Toloka é a maior fonte de dados etiquetados por máquina para tarefas de aprendizado de máquina. Todos os dias em Tolok, dezenas de milhares de artistas produzem mais de 5 milhões de classificações. Para qualquer pesquisa e experimentos relacionados ao aprendizado de máquina, são necessários grandes volumes de dados de qualidade. Portanto, estamos começando a publicar conjuntos de dados abertos para pesquisa acadêmica em várias áreas.
Hoje, compartilharemos links para os primeiros conjuntos de dados públicos e falaremos sobre como eles foram montados. Também mostraremos onde colocar o estresse no nome de nossa plataforma.
Um fato interessante: quanto mais complexa a tecnologia da inteligência artificial, mais ela precisa de ajuda humana. As pessoas categorizam imagens para treinar a visão computacional; As pessoas avaliam a relevância das páginas para pesquisar consultas. as pessoas convertem a fala em texto para que o assistente de voz aprenda a entender e falar. A máquina precisa de avaliações humanas para que funcione mais sem pessoas e melhor que as pessoas.
Anteriormente, muitas empresas coletavam tais avaliações exclusivamente com a ajuda de funcionários especialmente treinados - avaliadores. Mas, com o tempo, havia muitas tarefas no campo de aprendizado de máquina e, na maioria das vezes, as tarefas deixaram de exigir conhecimento e experiência especiais. Portanto, houve uma demanda pela ajuda da "multidão" (multidão). Mas, por si só, nem todos podem encontrar um grande número de artistas aleatórios e trabalhar com eles. As plataformas de crowdsourcing resolvem esse problema.
O Yandex.Toloka (corretamente pronunciado dessa maneira, com ênfase na última sílaba) é uma das maiores plataformas de crowdsourcing do mundo. Temos mais de 4 milhões de usuários registrados. Mais de 500 projetos coletam avaliações com a nossa ajuda todos os dias. Fato agradável: este ano, na seção Rotulagem de dados na conferência Data Fest, todos os seis palestrantes de diferentes empresas mencionaram Toloka como uma fonte de marcação para seus projetos.
Muito foi dito sobre o uso da Toloka nos negócios. Hoje falaremos sobre nossa outra área, que consideramos não menos útil.
Pesquisa em Tolok
O crowdsourcing e, em geral, a tarefa de coletar em massa marcações humanas, são praticamente os mesmos da aplicação industrial do aprendizado de máquina. Essa é uma área em que todas as empresas de tecnologia gastam muito dinheiro. Mas, ao mesmo tempo, por algum motivo, é ela quem investe muito em termos de pesquisa: no trabalho com multidões, em contraste com outras áreas da ML, relativamente poucos estudos e artigos sérios.
Nós gostaríamos de mudar isso. Nossa equipe vê o Toloka não apenas como uma ferramenta para resolver problemas aplicados, mas também como uma plataforma para pesquisa científica em várias áreas.
Conjuntos de dados públicos Toloka
Queremos apoiar a comunidade científica e atrair pesquisadores para o Toloka, por isso estamos começando a publicar conjuntos de dados para fins acadêmicos não comerciais. Eles podem ser de interesse para pesquisadores de diferentes direções: aqui estão os bots de bate-papo e dados para testar modelos de agregação de veredictos de tolkers, para pesquisa lingüística e para tarefas de visão computacional. Vamos falar sobre eles:
Toloka Persona Chat RusUm conjunto de dados de 10 mil diálogos ajudará os pesquisadores dos sistemas de diálogo a elaborar abordagens para o treinamento de bots de bate-papo. Nós o preparamos juntamente com o
iPavlov , um projeto do Laboratório de Sistemas Neurais e Deep Learning do MIPT, que realiza pesquisas no campo da inteligência artificial conversacional e desenvolve o
DeepPavlov , uma biblioteca aberta para a criação de assistentes interativos. O conjunto de dados Persona Chat Rus contém perfis que descrevem a personalidade de uma pessoa e diálogos entre os participantes do estudo.
Como os dados foram coletadosNo primeiro estágio, com a ajuda dos usuários do Toloka, coletamos perfis contendo informações sobre uma pessoa, seus hobbies, profissão, eventos familiares e de vida, e selecionamos aqueles que são adequados para diálogos.
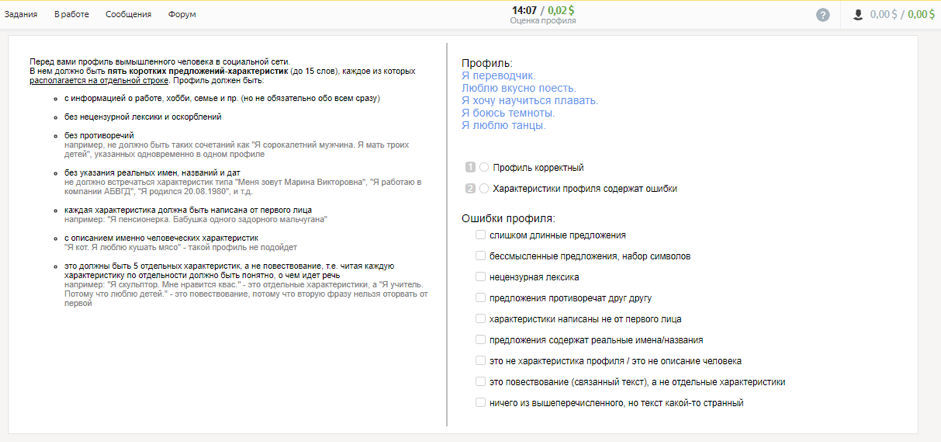
Na segunda etapa, convidamos os participantes a desempenhar o papel da pessoa descrita por um desses perfis e a se comunicar no messenger. O objetivo do diálogo é aprender mais sobre o interlocutor e falar sobre você. As caixas de diálogo resultantes foram verificadas por outros artistas.

Relevância 2 da agregação TolokaO conjunto de dados permite explorar métodos de controle de qualidade no crowdsourcing. Ele contém quase meio milhão de avaliações anônimas de artistas coletados no projeto “Relevância (2 graduações)” em 2016. Você encontrará aqui avaliações anônimas de tolokers e avaliações de referência que ajudarão a medir a qualidade das respostas. O estudo desses dados permitirá rastrear como as opiniões dos artistas afetam a qualidade da avaliação final, quais métodos de agregação de resultados são melhores para usar e quantas opiniões precisam ser coletadas para obter uma resposta confiável.
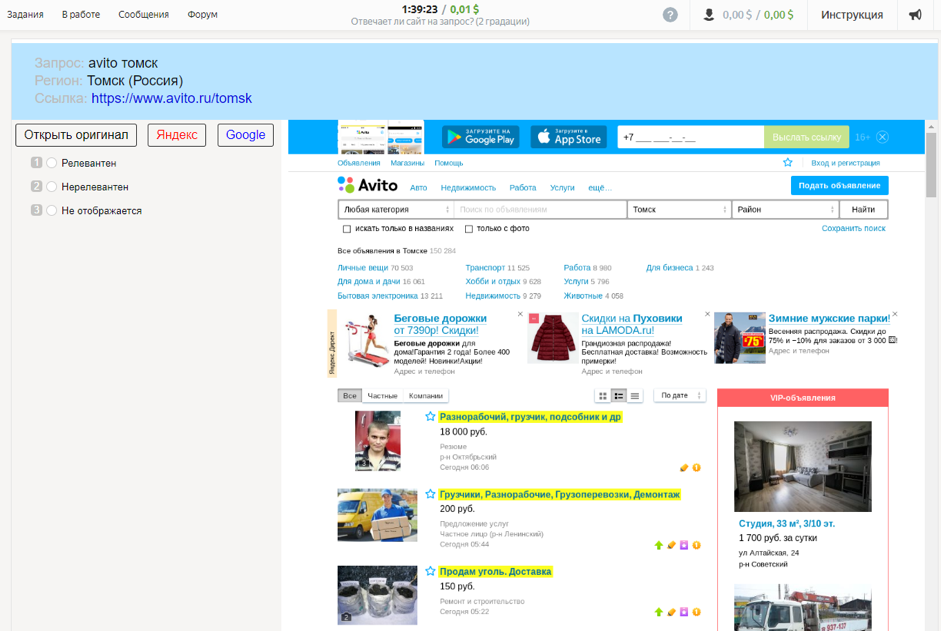
Como os dados foram coletadosFoi oferecido ao contratado a solicitação e a região do usuário que o definiu, uma captura de tela do documento e um link para ele, a capacidade de usar mecanismos de pesquisa e opções de resposta: “Relevante”, “Não relevante”, “Não exibido”.
Relevância da agregação Toloka 5Esse conjunto de dados é igual ao anterior, apenas as estimativas aqui foram coletadas não em formato binário, mas em uma escala de cinco pontos no projeto “Relevância (5 gradações)”. O conjunto de dados contém mais de um milhão de classificações.
Como os dados foram coletadosA avaliação de documentos para cinco séries é mais complexa e requer mais qualificações. Foi oferecido ao contratante a solicitação e a região do usuário que o definiu, uma captura de tela do documento e um link para ele, botões para o uso de mecanismos de pesquisa e cinco opções de resposta: “Vital”, “Útil”, “Relevante +”, “Relevante -”, “Irrelevante”.

O principal indicador de qualidade é a precisão das respostas agregadas, estimadas com base nas tarefas de controle (goldensets). Algumas tarefas no conjunto de dados não têm uma, mas várias respostas corretas. Qualquer uma dessas respostas é considerada correta. Precisão dos principais métodos de agregação:
● A opinião da maioria é de 89,92%.
● Dawid-Skene - 90,72%.
● GLAD - 90,16%.
Relações Léxicas da Sabedoria da Multidão (LRWC)O conjunto de dados contém as opiniões de falantes nativos da língua russa sobre a relação gênero-espécie entre as palavras: a conexão entre o geral (hiperônimo) e o privado (hipônimo). Coletado pelo pesquisador Dmitry Ustalov em 2017.
Como os dados foram coletadosPara o estudo, foram utilizados 300 dos substantivos mais usados nos russos modernos. Utilizando thesauri (RuTez, RuWordNet) e métodos automatizados para a formação de hiperônimos (Watset, Hyperstar), foram obtidos 10.600 pares de gêneros e espécies (do tipo “gatinho” - “mamífero”). Os participantes do estudo precisaram responder à pergunta: "É verdade que um gatinho é uma espécie de mamífero?" Para formular corretamente a questão, os hiperônimos foram colocados no caso genitivo usando um analisador morfológico e gerador de pymorphy2.
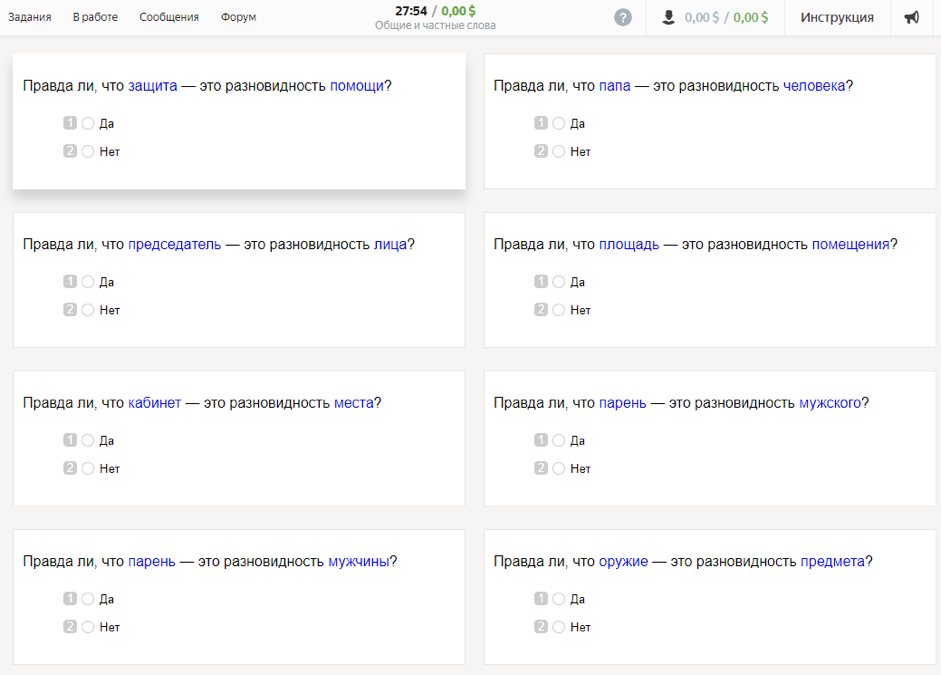
Cada par foi marcado por sete artistas de língua russa com mais de 20 anos. De acordo com os resultados obtidos após a agregação de todas as estimativas, 4576 pares de palavras receberam respostas positivas e 6024 - negativas. Curiosamente, os participantes do estudo foram mais unânimes em escolher uma resposta negativa do que positiva.
Contextos de palavras desanimadas por sentido anotado por humanos para russoO conjunto de dados contém 2562 significados contextuais de 20 palavras, representando a maior variedade de significados semânticos. O estudo foi realizado por Dmitry Ustalov em 2017.
Como os dados foram coletadosOs participantes do estudo receberam a palavra e um exemplo de seu uso na fala. Era necessário determinar o significado da palavra no contexto da expressão e escolher uma das opções de resposta.

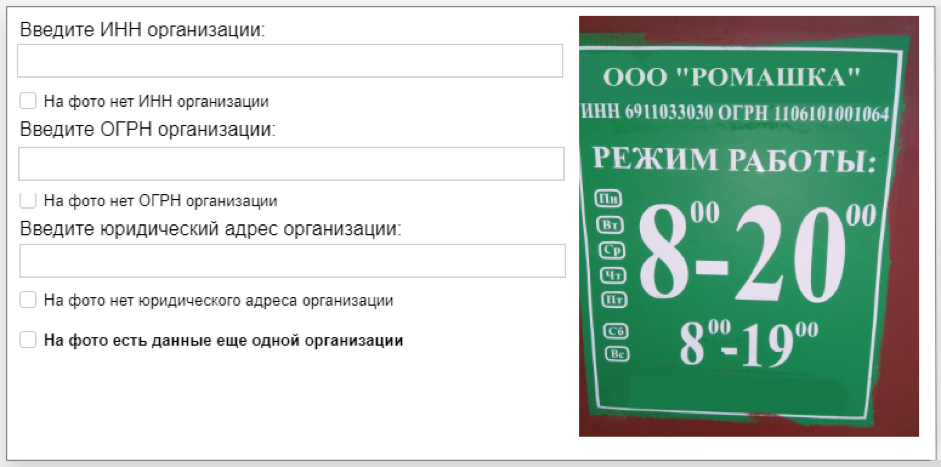
Reconhecimento de identificação comercial TolokaPara este conjunto de dados, preparamos 10 mil fotografias de placas informativas das organizações e um arquivo de texto com números (TIN e PSRN), que foram indicados na placa. Tendo aprendido com esses dados, o modelo de visão por computador poderá reconhecer a sequência de números na imagem. O conjunto de dados é fornecido pelo serviço Yandex.Directory.
Como os dados foram coletadosPrimeiro, lançamos a tarefa no aplicativo móvel Toloka: os artistas foram convidados a chegar ao endereço marcado no mapa, encontrar a organização e tirar uma foto da sua placa de informações. Esta e outras tarefas de campo ajudam a manter as informações atualizadas no Yandex.Directory.
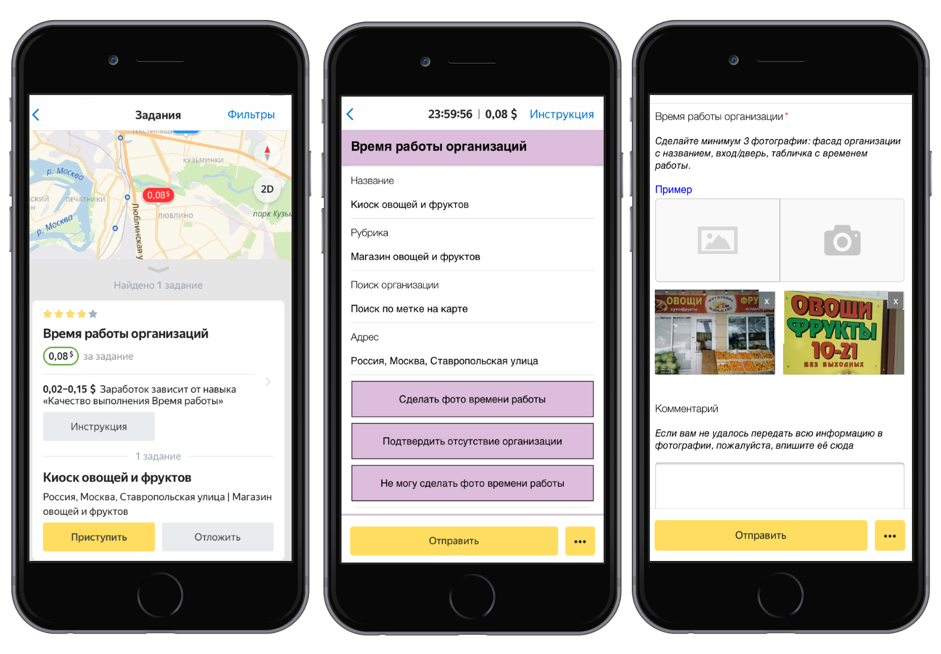
Em seguida, a qualidade das tarefas concluídas foi verificada por outros artistas. Enviamos as fotos com TIN e PSRN para descriptografia. Os Tolokers reimprimiram esses números a partir de fotos, após o que processamos os resultados e formamos um conjunto de dados.
Recursos de agregação TolokaO conjunto de dados contém cerca de 60 mil classificações em mil tarefas com as respostas corretas para quase todas as tarefas. Os artistas classificaram os sites em cinco categorias, de acordo com a disponibilidade de conteúdo adulto. Além de cada tarefa, são anexados 52 indicadores de valor real que podem ser usados para prever a categoria.
Você pode selecionar e baixar conjuntos de dados no link:
https://toloka.yandex.ru/datasets/ . Não planejamos insistir nisso e instamos os pesquisadores a prestarem atenção ao crowdsourcing e a falarem sobre seus projetos.