Bom dia, Khabravchane. Trabalho na Veeam Software e sou um dos desenvolvedores da nossa solução de backup Linux. Por ocupação, encontrei o BTRFS. Mais recentemente, passou do status de "ainda não adequado" para o status de "estável". E enquanto seus primeiros usuários da rede discutiam áreas problemáticas e de estabilidade, nós da Veeam cutucamos uma varinha e tentamos fazer backup. Descobriu-se, para dizer o mínimo, não muito - é muito diferente, não como os sistemas de arquivos tradicionais. Eu tive que estudar muitos aspectos e coletar muitos ancinhos antes de aprendermos a trabalhar com ele. No processo de aprendizado, o BTRFS conseguiu me impressionar, tanto de uma maneira boa como não muito. Tenho certeza de que ela não deixará indiferente nenhum especialista em TI do mundo Linux: alguns cuspirão, outros elogiarão.
Se você já ouviu falar sobre esse sistema de arquivos, mas não sabe por que, está interessado nos detalhes ou procura por onde começar a conhecê-lo, convido você a conhecer.
1. Introdução
BTRFS (B-Tree Filesystem) - sistema de arquivos para sistemas operacionais do tipo Unix, baseado na técnica Copiar na Gravação (CoW), projetada para facilitar o dimensionamento do sistema de arquivos, um alto grau de confiabilidade e segurança dos dados, flexibilidade de configuração e facilidade de administração, mantendo ao mesmo tempo alta velocidade. Pelo menos é o que diz a
página principal do wiki .
Para cumprir as formalidades, listamos os principais recursos do btrfs:
- Tamanho máximo do arquivo 2 ^ 64 bytes
- Tabela de inodes dinâmicos
- Deduplicação de dados
- Armazenamento eficaz de arquivos de tamanhos muito pequenos e muito grandes
- Criando Subwolums e Snapshots
- Quotas de subvolume
- Soma de verificação para dados e metadados
- A capacidade de combinar várias unidades em um único sistema de arquivos
- Criando uma configuração RAID no nível do sistema de arquivos
- Compressão de dados
- Desfragmente dados em tempo real
Quero avisar imediatamente que o BTRFS está desenvolvendo ativamente e alguns pontos podem diferir de versão para versão. O link -
https://btrfs.wiki.kernel.org/index.php/Changelog, você pode descobrir quando qual funcionalidade foi adicionada, alterada ou corrigida.
Sim, o BTRFS é um sistema de arquivos jovem e moderno que resolve uma grande variedade de tarefas, mas não sem suas desvantagens:
- Seu desenvolvimento ativo leva a uma alteração em quaisquer pontos-chave nos quais utilitários de terceiros podem confiar ao trabalhar com ele.
- Apesar das garantias dos desenvolvedores sobre a estabilidade do BTRFS, os usuários encontram regularmente problemas que potencialmente levam à perda de dados. Como regra, eles são de natureza "flutuante", como resultado dos quais ainda não foram estudados e corrigidos.
- Alta suscetibilidade à fragmentação.
- Documentação escassa e às vezes desatualizada.
Uma página inteira é dedicada aos problemas do sistema de arquivos em diferentes versões dos kernels -
https://btrfs.wiki.kernel.org/index.php/Gotchas . Eu recomendo fortemente que você olhe para lá - acaba sendo muito interessante e não óbvio.
Estrutura BTRFS
O dispositivo BTRFS simplificado pode ser dividido nos seguintes níveis:

Os dispositivos de bloco estão localizados no nível mais baixo, representando um ou vários espaços de endereço físico separados (o mesmo "físico" que os próprios dispositivos de bloco, mas esses já são detalhes). Por meio de estruturas especiais, os blocos alocados de memória física são combinados em um único espaço de endereço virtual.
Estruturas e blocos de metadados com dados do usuário (extensões) já são endereçados em nível lógico. Como resultado, os dados localizados seqüencialmente em um nível lógico podem residir fisicamente em diferentes dispositivos de bloco.
As estruturas de metadados podem ser divididas em níveis. Obviamente, não os classificarei - existem muitos deles, e esses detalhes de baixo nível são o tópico de um artigo separado. É importante aqui que algumas estruturas na hierarquia acabem sendo de nível superior ao de outras e, no topo, haverá uma estrutura que é um subvolume.
Subvolume é um tipo de ponto de entrada, ou melhor, os elementos raiz do sistema de arquivos. Eles formam uma camada separada de representação de dados, que encapsula o trabalho das camadas inferiores, apresentando os dados do usuário da forma usual: diretórios e arquivos. Além disso, os sub-lobos são um elemento-chave do mecanismo CoW no BTRFS. Os mesmos arquivos em dois subvolumes podem ser os mesmos dados nos níveis mais baixos.
A última camada é a camada de dados. Como o usuário os vê. Esses são arquivos e diretórios localizados no subvolume.
Mas basta teoria. É hora de começar a praticar!
Btrfs-progs
Este é um conjunto padrão de utilitários para gerenciar o BTRFS. Dependendo do pacote de distribuição, o pacote com esses utilitários no repositório pode ter nomes diferentes:
btrfsprogs ,
btrfs-progs ,
btrfs-tools , etc. Se o seu repositório não tinha nada parecido, você sempre pode compilá-lo manualmente, as fontes não estão muito longe -
https://github.com/kdave/btrfs-progs .
Os utilitários mais importantes deste pacote são
btrfs e
mkfs.btrfs . A partir do segundo, eu acho, tudo está muito claro - é necessário criar BTRFS em um dispositivo de bloco. Primeiro, o
btrfs é o principal utilitário que permite fazer o resto. Uma espécie de "faca suíça".
Neste artigo, usei a versão v4.15.1. O utilitário está se desenvolvendo muito ativamente e há diferenças visíveis de versão para versão. Portanto, se você não possui o comando necessário, verifique a versão do utilitário
btrfs , pois ele pode já estar desatualizado.
Além disso, provavelmente, os utilitários
btrfsck e
btrfstune são encontrados no pacote.
- O primeiro deles serve para verificar se há erros no sistema de arquivos e, se necessário, para as correções subsequentes, ele não é recomendado - ele está em status obsoleto , sua funcionalidade foi movida para o comando btrfs check .
- O segundo permite executar algumas operações úteis no btrfs, por exemplo, alterar o identificador exclusivo do sistema de arquivos (FS UUID) ou ativar determinadas funcionalidades do sistema de arquivos.
Além dos utilitários listados acima, existem muitos outros utilitários no pacote, mas são principalmente necessários para depurar btrfs e não serão úteis para nós neste artigo.
Formatando um disco no BTRFS
Na prática, tudo é mais simples. Vamos começar com uma unidade.
A formatação de um único disco no btrfs ocorre com o comando usual:
mkfs.btrfs /dev/sdc -L single_drive
Em resposta, o utilitário emitirá os parâmetros do sistema de arquivos criado para o console:
btrfs-progs v4.15.1 See http://btrfs.wiki.kernel.org for more information. Label: single_drive UUID: 59307d69-6d2f-4d2e-aae2-a5189ad3c256 Node size: 16384 Sector size: 4096 Filesystem size: 1.00GiB Block group profiles: Data: single 8.00MiB Metadata: DUP 51.19MiB System: DUP 8.00MiB SSD detected: no Incompat features: extref, skinny-metadata Number of devices: 1 Devices: ID SIZE PATH 1 1.00GiB /dev/sdc
Vamos percorrer os parâmetros apresentados.
Ao marcar um dispositivo de bloco, o btrfs aplicará duplicação aos metadados e dados do sistema por padrão, e os dados do usuário permanecerão na mídia em uma única cópia. A criação de btrfs em vários discos ao mesmo tempo aplicará o perfil "RAID0" aos dados do usuário por padrão e "RAID1" aos metadados.
Este grupo de parâmetros é controlado usando duas chaves:
-d para dados e
-m para metadados e dados do sistema.
Mas há uma nuance ... As coisas são diferentes com os SSDs. O fato é que, se estivéssemos marcando uma unidade SSD (ou unidade flash), por padrão, o sistema de arquivos não duplicaria os metadados. Os SSDs podem estender a deduplicação de dados para prolongar a vida útil dos elementos de memória. I.e. tendo duas cópias lógicas dos dados, na verdade apenas uma será gravada no meio. Como resultado, quando um segmento de memória falha, "ambas as cópias" dos dados serão danificadas. Além disso, ao escrever dados duas vezes, o recurso SSD é simplesmente consumido mais rapidamente.
Para determinar o tipo de mídia, o btrfs verifica o conteúdo do arquivo
/ sys / block / DEV / fila / rotacional , onde "DEV" é o nome do dispositivo de bloco que está sendo verificado.
Obviamente, mesmo no caso de um SSD, o perfil de armazenamento pode ser forçado.
Para criar uma instância btrfs em vários dispositivos, especifique-os com um espaço:
sudo mkfs.btrfs /dev/sdc /dev/sdd -L double_drive
ou com perfis:
sudo mkfs.btrfs /dev/sdc /dev/sdd -d raid1 -m raid1 -L raid1_drive
Observe que a mídia não precisa ter o mesmo tamanho, mesmo que o espelhamento completo seja usado. No entanto, assim que não houver espaço suficiente na unidade menor para alocar memória, o sistema de arquivos exibirá uma mensagem indicando que não há espaço livre, embora fisicamente ainda possa haver espaço livre em outras mídias.
Montagem
A primeira montagem de btrfs criados recentemente não é diferente de outros sistemas de arquivos:
mount /dev/sdc /mnt
Se o sistema de arquivos estiver localizado em vários discos, para montagem, basta especificar qualquer um deles.
Em geral, montar btrfs sempre envolve montar um ou mais de seu subvolume. Se o comando mount não for especificado, qual subvolume deve ser montado, o btrfs lerá no registro especial o ID do subvolume, que deve ser montado por padrão. Esta entrada pode ser alterada posteriormente com o
btrfs set-default , mas quando você a monta pela primeira vez no btrfs, existe apenas um subvolume - o raiz. É ele especificado por padrão para montagem.
O submundo raiz no btrfs está sempre presente. Ele aparece junto com o sistema de arquivos e não está sujeito a alterações no futuro.
Existem duas maneiras de montar qualquer subvolume que não seja o padrão:
especifique o caminho do subvolume raiz btrfs:
mount -o subvol=/path/to/subvol /dev/sdc /mnt
especifique o ID do subvolume:
mount -o subvolid=257 /dev/sdc /mnt
Como já mencionado, um dos subvolumes btrfs é especificado como montado por padrão. Descubra qual é possível fazendo:
btrfs subvolume get-default /path/to/any/subvolume
Para instalar o submount padrão, você pode usar o comando:
btrfs subvolume set-default 258 /path/to/any/subvolume
O caminho para o subvolume, neste caso, é necessário apenas para indicar a instância btrfs específica à qual o comando se aplica. A propósito, isso não precisa ser um submundo; o caminho para qualquer diretório também é adequado.
O comando
mount aceita um grande número de opções para gerenciar os recursos do btrfs: desfragmentação, liberação de cache, compactação, vaca, registro, equilíbrio, suporte a ssd e até um vagão de várias coisas específicas do btrfs. Não os considerarei na estrutura deste artigo, porque eles são necessários para ajustar o sistema de arquivos e, na grande maioria dos casos, você pode ficar sem eles.
Subvolume é
Um subvolume é um elemento-chave do btrfs que executa várias funções:
- armazenamento de dados do usuário e outro subvolume,
- fornecer acesso aos dados (montagem),
- Mecanismo CoW
- criando instantâneos.
Numa primeira aproximação, o subvolume é um diretório normal. Você pode renomeá-los / movê-los, visualizar seu conteúdo, colocar e modificar arquivos dentro deles. Não são necessários utilitários especiais.
A criação e a exclusão de um subvolume são realizadas nos btrfs montados usando comandos especiais:
btrfs subvolume create /mnt/subvolume_name btrfs subvolume delete /mnt/subvolume_name
Observo que, se você tentar remover o subvolume usando o gerenciador de arquivos ou o utilitário
rm , a operação terminará com um erro de
operação não permitida (a operação não é permitida).
UPD: A partir da versão 4.18.0 do kernel, é possível excluir sub-voleios usando o utilitário
rm ou as ferramentas de gerenciamento de arquivos. Aparentemente, era um bug, não um recurso. Agradecimentos a Prototik
habravchanin pelo esclarecimento.
Após criar um subvolume, você pode ver suas propriedades:
btrfs subvolume show /mnt/subvolume_name Name: subx UUID: 09af45e8-d2b2-b342-8a92-fa270ac82d0a Parent UUID: - Received UUID: - Creation time: 2019-03-23 17:59:28 +0100 Subvolume ID: 268 Generation: 39 Gen at creation: 35 Parent ID: 260 Top level ID: 260 Flags: - Snapshot(s):
Vamos examinar as principais propriedades do subwolume:
- Nome - o nome do subvolume
- O UUID é um identificador exclusivo universal que serve principalmente para determinar as relações subwoofer-instantâneo,
- UUID pai - identificador do ancestral do subvolume do qual o atual é derivado,
- UUID recebido - identificador do ancestral do subvolume enviado via btrfs send ,
- ID do subvolume - um identificador exclusivo para posicionamento na árvore B,
- Geração - número da transação na última atualização dos metadados do subvolume,
- Geração na criação - número da transação no momento em que o subvolume foi criado,
- ID pai - identificador do subvolume no qual o atual está incorporado,
- O ID de nível superior é exatamente o mesmo que o ID principal,
- Bandeiras - bandeiras (na verdade, apenas 1 bandeira é somente leitura ),
- Instantâneos - uma lista de instantâneos obtidos deste subvolume.
O subvolume possui mais um parâmetro - esse é o caminho do elemento raiz btrfs. O caminho é exibido ao listar o subvolume:
btrfs subvolume list /path/to/any/btrfs/mountpoint
Mas aqui tudo é simples e claro - nem faz sentido citar a saída do comando.
Como nos comandos
get-default e
set-default , aqui você pode especificar o caminho para qualquer subvolume, o resultado disso não será alterado. Esse caminho é usado para encontrar o subbolum raiz btrfs. Após o qual toda a árvore subwolum é lida.
Se você tentar copiar um subvolume, por exemplo, com o utilitário
cp , a operação de cópia será bem-sucedida, mas, como resultado, não será criado um subvolume, mas um diretório regular. No entanto, o btrfs fornece uma ferramenta muito mais flexível para criar essas cópias - instantâneos.
O instantâneo é
O instantâneo também é um submundo, apenas com propriedades avançadas.
A principal diferença é que o instantâneo possui registros de qual subwolum foi produzido. Esses são os campos
UUID pai e
UUID recebido . No subwoofer, esses campos também estão presentes, mas estão sempre vazios. Portanto, de fato, um instantâneo e um subvolume são o mesmo.
Ao criar, você pode bloquear o instantâneo para alterações usando a opção
-r .
btrfs subvolume snapshot -r /path/to/subvol /path/to/snapshot
Nesse caso, é garantido que os arquivos permanecem no estado em que estavam no momento em que o instantâneo foi criado.
O sinalizador somente leitura também pode ser controlado manualmente, isso funciona para qualquer subvolume:
btrfs property get /path/to/subvol ro btrfs property set /path/to/subvol ro true
Se observarmos agora as propriedades do instantâneo, veremos o campo
UUID pai preenchido:
btrfs subvolume show /path/to/snapshot Name: subx UUID: d08612d8-596a-11e9-8647-d663bd873d93 Parent UUID: 09af45e8-d2b2-b342-8a92-fa270ac82d0a Received UUID: - Creation time: 2019-03-23 17:59:28 +0100 Subvolume ID: 269 Generation: 39 Gen at creation: 35 Parent ID: 260 Top level ID: 260 Flags: - Snapshot(s):
Um recurso importante da operação de captura instantânea é que ela não é recursiva. Em vez do subvolume aninhado, diretórios vazios serão criados na captura instantânea.
Vamos voltar ao exemplo a seguir.
No sistema de arquivos, existe um subwoofer "sub0", dentro do qual existe um subwoofer
subA e um diretório
dirB . Dentro de cada um deles estão
fileA e
fileB, respectivamente.
Remova o instantâneo:
btrfs subvolume snapshot sub0 snap0
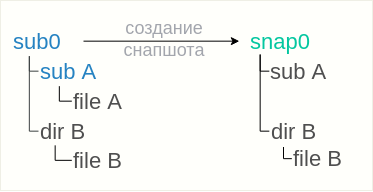
O instantâneo
snap0 criado herdará todos os arquivos e diretórios de seu pai, no entanto, o
subwoofer subA não aparecerá dentro do instantâneo. Em vez disso, apenas um diretório vazio aparecerá no instantâneo, ou seja, o conteúdo do
subvolume subA não será herdado.
Por um lado, isso é bom - removemos o instantâneo de um subvolume específico, e todos os aninhados não nos interessam. Por outro lado, se a captura instantânea recursiva for necessária, o btrfs não terá uma solução para esse problema. Teremos que procurar por rodadas de trabalho.
A primeira solução alternativa é baseada no fato de que o instantâneo foi removido sem um sinalizador somente leitura, o que permite corrigir a situação de maneira simples:
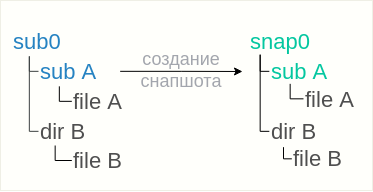
Se o instantâneo foi removido com o sinalizador somente leitura, a opção acima não funcionará, porque no
snap0, você não pode excluir o diretório nem colocar um instantâneo. Existe apenas uma opção - coloque instantâneos em algum lugar perto do
subwoofer snap0:
btrfs subvolume snapshot sub0/subA snapA
e, em seguida, monte
snapA dentro do instantâneo
snap0 , o diretório para isso já está lá:
mount -o subvol=snapA snap0/subA
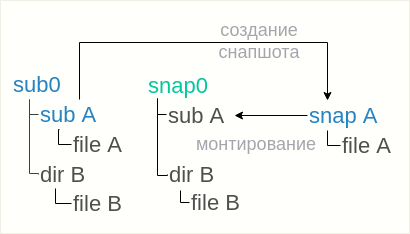
De qualquer forma, é importante entender que os instantâneos recursivos serão todos gravados em operações diferentes, em momentos diferentes. Não se pode falar em remoção atômica de um instantâneo de vários subvolumes.
Copiar na gravação
Um pouco sobre o subvolume e a abordagem CoW. Imagine que um subvolume está presente no sistema de arquivos e um arquivo está localizado nele (tome o caso ideal - o arquivo não está fragmentado). Em seguida, um instantâneo é removido do subwolly.

Um novo subvolume (captura instantânea) aparecerá no sistema de arquivos com exatamente o mesmo conteúdo que o subvolume original. O processo de criação de um instantâneo é quase instantâneo - os dados do próprio arquivo não são copiados. Em vez disso, metadados adicionais são criados e um instantâneo junto com o subvolume pai se torna o proprietário do arquivo. De fato, havia apenas um arquivo no disco, mas agora ele pertence ao subvolume e ao instantâneo.
Se você agora alterar o arquivo no subvolume, as alterações não afetarão o arquivo no instantâneo. Se o sinalizador somente leitura não foi definido ao criar o instantâneo, o arquivo no instantâneo também pode ser modificado.
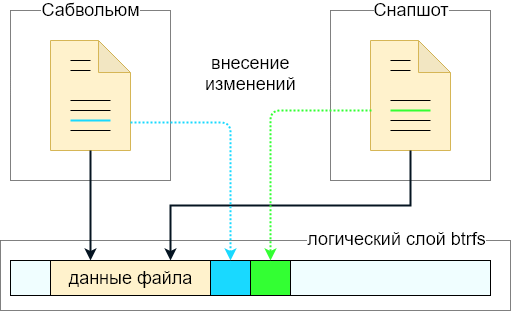
Tecnicamente, quando um arquivo é alterado, apenas essas alterações são registradas. Portanto, o arquivo de origem será armazenado no disco mais um delta que distingue o arquivo original do modificado. Se você excluir um dos subvolumes (no segundo, quero dizer um instantâneo), os dados em excesso que não são mais usados por ninguém serão apagados do disco e apenas a versão atual do arquivo permanecerá no disco (do ponto de vista do subvolume restante).
Uma breve observação : após a remoção, o subwoofer desaparecerá dos olhos do usuário instantaneamente e o utilitário retornará o controle ao terminal; no entanto, os dados no disco serão limpos pelo processo em segundo plano por algum tempo. Ou seja, diferente da remoção de um diretório regular, não há necessidade de aguardar a conclusão real da operação de exclusão. Se você precisar sincronizar com esse processo e aguardar a conclusão, poderá especificar a opção
--commit-after ao chamar
delete . O comando
btrfs subvolume list ,
chamado com a opção
-d , exibe uma lista de subvolumes que foram excluídos pelo usuário e estão atualmente no processo de serem excluídos do disco.
Além disso, o btrfs permite clonar arquivos no sistema de arquivos sem recorrer a capturas instantâneas. Isso é feito através da cópia regular com a
--reflink :
cp -ax --reflink=always /original/file /copied/file
A tecla
reflink=always indica ao sistema de arquivos que queremos usar o mecanismo CoW ao copiar. Após a cópia, os arquivos podem ser alterados independentemente um do outro, para que tenhamos o mesmo comportamento após a criação de um instantâneo. Então, por que precisamos de subbolums?
Os subtítulos no btrfs desempenham o papel de uma ferramenta de controle de alto nível para conjuntos de dados inteiros: primeiro, é a remoção de instantâneos atômicos de todos os dados de um subvolume (no caso de --reflink a atomicidade é apenas no nível do arquivo) e, em segundo lugar, é possível ver de quem é herdada. , ou "reverter" rapidamente o conjunto de dados para uma versão anterior etc.
Assim, o btrfs fornece a capacidade de capturar estados de arquivo nos momentos desejados, usando o subvolume como um meio de alto nível para gerenciar esses estados.
Recuperação de Subvolume
Nas vastas extensões, surge a pergunta: "Eu tenho um subwoofer, tenho um instantâneo, como fazer o inverso?" Essa abordagem não é aplicável ao btrfs, porque não há oportunidade de "retroceder o subwolly". Em vez disso, o btrfs oferece uma estratégia para substituir o subwolly por seu instantâneo. De fato, por que reverter algo, se o instantâneo em si é esse objeto que queremos obter com reversão.
Imagine este cenário: no btrfs, existe um subvolume no qual os arquivos de um banco de dados estão localizados (bem ou outros dados importantes). Os instantâneos são removidos periodicamente desse subvolume e, em algum momento, é necessário reverter os dados. Nesse caso, simplesmente nos livramos do subwolum e, em vez disso, começamos a usar o instantâneo retirado dele, ou - se não queremos estragar esses dados também - removemos outro instantâneo do instantâneo. Se o submundo original não foi montado e usado como um diretório normal, ele deve ser excluído ou movido / renomeado, e um instantâneo deve ser colocado em seu lugar.
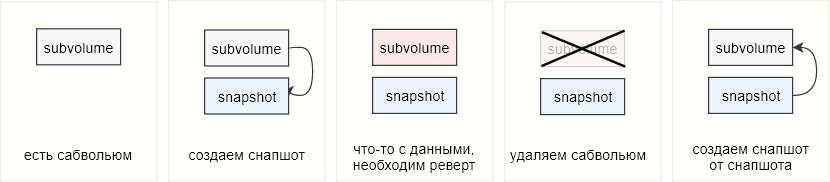
No console, pode ser algo como isto:
Se o subvolume foi montado e usado através do ponto de montagem, é suficiente desmontar o subvolume e montar uma captura instantânea em seu lugar.

Para completar, tentarei novamente e um pouco diferente. O subvolume no qual as alterações ocorrem é o ramo
principal .
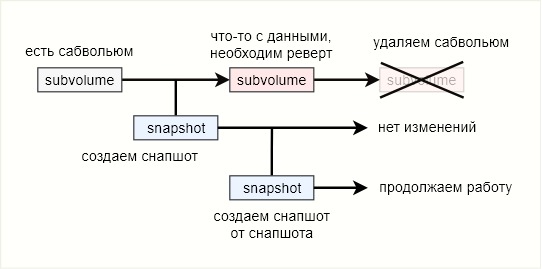
Ao criar um instantâneo, o estado dos arquivos no disco é corrigido. A partir de agora, um instantâneo é um brunch do ramo
principal . Todas as alterações adicionais no
main não afetarão o instantâneo de forma alguma. A reversão para a captura instantânea significa interromper o uso da ramificação
principal e mudar completamente para o brunch. O ramo
principal pode ser excluído por desnecessário. Assim, o btrfs é praticamente um sistema de controle de versão, mas sem a capacidade de mesclar ramificações.
Árvore do sistema de arquivos
Um dos pontos não óbvios associados ao uso de btrfs é como dividir os dados do sistema em subvolume. Obviamente, não existe uma abordagem "certa" para esse problema. Mas existem três maneiras de organizar a estrutura do subvolume: uma estrutura plana, aninhada e mista.
Uma estrutura plana significa que o subvolume é colocado em uma lista plana no subvolume raiz. Por exemplo, você pode selecionar a raiz do sistema de arquivos (vamos chamá-la de
raiz ), o diretório
inicial do usuário, o diretório com o site
/ var / www e o banco de dados localizado, por exemplo, em
/ var / database como subvolumes separados.
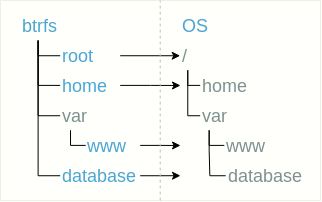
Por conveniência, algum subvolume pode ser colocado em diretórios, como, por exemplo, no caso do subvolume
var / www .
Com essa abordagem, todo o subvolume deve ser montado. O sub
raiz deve ter um ponto de montagem / e, dentro dele, deve conter os diretórios
home e
var .
Após a montagem da raiz na / home deve ser instalado sabvolyum casa , e no / var / www e / var / databas um e - sabvolyumy var / www e banco de dados , respectivamente.Portanto, a árvore do btrfs-subvolume pode ser exibida arbitrariamente no sistema de arquivos virtual do sistema operacional, e já existe o suficiente para isso.Prós:
- o usuário vê apenas o subvolume montado,
- é fácil substituir o subwoofer (desmonte um, monte o outro),
- fácil remover o subwoofer.
Contras:
- é fácil ficar confuso sobre onde instalá-lo,
- para cada subvolume deve haver uma entrada no fstab e, se houver “reversões” para capturas instantâneas, as entradas correspondentes no fstab também deverão ser atualizadas.
A estrutura aninhada do subvolume sugere um uso simples do subvolume em vez de alguns diretórios.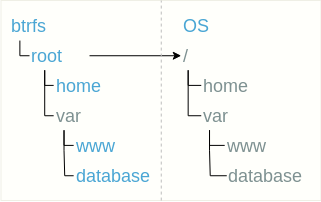 Nesse caso, além do subvolume raiz, nada mais é necessário para ser montado.
Nesse caso, além do subvolume raiz, nada mais é necessário para ser montado.Prós:
- todo subvolume é visível, a estrutura é fácil de perceber,
- você não precisa montar nada novamente, tudo é como em um sistema de arquivos "regular".
Contras:
- todos os subvolumes são visíveis, talvez alguns desejem se esconder do usuário,
- é difícil remover / substituir o subwolum (a razão para isso é subwolves aninhados).
Bem, a terceira abordagem é mista. Envolve uma combinação dos dois primeiros para maximizar os benefícios de ambos. No entanto, é possível que essa abordagem específica leve a uma estrutura complexa, difícil de mudar e confusa, com um grande número de entradas no fstab. Tudo depende da sobriedade do administrador do sistema.
Adicionar / remover disco, equilibrar
O btrfs possui excelente funcionalidade - a capacidade de "adicionar dispositivos de bloco quentes" diretamente durante a operação do sistema de arquivos: btrfs device add /path/to/device /path/to/btrfs
Ou exclua: btrfs device remove /path/to/device /path/to/btrfs
A propósito, em uma chamada de adição / exclusão, você pode especificar vários discos.Novamente, o caminho especificado é o caminho para qualquer subvolume daquele btrfs ao qual o comando será aplicado.Vamos verificar quantos e quais dispositivos de bloco estão sob controle do btrfs: btrfs filesystem show /path/to/btrfs Label: none uuid: 52961dda-df84-4e2d-9727-e93e7738df81 Total devices 2 FS bytes used 192.00KiB devid 1 size 20.00GiB used 132.00MiB path /dev/sdc devid 2 size 50.00GiB used 0.00B path /dev/sdd
0.00B no campo usado indica que o disco adicionado está vazio. Para preenchê-lo com dados de acordo com o perfil de gravação, você deve equilibrar: btrfs balance start /path/to/btrfs
O comando balance redistribui os dados nos discos de acordo com o perfil de gravação selecionado. Por exemplo, no caso do RAID1, o saldo levará à clonagem de dados do dispositivo original, no caso do RAID0, levará a uma distribuição mais uniforme dos dados entre dois discos, etc.Como resultado da balança, se antes havia vazios no disco, os dados no disco seriam gravados de maneira mais densa, ou seja, desfragmentação vai acabar. No entanto, é importante entender que isso não é exatamente essa desfragmentação. Nesse caso, o comando balance não analisa o conteúdo lógico, mas opera apenas em blocos de dados. Ela não presta atenção ao fato de que qualquer arquivo está espalhado no disco. Em vez disso, o saldo transfere os blocos de dados de um lugar para outro. I.e.
um arquivo fragmentado para equilibrar permanecerá fragmentado após ele. Mas! A fragmentação no nível dos blocos de dados ainda diminuirá, e isso pode ser usado.Para evitar confusão, digamos o seguinte: a operação de equilíbrio reduz a fragmentação no nível dos blocos de dados, mas não afeta a fragmentação do arquivo.Além disso, o comando balance fornece a capacidade de alterar o perfil de gravação. Por exemplo, o perfil DUP foi usado no disco e, após adicionar o disco, eles decidiram criar o RAID1 completo. Para fazer isso, use o filtro convert: btrfs balance start -dconvert=raid1 -mconvert=raid1 /path/to/btrfs
Usando as opções -dconverte, -mconvertnovos perfis de registro são definidos para dados e metadados, respectivamente. Há também a opção -sconvert, projetada para alterar o perfil de gravação de dados do sistema; no entanto, você também precisará adicionar a opção -f (--force) com ela para forçar a operação.Em geral, o principal objetivo dos filtros é definir as regras para a operação da balança: quais blocos processar e quais não tocar. Portanto, por exemplo, você pode afetar apenas os blocos gravados com um perfil de gravação específico (perfis de filtro) ou os blocos ocupados acima de uma determinada porcentagem (filtro de uso), ou pode afetar apenas grupos de blocos relacionados a um disco específico (filtro devid) etc. A propósito, eles ainda podem ser combinados. Em geral, as capacidades dos filtros são muito extensas e são principalmente necessárias para a realização de um balanço seletivo de dados.Fragmentação
Infelizmente, o btrfs, devido à sua arquitetura, é extremamente suscetível a um fenômeno como a fragmentação. O fato é que os dados são sempre gravados em um novo local no disco. Mesmo se você ler o arquivo, não faça nada com os dados e grave-o novamente no mesmo arquivo, os dados irão para uma nova área no disco. O mesmo acontece se você atualizar os dados no arquivo apenas parcialmente - as alterações serão gravadas em uma nova área no disco. Assim, as alterações frequentes fragmentam os arquivos com muita força, aumentando a "dispersão" dos fragmentos, no caso geral, em vários discos. Isso leva a um aumento da carga na CPU e a um consumo desnecessário de memória. Os mais fragmentados são bancos de dados e imagens de máquinas virtuais.Você pode avaliar a fragmentação do arquivo usando o utilitário filefrag (não incluído no btrfs-progs). filefrag /path/to/your/file
Ele mostra o número de extensões usadas para armazenar o arquivo. Simplificando - quanto menos extensões envolvidas, menos fragmentado o arquivo.Existem dois métodos para combater a fragmentação no btrfs: desfragmentação e a flag nocow.A desfragmentação pode ser aplicada a um único arquivo ou a um subvolume / diretório, incluindo recursivamente. O comando é o seguinte: btrfs filesystem defragment /path/to/file/or/dir
Devo dizer que essa equipe nem sempre leva aos resultados esperados. Arquivos pequenos e ligeiramente fragmentados (10 a 20 extensões) após a desfragmentação podem ser divididos em ainda mais partes. Além disso, a desfragmentação do btrfs em algumas versões do kernel interrompe a desduplicação de arquivos, tornando-as cópias físicas reais. I.e.
os instantâneos no nível físico se tornarão cópias completas.A segunda maneira de combater a fragmentação é com um atributo de arquivo nocow. chattr +C /path/to/file
O atributo nocowpode ser definido apenas para um arquivo novo ou vazio. Desativa a cópia no mecanismo de gravação , para que o btrfs sempre trabalhe com uma área de disco fixa ao atualizar o conteúdo de um arquivo, gravando dados sobre os existentes (no nível físico). Das desvantagens do nocow - também desabilita a verificação da soma de verificação para esse arquivo. Em outras palavras, sem vaca - sem soma de verificação.Claro, defina manualmente o atributonocowcada arquivo é uma tarefa ingrata. Se esse sinalizador do diretório / subvolume estiver definido, todos os novos arquivos criados nele herdarão o sinalizador automaticamente. O mesmo se aplica aos diretórios aninhados criados. Se no momento em que o atributo foi ativado, alguns dados já estavam no diretório, isso não os afetará de forma alguma - o atributo nocowpode ser definido apenas como um arquivo novo ou vazio.E outra maneira de definir o sinalizador automaticamente nocowé montar o sistema de arquivos com a opção nodatacow: mount -o subvol=path/to/subvol,nodatacow /dev/sdXX /path/to/mountpoint
Essa opção fará com que a opção se conecte automaticamente nodatasum, de modo que, para arquivos recém-criados, as somas de verificação não sejam calculadas.Como sempre, há uma nuance: você não pode montar apenas um subwoofer com uma opção nocow. Todo subvolume terá uma opção nocowou nenhuma. Tudo é decidido pelo primeiro subvolume montado: se tivesse uma opção especificada nodatacow, todas as montagens subsequentes irão automaticamente com essa opção.Um momento não óbvio surge se você colocar um sinalizador em um arquivo nocowe remover a captura instantânea do subvolume em que esse arquivo está localizado. Nesse caso, o btrfs ignora o sinalizador nocowse mais de um subvolume se referir ao bloco de dados atualizado. Portanto, apesar da bandeiranocow(a propósito, o arquivo também o herdará no instantâneo), as alterações em qualquer um dos arquivos serão direcionadas para uma nova área no disco e o arquivo novamente será fragmentado. Se o bloco de dados no arquivo for atualizado várias vezes, na primeira vez em que ele cair em uma nova área do disco, e com as entradas subseqüentes, ele será atualizado nessa nova área "no local".Truques e falhas
Ao usar o btrfs-progs, você pode omitir o nome completo do comando: btrfs sub cre = btrfs subvolume create
Basta a coincidência dos primeiros caracteres, que determinam exclusivamente o comando: su = subvolume, fi = filesystem, ba = balance, de = device;
Eu acho que o princípio é claro.Infelizmente, o btrfs não pode criar uma captura instantânea do diretório, mas há uma solução alternativa:Você nocownão pode definir o atributo para um arquivo de dados existente. No entanto, você pode seguir o seguinte caminho:Se o btrfs ficar sem espaço, até a exclusão de um arquivo poderá causar o erro "Sem espaço restante no dispositivo" . Para a solução, é recomendável conectar uma unidade temporária com tamanhos de preferência de pelo menos 1 GB aos btrfs. Depois limpe os dados. Em seguida, remova a unidade temporária.A operação de equilíbrio , chamada sem especificar perfis de gravação, os altera implicitamente de dup para raid1 . O que, aliás, está escrito na página Gotchas . Isso acontece depois de adicionar o disco ao btrfs, que usa o perfil de gravação dup . Lembre-se de que a formatação de uma única unidade no btrfs usa o perfil dup padrão para metadados e dados do sistema.Talvez o mais importante
Evite criar clones de baixo nível de dispositivos de bloco com btrfs. Sendo um sistema de arquivos “inteligente”, para algumas operações (geralmente na montagem) o btrfs relê os dados do sistema em dispositivos de bloco para encontrar todas as partes do sistema de arquivos. Se dois dispositivos de bloco com os mesmos UUIDs forem encontrados no processo de pesquisa, o btrfs os aceitará como parte da mesma instância. Se, ao mesmo tempo, esses dois dispositivos forem o original e seu clone, depois de montar o driver, você saberá como o sistema de arquivos funcionará, mas é claro que isso não terminará com nada de bom. Na pior das hipóteses, isso resultará em corrupção irreversível dos dados.Se você realmente deseja clonar discos com btrfs de uma maneira de baixo nível, deve-se tomar muito cuidado. Em geral, um clone não deve estar visível para o kernel do SO como um dispositivo de bloco enquanto o original estiver presente no sistema e vice-versa. Fornecendo essa condição, você pode alterar o UUID do clone (bem, ou o original, aqui opcional). O utilitário btrfstune que acompanha o pacote btrfs-progs ajudará : btrfstune -u /path/to/device
E novamente: o btrfstune , sendo um utilitário "inteligente", mudará o UUID não apenas no disco, mas em todo o sistema de arquivos. Isso significa que, quando chamada, ela lerá todos os dispositivos de bloco para substituir o UUID em todos os dispositivos relacionados ao sistema de arquivos.Em vez de uma conclusão
Se neste momento você não entende nada - isso é normal. O Btrfs não é trivial e pode não sucumbir imediatamente. Toda vez que me parecia que agora eu a entendia, ela jogava uma surpresa e a fazia repensar as coisas existentes. Não posso dizer que entendi tudo no momento atual - no processo de escrever encontrei algo novo, embora já tenha escrito com base em minha experiência.Eu compararia o processo de dominar o btrfs com a transição de um estilo de programação procedural para um estilo orientado a objetos. A primeira impressão é "uau, que incrível", mas, em seguida, você continua a escrever código processual agrupado em classes.No artigo, tentei não derramar água - para escrever tudo sobre o caso. Apesar disso, ficou bastante volumoso. Mas longe de tudo era possível dizer - você ainda pode escrever e escrever sobre btrfs. Este artigo é apenas a ponta do iceberg. O começo é entender sua filosofia e começar a usá-la. E agora é hora de terminar.Obrigado por ler até o fim. Espero que não esteja cansado. Escreva nos comentários sobre o que mais você gostaria de saber.Faça backups, senhores. E nunca deixe que eles sejam úteis.