é muito bom. A dimensão alta é bem digerida
LogisticRegression . Ela mostrou maior qualidade.
Também tentei, como exercício, construir um modelo em uma rede neural no Tensorflow usando
este excelente tutorial, mas acabou pior do que com uma regressão logística.
Seleção de hiperparâmetros
Também joguei com os hiperparâmetros XGBoost e Tensorflow, mas deixo-o fora da publicação, porque o resultado da regressão logística não foi superado. Por fim, torci todas as canetas que poderiam ser. Todos os parâmetros, como resultado, permaneceram padrão, exceto dois: solver = 'liblinear' e C = 3.0
Outro parâmetro que pode afetar o resultado é o tamanho da amostra de treinamento. Porque Estou lidando com dados históricos e, ao longo de vários anos, a história pode mudar seriamente; por exemplo, a responsabilidade por algo pode ser transferida para outra equipe; dados mais recentes podem ser mais úteis e dados antigos podem até diminuir a qualidade. Nesse sentido, criei heurísticas - quanto mais antigos os dados, menor a contribuição que eles devem dar para modelar o treinamento. Dependendo da idade, os dados são multiplicados por um determinado coeficiente, que é retirado da função. Gerei várias funções para atenuar os dados e usei a que deu o maior aumento nos testes.
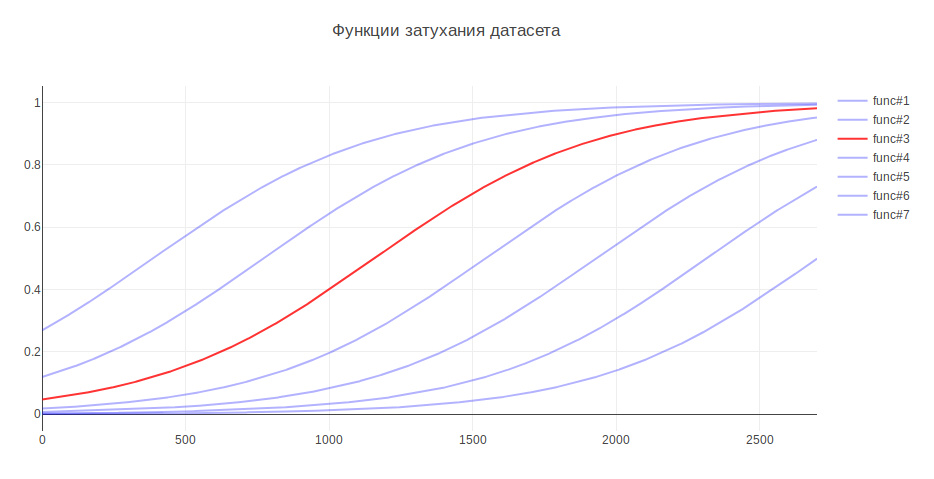
Por esse motivo, a qualidade da classificação aumentou 3%
Avaliação da qualidade
Em problemas de classificação, precisamos pensar sobre o que é mais importante para nós -
precisão ou integridade ? No meu caso, se o algoritmo estiver errado, não há nada errado, temos um conhecimento muito bom entre as equipes e a tarefa será transferida para os responsáveis ou para o principal no controle de qualidade. Além disso, o algoritmo não comete erros aleatoriamente, mas encontra um comando próximo ao problema. Portanto, foi decidido levar 100% para a integridade. E para medir a qualidade, foi escolhida a métrica de precisão - a proporção de respostas corretas, que para o modelo final foi de 76%.
Como mecanismo de validação, usei a validação cruzada pela primeira vez - quando a amostra é dividida em N partes e a qualidade é verificada em uma parte, e o treinamento é realizado no restante, e assim N vezes, até que cada parte esteja na função de teste. O resultado é então calculado a média. Mas no meu caso, essa abordagem não se encaixava, porque a ordem dos dados está mudando e, como já se tornou conhecido, a qualidade depende da atualização dos dados. Portanto, estudei o tempo todo nos antigos e fui validado nos novos.
Vamos ver quais comandos o algoritmo mais frequentemente confunde:

Em primeiro lugar, estão Marketing e Pandora. Isso não é surpreendente, pois a segunda equipe cresceu fora da primeira e assumiu a responsabilidade por muitas funcionalidades. Se você considerar o restante da equipe, também poderá ver os motivos associados à cozinha interna da empresa.
Para comparação, quero olhar para modelos aleatórios. Se você designar uma pessoa responsável aleatoriamente, a qualidade será de cerca de 5% e, para a classe mais comum, - 29%
Os sinais mais significativos
LogisticRegression para cada classe retorna coeficientes de atributo. Quanto maior o valor, maior a contribuição desse atributo para essa classe.
Sob o spoiler, a saída do topo dos sinais. Os prefixos indicam de onde vieram os sinais:
- sum - tf-idf para Resumo em palavras e números
- sum2 - tf-idf para Resumo em divisões de três caracteres
- desc - tf-idf para Descrição em palavras e números
- desc2 - tf-idf para Descrição em partições de três caracteres
- laboratório - campo Etiquetas
- rep - repórter de campo
SinaisEquipe A: sum_site (1.28), lab_responses_and_invitations (1.37), lab_failure_to empregador (1.07), lab_makeup (1.03), sum_work (1.59), lab_hhs (1.19), lab_feedback (1.06), rep_name (1.16), sum_ window (1.13), sum_ break (1.04), rep_name_1 (1.22), lab_responses_seeker (1.0), lab_site (0.92)
API: lab_delete_account (1.12), sum_comment_resume (0.94), rep_name_2 (0.9), rep_name_3 (0.83), rep_name_4 (0.89), rep_name_5 (0.91), lab_measurements_managers (0,87), lab_measurements_managers (0,87), lab_comments_to_result (1.6), account ), soma_view (0,91), comentário_declaração (1,02), nome_p rep_6 (0,85), resumo_documento (0,86), soma_api (1,01)
Android: sum_android (1.77), lab_ios (1.66), sum_application (2.9), sum_hr_mobile (1.4), lab_android (3.55), sum_hr (1.36), lab_mobile_application (3.33), sum_mobile (1.4), rep_name_2 (1.34), sum2_ril (1.27 ), sum_android_application (1.28), sum2_pril_rilo (1.19), sum2_pril_ril (1.27), sum2_pril_lozh (1.19), sum2_lo_lozh_log (1.19)
Faturamento: rep_name_7 (3.88), desc_account (3.23), rep_name_8 (3.15), lab_billing_wtf (2.46), rep_name_9 (4.51), rep_name_10 (2.88), sum_account (3.16), lab_billing (2.41), rep_name_11 (2.27), lab_b36_ ), sum_service (2.33), lab_payment_services (1.92), sum_act (2.26), rep_name_12 (1.92), rep_name_13 (2.4)
Conhaque: avaliação lab_talent (2.17), rep_name_14 (1.87), rep_name_15 (3.36), lab_clickme (1.72), rep_name_16 (1.44), rep_name_17 (1.63), rep_name_18 (1.29), sum_page (1.24), sum_brand (1.39) lab ), sum_constructor (1.59), lab_brand da página (1.33), sum_description (1.23), sum_description_of da empresa (1.17), lab_article (1.15)
Clickme: desc_act (0,73), sum_adv_hh (0,65), sum_adv_hh_ru (0,65), sum_hh (0,77), lab_hhs (1,27), lab_bs (1,91), rep_name_19 (1,17), rep_name_20 (1,29), rep_name_21 (1,9), rep_name_ ), soma_advertising (0,67), soma_colocação (0,65), soma_adv (0,65), soma_hh_ua (0,64), soma_click_31 (0,64)
Marketing: lab_region (0.9), lab_brakes_site (1.23), sum_mail (1.32), lab_managers_of vacies (0.93), sum_calender (0.93), rep_name_22 (1.33), lab_requests (1.25), rep_name_6 (1.53), lab_product_1.55 (reproduction_name_23) ), sum_yandex (1.26), sum_distribution_vacancy (0.85), sum_distribution (0.85), sum_category (0.85), sum_error_function (0.83)
Mercury: lab_services (1.76), sum_captcha (2.02), lab_search_services (1.89), lab_lawyers (2.1), lab_authorization_worker (1.68), lab_authorization_worker (1.68), lab_proforientation (2.53), lab_ready_summary (2.21), rep_name_24 (1.7725_mail ), sum_user (1.57), rep_name_26 (1.43), lab_moderation_of vacanties (1.58), desc_password (1.39), rep_name_27 (1.36)
Mobile_site: sum_mobile_version (1.32), sum_version_site (1.26), lab_application (1.51), lab_statistics (1.32), sum_mobile_version_site (1.25), lab_mobile_version (5.1), lab_mobile_version (5.1), sum_version (1. ), lab_jtb (1.07), rep_name_16 (1.12), rep_name_29 (1.05), sum_site (0.95), rep_name_30 (0.92)
TMS: rep_name_31 (1.39), lab_talantix (4.28), rep_name_32 (1.55), rep_name_33 (2.59), sum_valuation_talantix (0.74), lab_search (0.57), lab_search (0.63), rep_name_34 (0.64), lab_port (0.56) ), lab_tms (0,74), soma_hh resposta (0,57), lab_mailing (0,64), sum_talantix (0,6), sum2_po (0,56)
Talantix: sum_system (0.86), rep_name_16 (1.37), sum_talantix (1.16), lab_mail (0.94), lab_xor (0.8), lab_talantix (3.19), rep_name_35 (1.07), rep_name_18 (1.33), lab_personal_data (0.79) ), sum_talantics (0,89), sum_proceed (0,78), lab_mail (0,77), sum_response_stop_view (0,73), rep_name_6 (0,72)
Serviços da Web: sum_vacancy (1.36), desc_pattern (1.32), sum_archive (1.3), lab_patterns (1.39), sum_number_phone (1.44), rep_name_36 (1.28), lab_lawyers (2.1), lab_invitation (1.27), lab_invitation (2) ), lab_selected_summages (1.2), lab_key_keys (1.22), sum_find (1.18), sum_phone (1.16), sum_folder (1.17)
iOS: sum_application (1.41), desc_application (1.13), lab_andriod (1.73), rep_name_37 (1.05), lab_mobile_application (1.88), lab_ios (4.55), rep_name_6 (1.41), rep_name_38 (1.35), sum_mobile_application ), sum_mobile (0,98), rep_name_39 (0,74), sum_resum_hide (0,88), rep_name_40 (0,81), lab_Duplicação de vagas (0,76)
Arquitetura: sum_statistics_response (1.1), rep_name_41 (1.4), lab_graphics_views_and_responses_ vacancies (1.04), lab_creation_of vacancies (1.16), lab_quotas (1.0), sum_special offer (1.02), rep_name_42 (1.33) 1.01_01_01_01_back ), rep_name_43 (1.09), sum_dependent (0.83), sum_statistics (0.83), lab_responses_worker (0.76), sum_500ka (0.74)
Salário: lab_500 (1.18), lab_authorization (0.79), sum_500 (1.04), rep_name_44 (0.85), sum_500_site (1.03), lab_site (1.54), lab_visibility_name (1.54), lab_price list (1.26), lab_setting_visibility_7 (resultado) sum_error (0.79), lab_delivered_orders (1.33), rep_name_43 (0.74), sum_ie_11 (0.69), sum_500_error (0.66), sum2_site_ite (0.65)
Produtos para dispositivos móveis: lab_mobile_application (1,69), lab_backs (1,65), sum_hr_mobile (0,81), lab_applicant (0,88), lab_employer (0,84), sum_mobile (0,81), rep_name_45 (1,2), desc_d0 (0,87), rep_name_46 (1.rr) 0,79), sum_incorrect_search_work (0,61), desc_application (0,71), rep_name_47 (0,69), rep_name_28 (0,61), sum_work_search (0,59)
Pandora: sum_receive (2,68), desc_receive (1,72), lab_sms (1,59), sum_ letter (2,75), sum_notification_response (1,38), sum_password (1,52), lab_recover_password (1,52), lab_mail_mail resumos (1,91, email) (1,91) ), lab_mail (1.72), lab_mail (3.37), desc_mail (1.69), desc_mail (1.47), rep_name_6 (1.32)
Pimentas: lab_saving_summary (1.43), sum_summing (2.02), sum_oron (1.57), sum_oron_vacancy (1.66), desc_resum (1.19), lab_summing (1.39), sum_code (1.2), lab_applicant (1.34), sum_index (1.47), sum_index ), lab_creation_summary (1.28), rep_name_45 (1.82), sum_civilness (1.47), sum_save_summary (1.18), lab_invital_index (1.13)
Pesquisa-1: sum2_poi_is_search (1.86), sum_loop (3.59), lab_questions_o_search (3.86), sum2_poi (1.86), desc_overs (2.49), lab_observing_summary (2.2), lab_observer (2.32), lab_loop (4.3oopropo_1) (1,62), sum_synonym (1,71), sum_sample (1,62), sum2_isk (1,58), sum2_is_isk (1,57), lab_auto-update_sum (1,57)
Pesquisa-2: rep_name_48 (1.13), desc_d1 (1.1), lab_premium_in_search (1.02), lab_views_of vagas (1.4), sum_search (1.4), desc_d0 (1.2), lab_show_contacts (1.17), rep_name_49 (1.12950, lab13 (1.05), lab_search_of vagas (1.62), lab_responses_and_invitations (1.61), sum_response (1.09), lab_selected_results (1.37), lab_filter_of_responses (1.08)
SuperProdutos: lab_contact_information (1.78), desc_address (1.46), rep_name_46 (1.84), sum_address (1.74), lab_selected_resumes (1.45), lab_reviews_worker (1.29), sum_right_shot (1.29), sum_right_range (1.29) ), sum_error_position (1.33), rep_name_42 (1.32), sum_quota (1.14), desc_address_office (1.14), rep_name_51 (1.09)
Os sinais refletem aproximadamente o que as equipes estão fazendo.
Uso do modelo
Com isso, a construção do modelo é concluída e é possível construir um programa em sua base.
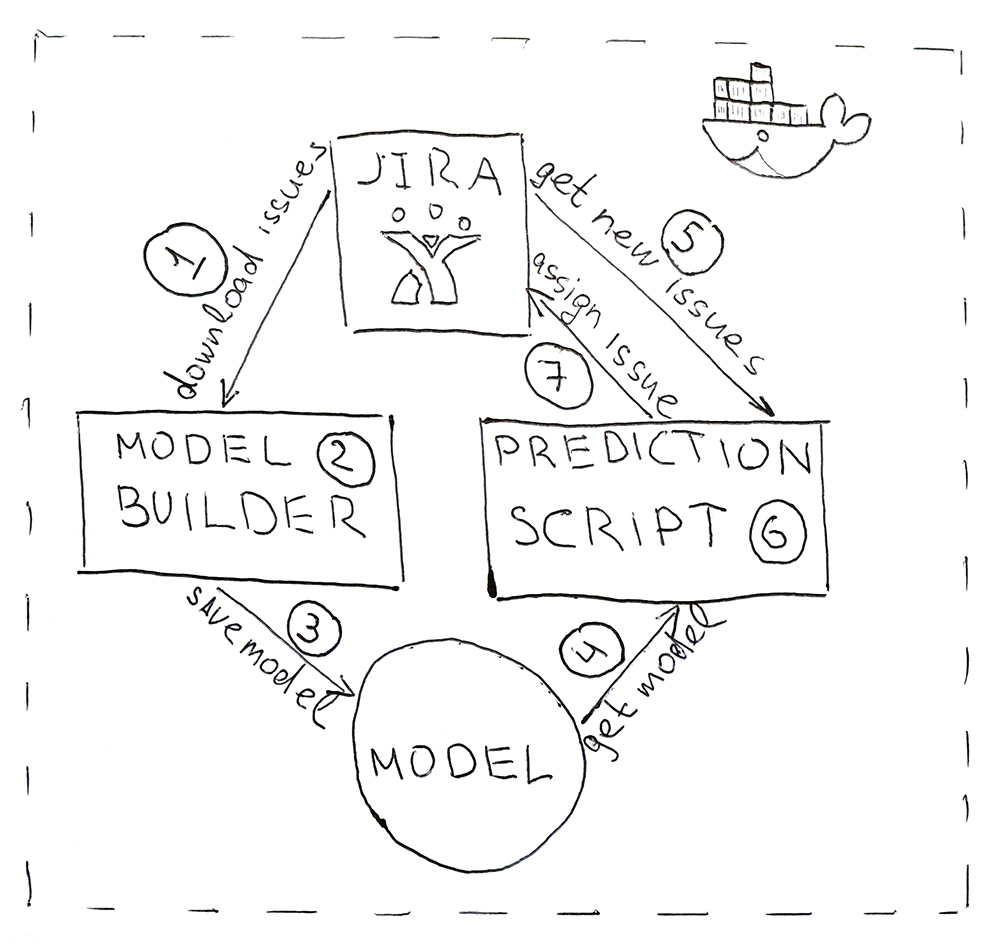
O programa consiste em dois scripts Python. O primeiro cria um modelo e o segundo faz previsões.
- O Jira fornece uma API através da qual você pode fazer o download de tarefas já concluídas (HHS). Uma vez por dia, o script é iniciado e os baixa.
- Os dados baixados são convertidos em tags. Primeiro, os dados são batidos para treinamento e teste e submetidos ao modelo de ML para validação, para garantir que a qualidade não comece a declinar do início ao início. E, na segunda vez em que o modelo é treinado em todos os dados. Todo o processo leva cerca de 10 minutos.
- O modelo treinado é salvo no disco rígido. Eu usei o utilitário dill para serializar objetos. Além do próprio modelo, também é necessário salvar todos os objetos que foram utilizados para obter as características. Isso é para obter sinais no mesmo espaço para o novo HHS.
- Usando o mesmo endro, o modelo é carregado no script para previsão, que é executado uma vez a cada 5 minutos.
- Vá para Jira para o novo HHS.
- Obtemos os sinais e os passamos para o modelo, que retornará para cada HHS o nome da classe - o nome da equipe.
- Nós encontramos a pessoa responsável pela equipe e atribuímos a ele uma tarefa por meio da API do Jira. Pode ser um testador, se a equipe não tiver um testador, será um líder de equipe.
Para tornar o programa conveniente para implantar e ter as mesmas versões de biblioteca que durante o desenvolvimento, os scripts são empacotados em um contêiner do Docker.
Como resultado, automatizamos o processo de rotina. A precisão de 76% não é muito grande, mas neste caso as falhas não são críticas. Todas as tarefas encontram seus desempenhos e, o mais importante, para isso, você não precisa mais se distrair várias vezes ao dia para entender a essência das tarefas e procurar os responsáveis. Tudo funciona automaticamente! Viva!