O ecossistema TensorFlow contém vários compiladores e otimizadores que trabalham em vários níveis da pilha de software e hardware. Para quem usa o Tensorflow diariamente, essa pilha de vários níveis pode gerar erros de difícil compreensão, tanto no tempo de compilação quanto no tempo de execução, associados ao uso de vários tipos de hardware (GPU, TPU, plataformas móveis, etc.)
Esses componentes, começando com o gráfico Tensorflow, podem ser representados na forma de um diagrama:
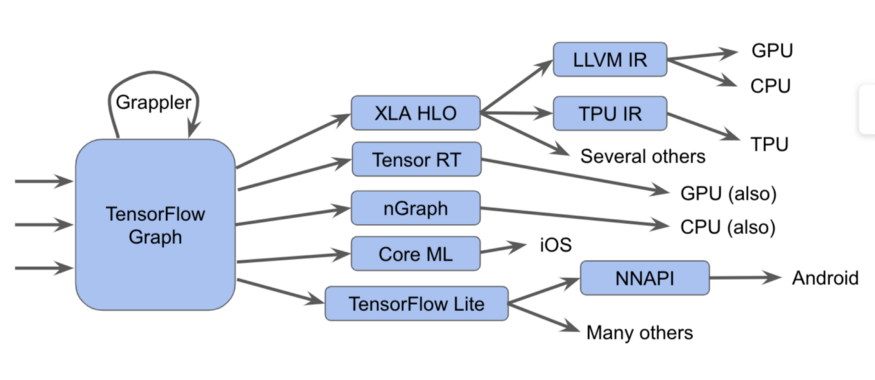 Na verdade é mais difícil
Na verdade é mais difícilNeste diagrama, podemos ver que os gráficos do Tensorflow podem ser executados de várias maneiras diferentes.
uma notaNo TensorFlow 2.0, os gráficos podem estar implícitos; a execução gananciosa pode executar operações individualmente, em grupos ou em um gráfico completo. Esses gráficos ou fragmentos do gráfico devem ser otimizados e executados.
Por exemplo:
- Enviamos os gráficos ao executor do Tensorflow, que chama kernels manuscritos especializados
- Converta-os em XLA HLO (representação XLA High-Level Optimizer) - uma representação de alto nível do otimizador XLA, que, por sua vez, pode chamar o compilador LLVM para a CPU ou GPU, ou continuar a usar XLA para TPU ou combiná-los.
- Nós os convertemos para TensorRT , nGraph ou outro formato para um conjunto de instruções especializado implementado em hardware.
- Nós os convertemos para o formato TensorFlow Lite , executado no tempo de execução do TensorFlow Lite ou convertido em código para ser executado na GPU ou DSP através da API de redes neurais do Android (NNAPI) ou similares.
Também existem métodos mais complexos, incluindo muitas passagens de otimização em cada camada, como, por exemplo, na estrutura Grappler, que otimiza as operações no TensorFlow.
Embora essas várias implementações de compiladores e representações intermediárias melhorem o desempenho, sua diversidade representa um problema para os usuários finais, como mensagens de erro confusas ao emparelhar esses subsistemas. Além disso, os criadores de novas pilhas de software e hardware devem ajustar as passagens de otimização e conversão para cada novo caso.
E em virtude de tudo isso, temos o prazer de anunciar a MLIR, uma Representação Intermediária Multinível. Este é um formato de visualização intermediária e bibliotecas de compilação para uso entre uma visualização de modelo e um compilador de baixo nível que gera código dependente de hardware. Apresentando o MLIR, queremos dar lugar a novas pesquisas no desenvolvimento de otimizadores de compiladores e implementações de compiladores baseados em componentes de qualidade industrial.
Esperamos que o MLIR seja do interesse de muitos grupos, incluindo:
- pesquisadores de compiladores e profissionais que desejam otimizar o desempenho e o consumo de memória dos modelos de aprendizado de máquina;
- fabricantes de hardware que procuram uma maneira de integrar seu hardware ao Tensorflow, como TPUs, neuroprocessadores móveis em smartphones e outros ASICs personalizados;
- pessoas que desejam dar às linguagens de programação os benefícios proporcionados pela otimização de compiladores e aceleradores de hardware;
O que é MLIR?
O MLIR é essencialmente uma infraestrutura flexível para os compiladores de otimização modernos. Isso significa que consiste em uma especificação de representação intermediária (IR) e um conjunto de ferramentas para transformar essa representação. Quando falamos de compiladores, passar de uma visão de nível superior para uma de nível inferior é chamado de redução, e usaremos esse termo no futuro.
O MLIR é construído sob a influência do LLVM e emprega descaradamente muitas boas idéias dele. Ele possui um sistema de tipos flexível e foi projetado para representar, analisar e transformar gráficos, combinando muitos níveis de abstração em um nível de compilação. Essas abstrações incluem operações de fluxo de tensão, regiões de loop poliédrico aninhadas, instruções LLVM e operações e tipos de ponto fixo.
Dialetos de MLIR
Para separar os vários alvos de software e hardware, o MLIR possui "dialetos", incluindo:
- TensorFlow IR, que inclui tudo o que pode ser feito nos gráficos do TensorFlow
- XLA HLO IR, projetado para obter todos os benefícios fornecidos pelo compilador XLA, cuja saída podemos obter código para TPU, e não apenas.
- Um dialeto de afinidade experimental projetado especificamente para representações e otimizações poliédricas
- LLVM IR, 1: 1 que corresponde à visualização LLVM nativa, permitindo que o MLIR gere código para a GPU e a CPU usando LLVM.
- TensorFlow Lite projetado para gerar código para plataformas móveis
Cada dialeto contém um conjunto de operações específicas, usando invariantes, como: "é um operador binário, e sua entrada e saída são do mesmo tipo".
Extensões MLIR
O MLIR não possui uma lista fixa e integrada de operações intrínsecas globais. Os dialetos podem definir tipos completamente personalizados e, assim, o MLIR pode modelar coisas como o sistema de tipos LLVM IR (com agregados de primeira classe), abstrações de idiomas de domínio, como tipos quantizados, importantes para aceleradores otimizados para ML e, no futuro, mesmo um sistema do tipo Swift ou Clang.
Se você deseja anexar um novo compilador de baixo nível a esse sistema, é possível criar um novo dialeto e descer do dialeto do gráfico TensorFlow ao dialeto. Isso simplifica o caminho para desenvolvedores de hardware e desenvolvedores de compiladores. Você pode direcionar o dialeto para diferentes níveis do mesmo modelo; os otimizadores de alto nível serão responsáveis por partes específicas do RI.
Para pesquisadores de compiladores e desenvolvedores de estruturas, o MLIR permite criar transformações em todos os níveis, você pode definir suas próprias operações e abstrações em RI, permitindo modelar melhor as tarefas de aplicativos. Portanto, o MLIR é mais do que uma infraestrutura pura de compilador, que é o LLVM.
Embora o MLIR funcione como um compilador para o ML, ele também permite o uso de tecnologias de aprendizado de máquina! Isso é muito importante para engenheiros que desenvolvem bibliotecas numéricas e não pode fornecer suporte para toda a variedade de modelos e hardware de ML. A flexibilidade do MLIR facilita a exploração de estratégias para descida de código ao se mover entre os níveis de abstração.
O que vem a seguir
Abrimos um
repositório do GitHub e convidamos todos os interessados (estude o nosso guia!). Estaremos lançando algo mais do que esta caixa de ferramentas - as especificações de dialeto TensorFlow e TF Lite, nos próximos meses. Podemos contar mais, para descobrir mais, veja a
apresentação de Chris Luttner e nosso
README no Github .
Se você deseja acompanhar todas as coisas relacionadas ao MLIR, junte-se à nossa
nova lista de discussão , que em breve se concentrará nos anúncios de versões futuras do nosso projeto. Fique conosco!