Apesar de a maior parte do setor de TI implementar soluções de infraestrutura baseadas em contêineres e soluções em nuvem, é necessário entender as limitações dessas tecnologias. Tradicionalmente, Docker, Linux Containers (LXC) e Rocket (rkt) não são realmente isolados porque compartilham o núcleo do sistema operacional pai em seu trabalho. Sim, eles são eficazes em termos de recursos, mas o número total de vetores de ataque estimados e perdas potenciais de hackers ainda são grandes, especialmente no caso de um ambiente de nuvem com vários inquilinos no qual os contêineres estão localizados.

A raiz do nosso problema está na fraca delimitação de contêineres no momento em que o sistema operacional host cria uma área de usuário virtual para cada um deles. Sim, pesquisa e desenvolvimento foram conduzidos com o objetivo de criar "contêineres" reais com uma caixa de areia de pleno direito. E a maioria das soluções resultantes leva a uma reestruturação dos limites entre os contêineres para aumentar seu isolamento. Neste artigo, examinaremos quatro projetos exclusivos da IBM, Google, Amazon e OpenStack, respectivamente, que usam métodos diferentes para atingir o mesmo objetivo: criar isolamento confiável. Portanto, o IBM Nabla implementa contêineres sobre o Unikernel, o Google gVisor cria um kernel convidado especializado, o Amazon Firecracker usa um hipervisor extremamente leve para aplicativos sandbox e o OpenStack coloca os contêineres em uma máquina virtual especializada otimizada para ferramentas de orquestração.
Visão geral da moderna tecnologia de contêineres
Os contêineres são uma maneira moderna de empacotar, compartilhar e implantar um aplicativo. Ao contrário de um aplicativo monolítico, no qual todas as funções são empacotadas em um programa, os aplicativos de contêiner ou microsserviços destinam-se ao uso restrito direcionado e são especializados em apenas uma tarefa.
Um contêiner inclui todas as dependências (por exemplo, pacotes, bibliotecas e binários) que um aplicativo precisa para concluir sua tarefa específica. Como resultado, os aplicativos em contêineres são independentes da plataforma e podem ser executados em qualquer sistema operacional, independentemente da versão ou dos pacotes instalados. Essa conveniência poupa os desenvolvedores de uma grande parte do trabalho de adaptação de diferentes versões de software para diferentes plataformas ou clientes. Embora conceitualmente não seja totalmente preciso, muitas pessoas gostam de pensar em contêineres como "máquinas virtuais leves".
Quando um contêiner é implantado em um host, os recursos de cada contêiner, como sistema de arquivos, processo e pilha de rede, são colocados em um ambiente praticamente isolado que outros contêineres não podem acessar. Essa arquitetura permite que centenas e milhares de contêineres sejam executados simultaneamente em um único cluster, e cada aplicativo (ou microsserviço) pode ser facilmente dimensionado replicando um grande número de instâncias.
Nesse caso, o layout do contêiner é baseado em dois “blocos de construção” principais: o espaço para nome do Linux e os grupos de controle do Linux (cgroups).
O espaço para nome cria um espaço de usuário praticamente isolado e fornece ao aplicativo recursos dedicados do sistema, como sistema de arquivos, pilha de rede, ID do processo e ID do usuário. Nesse espaço isolado do usuário, o aplicativo controla o diretório raiz do sistema de arquivos e pode ser executado como raiz. Esse espaço abstrato permite que cada aplicativo funcione independentemente, sem interferir com outros aplicativos que residem no mesmo host. No momento, seis namespaces estão disponíveis: montagem, comunicação entre processos (ipc), sistema de compartilhamento de tempo UNIX (uts), identificação do processo (pid), rede e usuário. É proposto que esta lista seja complementada com dois namespaces adicionais: time e syslog, mas a comunidade Linux ainda não decidiu as especificações finais.
Os Cgroups fornecem limitação, priorização, monitoramento e controle de recursos de hardware. Um exemplo dos recursos de hardware que eles podem controlar é o processador, a memória, o dispositivo e a rede. Ao combinar o namespace e o cgroups, podemos executar com segurança vários aplicativos no mesmo host, com cada aplicativo em seu próprio ambiente isolado - que é a propriedade fundamental do contêiner.
A principal diferença entre uma máquina virtual (VM) e um contêiner é que a máquina virtual é virtualização no nível do hardware e o contêiner é virtualização no nível do sistema operacional. O hipervisor da VM emula o ambiente de hardware de cada máquina, onde o tempo de execução do contêiner já emula o sistema operacional de cada objeto. Máquinas virtuais compartilham o hardware físico do host e os contêineres compartilham o hardware e o núcleo do SO. Como os contêineres geralmente compartilham mais recursos com o host, seu trabalho com os ciclos de armazenamento, memória e CPU é muito mais eficiente do que com uma máquina virtual. No entanto, a desvantagem desse acesso compartilhado são os problemas no plano de segurança da informação, pois é estabelecida muita confiança entre os contêineres e o host. A Figura 1 ilustra a diferença arquitetônica entre um contêiner e uma máquina virtual.
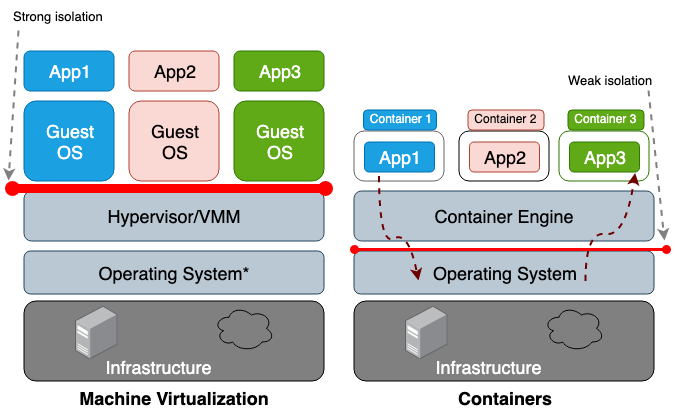
Em geral, o isolamento de equipamentos virtualizados cria um perímetro de segurança muito mais forte do que apenas o isolamento de um espaço para nome. O risco de um invasor sair com êxito de um processo isolado é muito maior do que a chance de sair com êxito da máquina virtual. A razão do maior risco de ir além do ambiente de contêiner limitado é o fraco isolamento criado pelo namespace e cgroups. O Linux os implementa associando novos campos de propriedades a cada processo. Esses campos no sistema de arquivos
/proc indicam ao sistema operacional host se um processo pode ver outro ou quanto recursos de processador / memória um determinado processo pode usar. Ao visualizar processos e threads em execução no sistema operacional pai (por exemplo, o comando top ou ps), o processo do contêiner se parece com qualquer outro. Normalmente, soluções tradicionais, como LXC ou Docker, não são consideradas totalmente isoladas porque usam o mesmo núcleo no mesmo host. Portanto, não é de surpreender que os contêineres tenham um número suficiente de vulnerabilidades. Por exemplo, CVE-2014-3519, CVE-2016-5195, CVE-2016-9962, CVE-2017-5123 e CVE-2019-5736 podem resultar em um invasor obtendo acesso a dados fora do contêiner.
A maioria das explorações de kernel cria um vetor para um ataque bem-sucedido, porque geralmente resulta em escalonamento de privilégios e permite que um processo comprometido obtenha controle fora do espaço de nome pretendido. Além dos vetores de ataque no contexto de vulnerabilidades de software, a configuração inadequada também pode desempenhar um papel. Por exemplo, implantar imagens com privilégios excessivos (CAP_SYS_ADMIN, acesso privilegiado) ou pontos críticos de montagem (
/var/run/docker.sock ) pode resultar em um vazamento. Dadas essas conseqüências potencialmente catastróficas, você deve entender o risco que corre ao implantar o sistema em um espaço de vários locatários ou ao usar contêineres para armazenar dados confidenciais.
Esses problemas motivam os pesquisadores a criar perímetros de segurança mais fortes. A idéia é criar um contêiner sandbox real o mais isolado possível do sistema operacional principal. A maioria dessas soluções inclui o desenvolvimento de uma arquitetura híbrida que utiliza uma distinção estrita entre o aplicativo e a máquina virtual e se concentra em melhorar a eficiência das soluções de contêiner.
No momento da redação deste artigo, não havia um único projeto que pudesse ser considerado maduro o suficiente para ser aceito como padrão, mas, no futuro, os desenvolvedores, sem dúvida, aceitarão alguns desses conceitos como principais.
Começamos nossa análise com o Unikernel, o sistema altamente especializado mais antigo que compacta um aplicativo em uma imagem usando um conjunto mínimo de bibliotecas de SO. O conceito do Unikernel em si provou ser fundamental para muitos projetos cujo objetivo era criar imagens seguras, compactas e otimizadas. Depois disso, passaremos a considerar o IBM Nabla, um projeto para iniciar aplicativos Unikernel, incluindo contêineres. Além disso, temos o Google gVisor, um projeto para iniciar contêineres no espaço do kernel do usuário. Em seguida, mudaremos para soluções de contêineres baseadas em máquinas virtuais - Amazon Firecracker e OpenStack Kata. Para resumir este post, comparando todas as soluções acima.
Unikernel
O desenvolvimento de tecnologias de virtualização nos permitiu mudar para a computação em nuvem. Hipervisores como Xen e KVM lançaram as bases para o que hoje conhecemos como Amazon Web Services (AWS) e Google Cloud Platform (GCP). E embora os hipervisores modernos sejam capazes de trabalhar com centenas de máquinas virtuais combinadas em um único cluster, os sistemas operacionais tradicionais de uso geral não são muito adaptados e otimizados para funcionar em um ambiente como esse. O objetivo geral do sistema operacional é, em primeiro lugar, oferecer suporte e trabalhar com o maior número possível de aplicativos, portanto, seus kernels incluem todos os tipos de drivers, bibliotecas, protocolos, agendadores e assim por diante. No entanto, a maioria das máquinas virtuais agora implantadas em algum lugar da nuvem é usada para executar um único aplicativo, por exemplo, para fornecer DNS, um proxy ou algum tipo de banco de dados. Como um aplicativo único depende apenas de uma parte específica e pequena do kernel do sistema operacional, todas as outras "saias" simplesmente desperdiçam recursos do sistema e, pelo fato de existir, aumentam o número de vetores para um possível ataque. De fato, quanto maior a base de código, mais difícil é eliminar todas as deficiências e mais vulnerabilidades, erros e outras fraquezas em potencial. Esse problema incentiva os especialistas a desenvolver sistemas operacionais altamente especializados com um conjunto mínimo de funcionalidades do kernel, ou seja, a criar ferramentas para suportar um aplicativo específico.
Pela primeira vez, a ideia do Unikernel nasceu nos anos 90. Então, ele tomou forma como uma imagem especializada de uma máquina com um único espaço de endereço que pode funcionar diretamente em hipervisores. Ele compacta os aplicativos e funções principais e dependentes do kernel em uma única imagem. Nemesis e Exokernel são as duas primeiras versões de pesquisa do projeto Unikernel. O processo de empacotamento e implantação é mostrado na Figura 2.
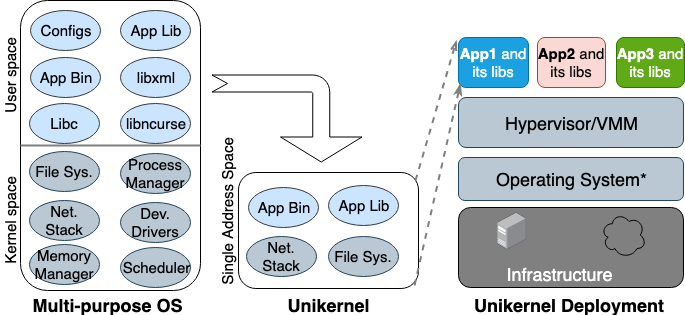 Figura 2. Sistemas operacionais multiuso projetados para oferecer suporte a todos os tipos de aplicativos; muitas bibliotecas e drivers são carregados com antecedência. Unikernels são sistemas operacionais altamente especializados, projetados para suportar um aplicativo específico.
Figura 2. Sistemas operacionais multiuso projetados para oferecer suporte a todos os tipos de aplicativos; muitas bibliotecas e drivers são carregados com antecedência. Unikernels são sistemas operacionais altamente especializados, projetados para suportar um aplicativo específico.
O unikernel divide o kernel em várias bibliotecas e coloca apenas os componentes necessários na imagem. Como máquinas virtuais regulares, o unikernel é implementado e executado no hipervisor da VM. Devido ao seu tamanho pequeno, ele pode carregar rapidamente e também escalar rapidamente. Os recursos mais importantes do Unikernel são segurança aumentada, tamanho reduzido, alto grau de otimização e carregamento rápido. Como essas imagens contêm apenas bibliotecas dependentes de aplicativos e o shell do SO não é acessível se não estiver conectado propositadamente, o número de vetores de ataque que os invasores podem usar neles é mínimo.
Ou seja, não é apenas difícil para os invasores ganhar uma posição nesses núcleos únicos, mas sua influência também é limitada a uma instância principal. Como o tamanho das imagens do Unikernel é de apenas alguns megabytes, elas são baixadas em dezenas de milissegundos e literalmente centenas de instâncias podem ser executadas em um único host. Usando a alocação de memória no mesmo espaço de endereço em vez de uma tabela de páginas multinível, como é o caso da maioria dos sistemas operacionais modernos, os aplicativos unikernel têm um atraso menor no acesso à memória em comparação com o mesmo aplicativo em execução em uma máquina virtual comum. Como os aplicativos se reúnem com o kernel ao criar a imagem, os compiladores podem simplesmente executar a verificação de tipo estático para otimizar arquivos binários.
O Unikernel.org mantém uma lista de projetos do unikernel. Mas com todas as suas características e propriedades distintas, o unikernel não é amplamente utilizado. Quando a Docker adquiriu a Unikernel Systems em 2016, a comunidade decidiu que a empresa agora embalaria contêineres neles. Mas três anos se passaram e ainda não há sinais de integração. Uma das principais razões para essa lenta implementação é que ainda não existe uma ferramenta madura para criar aplicativos Unikernel, e a maioria desses aplicativos pode funcionar apenas em determinados hipervisores. Além disso, a portabilidade de um aplicativo para o unikernel pode exigir a reescrita manual do código em outros idiomas, incluindo a reescrita das bibliotecas dependentes do kernel. Também é importante que o monitoramento ou depuração em unikernels seja impossível ou tenha um impacto significativo no desempenho.
Todas essas restrições impedem os desenvolvedores de mudar para essa tecnologia. Deve-se notar que o unikernel e os contêineres têm muitas propriedades semelhantes. Tanto a primeira como a segunda são imagens imutáveis altamente focadas, o que significa que os componentes dentro deles não podem ser atualizados ou corrigidos, ou seja, você sempre precisa criar uma nova imagem para o patch do aplicativo. Hoje, o Unikernel é semelhante ao ancestral do Docker: então o tempo de execução do contêiner não estava disponível e os desenvolvedores precisavam usar as ferramentas básicas para criar um ambiente de aplicativo isolado (chroot, descompartilhamento e cgroups).
Ibm nabla
Uma vez, pesquisadores da IBM propuseram o conceito de "Unikernel como um processo" - ou seja, o aplicativo unikernel que seria executado como um processo em um hipervisor especializado. O projeto IBM “Nabla containers” fortaleceu o perímetro de segurança do unikernel, substituindo o hypervisor universal (por exemplo, QEMU) por seu próprio desenvolvimento chamado Nabla Tender. A lógica por trás dessa abordagem é que as chamadas entre o unikernel e o hipervisor ainda fornecem o maior número de vetores de ataque. É por isso que o uso de um hypervisor dedicado ao unikernel com menos chamadas de sistema permitidas pode fortalecer significativamente o perímetro de segurança. O Nabla Tender intercepta chamadas que o unikernel roteia para o hipervisor e já as converte em solicitações do sistema. Ao mesmo tempo, a política seccomp do Linux bloqueia todas as outras chamadas do sistema que não são necessárias para o Tender funcionar. Assim, o Unikernel em conjunto com o Nabla Tender é executado como um processo no espaço do usuário do host. Abaixo, na figura 3, é mostrado como o Nabla cria uma interface fina entre o unikernel e o host.
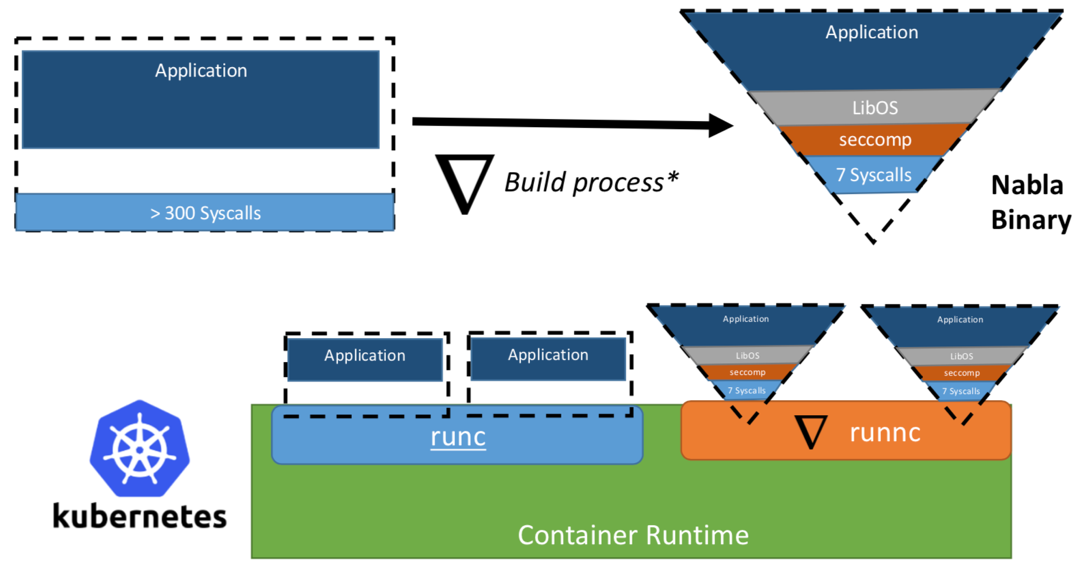 Figura 3. Para vincular o Nabla às plataformas de contêiner existentes, o Nabla usa um ambiente compatível com OCI, que por sua vez pode ser conectado ao Docker ou ao Kubernetes.
Figura 3. Para vincular o Nabla às plataformas de contêiner existentes, o Nabla usa um ambiente compatível com OCI, que por sua vez pode ser conectado ao Docker ou ao Kubernetes.Os desenvolvedores afirmam que o Nabla Tender usa menos de sete chamadas do sistema em seu trabalho para interagir com o host. Como as chamadas do sistema servem como uma espécie de ponte entre os processos no espaço do usuário e o kernel do sistema operacional, quanto menos chamadas do sistema estiverem disponíveis, menor será o número de vetores disponíveis para atacar o kernel. Outra vantagem de executar o unikernel como um processo é que você pode depurar esses aplicativos usando um grande número de ferramentas, por exemplo, usando o gdb.
Para trabalhar com plataformas de orquestração de contêiner, a Nabla fornece um
runnc dedicado, implementado usando o padrão Open Container Initiative (OCI). O último define uma API entre clientes (por exemplo, Docker, Kubectl) e o ambiente de tempo de execução (por exemplo, runc). O Nabla também vem com um construtor de imagens que o
runnc poderá executar mais tarde. No entanto, devido a diferenças no sistema de arquivos entre unikernels e contêineres tradicionais, as imagens Nabla não atendem às especificações de imagem OCI e, portanto, as imagens do Docker não são compatíveis com o
runnc . No momento da redação deste artigo, o projeto ainda está nos estágios iniciais de desenvolvimento. Existem outras restrições, por exemplo, a falta de suporte para montar / acessar sistemas de arquivos host, adicionar várias interfaces de rede (necessárias para o Kubernetes) ou usar imagens de outras imagens de unikernel (por exemplo, MirageOS).
Google gVisor
O Google gVisor é uma tecnologia sandbox usando o Google Cloud Platform Application Engine (GCP), recursos de nuvem e CloudML. Em algum momento, o Google percebeu o risco de executar aplicativos não confiáveis na infraestrutura de nuvem pública e a ineficiência de aplicativos sandbox usando máquinas virtuais. Como resultado, um kernel do espaço do usuário foi desenvolvido para um ambiente isolado de aplicativos não confiáveis. O gVisor coloca esses aplicativos na sandbox, interceptando todas as chamadas do sistema para o kernel do host e processando-as no ambiente do usuário usando o kernel do gVisor Sentry. Em essência, ele funciona como uma combinação de um núcleo convidado e um hipervisor. A Figura 4 mostra a arquitetura do gVisor.
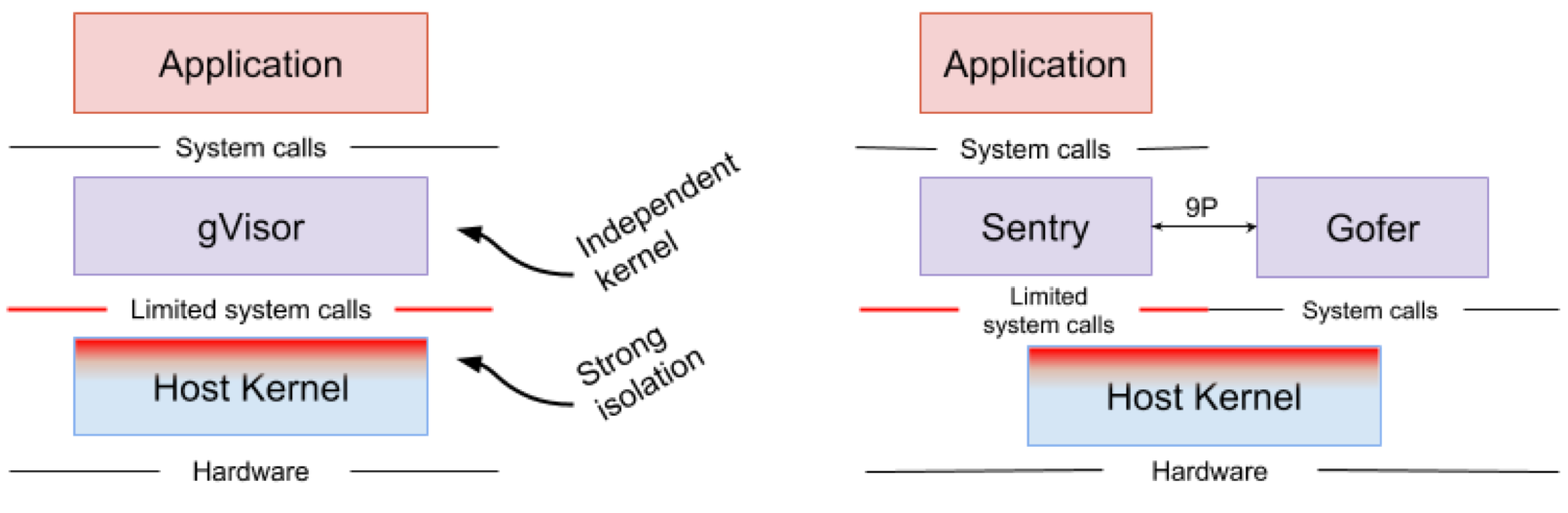 Figura 4. Implementação do kernel do gVisor // Os sistemas de arquivos Sentry e gVisor Gofer usam um pequeno número de chamadas do sistema para interagir com o host
Figura 4. Implementação do kernel do gVisor // Os sistemas de arquivos Sentry e gVisor Gofer usam um pequeno número de chamadas do sistema para interagir com o hostO gVisor cria um forte perímetro de segurança entre o aplicativo e seu host. Limita as chamadas do sistema que os aplicativos podem usar no espaço do usuário. Sem depender da virtualização, o gVisor funciona como um processo host que interage entre um aplicativo independente e um host. O Sentry suporta a maioria das chamadas de sistema Linux e os principais recursos do kernel, como entrega de sinal, gerenciamento de memória, pilha de rede e modelo de fluxo. O Sentry implementa mais de 70% das 319 chamadas do sistema Linux para dar suporte a aplicativos em área restrita. No entanto, o Sentry usa menos de 20 chamadas do sistema Linux para interagir com o kernel host. Vale ressaltar que o gVisor e o Nabla têm uma estratégia muito semelhante: proteger o sistema operacional host e essas duas soluções usam menos de 10% das chamadas do sistema Linux para interagir com o kernel. Mas você precisa entender que o gVisor cria um kernel multiuso e, por exemplo, o Nabla conta com kernels exclusivos. Ao mesmo tempo, ambas as soluções iniciam um kernel convidado especializado no espaço do usuário para dar suporte a aplicativos isolados confiáveis por eles.
Alguém pode se perguntar por que o gVisor precisa de seu próprio kernel, quando o kernel Linux já é de código aberto e facilmente acessível. , gVisor, Golang, , Linux, C. Golang. gVisor — Docker, Kubernetes OCI. Docker gVisor, gVisor runsc. Kubernetes «» gVisor «»-.
gVisor , . gVisor , , , . ( , Nabla , unikernel . Nabla hypercall). gVisor (passthrough), , , , GPU, . , gVisor 70% Linux, , , gVisor.
Amazon Firecracker
Amazon Firecracker — , AWS Lambda AWS Fargate. , « » (MicroVM) multi-tenant . Firecracker Lambda Fargate EC2 , . , , . Firecracker , , . Firecracker , . Linux ext4 . Amazon Firecracker 2017 , 2018 .
unikernel, Firecracker . micro-VM , . , micro-VM Firecracker 5 ~125 2 CPU + 256 RAM. 5 Firecracker .
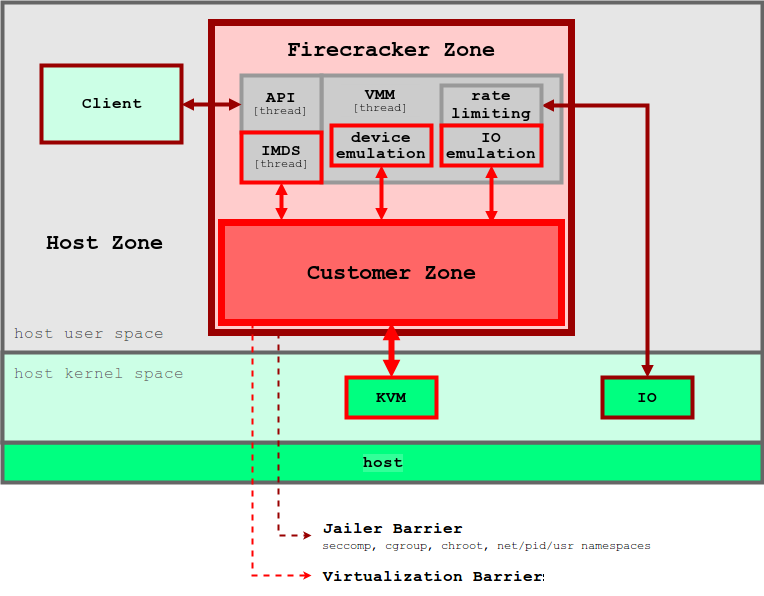 5. Firecracker
5. FirecrackerFirecracker KVM, . Firecracker seccomp, cgroups namespaces, , , . Firecracker . , API microVM. virtIO ( ). Firecracker microVM: virtio-block, virtio-net, serial console 1-button , microVM. . , , microVM File Block Devices, . , cgroups. , .
Firecracker Docker Kubernetes. Firecracker , , , . . , , OCI .
OpenStack Kata
, 2015 Intel Clear Containers. Clear Containers Intel VT QEMU-KVM
qemu-lite . 2017 Clear Containers Hyper RunV, OCI, Kata. Clear Containers, Kata .
Kata OCI, (CRI) (CNI). (, passthrough, MacVTap, bridge, tc mirroring) , , . 6 , Kata .
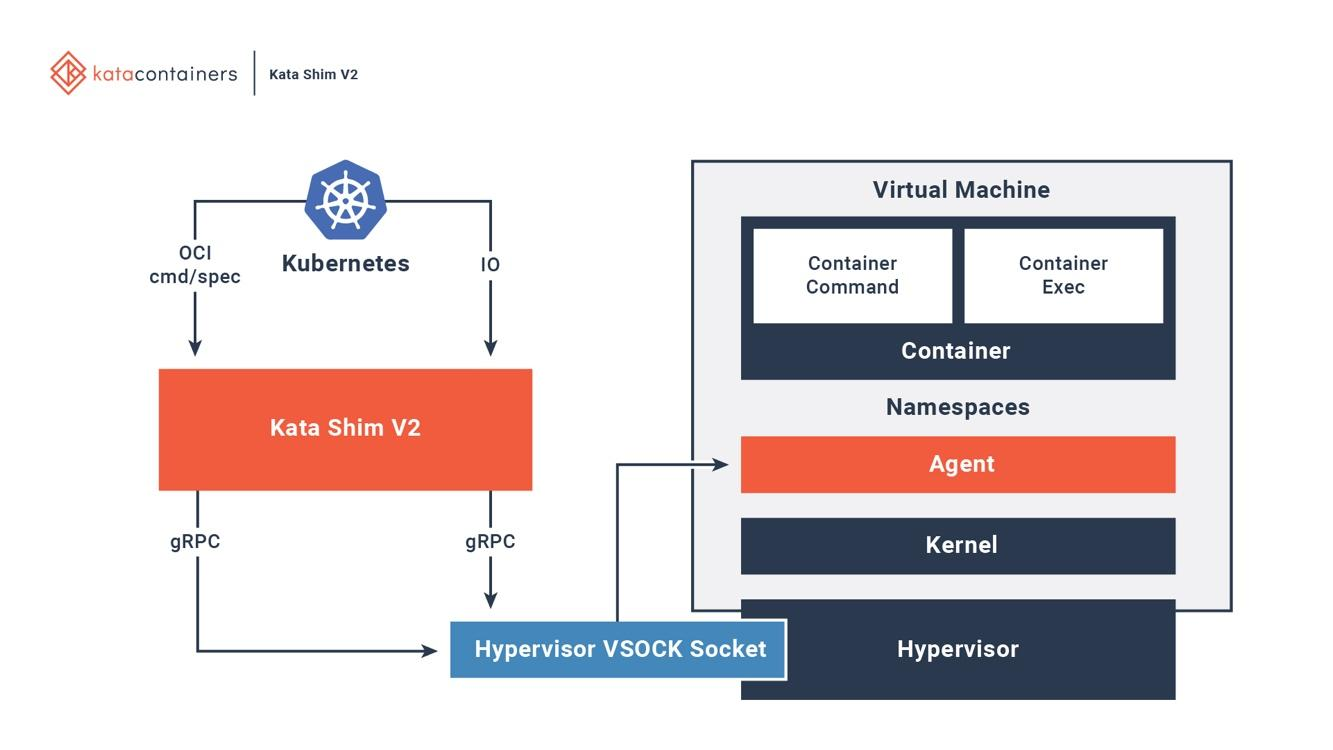 6. Kata Docker Kubernetes
6. Kata Docker KubernetesKata . Kata Kata Shim, API (, docker kubectl) VSock. Kata . NEMU — QEMU ~80% . VM-Templating Kata VM . , , , CVE-2015-2877. « » (, , , virtio), .
Kata Firecracker — «» , . , . Firecracker — , , Kata — , . Kata Firecracker. , .
Conclusão
, — .
IBM Nabla — unikernel, .
Google gVisor — , .
Amazon Firecracker — , .
OpenStack Kata — , .
, , . . Nabla , , unikernel-, MirageOS IncludeOS. gVisor Docker Kubernetes, - . Firecracker , . Kata OCI KVM, Xen. .
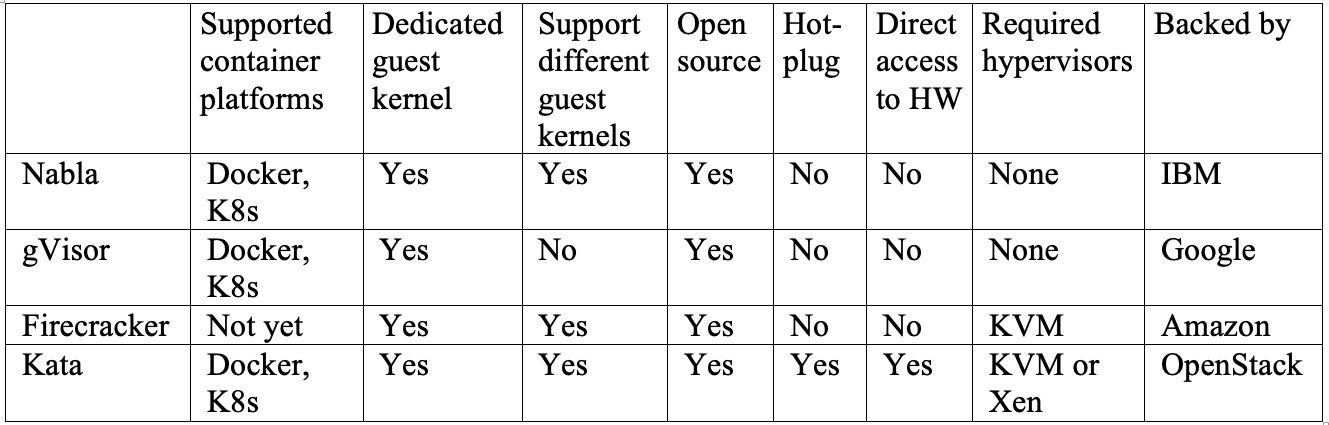
, , , , .