Sobre o artigo
Esta publicação é uma pequena observação para programadores que desejam aprender mais sobre como a GPU lida com ramificações. Você pode considerá-lo uma introdução a este tópico. Eu recomendo começar examinando [
1 ], [
2 ] e [
8 ] para ter uma idéia de como o modelo de execução da GPU se parece em geral, porque consideraremos apenas um detalhe separado. Para leitores curiosos, existem todos os links no final do post. Se você encontrar erros, entre em contato comigo.
Conteúdo
- Sobre o artigo
- Conteúdo
- Vocabulário
- Qual a diferença entre o núcleo da GPU e o núcleo da CPU?
- O que é consistência / discrepância?
- Exemplos de processamento de máscara de execução
- ISA fictício
- AMD GCN ISA
- AVX512
- Como lidar com a discrepância?
- Referências
Vocabulário
- GPU - Unidade de processamento gráfico, GPU
- Classificação de Flynn
- SIMD - Dados múltiplos de instrução única, fluxo de instrução único, fluxo de dados múltiplo
- SIMT - Threads múltiplos de instrução única, fluxo de instrução único, threads múltiplos
- Wave (SIM) - um fluxo executado no modo SIMD
- Linha (faixa) - um fluxo de dados separado no modelo SIMD
- SMT - Multithreading simultâneo, multithreading simultâneo (Intel Hyper-threading) [ 2 ]
- Vários threads compartilham os principais recursos de computação
- IMT - Multithreading intercalado, multithreading alternado [ 2 ]
- Vários threads compartilham o total de recursos de computação do kernel, mas apenas um
- BB - Bloco Básico, um bloco básico - uma sequência linear de instruções com um único salto no final
- ILP - Paralelismo no nível da instrução, paralelismo no nível da instrução [ 3 ]
- ISA - Arquitetura do Conjunto de Instruções, arquitetura do conjunto de instruções
No meu post vou aderir a essa classificação inventada. Assemelha-se aproximadamente à forma como uma GPU moderna é organizada.
:
GPU -+
|- 0 -+
| |- 0 +
| | |- 0
| | |- 1
| | |- ...
| | +- Q-1
| |
| |- ...
| +- M-1
|
|- ...
+- N-1
* - SIMD
:
+
|- 0
|- ...
+- N-1
Outros nomes:
- O núcleo pode ser chamado de CU, SM, EU
- Uma onda pode ser chamada de frente de onda, thread de hardware (thread HW), warp, um contexto
- Uma linha pode ser chamada de thread de programa (thread SW)
Qual a diferença entre o núcleo da GPU e o núcleo da CPU?
Qualquer geração atual de núcleos de GPU é menos poderosa que os processadores centrais: ILP simples / múltiplos problemas [
6 ] e pré-busca [
5 ], sem previsão ou previsão de transições / retornos. Tudo isso, junto com pequenos caches, libera uma área bastante grande no chip, que é preenchida com muitos núcleos. Os mecanismos de carregamento / armazenamento de memória são capazes de lidar com a largura do canal em uma ordem de magnitude maior (isso não se aplica às GPUs integradas / móveis) do que as CPUs convencionais, mas você deve pagar por isso com altas latências. Para ocultar a latência, a GPU usa SMT [
2 ] - enquanto uma onda está ociosa, outras usam os recursos de computação gratuitos do kernel. Normalmente, o número de ondas processadas por um núcleo depende dos registros utilizados e é determinado dinamicamente alocando um arquivo de registro fixo [
8 ]. O planejamento para a execução das instruções é híbrido - dinâmico-estático [
6 ] [
11 4.4]. Os kernels SMT executados no modo SIMD atingem altos valores de FLOPS (operações de ponto flutuante por segundo, flops, número de operações de ponto flutuante por segundo).
 Gráfico de legenda. Preto - inativo, branco - ativo, cinza - desligado, azul - inativo, vermelho - pendenteFigura 1. Histórico de execução 4: 2
Gráfico de legenda. Preto - inativo, branco - ativo, cinza - desligado, azul - inativo, vermelho - pendenteFigura 1. Histórico de execução 4: 2A imagem mostra o histórico da máscara de execução, em que o eixo x mostra o tempo da esquerda para a direita e o eixo y mostra o identificador da linha que vai de cima para baixo. Se você ainda não entender isso, volte ao desenho depois de ler as seções a seguir.
Esta é uma ilustração de como o histórico de execução do núcleo da GPU pode parecer em uma configuração fictícia: quatro ondas compartilham um amostrador e duas ALUs. O planejador de ondas em cada ciclo emite duas instruções de duas ondas. Quando uma onda está ociosa ao executar um acesso à memória ou uma operação ALU longa, o agendador alterna para outro par de ondas, devido ao qual a ALU é constantemente ocupada em quase 100%.
Figura 2. Histórico de execução 4: 1Um exemplo com a mesma carga, mas desta vez em cada ciclo da instrução apenas uma onda é emitida. Observe que a segunda ALU está passando fome.
Figura 3. Histórico de execução 4: 4Desta vez, quatro instruções são emitidas em cada ciclo. Observe que há muitas solicitações para a ALU, portanto, duas ondas quase sempre estão aguardando (na verdade, isso é um erro do algoritmo de planejamento).
Atualização Para obter mais informações sobre as dificuldades de planejar a execução de instruções, consulte [
12 ].
No mundo real, as GPUs têm configurações de núcleo diferentes: algumas podem ter até 40 ondas por núcleo e 4 ALUs, outras possuem 7 ondas fixas e 2 ALUs. Tudo isso depende de muitos fatores e é determinado graças ao meticuloso processo de simulação de arquitetura.
Além disso, as ALUs SIMD reais podem ter uma largura menor que as ondas que elas servem e, em seguida, são necessários vários ciclos para processar uma instrução emitida; o fator é chamado comprimento "carrilhão" [
3 ].
O que é consistência / discrepância?
Vamos dar uma olhada no seguinte trecho de código:
Exemplo 1
uint lane_id = get_lane_id(); if (lane_id & 1) {
Aqui vemos um fluxo de instruções em que o caminho da execução depende do identificador da linha que está sendo executada. Obviamente, linhas diferentes têm significados diferentes. O que vai acontecer? Existem diferentes abordagens para resolver esse problema [
4 ], mas no final todas elas fazem a mesma coisa. Uma dessas abordagens é a máscara de execução, que abordarei. Essa abordagem foi usada nas GPUs da Nvidia antes de Volta e nas GPUs da AMD GCN. O ponto principal da máscara de execução é que armazenamos um pouco para cada linha na onda. Se o bit de execução da linha correspondente for 0, nenhum registro será afetado para a próxima instrução emitida. De fato, a linha não deve sentir a influência de toda a instrução executada, porque seu bit de execução é 0. Isso funciona da seguinte maneira: a onda viaja ao longo do gráfico de fluxo de controle na ordem de busca de profundidade, salvando o histórico das transições selecionadas até que os bits sejam definidos. Eu acho que é melhor mostrar isso por exemplo.
Suponha que temos ondas com uma largura de 8. Aqui está a aparência da máscara de execução para o fragmento de código:
Exemplo 1. Histórico da máscara de execução
Agora considere exemplos mais complexos:
Exemplo 2
uint lane_id = get_lane_id(); for (uint i = lane_id; i < 16; i++) {
Exemplo 3
uint lane_id = get_lane_id(); if (lane_id < 16) {
Você pode perceber que a história é necessária. Ao usar a abordagem de máscara de execução, o equipamento geralmente usa algum tipo de pilha. A abordagem ingênua é armazenar uma pilha de tuplas (exec_mask, endereço) e adicionar instruções de convergência que extraem a máscara da pilha e alteram o ponteiro de instruções da onda. Nesse caso, a onda terá informações suficientes para ignorar todo o CFG de cada linha.
Em termos de desempenho, são necessários apenas alguns loops para processar uma instrução de fluxo de controle por causa de todo esse armazenamento de dados. E não esqueça que a pilha tem uma profundidade limitada.
Update. Graças a
@craigkolb, li um artigo [
13 ], que observa que as instruções de junção / junção do AMD GCN selecionam primeiro um caminho a partir de menos threads [
11 4.6], o que garante que a profundidade da pilha de máscaras seja igual a log2.
Update. Obviamente, quase sempre é possível incorporar tudo em um shader / estrutura CFG em um shader e, portanto, armazenar todo o histórico de máscaras de execução em registros e planejar estaticamente ignorar / convergir CFG [
15 ]. Depois de analisar o back-end LLVM para AMDGPU, não encontrei nenhuma evidência de manipulação de pilha constantemente emitida pelo compilador.
Suporte de hardware de máscara de tempo de execução
Agora, veja estes gráficos de fluxo de controle da Wikipedia:
Figura 4. Alguns dos tipos de gráficos de fluxo de controleQual é o conjunto mínimo de instruções de controle de máscara que precisamos para lidar com todos os casos? Aqui está o que parece no meu ISA artificial com paralelismo implícito, controle explícito de máscara e sincronização totalmente dinâmica de conflitos de dados:
push_mask BRANCH_END ; Push current mask and reconvergence pointer pop_mask ; Pop mask and jump to reconvergence instruction mask_nz r0.x ; Set execution bit, pop mask if all bits are zero ; Branch instruction is more complicated ; Push current mask for reconvergence ; Push mask for (r0.x == 0) for else block, if any lane takes the path ; Set mask with (r0.x != 0), fallback to else in case no bit is 1 br_push r0.x, ELSE, CONVERGE
Vamos dar uma olhada no caso d).
A: br_push r0.x, C, D B: C: mask_nz r0.y jmp B D: ret
Não sou especialista em analisar fluxos de controle ou projetar o ISA; portanto, tenho certeza de que há um caso em que meu ISA artificial não será capaz de lidar com isso, mas isso não é importante, porque um CFG estruturado deve ser suficiente para todos.
Update. Leia mais sobre o suporte GCN para obter instruções sobre fluxo de controle aqui: [
11 ] cap.4 e sobre a implementação do LLVM aqui: [
15 ].
Conclusão:
- Divergência - a diferença resultante nos caminhos escolhidos por diferentes linhas da mesma onda
- Consistência - sem discrepância.
Exemplos de processamento de máscara de execução
ISA fictício
Compilei os trechos de código anteriores no meu ISA artificial e os executei em um simulador no SIMD32. Veja como ele lida com a máscara de execução.
Update. Observe que um simulador artificial sempre escolhe o caminho verdadeiro, e esse não é o melhor caminho.
Exemplo 1
 Figura 5. O histórico do exemplo 1
Figura 5. O histórico do exemplo 1Você notou uma área preta? Este tempo desperdiçado. Algumas linhas esperam que outras pessoas concluam a iteração.
Exemplo 2
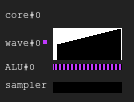 Figura 6. Histórico do exemplo 2
Figura 6. Histórico do exemplo 2Exemplo 3
mov r0.x, lane_id lt.u32 r0.y, r0.x, u(16)
 Figura 7. Histórico do exemplo 3
Figura 7. Histórico do exemplo 3AMD GCN ISA
Update. A GCN também usa processamento explícito de máscaras; mais sobre isso pode ser encontrado aqui: [
11 4.x]. Decidi mostrar alguns exemplos de seu ISA, graças ao
shader-playground, isso é fácil de fazer. Talvez um dia eu encontre um simulador e consiga obter diagramas.
Lembre-se de que o compilador é inteligente, para que você possa obter outros resultados. Tentei enganar o compilador para que ele não otimizasse minhas ramificações, colocando lá os loops de ponteiro e depois limpando o código do assembler; Eu não sou especialista em GCN, portanto, alguns pontos importantes podem ser ignorados.
Observe também que as instruções S_CBRANCH_I / G_FORK e S_CBRANCH_JOIN não são usadas nesses fragmentos porque são simples e o compilador não as suporta. Portanto, infelizmente, não foi possível considerar a pilha de máscaras. Se você souber como fazer o processamento da pilha de problemas do compilador, informe-me.
Update. Confira esta
palestra do @ SiNGUL4RiTY sobre a implementação de um fluxo de controle vetorizado no back-end LLVM usado pela AMD.
Exemplo 1
Exemplo 2
Exemplo 3
AVX512
Update. @tom_forsyth apontou para mim que a extensão AVX512 também possui processamento explícito de máscara, então aqui estão alguns exemplos. Mais detalhes sobre isso podem ser encontrados em [
14 ], 15.xe 15.6.1. Não é exatamente uma GPU, mas ainda possui um SIMD16 real de 32 bits. Os trechos de código foram criados usando o godbolt ISPC (–target = avx512knl-i32x16) e foram fortemente reprojetados, portanto, podem não ser 100% verdadeiros.
Exemplo 1
Exemplo 2
Exemplo 3
Como lidar com a discrepância?
Tentei criar uma ilustração simples, mas completa, de como a ineficiência surge da combinação de linhas divergentes.
Imagine um simples pedaço de código:
uint thread_id = get_thread_id()
Vamos criar 256 threads e medir o tempo de execução:
Figura 8. Duração de encadeamentos divergentesO eixo x é o identificador do fluxo do programa, o eixo y é o ciclo do relógio; colunas diferentes mostram quanto tempo é desperdiçado ao agrupar fluxos com diferentes comprimentos de onda em comparação com a execução de thread único.
O tempo de execução da onda é igual ao tempo máximo de execução entre as linhas contidas nele. Você pode ver que o desempenho já diminui drasticamente com o SIMD8 e outras expansões apenas pioram um pouco.
Figura 9. Tempo de execução de threads consistentesAs mesmas colunas são mostradas nesta figura, mas desta vez o número de iterações é classificado por identificadores de fluxo, ou seja, fluxos com um número semelhante de iterações são transmitidos para uma única onda.
Neste exemplo, a execução é potencialmente acelerada pela metade.
Obviamente, o exemplo é muito simples, mas espero que você entenda o ponto: a discrepância na execução decorre da discrepância dos dados, portanto os CFGs devem ser simples e os dados consistentes.
Por exemplo, se você estiver escrevendo um traçador de raios, poderá se beneficiar do agrupamento dos raios com a mesma direção e posição, porque eles provavelmente passarão pelos mesmos nós no BVH. Veja [
10 ] e outros artigos relacionados para mais detalhes.
Também vale ressaltar que existem técnicas para lidar com discrepâncias no nível do hardware, por exemplo, Dynamic Warp Formação [
7 ] e execução prevista para ramificações pequenas.
Referências
[1]
Uma viagem pelo Pipeline gráfico[2]
Kayvon Fatahalian: COMPUTAÇÃO PARALELA[3]
Arquitetura de computadores: uma abordagem quantitativa[4]
Reconvergência SIMT sem pilha a baixo custo[5]
Dissecando a hierarquia de memória da GPU através de microbenchmarking[6]
Dissecando a arquitetura NVIDIA Volta GPU via microbenchmarking[7]
Formação dinâmica de urdidura e programação para fluxo de controle eficiente da GPU[8]
Maurizio Cerrato: arquiteturas de GPU[9]
Simulador de GPU de brinquedo[10]
Reduzindo a divergência de filiais em programas GPU[11]
Arquitetura do conjunto de instruções "Vega"[12]
Joshua Barczak: Simulando a execução de shader para GCN[13]
Vetor tangente: uma digressão sobre divergência[14]
Arquiteturas Intel 64 e IA-32Manual do desenvolvedor de software[15]
Vetorizando o fluxo de controle divergente para aplicativos SIMD