Discutiremos a implementação do mapa em um idioma sem genéricos, consideraremos o que é uma tabela de hash, como ela está organizada no Go, quais são os prós e os contras dessa implementação e em que você deve prestar atenção ao usar essa estrutura.
Detalhes sob o corte.
Atenção! Se você já conhece as tabelas de hash no Go, aconselho que você pule o básico e vá
aqui , caso contrário, existe o risco de se cansar do momento mais interessante.
O que é uma tabela de hash
Para começar, lembrarei o que é uma tabela de hash. Esta é uma estrutura de dados que permite armazenar pares de valores-chave e, como regra, ter funções:
- Mapeamento:
map(key) → value
- Inserções:
insert(map, key, value)
- Exclusões:
delete(map, key)
- Pesquisa:
lookup(key) → value
Tabela de hash no idioma go
Uma tabela de hash no idioma go é representada pela palavra-chave map e pode ser declarada de uma das maneiras abaixo (mais sobre elas posteriormente):
m := make(map[key_type]value_type) m := new(map[key_type]value_type) var m map[key_type]value_type m := map[key_type]value_type{key1: val1, key2: val2}
As principais operações são executadas da seguinte forma:
- Inserir:
m[key] = value
- Remoção:
delete(m, key)
- Pesquisa:
value = m[key]
ou
value, ok = m[key]
Contorne uma mesa em movimento
Considere o seguinte programa:
package main import "fmt" func main() { m := map[int]bool{} for i := 0; i < 5; i++ { m[i] = ((i % 2) == 0) } for k, v := range m { fmt.Printf("key: %d, value: %t\n", k, v) } }
Lançamento 1:
key: 3, value: false key: 4, value: true key: 0, value: true key: 1, value: false key: 2, value: true
Execução 2:
key: 4, value: true key: 0, value: true key: 1, value: false key: 2, value: true key: 3, value: false
Como você pode ver, a saída varia de execução para execução. E tudo porque o mapa em Go é desordenado, ou seja, não está ordenado. Isso significa que você não precisa confiar na ordem ao circular. O motivo pode ser encontrado no código-fonte do idioma de execução:
A localização da pesquisa é determinada
aleatoriamente , lembre-se disso! Há rumores de que os desenvolvedores de tempo de execução estão forçando os usuários a não confiar na ordem.
Ir para pesquisa de tabela
Vejamos um pedaço de código novamente. Suponha que desejemos criar pares "número" - "número vezes 10":
package main import ( "fmt" ) func main() { m := map[int]int{0: 0, 1: 10} fmt.Println(m, m[0], m[1], m[2]) }
Lançamos:
map[0:0 1:10] 0 10 0
E vemos que, quando tentamos obter o valor de dois (que esquecemos de colocar), obtivemos 0. Nós encontramos linhas explicando esse comportamento na
documentação : “Uma tentativa de buscar um valor do mapa com uma chave que não está presente no mapa retornará o valor zero para o tipo das entradas no mapa. ", mas traduzido para o russo, isso significa que, quando tentamos obter o valor do mapa, mas ele não está lá, obtemos um" valor de tipo zero ", que, no caso do número 0. O que fazer, se queremos distinguir entre os casos 0 e a ausência 2? Para fazer isso, criamos uma forma especial de "atribuição múltipla" - uma forma em que, em vez do valor único usual, o mapa retorna um par: o próprio valor e outro booleano que responde à pergunta se a chave solicitada está presente no mapa ou não "
Corretamente, o trecho de código anterior terá a seguinte aparência:
package main import ( "fmt" ) func main() { m := map[int]int{0: 0, 1: 10} m2, ok := m[2] if !ok {
E na inicialização, obtemos:
map[0:0 1:10] 0 10 20
Crie uma tabela no Go.
Suponha que desejemos contar o número de ocorrências de cada palavra em uma string, iniciar um dicionário para isso e passar por isso.
package main func main() { var m map[string]int for _, word := range []string{"hello", "world", "from", "the", "best", "language", "in", "the", "world"} { m[word]++ } for k, v := range m { println(k, v) } }
Você vê um
esquilo apanhado? - e ele é!
Quando tentamos iniciar esse programa, entramos em pânico e a mensagem "atribuição à entrada no mapa nulo". E tudo porque o mapa é um tipo de referência e não é suficiente declarar uma variável, você precisa inicializá-la:
m := make(map[string]int)
Um pouco mais baixo, ficará claro por que isso funciona dessa maneira. No começo, já havia quatro maneiras de criar um mapa, duas delas examinadas - essa declaração como variável e a criação através do make. Você também pode criar usando o design "
Compostos literais "
map[key_type]value_type{}
e se você desejar, mesmo inicializando imediatamente com valores, esse método também é válido. Quanto à criação usando new - na minha opinião, não faz sentido, porque essa função aloca memória para a variável e retorna um ponteiro preenchido com o tipo de valor zero, que no caso do mapa será nulo (obtemos o mesmo resultado que em var, mais precisamente um ponteiro para ele).
Como o mapa é passado para uma função?
Suponha que tenhamos uma função que tente alterar o número que foi passado para ela. Vamos ver o que acontece antes e depois da chamada:
package main func foo(n int) { n = 10 } func main() { n := 15 println("n before foo =", n) foo(n) println("n after foo =", n) }
Um exemplo, eu acho, é bastante óbvio, mas ainda inclui a conclusão:
n before foo = 15 n after foo = 15
Como você provavelmente adivinhou, a função n veio por valor, não por referência; portanto, a variável original não mudou.
Vamos fazer um truque de mapa semelhante:
package main func foo(m map[int]int) { m[10] = 10 } func main() { m := make(map[int]int) m[10] = 15 println("m[10] before foo =", m[10]) foo(m) println("m[10] after foo =", m[10]) }
E eis que:
m[10] before foo = 15 m[10] after foo = 10
O valor foi alterado. “Bem, o Mapa é passado por referência?”, Você pergunta.
Não. Não há links no Go. É impossível criar 2 variáveis com 1 endereço, como em C ++, por exemplo. Mas então você pode criar 2 variáveis apontando para o mesmo endereço (mas esses são ponteiros e estão em Go).
Suponha que temos uma função fn que inicializa o mapa m. Na função principal, simplesmente declaramos uma variável, enviamos para inicializar e olhamos o que aconteceu depois.
package main import "fmt" func fn(m map[int]int) { m = make(map[int]int) fmt.Println("m == nil in fn?:", m == nil) } func main() { var m map[int]int fn(m) fmt.Println("m == nil in main?:", m == nil) }
Conclusão:
m == nil in fn?: false
m == nil in main?: true
Portanto, a variável m foi passada
por valor , portanto, como no caso de passar um int regular para a função, ela não foi alterada (a cópia local do valor em fn foi alterada). Então, por que o valor em si muda? Para responder a essa pergunta, considere o código do idioma de execução:
O mapa no Go é apenas um ponteiro para a estrutura hmap. Esta é a resposta para a pergunta: por que, apesar de o mapa ser passado para a função por valor, os próprios valores nele mudam - tudo se resume ao ponteiro. A estrutura hmap também contém o seguinte: o número de elementos, o número de "buckets" (apresentados como um logaritmo para acelerar os cálculos), semente para hashes aleatórios (para tornar mais difícil a adição - tente pegar as teclas para que haja colisões contínuas), todos os tipos de campos de serviço e o mais importante, um ponteiro para os baldes em que os valores são armazenados. Vejamos a foto:
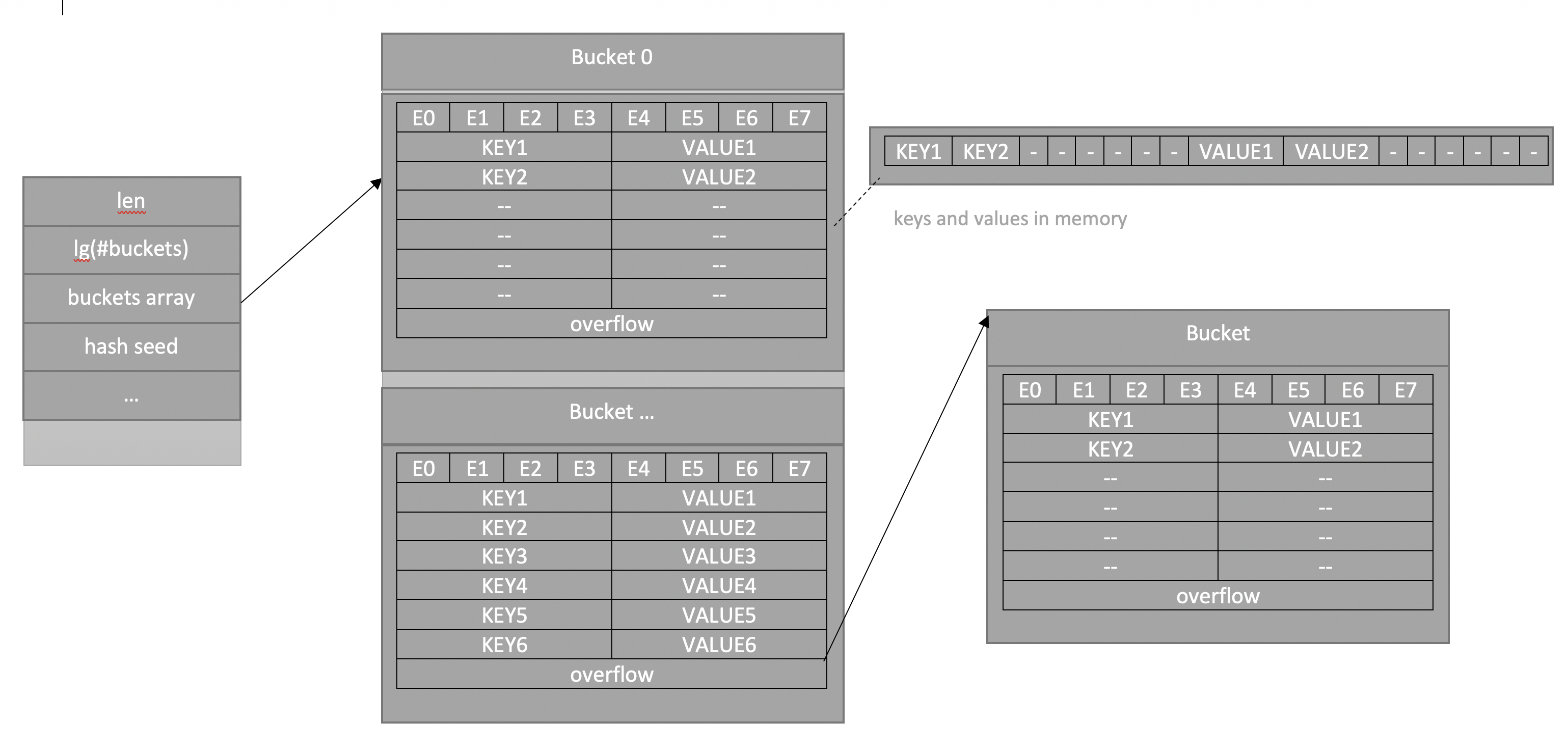
A imagem mostra uma imagem esquemática da estrutura na memória - há um cabeçalho hmap, o ponteiro para o qual é um mapa no Go (é criado quando declarado com var, mas não é inicializado, o que causa uma falha no programa ao tentar inseri-lo). O campo buckets é um repositório de pares de valores-chave, existem vários buckets, cada um contendo 8 pares. Primeiro no “bucket” estão os slots para bits de hash adicionais (e0..e7 é chamado e - porque bits de hash
extras ). A seguir, são apresentadas as chaves e os valores como uma lista de todas as chaves, depois uma lista de todos os valores.
O hash da função determina em qual intervalo colocamos o valor; dentro de cada intervalo, pode haver até 8 colisões; no final de cada intervalo, há um ponteiro para outro, se o anterior estourar.
Como o mapa cresce?
No código fonte, você pode encontrar a linha:
isto é, se houver uma média de mais de 6,5 elementos em cada bucket, ocorrerá um aumento na matriz de buckets. Nesse caso, a matriz é alocada 2 vezes mais e os dados antigos são copiados para ela em pequenas porções a cada inserção ou exclusão, para não criar atrasos muito grandes. Portanto, todas as operações serão um pouco mais lentas no processo de evacuação de dados (ao pesquisar, também, precisamos procurar em dois locais). Após uma evacuação bem-sucedida, novos dados começam a ser usados.
Tomando o endereço do elemento do mapa.
Outro ponto interessante - no começo do uso da linguagem que eu queria fazer assim:
package main import ( "fmt" ) func main() { m := make(map[int]int) m[1] = 10 a := &m[1] fmt.Println(m[1], *a) }
Mas Go diz: "não é possível usar o endereço de m [1]". A explicação de por que é impossível usar o endereço do valor está no procedimento de evacuação de dados. Imagine que pegamos o endereço do valor e, em seguida, o mapa cresceu, nova memória foi alocada, os dados foram evacuados, os antigos foram excluídos, o ponteiro ficou incorreto e, portanto, essas operações são proibidas.
Como o mapa é implementado sem genéricos?
Nem uma interface vazia, nem a geração de código têm algo a ver com isso; a coisa toda é substituí-la no momento da compilação. Considere o que as funções familiares do Go se transformam:
v := m["k"] → func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer v, ok := m["k"] → func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) m["k"] = 9001 → func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer delete(m, "k") → func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)
Vemos que existem funções mapaccess para acessos, para escrever e excluir mapassign e mapdelete, respectivamente. Todas as operações usam unsafe.Pointer, que não se importa com o tipo para o qual aponta, e as informações sobre cada valor são descritas por um descritor de
tipo .
type mapType struct { key *_type elem *_type ...} type _type struct { size uintptr alg *typeAlg ...} type typeAlg struct { hash func(unsafe.Pointer, uintptr) uintptr equal func(unsafe.Pointer, unsafe.Pointer) bool...}
MapType armazena os descritores (_type) da chave e do valor. Para um descritor de tipo, são definidas operações (typeAlg) de comparação, tendo um hash, tamanho e assim por diante, para que sempre saibamos como produzi-los.
Um pouco mais sobre como isso funciona. Quando escrevemos v = m [k] (tentando obter o valor de v da chave k), o compilador gera algo como o seguinte:
kPointer := unsafe.Pointer(&k) vPointer := mapaccess1(typeOf(m), m, kPointer) v = *(*typeOfvalue)vPointer
Ou seja, pegamos um ponteiro para uma chave, a estrutura mapType, a partir da qual descobrimos quais descritores da chave e do valor, o ponteiro para o próprio hmap (ou seja, mapa) e passamos tudo para o mapaccess1, que retornará um ponteiro para o valor. Lançamos o ponteiro para o tipo desejado, desreferencia e obtemos o valor.
Agora, vejamos o código de pesquisa do tempo de execução (que é ligeiramente adaptado para leitura):
func lookup(t *mapType, m *mapHeader, key unsafe.Pointer) unsafe.Pointer {
A função procura a chave no mapa e retorna um ponteiro para o valor correspondente, os argumentos já são familiares para nós - este é mapType, que armazena descritores dos tipos e valores de chave, o próprio mapa (mapHeader) e um ponteiro para a memória que armazena a chave. Retornamos um ponteiro para a memória que armazena o valor.
if m == nil || m.count == 0 { return zero }
Em seguida, verificamos se o ponteiro para o cabeçalho do mapa não é nulo, se existem 0 elementos e retornamos um valor nulo, se houver.
hash := t.key.hash(key, m.seed)
Calculamos o hash da chave (sabemos como calcular para uma determinada chave a partir de um descritor de tipo). Depois, tentamos entender qual "balde" você precisa ver (o restante da divisão pelo número de "baldes", os cálculos são apenas ligeiramente acelerados). Em seguida, calculamos o hash adicional (pegamos os 8 bits mais significativos do hash) e determinamos a posição do “bucket” na memória (aritmética do endereço).
for { for i := 0; i < 8; i++ { if b.extra[i] != extra {
A pesquisa, se você olha, não é tão complicada: passamos pelas cadeias de "baldes", passando para a próxima, se você não a encontrou. A pesquisa no "bloco" começa com uma comparação rápida do hash adicional (é por isso que esses e0 ... e7 no início de cada um são um "mini" hash do par para comparação rápida). Se não corresponder, vá além, se corresponder, verificamos com mais cuidado - determinamos onde a chave suspeita de ser pesquisada se encontra na memória, comparamos se é igual ao solicitado. Se igual, determine a posição do valor na memória e retorne. Como você pode ver, nada sobrenatural.
Conclusão
Use mapas, mas saiba e entenda como eles funcionam! Você pode evitar o rake entendendo algumas das sutilezas - por que você não pode pegar o endereço do valor, por que tudo cai durante a declaração sem inicialização, por que é melhor alocar memória com antecedência, se o número de elementos for conhecido (evitaremos a evacuação) e muito mais.
Referências:
"Ir mapas em ação", Andrew Gerrand“Como o tempo de execução go implementa mapas com eficiência”, Dave Cheney"Entendendo o tipo em movimento", William KennedyImplementação interna do mapa, Keith Randallcódigo fonte do mapa, Go Runtimegolang specir eficazgopher imagens