
Oi, habrozhiteli! Recentemente, entregamos um livro de
Chris Richardson à gráfica, cujo objetivo é ensinar o desenvolvimento bem-sucedido de aplicativos usando a arquitetura de microsserviços. O livro discute não apenas as vantagens, mas também as desvantagens dos microsserviços. Você aprenderá em que situações faz sentido aplicá-las e quando é melhor pensar em uma abordagem monolítica.
O livro enfoca arquitetura e design. Ele foi desenvolvido para qualquer pessoa cujas responsabilidades incluam a criação e entrega de software, incluindo desenvolvedores, arquitetos, diretores técnicos e chefes de departamentos de desenvolvimento.
A seguir, um trecho do livro Usando mensagens assíncronas
Usando mensagens assíncronas para melhorar a disponibilidade
Como você viu, os vários mecanismos do IPC levam você a vários compromissos. Um deles está relacionado a como o IPC afeta a acessibilidade. Nesta seção, você aprenderá que a interação síncrona com outros serviços como parte do processamento de solicitações reduz a disponibilidade do aplicativo. Nesse sentido, ao projetar seus serviços, você deve usar mensagens assíncronas sempre que possível.
Primeiro, vamos ver quais problemas a interação síncrona cria e como isso afeta a acessibilidade.
3.4.1 A interação sincronizada reduz a disponibilidade
O REST é um mecanismo IPC extremamente popular. Você pode ficar tentado a usá-lo para comunicação entre serviços. Mas o problema com o REST é que é um protocolo síncrono: o cliente HTTP precisa aguardar até que o serviço retorne uma resposta. Sempre que os serviços se comunicam por meio de um protocolo síncrono, isso reduz a disponibilidade do aplicativo.
Para entender por que isso acontece, considere o cenário mostrado na Fig. 3.15 O serviço de pedidos possui uma API REST para criar pedidos. Para verificar o pedido, ele se volta para os serviços de Consumidor e Restaurante, que também possuem uma API REST.
A criação de um pedido consiste nesta sequência de etapas.
- O cliente faz uma solicitação HTTP POST / orders ao serviço Order.
- O serviço de pedido recupera as informações do cliente fazendo uma solicitação HTTP GET / customers / id ao serviço de consumidor.
- O serviço de pedido recupera informações de restaurante executando uma solicitação HTTP GET / restaurant / id para o serviço de restaurante.
- Recebimento de pedidos verifica a solicitação usando informações sobre o cliente e o restaurante.
- Recebimento de pedidos cria um pedido.
- A Solicitação de Pedidos envia uma resposta HTTP ao cliente.
Como esses serviços usam HTTP, todos eles devem estar acessíveis para o FTGO processar a solicitação CreateOrder. Não será possível criar um pedido se pelo menos um dos serviços estiver indisponível. Do ponto de vista matemático, a disponibilidade de uma operação do sistema é um produto da disponibilidade dos serviços envolvidos nela. Se o serviço de pedidos e os dois serviços que ele chama tiver disponibilidade de 99,5%, sua disponibilidade geral será de 99,5% 3 = 98,5%, o que é muito menor. Cada serviço subsequente que participa da solicitação torna a operação menos acessível.
Esse problema não é exclusivo das interações baseadas em REST. A disponibilidade diminui sempre que um serviço precisa receber respostas de outros serviços para responder a um cliente. Mesmo a transição para um estilo de interação solicitação / resposta sobre mensagens assíncronas não ajudará aqui. Por exemplo, se o serviço de pedidos enviar uma mensagem ao serviço de consumidor por meio de um broker e começar a esperar por uma resposta, sua disponibilidade se deteriorará.
Se você deseja maximizar a acessibilidade, minimize a quantidade de interação síncrona. Vamos ver como fazer isso.
3.4.2 Livre-se da interação síncrona
Existem várias maneiras de reduzir a quantidade de interação síncrona com outros serviços ao processar solicitações síncronas. Em primeiro lugar, para evitar completamente esse problema, todos os serviços podem ser fornecidos com APIs exclusivamente assíncronas. Mas isso nem sempre é possível. Por exemplo, as APIs públicas geralmente aderem ao padrão REST. Portanto, é necessário que alguns serviços tenham APIs síncronas.
Felizmente, para processar solicitações síncronas, não é necessário executá-las. Vamos falar sobre essas opções.
Usando estilos de interação assíncronaIdealmente, toda interação deve ocorrer no estilo assíncrono descrito anteriormente neste capítulo. Imagine, por exemplo, que o cliente do aplicativo FTGO use um estilo de interação de solicitação assíncrona / resposta assíncrona para criar pedidos. Para criar um pedido, ele envia uma mensagem de solicitação ao serviço de pedidos. Em seguida, esse serviço troca mensagens de forma assíncrona com outros serviços e, eventualmente, retorna uma resposta ao cliente (Fig. 3.16).
O cliente e o serviço se comunicam de forma assíncrona, enviando mensagens pelos canais. Nenhum dos participantes dessa interação está bloqueado aguardando uma resposta.
Essa arquitetura seria extremamente robusta, porque o broker armazena em buffer as mensagens até que seu consumo seja possível. Mas o problema é que os serviços geralmente têm uma API externa que usa um protocolo síncrono como o REST e, como resultado, devem responder imediatamente às solicitações.
Se o serviço tiver uma API síncrona, a acessibilidade poderá ser aprimorada por meio da replicação de dados. Vamos ver como isso funciona.
Replicação de dadosUma maneira de minimizar a interação síncrona durante o processamento da consulta é replicar dados. O serviço armazena uma cópia (réplica) dos dados necessários para processar solicitações. Para manter a réplica atualizada, ela assina eventos publicados pelos serviços aos quais esses dados pertencem. Por exemplo, um serviço de pedidos pode armazenar uma cópia dos dados pertencentes aos serviços de consumidor e restaurante. Isso permitirá que ele processe solicitações para criar pedidos sem recorrer a esses serviços. Essa arquitetura é mostrada na fig. 3.17
Os serviços de consumidor e restaurante publicam eventos sempre que seus dados são alterados. O serviço de pedidos assina esses eventos e atualiza sua réplica.
Em alguns casos, a replicação de dados é uma boa solução. Por exemplo, o Capítulo 5 descreve como o serviço de pedidos replica os dados do serviço de restaurante para poder verificar itens de menu. Uma das desvantagens dessa abordagem é que, às vezes, é necessário copiar grandes quantidades de dados, o que é ineficiente. Por exemplo, se tivermos muitos clientes, armazenar uma réplica dos dados pertencentes ao serviço ao consumidor pode ser impraticável. Outra desvantagem da replicação reside no fato de que ela não resolve o problema de atualizar dados pertencentes a outros serviços.
Para resolver esse problema, um serviço pode atrasar a interação com outros serviços até responder ao seu cliente. Isso será discutido mais adiante.
Finalize o processamento após retornar uma respostaOutra maneira de eliminar a interação síncrona durante o processamento da consulta é executar esse processamento na forma das etapas a seguir.
- O serviço verifica a solicitação apenas com a ajuda dos dados disponíveis localmente.
- Ele atualiza seu banco de dados, incluindo a adição de mensagens à tabela OUTBOX.
- Retorna a resposta ao seu cliente.
Durante o processamento da solicitação, o serviço não acessa de forma síncrona nenhum outro serviço. Em vez disso, ele envia mensagens assíncronas. Essa abordagem fornece conectividade ruim de serviços. Como você verá no próximo capítulo, esse processo é frequentemente implementado como uma narrativa.
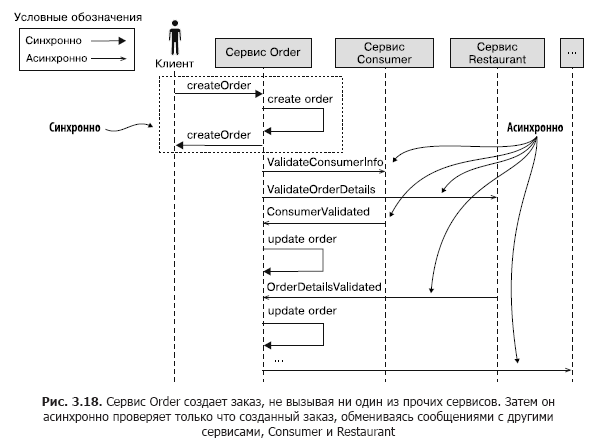
Imagine que o serviço de pedidos atue dessa maneira. Ele cria um pedido com o status PENDING e o verifica trocando mensagens assíncronas com outros serviços. Na fig. A Figura 3.18 mostra o que acontece quando a operação createOrder () é chamada. A cadeia de eventos é assim.
- O serviço Pedido cria um pedido com o status PENDENTE.
- O serviço de pedidos retorna uma resposta com o ID do pedido ao seu cliente.
- O serviço de pedidos envia uma mensagem ValidateConsumerInfo ao serviço de consumidor.
- O serviço de pedidos envia uma mensagem ValidateOrderDetails ao serviço de restaurante.
- O serviço ao consumidor recebe uma mensagem ValidateConsumerInfo, verifica se o cliente pode fazer um pedido e envia uma mensagem ConsumerValidated ao serviço do pedido.
- O serviço de restaurante recebe uma mensagem ValidateOrderDetails, verifica a correção dos itens de menu e a capacidade do restaurante de entregar um pedido em um determinado endereço e envia uma mensagem OrderDetailsValidated ao serviço de pedidos.
- O serviço de pedidos recebe mensagens ConsumerValidated e OrderDetailsValidated e altera o status do pedido para VALIDATED.
E assim por diante ...
O serviço de pedidos pode receber mensagens ConsumerValidated e OrderDetailsValidated em qualquer pedido. Para saber qual ele recebeu primeiro, ele altera o status do pedido. Se a primeira mensagem foi ConsumerValidated, o status do pedido muda para CONSUMER_VALIDATED e se OrderDetailsValidated muda para ORDER_DETAILS_VALIDATED. Após receber a segunda mensagem, o serviço de pedidos define o status do pedido como VALIDATED.
Após verificar o pedido, o serviço de pedidos executa as etapas restantes para criá-lo, as quais discutiremos no próximo capítulo. Uma grande parte dessa abordagem é que o serviço de pedidos pode criar um pedido e responder ao cliente, mesmo que o serviço ao consumidor esteja indisponível. Mais cedo ou mais tarde, o serviço ao consumidor recuperará e processará todas as mensagens pendentes, o que concluirá a verificação dos pedidos.
A desvantagem de retornar uma resposta antes que a solicitação seja completamente processada é que isso torna o cliente mais complexo. Por exemplo, quando o serviço de pedido retorna uma resposta, fornece garantias mínimas sobre o status do pedido que acabou de ser criado. Ele responde imediatamente, antes mesmo de verificar o pedido e autorizar o cartão bancário do cliente. Portanto, para descobrir se o pedido foi criado com sucesso, o cliente deve solicitar informações periodicamente ou o serviço de pedidos deve enviar uma mensagem de notificação. Apesar da complexidade dessa abordagem, em muitos casos vale a pena preferir, principalmente porque leva em conta os problemas com o gerenciamento de transações distribuídas, os quais discutiremos no capítulo 4. Nos capítulos 4 e 5, demonstrarei essa técnica usando o exemplo do serviço Order.
Sumário
- A arquitetura de microsserviços é distribuída, portanto, a comunicação entre processos desempenha um papel fundamental nela.
- O desenvolvimento do serviço API deve ser abordado com cuidado e cuidado. É mais fácil fazer alterações compatíveis com versões anteriores, porque elas não afetam a maneira como os clientes trabalham. Ao fazer alterações recentes na API de serviço, você geralmente precisa manter a versão antiga e a nova até que os clientes sejam atualizados.
- Existem muitas tecnologias IPC, cada uma com suas próprias forças e fraquezas. A principal decisão no estágio de design é a escolha entre a chamada de procedimento remoto síncrono e as mensagens assíncronas. Os mais fáceis de usar são protocolos síncronos como o REST, com base na chamada de procedimentos remotos. Mas, idealmente, para aumentar a acessibilidade, os serviços devem se comunicar usando mensagens assíncronas.
- Para evitar um acúmulo de falhas do tipo avalanche no sistema, um cliente que usa um protocolo síncrono deve ser capaz de lidar com falhas parciais - o fato de o serviço chamado estar indisponível ou exibir alta latência. Em particular, ao executar solicitações, é necessário contar o tempo de espera, limitar o número de solicitações em atraso e aplicar o modelo "Fusível" para evitar chamadas para o serviço com defeito.
- Uma arquitetura usando protocolos síncronos deve incluir um mecanismo de descoberta para que os clientes possam determinar o local de rede das instâncias de serviço. A maneira mais fácil é focar no mecanismo de descoberta fornecido pela plataforma de implantação: nos modelos "Descoberta pelo servidor" e "Registro de terceiros". Uma abordagem alternativa é a implementação da descoberta de serviço no nível do aplicativo: os modelos de descoberta e auto-registro do cliente. Este método requer mais esforço, mas é adequado para situações em que os serviços são executados em várias plataformas de implantação.
- O modelo de mensagem e canal encapsula os detalhes da implementação do sistema de mensagens e se torna uma boa opção ao projetar esse tipo de arquitetura. Posteriormente, você pode vincular sua arquitetura a uma infraestrutura de mensagens específica, que normalmente usa um broker.
- Uma das principais dificuldades nas mensagens é a publicação e atualização do banco de dados. Uma boa solução é usar o modelo de publicação de eventos: a mensagem é gravada no banco de dados no início, como parte da transação. Um processo separado recupera a mensagem do banco de dados usando o modelo Interrogating Publisher ou Transactional Log Tracking e a transmite ao broker.
»Mais informações sobre o livro podem ser encontradas no
site do editor»
Conteúdo»
TrechoPara Khabrozhiteley, desconto de 30% nos livros de pré-venda com cupom -
Microservices