Saudação, Khabrovites! A tradução do artigo a seguir foi preparada especificamente para os alunos do curso
Infrastructure Platform ,
baseado em Kubernetes , que iniciará as aulas amanhã. Vamos começar.

Escalonamento automático em Kubernetes
O dimensionamento automático permite aumentar e diminuir automaticamente as cargas de trabalho, dependendo do uso de recursos.
O dimensionamento automático do Kubernetes tem duas dimensões:
- Autoscaler de cluster, responsável por dimensionar nós;
- Horizontal Pod Autoscaler (HPA), que dimensiona automaticamente o número de lares em um conjunto de implantação ou réplica.
O dimensionamento automático de cluster pode ser usado em conjunto com o dimensionamento automático da lareira horizontal para controlar dinamicamente os recursos de computação e o grau de simultaneidade do sistema necessário para cumprir os SLAs (acordos de nível de serviço).
O escalonamento automático de cluster é altamente dependente dos recursos do provedor de infraestrutura em nuvem que hospeda o cluster, e o HPA pode operar independentemente do provedor IaaS / PaaS.
Desenvolvimento HPA
O dimensionamento automático da lareira horizontal sofreu grandes mudanças desde a introdução do Kubernetes v1.1. A primeira versão do HPA dimensionou os lares com base no consumo medido da CPU e, posteriormente, no uso da memória. O Kubernetes 1.6 introduziu uma nova API chamada Custom Metrics, que fornecia ao HPA acesso a métricas personalizadas. O Kubernetes 1.7 adicionou um nível de agregação que permite que aplicativos de terceiros estendam a API do Kubernetes registrando-se como complementos da API.
Graças à API de métricas personalizadas e ao nível de agregação, sistemas de monitoramento como o Prometheus podem fornecer métricas específicas de aplicativos ao controlador HPA.
O dimensionamento automático da lareira horizontal é implementado como um loop de controle que consulta periodicamente a API de métricas de recursos (API de métricas de recursos) para obter as principais métricas, como uso de CPU e memória, e a API de métricas personalizadas (API de métricas personalizadas) para métricas específicas de aplicativos.
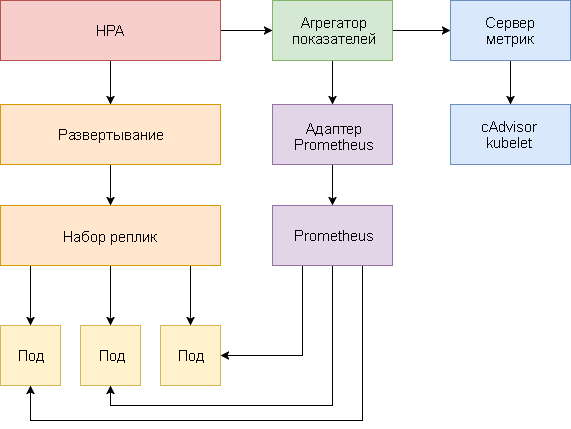
Abaixo está um guia passo a passo para configurar o HPA v2 para Kubernetes 1.9 e posterior.
- Instale o suplemento Metrics Server, que fornece as principais métricas.
- Inicie um aplicativo de demonstração para ver como o dimensionamento automático da lareira funciona com base no uso da CPU e da memória.
- Implante o Prometheus e o servidor de API personalizado. Registre um servidor de API personalizado no nível de agregação.
- Configure o HPA usando métricas personalizadas fornecidas pelo aplicativo de demonstração.
Antes de começar, você deve instalar o Go versão 1.8 (ou posterior) e clonar o
repositório k8s-prom- GOPATH no
GOPATH :
cd $GOPATH git clone https:
1. Configurando o Servidor de Métricas
O Kubernetes
Metric Server é o agregador de dados de utilização de recursos dentro do cluster que substitui o
Heapster . O servidor de métricas coleta informações de uso da CPU e da memória para nós e lares do
kubernetes.summary_api . A API Summary é uma API com eficiência de memória para transmitir métricas de dados Kubelet / cAdvisor para um servidor.
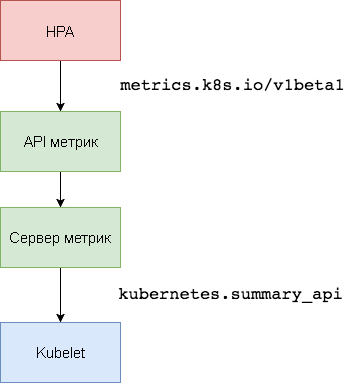
Na primeira versão do HPA, era necessário um agregador Heapster para obter a CPU e a memória. No HPA v2 e no Kubernetes 1.8, apenas um servidor métrico é necessário com o
horizontal-pod-autoscaler-use-rest-clients ativado. Esta opção é ativada por padrão no Kubernetes 1.9. O GKE 1.9 vem com um servidor de métricas pré-instalado.
Expanda o servidor de métricas no
kube-system nome do
kube-system :
kubectl create -f ./metrics-server
Após 1 minuto, o
metric-server começará a transmitir dados sobre o uso da CPU e da memória por nós e pods.
Exibir métricas do nó:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
Veja os indicadores de frequência cardíaca:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
2. Escalonamento automático baseado no uso da CPU e da memória
Para testar o dimensionamento automático horizontal da lareira (HPA), você pode usar um pequeno aplicativo Web baseado em Golang.
Expanda
podinfo no espaço para nome
default :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
Entre em
podinfo com o
podinfo usando o serviço NodePort em
http://<K8S_PUBLIC_IP>:31198 .
Especifique um HPA que atenda a pelo menos duas réplicas e dimensione para dez réplicas se a utilização média da CPU exceder 80% ou se o consumo de memória for superior a 200 MiB:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 80 - type: Resource resource: name: memory targetAverageValue: 200Mi
Crie HPA:
kubectl create -f ./podinfo/podinfo-hpa.yaml
Após alguns segundos, o controlador HPA entrará em contato com o servidor métrico e receberá informações sobre o uso da CPU e da memória:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5m
Para aumentar o uso da CPU, faça um teste de carga com rakyll / hey:
#install hey go get -u github.com/rakyll/hey #do 10K requests hey -n 10000 -q 10 -c 5 http:
Você pode monitorar eventos HPA da seguinte maneira:
$ kubectl describe hpa Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
Remova o podinfo temporariamente (você precisará reimplementá-lo em uma das próximas etapas deste guia).
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml
3. Configuração do servidor de métricas personalizadas
Para dimensionar com base em métricas personalizadas, são necessários dois componentes. O primeiro - o banco de dados de séries temporais do
Prometheus - coleta métricas de aplicativos e as salva. O segundo componente, o
k8s-prometheus-adapter , complementa o Kubernetes da API Custom Metrics com métricas fornecidas pelo construtor.
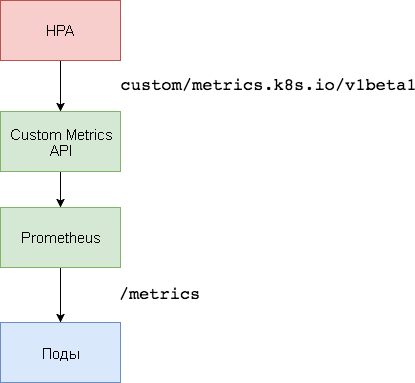
Um espaço para nome dedicado é usado para implantar o Prometheus e o adaptador.
Crie um espaço para nome de
monitoring :
kubectl create -f ./namespaces.yaml
Expanda Prometheus v2 no namespace de
monitoring :
kubectl create -f ./prometheus
Gere os certificados TLS necessários para o adaptador Prometheus:
make certs
Implemente o adaptador Prometheus para a API de métricas personalizadas:
kubectl create -f ./custom-metrics-api
Obtenha uma lista de métricas especiais fornecidas pelo Prometheus:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
Em seguida, extraia os dados de uso do sistema de arquivos para todos os pods no namespace de
monitoring :
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .
4. Escalonamento automático com base em métricas personalizadas
Crie o serviço podinfo do
podinfo e implemente no espaço para nome
default :
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
O aplicativo
podinfo passará a métrica especial
http_requests_total . O adaptador Prometheus removerá o sufixo
_total e marcará essa métrica como um contador.
Obtenha o número total de consultas por segundo na API de métricas personalizadas:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq . { "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-kv5g9", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "901m" }, { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-6b86c8ccc9-nm7bl", "apiVersion": "/__internal" }, "metricName": "http_requests", "timestamp": "2018-01-10T16:49:07Z", "value": "898m" } ] }
A letra
m significa
milli-units , portanto, por exemplo,
901m é 901 milissegundo.
Crie um HPA que expandirá a implantação do podinfo se o número de solicitações exceder 10 solicitações por segundo:
apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 10 metrics: - type: Pods pods: metricName: http_requests targetAverageValue: 10
Expanda HPA
podinfo no espaço para nome
default :
kubectl create -f ./podinfo/podinfo-hpa-custom.yaml
Após alguns segundos, o HPA obterá o valor
http_requests da API de métricas:
kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 899m / 10 2 10 2 1m
Aplique a carga para o serviço podinfo com 25 solicitações por segundo:
#install hey go get -u github.com/rakyll/hey #do 10K requests rate limited at 25 QPS hey -n 10000 -q 5 -c 5 http:
Após alguns minutos, o HPA começará a dimensionar a implantação:
kubectl describe hpa Name: podinfo Namespace: default Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests" on pods: 9059m / 10< Min replicas: 2 Max replicas: 10 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
Com o número atual de solicitações por segundo, a implantação nunca alcançará um máximo de 10 pods. Três réplicas são suficientes para garantir que o número de solicitações por segundo para cada pod seja menor que 10.
Após a conclusão dos testes de carga, o HPA reduzirá a escala de implantação para o número inicial de réplicas:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
Você deve ter notado que o redimensionador automático não responde imediatamente a alterações nas métricas. Por padrão, eles são sincronizados a cada 30 segundos. Além disso, a escala ocorre apenas se não houver um aumento ou diminuição nas cargas de trabalho durante os últimos 3-5 minutos. Isso ajuda a evitar decisões conflitantes e deixa tempo para conectar o auto-scaler do cluster.
Conclusão
Nem todos os sistemas podem impor a conformidade com o SLA com base apenas na utilização da CPU ou da memória (ou ambas). A maioria dos servidores da Web e servidores móveis para lidar com picos de tráfego precisa de dimensionamento automático com base no número de solicitações por segundo.
Para aplicativos ETL (do Eng. Extract Transform Load - “extração, transformação, carregamento”), o dimensionamento automático pode ser acionado, por exemplo, quando o comprimento limite especificado da fila de trabalhos é excedido.
Em todos os casos, instrumentar aplicativos usando o Prometheus e destacar os indicadores necessários para o dimensionamento automático permitem ajustar aplicativos para melhorar o processamento de picos de tráfego e garantir alta disponibilidade da infraestrutura.
Ideias, perguntas, comentários? Participe da discussão no
Slack !
Aqui está esse material. Estamos aguardando seus comentários e até o
curso !