Hoje, queremos falar sobre um recurso tão útil do Yandex.Cloud como máquinas virtuais interrompidas. Essa é uma opção especial que você pode escolher ao criar uma máquina virtual para usar recursos de computação a um preço reduzido. O que há de tão especial nas máquinas virtuais interruptíveis, por que elas são mais baratas que as normais e em que casos é aconselhável usá-las?

As capacidades do Yandex.Cloud e, mais precisamente, o serviço de infraestrutura do
Yandex Compute Cloud , são notavelmente maiores do que as usadas pelos usuários. Por padrão, supõe-se que os usuários possam escalar arbitrariamente. Pelo menos por esses motivos, sem levar em consideração outros aspectos, os recursos disponíveis da plataforma em nuvem excedem significativamente a demanda atual. É nessas capacidades livres que são criadas as máquinas virtuais interrompidas.
Principais limitações
Resumidamente, a natureza das máquinas virtuais interrompidas pode ser descrita da seguinte forma: o serviço oferece o uso de seus recursos de computação gratuitos a um preço mais baixo, desde que esses recursos possam ser recuperados a qualquer momento.
Em geral, as máquinas virtuais interrompidas funcionam como máquinas virtuais regulares, mas têm várias limitações:
- Eles não são cobertos por um contrato de nível de serviço (SLA).
- A capacidade de criar e executar não é garantida.
- Eles podem ser forçados a parar a qualquer momento. A probabilidade de uma parada é pequena, mas diferente de zero, pode mudar com o tempo e variar em diferentes zonas de disponibilidade do Yandex.Cloud .
- Uma máquina virtual interrompida não pode ser normalizada, mas uma máquina interrompida regularmente. O sinalizador correspondente é definido uma vez e não muda.
- A máquina será seguramente parada em um período não superior a 24 horas.
Na prática, na grande maioria dos casos, as máquinas virtuais interrompidas funcionam todas as 24 horas previstas pelas condições de serviço. Uma parada forçada geralmente ocorre apenas quando um grande número de máquinas virtuais comuns é criado em uma zona de disponibilidade específica em um curto período de tempo: um novo usuário com sérias necessidades aparece ou os usuários atuais são escalados em massa.
Ao mesmo tempo, uma máquina virtual parada pode ser iniciada novamente: todos os dados nos discos são salvos durante o desligamento automático e manual.
Casos de uso
As restrições para máquinas virtuais interrompidas levantam uma questão lógica: como aplicá-las se os recursos puderem ser revogados a qualquer momento? Como explicação, aqui estão alguns casos de uso possíveis.
Processamento em lote
O processamento em lote envolve a execução paralela de um grande número de tarefas que consomem muitos recursos. Pode ser a conversão de formatos de arquivo, processamento e reconhecimento de imagem,
operações ETL . A conclusão é que, no processamento em lote, há uma fila de trabalhos e um conjunto inteiro de processos de trabalho (executores) que recebem trabalhos da fila. Se um executor individual executando em uma máquina interrompida parar, a tarefa será simplesmente transferida para o próximo executor. Em outras palavras, interromper uma ou mesmo várias máquinas virtuais não terá um impacto negativo significativo no processo e no resultado do processamento.

Ao processar dados em lote, estamos falando sobre o uso de dezenas de máquinas virtuais. O uso de máquinas intermitentes proporciona economias muito visíveis. Agora, um dos principais consumidores de máquinas virtuais descontínuas produtivas com 32 núcleos é um cliente Yandex.Cloud de longa data, Seismotech. O Seismotek processa dados sísmicos, necessários para a exploração de campos de gás e petróleo. A exploração sísmica envolve trabalhar com grandes volumes de informação. Os dados são processados em um método em lote. A empresa usa simultaneamente mais de 60 máquinas interrompidas: um total de até 2000 vCPU e 4000 GB de RAM.
Projetos no Hadoop
O Hadoop é usado para desenvolver e executar programas distribuídos em execução em clusters de centenas e milhares de nós de baixo custo. Os mecanismos para replicação de arquivos e reinicialização automática de tarefas executadas em nós com falha fornecidos pelo Hadoop garantem a estabilidade de um sistema distribuído às falhas de máquinas individuais. É por isso que, onde o Hadoop é usado, pelo menos parte dos nós pode ser facilmente implantada em máquinas virtuais interrompidas. Se eles param mais cedo, as tarefas serão enviadas para outros nós.
Failover de serviços da Web
A disponibilidade contínua do serviço da web pode ser garantida usando um cluster. Um cluster consiste em dois ou mais servidores. Uma de suas tarefas no aplicativo de serviços da web é garantir uma operação estável no momento de picos de carga. Exemplos típicos: sites de compras online ou esportes, nos quais o crescimento do tráfego está vinculado a datas específicas. Para lojas, podem ser feriados tradicionais ou períodos de descontos e, para sites relacionados a esportes, podem ser dias de eventos em que as transmissões ao vivo são publicadas, revisões e relatórios fotográficos são publicados. Nesses momentos, o volume de tráfego pode aumentar significativamente.
O cluster deve lidar com o fluxo de visitantes, distribuindo tráfego para diferentes nós. Durante um período de crescimento acentuado, mas de curta duração, a tolerância a falhas pode ser fornecida adicionando servidores em máquinas virtuais descontinuadas. Esta opção é barata e faz seu trabalho bem. É importante observar uma condição: esse cluster deve ser híbrido, ou seja, incluir máquinas virtuais comuns. Nesse caso, mesmo a parada improvável de máquinas interrompidas não causará uma falha no serviço.
Projetos na Kubernetes
O Kubernetes automatiza a implantação, dimensionamento e gerenciamento de aplicativos em contêineres em um grande número de nós. Uma das principais entidades que pode ser chamada de bloco de construção do Kubernetes está em (pod). O Pod fornece o lançamento de um ou vários contêineres em um nó. Um nó para cada lareira é selecionado e designado pelo planejador Kubernetes. Se um nó separado com uma lareira em execução falhar, o planejador o transferirá automaticamente para um nó que está operando no modo normal. Esse esquema de manutenção da integridade sugere que parte dos nós pode ser hospedada em máquinas virtuais descontínuas.
Teste de integração contínua
A prática da integração contínua é baseada na montagem e teste freqüentes do projeto. Nesse caso, principalmente testes automatizados são usados. Esquematicamente, é assim: um ambiente de teste é criado em uma máquina virtual, a última compilação do aplicativo é carregada nela, são realizados testes automatizados, os resultados do teste são carregados, a máquina virtual é excluída. Como regra, o teste leva várias dezenas de minutos, menos frequentemente várias horas.
Tradicionalmente, os pontos fracos da integração contínua são considerados custos significativos para suportar o próprio processo de integração e a alta demanda por recursos de computação. Desse ponto de vista, e levando em consideração o período de testes automatizados, as máquinas virtuais descontinuadas parecem mais do que adequadas para a integração contínua. Eles são muito mais baratos e a probabilidade de um carro parar imediatamente no momento do teste é muito pequena. Além disso, mesmo se o carro ainda estiver parado, os danos do ponto de vista da empresa serão mínimos.
Use em conjunto com outros serviços Yandex.Cloud
O serviço Yandex Instance Groups permite monitorar automaticamente o status de um grupo inteiro de máquinas virtuais interrompidas. Ele pode criar independentemente máquinas virtuais com as características fornecidas, manter o número necessário de máquinas no grupo e reiniciar instâncias interrompidas se elas pararem. Não importa se ocorreu uma parada forçada ou se passaram 24 horas desde o início. Apenas uma coisa é importante: uma reinicialização ocorrerá se houver recursos disponíveis. O Yandex Instance Groups torna o trabalho com máquinas virtuais interrompidas mais conveniente, mas não pode garantir que as capacidades livres existam necessariamente em uma zona de disponibilidade específica.
Desempenho econômico
Como mencionamos, máquinas virtuais interrompíveis podem reduzir o custo do uso de recursos de computação. No Yandex, começamos a trabalhar em uma função semelhante há vários anos. Para dividir as tarefas de computação em garantido executável e interruptível, foram necessários investimentos consideráveis. Mas não foi em vão: no final, aumentamos o nível de utilização útil da infraestrutura do servidor de 30-40% para 70-80%.

Agora, recursos semelhantes estão disponíveis para todos os usuários do Yandex.Cloud com o clique de um botão. Um exemplo simples: se você transferir metade das máquinas virtuais usadas com cem por cento de carga do kernel para o formato de interrupção, poderá economizar de 35 a 40% do orçamento.
A um custo reduzido, os recursos de CPU e RAM estão disponíveis. O espaço em disco e os endereços IP são pagos a taxas regulares. Aqui está o que mostra um cálculo simples para a plataforma Cascade Lake.
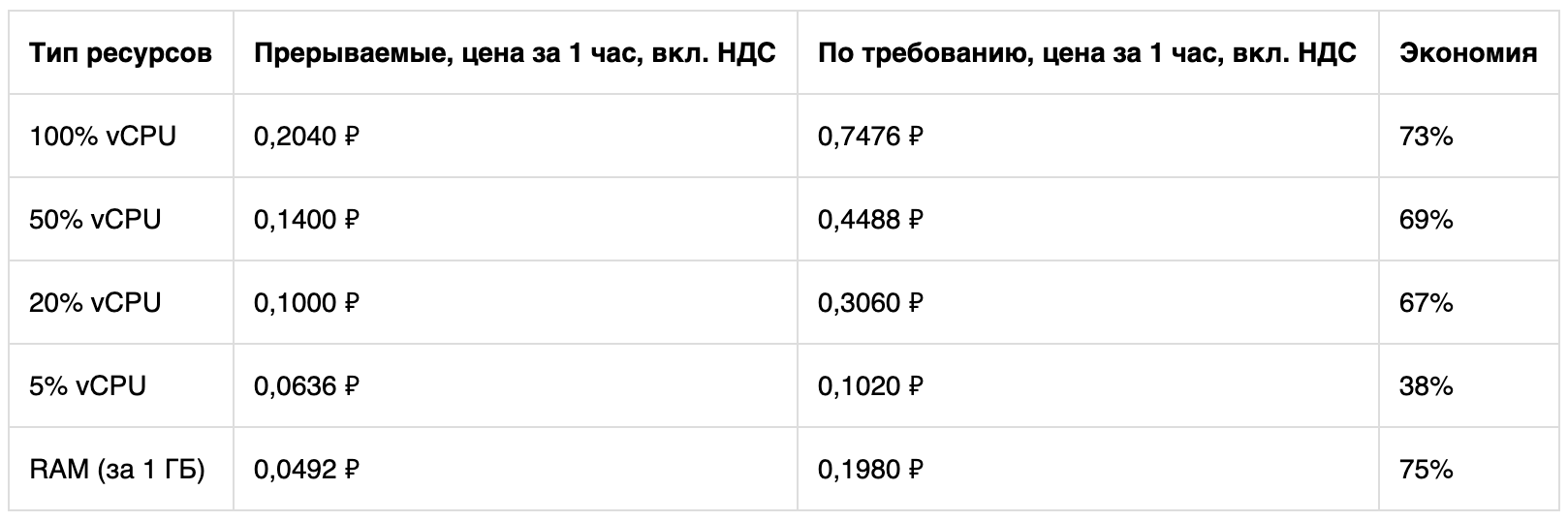
Se desejar, você pode comparar o custo do uso de máquinas virtuais em modos diferentes usando uma
calculadora .
Esperamos poder trazer um pouco de clareza e dar alguns exemplos úteis nos quais você pode usar máquinas virtuais interrompíveis para reduzir o custo de recursos de computação sem perder qualidade na execução de tarefas.
Outras publicações sobre Cloud on Habré