(primeira parte aqui: https://habr.com/en/post/456446/ )
Ceph
1. Introdução
Como a rede é um dos elementos principais da Ceph e é um pouco específica em nossa empresa, primeiro falaremos um pouco sobre ela.
Haverá muito menos descrições do próprio Ceph, principalmente uma infraestrutura de rede. Apenas servidores Ceph e alguns recursos dos servidores de virtualização Proxmox serão descritos.
Portanto: a própria topologia de rede é criada como Leaf-Spine. A arquitetura clássica de três camadas é uma rede em que há Core (roteadores principais), Agregação (roteadores de agregação) e diretamente conectados aos clientes do Access (roteadores de acesso):
Esquema de três níveis
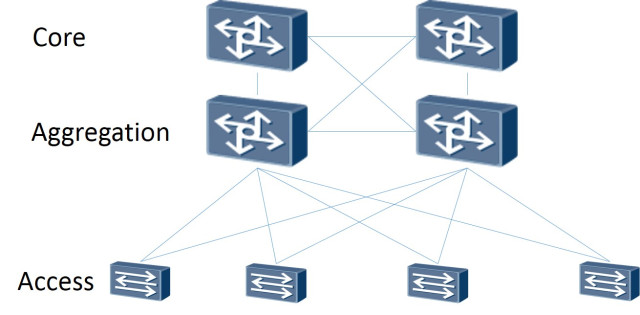
A topologia Leaf-Spine consiste em dois níveis: Spine (grosso modo o roteador principal) e Leaf (ramificações).
Esquema de dois níveis

Todo o roteamento interno e externo é construído no BGP. O principal sistema que lida com controle de acesso, anúncios e muito mais é o XCloud.
Os servidores para reserva de canal (e também para sua expansão) estão conectados a dois comutadores L3 (a maioria dos servidores está conectada aos comutadores Leaf, mas alguns servidores com maior carga de rede são conectados diretamente à coluna do comutador) e, por meio do BGP, anunciam seu endereço unicast, assim como qualquer endereço de broadcast para o serviço, se vários servidores atenderem ao tráfego do serviço e o balanceamento do ECMP for suficiente para eles. Um recurso separado desse esquema, que nos permitiu economizar endereços, mas também exigia que os engenheiros se familiarizassem com o mundo IPv6, era o uso do padrão não numerado BGP baseado na RFC 5549. Por algum tempo, Quagga foi usado para servidores no BGP para esse esquema para servidores e periodicamente houve problemas com a perda de festas e conectividade. Porém, depois de mudar para o FRRouting (cujos colaboradores ativos são nossos fornecedores de equipamentos de rede: Cumulus e XCloudNetworks), não observamos mais esses problemas.
Por conveniência, chamamos todo esse esquema geral de "fábrica".
Procure uma maneira
Opções de configuração de rede de cluster:
1) Segunda rede no BGP
2) A segunda rede em dois switches empilhados separados com LACP
3) Segunda rede em dois comutadores isolados separados com OSPF
Testes
Os testes foram realizados em dois tipos:
a) rede usando iperf, qperf, utilitários nuttcp
b) testes internos Ceph ceph-gobench, banco de rados, criou rbd e testou-os usando dd em um ou vários threads, usando fio
Todos os testes foram realizados em máquinas de teste com discos SAS. Os números no desempenho da rbd não foram muito analisados, foram usados apenas para comparação. Interessado em alterações, dependendo do tipo de conexão.
Primeira opção
As placas de rede estão conectadas à fábrica, configurada BGP.
O uso desse esquema para a rede interna não foi considerado a melhor opção:
Em primeiro lugar, o número excessivo de elementos intermediários na forma de comutadores, fornecendo latência adicional (esse foi o principal motivo).
Em segundo lugar, inicialmente, para transmitir estática no s3, eles usaram o endereço anycast gerado em várias máquinas com o radosgateway. Isso resultou no fato de que o tráfego das máquinas front-end para o RGW não foi distribuído uniformemente, mas passou pela rota mais curta - ou seja, o Nginx do front-end sempre virou para o mesmo nó com o RGW que estava conectado à folha compartilhada com ele (isso, é claro, era não é o argumento principal - simplesmente recusamos posteriormente os endereços anycast para retornar estático). Mas, pela pureza do experimento, eles decidiram realizar testes nesse esquema para obter dados para comparação.
Estávamos com medo de executar testes para toda a largura de banda, já que a fábrica é usada por servidores de produtos e, se bloquearmos os links entre a folha e a coluna, isso prejudicaria algumas das vendas.
Na verdade, esse foi outro motivo para rejeitar esse esquema.
Os testes Iperf com um limite de 3Gbps de 1, 10 e 100 fluxos de BW foram utilizados para comparação com outros esquemas.
Os testes mostraram os seguintes resultados:
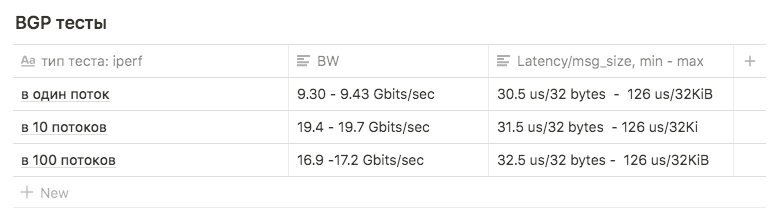
em 1 fluxo, aproximadamente 9,30 - 9,43 Gbits / s (nesse caso, o número de retransmissões aumenta fortemente, para 39148 ). A figura que se mostrou próxima ao máximo de uma interface sugere que uma das duas é usada. O número de retransmissões é de aproximadamente 500 a 600.
10 fluxos de 9,63 Gbits / s por interface, enquanto o número de retransmissões cresceu para uma média de 17045.
em 100 threads, o resultado foi pior que em 10 , enquanto o número de retransmissões é menor: o valor médio é 3354
Segunda opção
Lacp
Havia dois comutadores Juniper EX4500. Eles os coletaram na pilha, conectaram o servidor com os primeiros links para um switch, o segundo para o segundo.
A configuração inicial da ligação foi a seguinte:
root@ceph01-test:~# cat /etc/network/interfaces auto ens3f0 iface ens3f0 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f0 rx 8192 post-up /sbin/ethtool -G ens3f0 tx 8192 post-up /sbin/ethtool -L ens3f0 combined 32 post-up /sbin/ip link set ens3f0 txqueuelen 10000 mtu 9000 auto ens3f1 iface ens3f1 inet manual bond-master bond0 post-up /sbin/ethtool -G ens3f1 rx 8192 post-up /sbin/ethtool -G ens3f1 tx 8192 post-up /sbin/ethtool -L ens3f1 combined 32 post-up /sbin/ip link set ens3f1 txqueuelen 10000 mtu 9000 auto bond0 iface bond0 inet static address 10.10.10.1 netmask 255.255.255.0 slaves none bond_mode 802.3ad bond_miimon 100 bond_downdelay 200 bond_xmit_hash_policy 3 #(layer3+4 ) mtu 9000
Os testes iperf e qperf mostraram Bw de até 16 Gbits / s. Decidimos comparar diferentes tipos de mod:
rr, balance-xor e 802.3ad. Também comparamos diferentes tipos de hash layer2 + 3 e layer3 + 4 (na esperança de obter uma vantagem na computação em hash).
Também comparamos os resultados para diferentes valores sysctl da variável net.ipv4.fib_multipath_hash_policy, (bem, brincamos um pouco com net.ipv4.tcp_congestion_control , embora isso não tenha nada a ver com ligação . Há um bom artigo sobre ValdikSS para essa variável).
Mas em todos os testes, não funcionou para superar o limite de 18 Gbits / s (esse valor foi alcançado usando o balance-xor e o 802.3ad , não havia muita diferença entre os resultados dos testes) e esse valor foi atingido "in jump" por rajadas.
Terceira opção
OSPF
Para configurar esta opção, o LACP foi removido dos comutadores (o empilhamento foi deixado, mas foi usado apenas para gerenciamento). Em cada switch, eles coletaram uma vlan separada para um grupo de portas (de olho no futuro em que os servidores QA e PROD ficarão presos nos mesmos switches).
Configurou duas redes privadas planas para cada vlan (uma interface por switch). No topo desses endereços está o anúncio de outro endereço da terceira rede privada, que é a rede de cluster do CEPH.
Como a rede pública (através da qual usamos SSH) funciona no BGP, usamos frr para configurar o OSPF, que já está no sistema.
10.10.10.0/24 e 20.20.20.0/24 - duas redes planas nos comutadores
172.16.1.0/24 - rede para anúncio
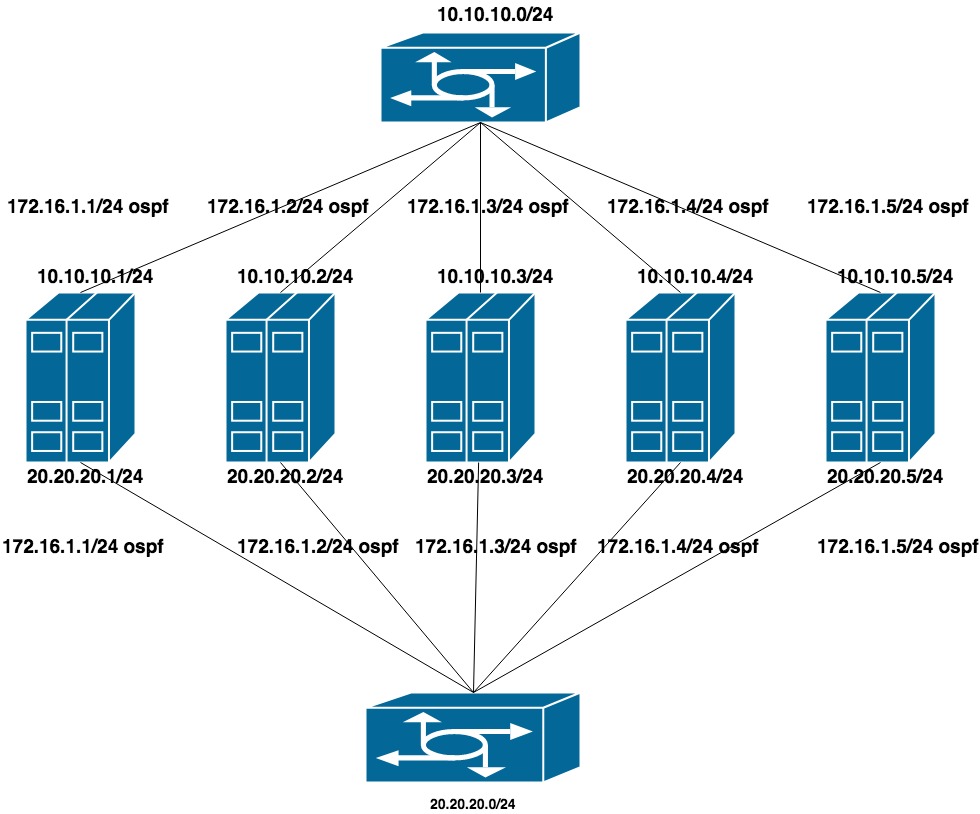
Configuração da máquina:
interfaces ens1f0 ens1f1 olham para uma rede privada
interfaces ens4f0 ens4f1 olhar para a rede pública
A configuração de rede na máquina é assim:
oot@ceph01-test:~# cat /etc/network/interfaces # This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback auto ens1f0 iface ens1f0 inet static post-up /sbin/ethtool -G ens1f0 rx 8192 post-up /sbin/ethtool -G ens1f0 tx 8192 post-up /sbin/ethtool -L ens1f0 combined 32 post-up /sbin/ip link set ens1f0 txqueuelen 10000 mtu 9000 address 10.10.10.1/24 auto ens1f1 iface ens1f1 inet static post-up /sbin/ethtool -G ens1f1 rx 8192 post-up /sbin/ethtool -G ens1f1 tx 8192 post-up /sbin/ethtool -L ens1f1 combined 32 post-up /sbin/ip link set ens1f1 txqueuelen 10000 mtu 9000 address 20.20.20.1/24 auto ens4f0 iface ens4f0 inet manual post-up /sbin/ethtool -G ens4f0 rx 8192 post-up /sbin/ethtool -G ens4f0 tx 8192 post-up /sbin/ethtool -L ens4f0 combined 32 post-up /sbin/ip link set ens4f0 txqueuelen 10000 mtu 9000 auto ens4f1 iface ens4f1 inet manual post-up /sbin/ethtool -G ens4f1 rx 8192 post-up /sbin/ethtool -G ens4f1 tx 8192 post-up /sbin/ethtool -L ens4f1 combined 32 post-up /sbin/ip link set ens4f1 txqueuelen 10000 mtu 9000 # loopback-: auto lo:0 iface lo:0 inet static address 55.66.77.88/32 dns-nameservers 55.66.77.88 auto lo:1 iface lo:1 inet static address 172.16.1.1/32
As configurações de Frr são assim:
root@ceph01-test:~# cat /etc/frr/frr.conf frr version 6.0 frr defaults traditional hostname ceph01-prod log file /var/log/frr/bgpd.log log timestamp precision 6 no ipv6 forwarding service integrated-vtysh-config username cumulus nopassword ! interface ens4f0 ipv6 nd ra-interval 10 ! interface ens4f1 ipv6 nd ra-interval 10 ! router bgp 65500 bgp router-id 55.66.77.88 # , timers bgp 10 30 neighbor ens4f0 interface remote-as 65001 neighbor ens4f0 bfd neighbor ens4f1 interface remote-as 65001 neighbor ens4f1 bfd ! address-family ipv4 unicast redistribute connected route-map redis-default exit-address-family ! router ospf ospf router-id 172.16.0.1 redistribute connected route-map ceph-loopbacks network 10.10.10.0/24 area 0.0.0.0 network 20.20.20.0/24 area 0.0.0.0 ! ip prefix-list ceph-loopbacks seq 10 permit 172.16.1.0/24 ge 32 ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32 ! route-map ceph-loopbacks permit 10 match ip address prefix-list ceph-loopbacks ! route-map redis-default permit 10 match ip address prefix-list default-out ! line vty !
Nessas configurações, a rede testa iperf, qperf etc. mostrou utilização máxima de ambos os canais em 19,8 Gbit / s, enquanto a latência caiu para 20us
Campo ID do roteador Bgp: usado para identificar o nó ao processar informações de roteamento e criar rotas. Se não especificado na configuração, um dos endereços IP do host é selecionado. Diferentes fabricantes de hardware e software podem ter algoritmos diferentes; no nosso caso, a FRR usou o maior endereço IP de loopback. Isso levou a dois problemas:
1) Se tentarmos desligar outro endereço (por exemplo, privado da rede 172.16.0.0) mais do que o atual, isso causou uma alteração no ID do roteador e, consequentemente, reinstalou as sessões atuais. Isso significa uma pequena interrupção e perda de conectividade de rede.
2) Se tentarmos desligar qualquer endereço de broadcast compartilhado por várias máquinas e ele tiver sido selecionado como um ID de roteador , dois nós com o mesmo ID de roteador aparecerão na rede .
Parte 2
Após testar o controle de qualidade, começamos a atualizar o Ceph de combate.
REDE
Passando de uma rede para duas
O parâmetro de rede do cluster é um daqueles que não podem ser alterados em tempo real, especificando o OSD via ceph tell osd. * Injectargs. Mudá-lo na configuração e reiniciar o cluster inteiro é uma solução tolerável, mas eu realmente não queria ter um pequeno tempo de inatividade. Também é impossível reiniciar um OSD com um novo parâmetro de rede - em algum momento, teríamos dois meio-clusters - OSDs antigos na rede antiga, novos no novo. Felizmente, o parâmetro de rede do cluster (assim como public_network, a propósito) é uma lista, ou seja, você pode especificar vários valores. Decidimos mudar gradualmente - primeiro adicione uma nova rede às configurações e remova a antiga. O Ceph percorre a lista de redes sequencialmente - o OSD começa a trabalhar primeiro com a rede listada primeiro.
A dificuldade era que a primeira rede funcionava através do bgp e estava conectada a um switch, e a segunda - ao ospf e conectada a outros que não estavam fisicamente conectados ao primeiro. No momento da transição, era necessário ter acesso temporário à rede entre as duas redes. A peculiaridade de montar nossa fábrica era que as ACLs não podem ser configuradas na rede se não estiverem na lista de anunciadas (neste caso, são "externas" e as ACLs só podem ser criadas externamente. Foi criada em spains, mas não chegou nas folhas).
A solução era uma muleta, complicada, mas funcionava: anunciar a rede interna via bgp, simultaneamente com ospf.
A sequência de transição é a seguinte:
1) Configure a rede de cluster para ceph em duas redes: através do bgp e do ospf
Nas configurações frr, não era necessário alterar nada, uma linha
ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32
não nos limita nos endereços anunciados, o endereço da rede interna é elevado na interface de loopback, basta configurar a recepção do anúncio desse endereço nos roteadores.
2) Adicione uma nova rede à configuração ceph.conf
cluster network = 172.16.1.0/24, 55.66.77.88/27
e comece a reiniciar o OSD, um de cada vez, até que todos mudem para a rede 172.16.1.0/24.
root@ceph01-prod:~#ceph osd set noout # - OSD # . , # , OSD 30 . root@ceph01-prod:~#for i in $(ps ax | grep osd | grep -v grep| awk '{ print $10}'); \ root@ceph01-prod:~# do systemctl restart ceph-osd@$i; sleep 30; done
3) Em seguida, removemos o excesso de rede da configuração
cluster network = 172.16.1.0/24
e repita o procedimento.
Isso é tudo, passamos sem problemas para uma nova rede.
Referências:
https://shalaginov.com/2016/03/26/network-topology-leaf-spine/
https://www.xcloudnetworks.com/case-studies/innova-case-study/
https://github.com/rumanzo/ceph-gobench