Sob o ponto de vista sobre qual abordagem a Huawei oferece ao organizar o acesso remoto remoto à memória usando a tecnologia AI Fabric e como ela difere do InfiniBand e do RDMA puro baseado em Ethernet.
A computação distribuída é usada em uma ampla variedade de indústrias. Trata-se de pesquisa científica e desenvolvimentos técnicos, como ferramentas de reconhecimento de rosto ou reconhecimento de piloto automático e indústria. Em geral, a análise de dados está encontrando cada vez mais aplicativos, e podemos dizer com confiança que, em um futuro próximo, não perderá popularidade. De fato, agora estamos passando por uma transição da era da computação em nuvem, onde os fatores mais importantes foram aplicativos e a velocidade da implantação de serviços, para a era da monetização de dados, inclusive através do uso de algoritmos de inteligência artificial. De acordo com nossos dados internos (relatório
GIV 2025: Revelando o modelo industrial de um mundo inteligente ), até 2025, 86% das empresas usarão a IA em seu trabalho. Muitos deles consideram essa área a principal para a modernização das atividades e, possivelmente, a ferramenta básica para tomar decisões de negócios no futuro. E isso significa que cada uma dessas empresas precisará de algum tipo de processamento de dados brutos - provavelmente através de clusters distribuídos.
A evolução da arquitetura
Com a crescente popularidade da computação distribuída, o volume de tráfego trocado entre máquinas individuais de data center aumenta. Tradicionalmente, ao discutir redes, a atenção está focada no crescimento do tráfego entre o data center e os usuários finais na Internet, e está realmente crescendo. Mas o aumento do tráfego horizontal em sistemas distribuídos excede em muito tudo o que os usuários geram. Segundo o Facebook, o tráfego entre seus sistemas internos dobra em menos de um ano.

Na tentativa de lidar com esse tráfego, você pode aumentar os clusters, mas não pode fazer isso indefinidamente. Portanto, prevendo o crescimento da carga de computação nos clusters, é necessário aumentar a eficiência do processamento - antes de tudo, encontrar e eliminar gargalos nessas redes distribuídas.
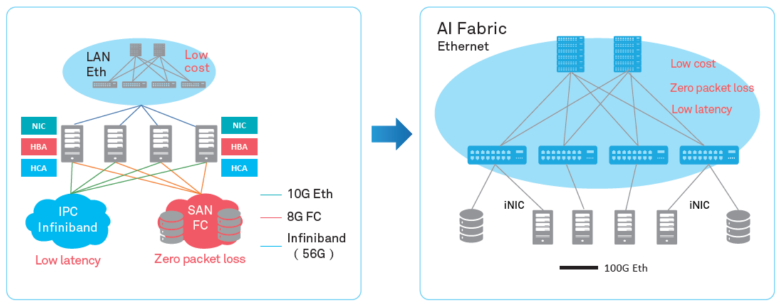
Se antes o “elo fraco” dos sistemas distribuídos era o recurso de cada um desses sistemas separadamente, enquanto o desenvolvimento constante de redes de transmissão de dados superava as necessidades, hoje são as comunicações em rede que são a principal fonte do problema. A familiar pilha de protocolos TCP / IP e a topologia em árvore não correspondem mais às tarefas atribuídas. Portanto, mais e mais datacenters estão abandonando o centralizado e estão migrando para uma nova arquitetura CLOS que fornece maior largura de banda e melhor escalabilidade de cluster, como, por exemplo, o Facebook fez há vários anos.

Ao mesmo tempo, é necessário otimizar o processo em um nível diferente - no nível de interação de dois sistemas separados. Neste artigo, queremos falar sobre quais ferramentas de otimização o data center da Huawei Ai Fabric fornece. Essa é a nossa tecnologia proprietária que acelera a troca de dados entre nós.
Alterações de rede
O principal "truque" do Huawei Ai Fabric é reduzir a sobrecarga ao transferir pacotes de dados entre sistemas dentro do cluster, implementando RDMA (Remote Direct Memory Access) - acesso direto à memória dos sistemas no cluster.
RDMA - uma maneira de reduzir os atrasos na transmissão
RDMA não é uma idéia nova. A tecnologia fornece troca direta de dados entre a memória e a interface de rede, reduzindo a latência e eliminando cópias desnecessárias de dados para buffers. Suas raízes remontam aos anos 90 pela Compaq, Intel e Microsoft.
Existem três tipos de atrasos na transmissão de um pacote de um sistema para outro:
- devido ao processamento do processador necessário, por exemplo, para armazenar dados no SO e calcular somas de verificação;
- devido a barramentos e canais de transmissão de dados (é tecnicamente impossível aumentar significativamente a largura de banda);
- devido ao equipamento de rede.

Para reduzir as perdas em toda essa cadeia, desde os anos 90, foi proposto o uso direto da memória dos sistemas em interação - um modelo abstrato da Arquitetura de Interface Virtual. Sua idéia principal é que aplicativos executados em dois sistemas interativos preenchem completamente a memória local e estabeleçam uma conexão P2P para transferência de dados sem afetar o sistema operacional. Dessa maneira, os atrasos na transmissão de pacotes podem ser significativamente reduzidos. Além disso, como o modelo VIA não implicava a colocação dos dados transmitidos em buffers intermediários, ele economizou os recursos necessários para a operação de cópia.

Em relação ao modelo abstrato, o VIA RDMA, como tecnologia, avançou ainda mais em direção à utilização otimizada de recursos. Em particular, ele não espera que o buffer seja preenchido para estabelecer uma conexão e permite conexões com vários computadores simultaneamente. Devido a isso, a tecnologia pode reduzir os atrasos de transmissão em até 1 ms, reduzindo a carga no processador.
InfiniBand vs Ethernet
As duas principais implementações de RDMA no mercado - o protocolo de transporte proprietário InfiniBand e o RDMA “puro” baseado em Ethernet, infelizmente não apresentam desvantagens.
O protocolo de transporte InfiniBand possui um mecanismo interno de controle de entrega de pacotes (proteção contra perda de dados), mas é suportado por equipamentos específicos e não é compatível com Ethernet. De fato, o uso desse protocolo fecha o data center de um fornecedor de equipamentos, o que acarreta certos riscos e promete dificuldades em termos de serviço (como a InfiniBand possui uma pequena participação de mercado, não será tão fácil encontrar especialistas). Bem, é claro, ao implementar o protocolo, você não pode usar o equipamento de rede IP existente.
O RDMA sobre Ethernet permite que você use equipamentos existentes na rede, suporta redes Ethernet, o que significa que será mais fácil encontrar especialistas em serviços. Comparado à Infiniband, isso reduz significativamente o custo de propriedade da infraestrutura e simplifica sua implantação.
A única desvantagem séria que impediu a ampla adoção do RDMA pela Ethernet é a falta de proteção contra a perda de pacotes, o que limita a largura de banda de toda a rede. Mecanismos de terceiros devem ser usados para reduzir a perda de pacotes ou impedir o congestionamento da rede. Seguimos por esse caminho, oferecendo nossos próprios algoritmos inteligentes para compensar as desvantagens do RDMA sobre Ethernet, mantendo suas vantagens na nova ferramenta - Huawei Ai Fabric.
Huawei AI Fabric - do seu jeito
O AI Fabric implementa RDMA sobre Ethernet, complementado por seu próprio algoritmo de gerenciamento de congestionamento de rede inteligente, que fornece perda de pacote zero, alta largura de banda de rede e baixo atraso de transmissão para fluxos RDMA.
O Huawei Ai Fabric é construído em padrões abertos e suporta uma variedade de equipamentos diferentes, o que otimiza o processo de implementação. No entanto, algumas ferramentas adicionais - complementos sobre padrões abertos, que permitem aumentar a eficiência da troca de dados, que discutiremos em publicações subseqüentes - estão disponíveis apenas para dispositivos fabricados pela Huawei. Os comutadores da série CloudEngine que suportam a solução possuem um chip integrado que analisa as características do tráfego e ajusta dinamicamente os parâmetros de rede, o que permite um uso mais eficiente do buffer do comutador. As características coletadas também são usadas para prever padrões de tráfego futuros.
Para quem isso é útil?
O Huawei Ai Fabric permite obter lucro em dois níveis.
Por um lado, a solução permite otimizar a arquitetura do data center - reduzindo o número de nós (devido à utilização mais otimizada dos recursos), criando um ambiente convergente sem a separação tradicional em sub-redes separadas, difíceis e caras de manter em partes. Usando a ferramenta, você não precisa selecionar sub-redes separadas para cada tipo de serviço no controlador de domínio (com seus próprios requisitos de rede). Você pode criar um único ambiente que fornece todos os serviços.

Por outro lado, o AI Fabric permite aumentar a velocidade da computação distribuída, especialmente onde você geralmente precisa acessar a memória de sistemas remotos. Por exemplo, a introdução da IA em qualquer campo implica um período de aprendizado do algoritmo, que pode incluir milhões de operações, de modo que o ganho de atraso em cada uma dessas operações resultará em uma aceleração séria do processo.
O efeito da introdução de uma ferramenta especializada, como o Huawei Ai Fabric, será perceptível em um data center com seis ou mais comutadores. Porém, quanto maior o data center, maior o lucro - devido à utilização ideal dos recursos, um cluster da mesma escala com o Ai Fabric proporcionará um desempenho mais alto. Por exemplo, um cluster de 384 nós pode obter o desempenho de um cluster "regular" de 512 nós. Além disso, a solução não possui restrições quanto ao número de comutadores físicos na infraestrutura. Pode haver dezenas de milhares (se você esquecer que os projetos geralmente são limitados ao tamanho do domínio administrativo).