Neste artigo, falarei sobre como o projeto no qual trabalho passou de um grande monólito para um conjunto de microsserviços.
O projeto iniciou sua história há muito tempo, no início de 2000. As primeiras versões foram escritas no Visual Basic 6. Com o tempo, ficou claro que o desenvolvimento dessa linguagem no futuro seria difícil de suportar, uma vez que o IDE e a própria linguagem são pouco desenvolvidos. No final dos anos 2000, foi decidido mudar para um C # mais promissor. A nova versão foi escrita em paralelo com o refinamento da antiga, gradualmente mais e mais código estava no .NET. O back-end em C # inicialmente focado na arquitetura de serviço, no entanto, durante o desenvolvimento, bibliotecas compartilhadas com lógica foram usadas e serviços foram lançados em um único processo. Acabou o aplicativo, que chamamos de "monólito de serviço".
Uma das poucas vantagens desse pacote foi a capacidade dos serviços de se chamarem através de uma API externa. Havia pré-requisitos óbvios para a transição para um serviço mais correto e, no futuro, arquitetura de microsserviço.
Começamos nosso trabalho de decomposição por volta de 2015. Ainda não atingimos um estado ideal - há partes de um grande projeto que são difíceis de chamar de monólitos, mas elas também não se parecem com microsserviços. No entanto, o progresso é substancial.
Eu vou falar sobre ele no artigo.
Conteúdo
Arquitetura e problemas da solução existente
Inicialmente, a arquitetura era a seguinte: A interface do usuário é um aplicativo separado, a parte monolítica é escrita no Visual Basic 6, o aplicativo no .NET era um conjunto de serviços relacionados que trabalha com um banco de dados bastante grande.
Desvantagens da solução anteriorPonto único de falhaTivemos um único ponto de falha: o aplicativo .NET foi executado em um processo. Se algum dos módulos falhar, o aplicativo inteiro falhará e você precisará reiniciá-lo. Como estamos automatizando um grande número de processos para diferentes usuários, devido a uma falha em um deles, alguns não funcionaram por algum tempo. E com um erro de software, a redundância também não ajudou.
A linha de melhoriasEssa falha é bastante organizacional. Nossa aplicação tem muitos clientes e todos desejam finalizá-la o mais rápido possível. Anteriormente, era impossível fazer isso em paralelo, e todos os clientes ficavam na fila. Esse processo causou um efeito negativo nos negócios, porque eles precisavam provar que sua tarefa era valiosa. E a equipe de desenvolvimento passou um tempo organizando essa programação. Isso exigiu muito tempo e esforço e, como resultado, o produto não pôde ser alterado tão rapidamente quanto seria dele.
Uso inadequado de recursosAo colocar os serviços em um único processo, sempre copiamos completamente a configuração de servidor para servidor. Queríamos colocar os serviços mais carregados separadamente, para não desperdiçar recursos e obter um gerenciamento mais flexível de nosso esquema de implantação.
É difícil introduzir tecnologia modernaUm problema familiar a todos os desenvolvedores: há um desejo de introduzir tecnologias modernas no projeto, mas não há possibilidade. Com uma solução monolítica grande, qualquer atualização da biblioteca atual, sem mencionar a transição para uma nova, se transforma em uma tarefa não trivial. Demora muito tempo para provar ao líder da equipe que ele trará mais bônus do que os nervos gastos.
Dificuldade para emitir alteraçõesEsse foi o problema mais sério - lançamos lançamentos a cada dois meses.
Cada lançamento se transformou em um verdadeiro desastre para o banco, apesar dos testes e dos esforços dos desenvolvedores. Os negócios entenderam que no início da semana algumas das funcionalidades não funcionariam para ele. E os desenvolvedores entenderam que estavam esperando por uma semana de incidentes graves.
Todos queriam mudar a situação.
Expectativas de microsserviço
Entrega de componentes mediante disponibilidade. Entrega dos componentes à medida que se tornam disponíveis devido à decomposição da solução e separação de vários processos.
Pequenas equipes de alimentos. Isso é importante porque era difícil gerenciar uma grande equipe que trabalhava em um monólito antigo. Essa equipe foi forçada a trabalhar de acordo com um processo rigoroso, mas eu queria mais criatividade e independência. Somente equipes pequenas podiam pagar.
Isolamento de serviços em processos separados. Idealmente, eu queria isolar em contêineres, mas um grande número de serviços escritos no .NET Framework são executados apenas no Windows. Agora, existem serviços no .NET Core, mas até agora são poucos.
Flexibilidade de implantação. Eu gostaria de combinar serviços conforme necessário, e não como o código força.
Uso de novas tecnologias. Isso é interessante para qualquer programador.
Problemas de transição
Obviamente, se fosse simples dividir um monólito em microsserviços, você não precisaria falar sobre isso em conferências e escrever artigos. Neste processo, existem muitas armadilhas, descreverei as principais que interferiram conosco.
O primeiro problema é típico da maioria dos monólitos: a coerência da lógica de negócios. Quando escrevemos um monólito, queremos reutilizar nossas classes para não escrever código extra. E ao mudar para microsserviços, isso se torna um problema: todo o código está bem conectado e é difícil separar os serviços.
No início do trabalho, o repositório tinha mais de 500 projetos e mais de 700 mil linhas de código. Esta é uma solução bastante grande e o
segundo problema . Não foi possível simplesmente pegar e dividir em microsserviços.
O terceiro problema é a falta de infraestrutura necessária. De fato, estávamos envolvidos na cópia manual do código fonte nos servidores.
Como mudar de monólito para microsserviços
Alocação de microsserviçosPrimeiro, imediatamente determinamos por nós mesmos que a separação dos microsserviços é um processo iterativo. Sempre fomos obrigados a conduzir o desenvolvimento de tarefas de negócios em paralelo. Como vamos realizar isso tecnicamente já é nosso problema. Portanto, estávamos nos preparando para o processo iterativo. Não funcionará de maneira diferente se você tiver um aplicativo grande e não estiver pronto para ser reescrito desde o início.
Quais métodos usamos para isolar microsserviços?
A primeira maneira é portar os módulos existentes como serviços. Nesse sentido, tivemos sorte: já havia serviços formalizados que funcionavam no protocolo WCF. Eles foram lançados em montagens separadas. Nós os movemos separadamente, adicionando um pequeno iniciador a cada montagem. Foi escrito usando a maravilhosa biblioteca Topshelf, que permite executar o aplicativo como um serviço e como um console. Isso é conveniente para depuração, pois não são necessários projetos adicionais na solução.
Os serviços foram conectados de acordo com a lógica comercial, pois usavam assemblies comuns e trabalhavam com um banco de dados comum. Era difícil chamá-los de microsserviços em sua forma pura. No entanto, poderíamos emitir esses serviços separadamente, em diferentes processos. Isso já permitiu reduzir sua influência um sobre o outro, reduzindo o problema com o desenvolvimento paralelo e um único ponto de falha.
Construir com um host é apenas uma linha de código na classe Program. Escondemos a prateleira superior em uma classe auxiliar.
namespace RBA.Services.Accounts.Host { internal class Program { private static void Main(string[] args) { HostRunner<Accounts>.Run("RBA.Services.Accounts.Host"); } } }
A segunda maneira de isolar microsserviços: crie-os para resolver novos problemas. Se o monólito não cresce ao mesmo tempo, isso já é excelente, o que significa que estamos nos movendo na direção certa. Para resolver novos problemas, tentamos fazer serviços separados. Se houve essa oportunidade, criamos mais serviços "canônicos" que controlam completamente seu modelo de dados, um banco de dados separado.
Como muitos, começamos com serviços de autenticação e autorização. Eles são perfeitos para isso. Eles são independentes, como regra, eles têm um modelo de dados separado. Eles mesmos não interagem com o monólito, apenas ele se volta para eles para resolver alguns problemas. Nesses serviços, você pode iniciar a transição para uma nova arquitetura, depurar a infraestrutura neles, experimentar algumas abordagens relacionadas às bibliotecas de rede etc. Em nossa organização, não há equipes que não pudessem fazer um serviço de autenticação.
A terceira maneira de isolar os microsserviços que usamos é um pouco específica para nós. Isso está retirando a lógica de negócios da camada da interface do usuário. Temos o aplicativo principal da interface do usuário da área de trabalho, que, como o back-end, é escrito em C #. Os desenvolvedores periodicamente cometiam erros e executavam as partes da lógica da interface do usuário que deveriam existir no back-end e reutilizadas.
Se você observar um exemplo real do código da parte da interface do usuário, poderá ver que a maior parte desta solução contém lógica de negócios real, que é útil em outros processos, não apenas na criação de um formulário de interface do usuário.
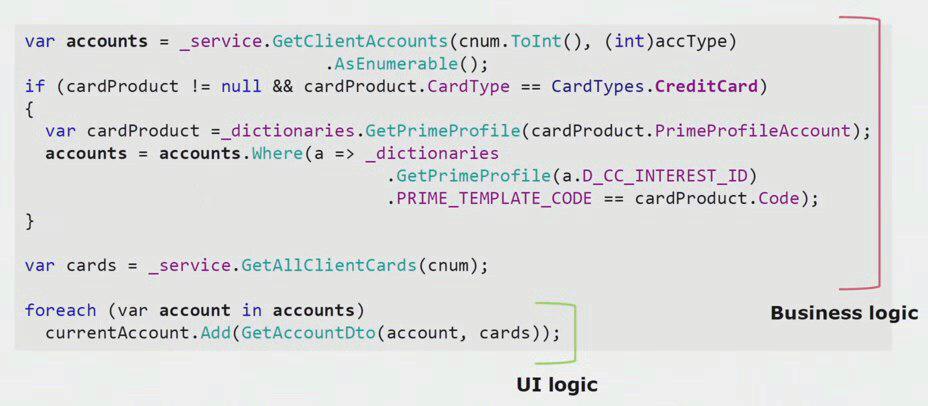
A lógica real da interface do usuário existe apenas as duas últimas linhas. Nós o transferimos para o servidor para podermos reutilizá-lo, reduzindo assim a interface do usuário e alcançando a arquitetura correta.
A quarta maneira mais importante de isolar microsserviços , o que permite reduzir o monólito, é a remoção dos serviços existentes com o processamento. Quando retiramos os módulos existentes, o resultado nem sempre é agradável para os desenvolvedores e o processo de negócios a partir do momento em que a funcionalidade foi criada pode ficar desatualizado. Graças à refatoração, podemos oferecer suporte a um novo processo comercial, porque os requisitos comerciais estão mudando constantemente. Podemos melhorar o código fonte, remover defeitos conhecidos, criar um melhor modelo de dados. Há muitas vantagens.
O departamento de serviços de processamento está intimamente ligado ao conceito de um contexto limitado. Este é um conceito do design orientado ao assunto. Significa uma seção de modelo de domínio na qual todos os termos de um único idioma são definidos exclusivamente. Considere o contexto de seguros e contas como um exemplo. Temos uma aplicação monolítica e é necessário trabalhar com a conta no seguro. Esperamos que o desenvolvedor encontre a classe "Account" existente em outro assembly, faça um link para ele a partir da classe "Insurance" e obteremos um código funcional. O princípio DRY será respeitado, a tarefa através do uso do código existente será realizada mais rapidamente.
Como resultado, verifica-se que os contextos de contas e seguros estão conectados. Quando novos requisitos surgem, essa conexão interfere no desenvolvimento, aumentando a complexidade de uma lógica de negócios já complexa. Para resolver esse problema, você precisa encontrar os limites entre os contextos no código e remover suas violações. Por exemplo, no contexto do seguro, é bem possível que o número da conta de 20 dígitos do Banco Central e a data de abertura da conta sejam suficientes.
Para separar esses contextos limitados um do outro e iniciar o processo de extração de microsserviços de uma solução monolítica, usamos uma abordagem como a criação de APIs externas no aplicativo. Se soubéssemos que algum módulo deveria se tornar um microsserviço, de alguma forma mudar dentro do processo, imediatamente fizemos chamadas para a lógica, que pertence a outro contexto limitado, através de chamadas externas. Por exemplo, através de REST ou WCF.
Decidimos por nós mesmos que não evitaríamos código que exigiria transações distribuídas. No nosso caso, foi bastante fácil cumprir essa regra. Ainda não encontramos essas situações em que transações realmente distribuídas são realmente necessárias - a consistência final entre os módulos é suficiente.
Considere um exemplo específico. Temos o conceito de uma orquestra - transportadora, que processa a essência da "aplicação". Ele alterna a criação de clientes, contas e cartões bancários. Se o cliente e a conta foram criados com êxito e a criação do cartão falhou, o aplicativo não entra no status "com êxito" e permanece no status "cartão não criado". No futuro, a atividade em segundo plano irá buscá-la e encerrá-la. O sistema está em estado de inconsistência por algum tempo, mas isso, no geral, nos convém.
Se, no entanto, surgir uma situação em que será necessário salvar parte dos dados de maneira consistente, provavelmente iremos aumentar o serviço para processar isso em um único processo.
Vamos considerar um exemplo de alocação de microsserviço. Como ele pode ser trazido para produção com relativa segurança? Neste exemplo, temos uma parte separada do sistema - o módulo de serviço de salário, uma das seções do código da qual gostaríamos de fazer microsserviço.
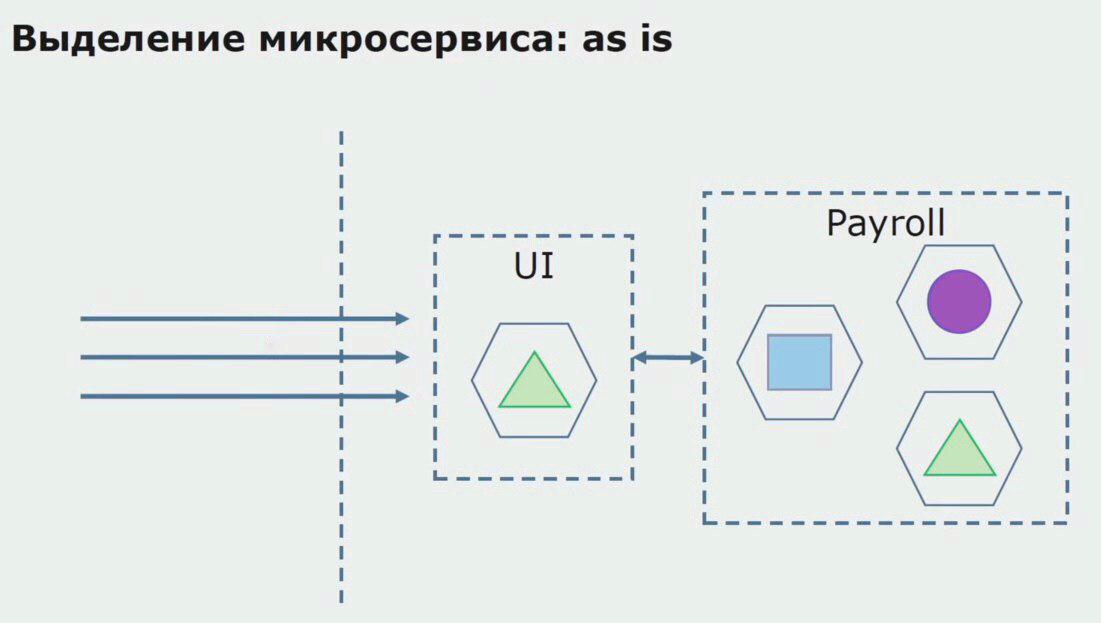
Primeiro, criamos um microsserviço reescrevendo o código. Melhoramos alguns pontos que não nos agradaram. Atendemos novos requisitos de negócios do cliente. Adicionamos ao pacote entre a interface do usuário e o back-end da API do Gateway, que fornecerá o encaminhamento de chamadas.
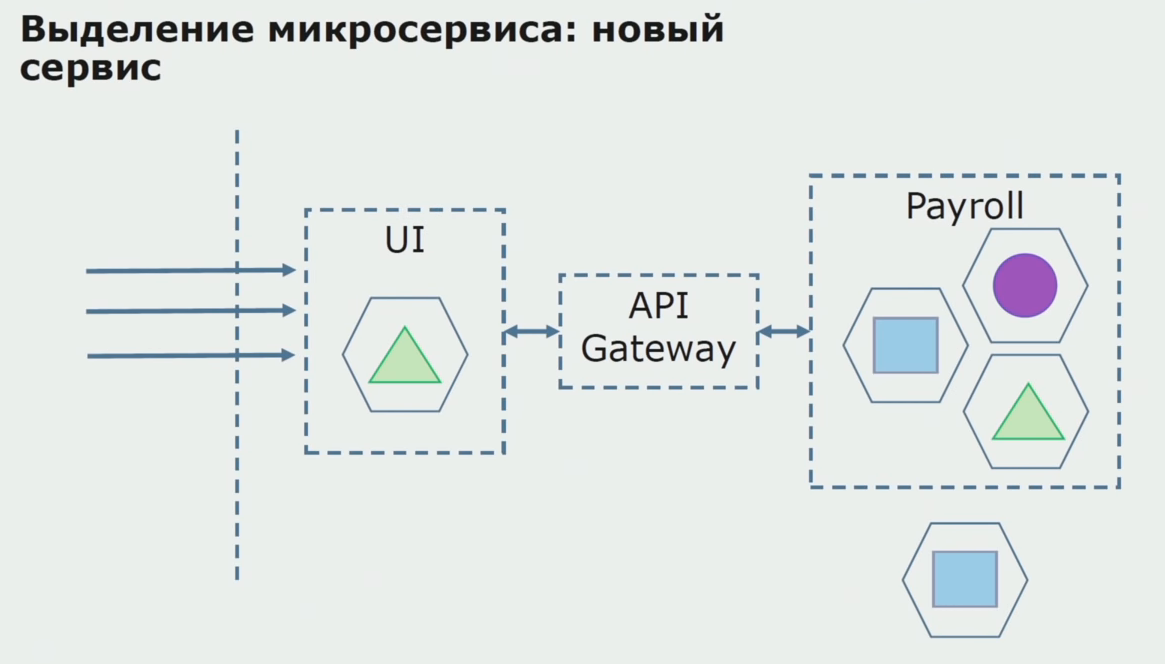
Em seguida, lançamos essa configuração em operação, mas no estado do piloto. A maioria dos nossos usuários ainda trabalha com processos de negócios antigos. Para novos usuários, estamos desenvolvendo uma nova versão de um aplicativo monolítico que esse processo não contém mais. De fato, temos um monte de monólitos e microsserviços trabalhando na forma de um piloto.
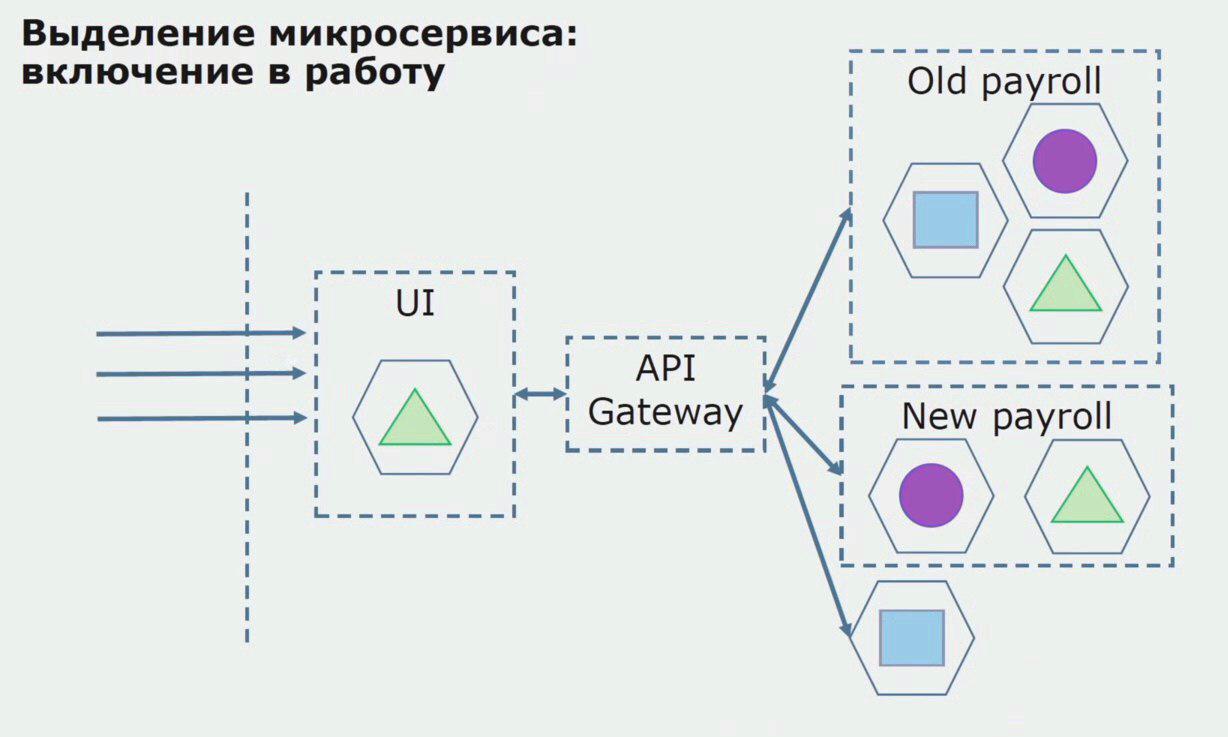
Com um piloto bem-sucedido, entendemos que a nova configuração é realmente operacional, podemos remover o monólito antigo da equação e deixar a nova configuração no lugar da solução antiga.
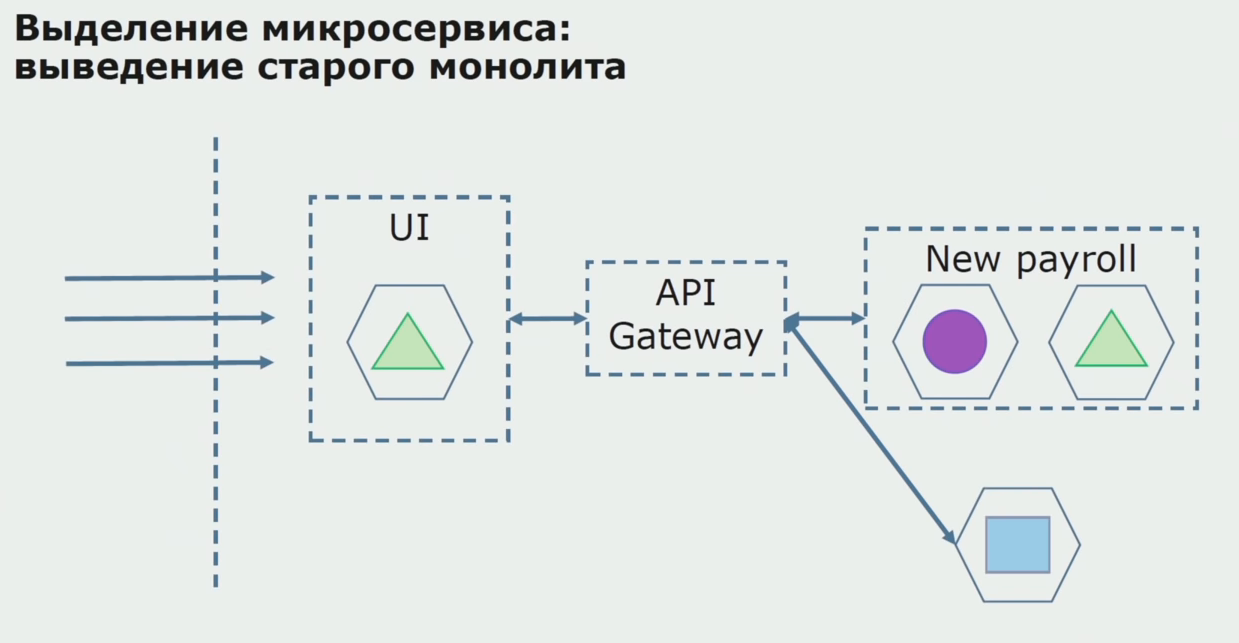
No total, usamos quase todos os métodos existentes para separar o código fonte de um monólito. Todos eles permitem reduzir o tamanho de partes do aplicativo e transferi-los para novas bibliotecas, criando um melhor código-fonte.
Trabalhar com um banco de dados
O banco de dados pode ser dividido pior que o código-fonte, pois contém não apenas o esquema atual, mas também os dados históricos acumulados.
Nosso banco de dados, como muitos outros, teve outra desvantagem importante - seu tamanho enorme. Esse banco de dados foi projetado de acordo com a lógica comercial complexa do monólito, e os links foram acumulados entre tabelas de vários contextos limitados.
No nosso caso, além de todos os problemas (um banco de dados grande, muitos relacionamentos, às vezes fronteiras incompreensíveis entre tabelas), surgiu um problema em muitos projetos grandes: usando o modelo de banco de dados compartilhado. Os dados foram obtidos das tabelas através da visualização, através da replicação e enviados para outros sistemas onde essa replicação é necessária. Como resultado, não foi possível remover as tabelas em um esquema separado, porque elas foram usadas ativamente.
A separação nos ajuda a dividir em contextos limitados no código. Geralmente, nos dá uma boa idéia de como dividimos os dados no nível do banco de dados. Entendemos quais tabelas se relacionam com um contexto limitado e quais se relacionam com outro.
Aplicamos duas maneiras globais de particionar o banco de dados: particionando tabelas existentes e particionando com processamento.
A separação de tabelas existentes é um método que é bom usar se a estrutura de dados for de alta qualidade, atender aos requisitos de negócios e atender a todos. Nesse caso, podemos selecionar as tabelas existentes em um esquema separado.
Um departamento de processamento é necessário quando o modelo de negócios mudou muito e as tabelas não nos satisfazem completamente.
Separe as tabelas existentes. Precisamos determinar o que separaremos. Sem esse conhecimento, nada resultará, e aqui a separação de contextos limitados no código nos ajudará. Como regra, se for possível entender os limites dos contextos no código-fonte, fica claro quais tabelas devem ser incluídas na lista para separação.
Imagine que temos uma solução na qual dois módulos monolíticos interagem com um banco de dados. Precisamos garantir que apenas um módulo interaja com a parte das tabelas separadas e o outro comece a interagir com ele através da API. Para iniciantes, basta que apenas uma entrada seja feita por meio da API. Essa é uma condição necessária para que possamos falar sobre a independência dos microsserviços. Os links de leitura podem permanecer até que haja um grande problema.

Como próxima etapa, já podemos selecionar uma seção de código que funcione com tabelas separáveis com ou sem processamento em um microsserviço separado e executá-la em um contêiner de processo separado. Este será um serviço separado com comunicação com o banco de dados monolítico e com as tabelas que não estão diretamente relacionadas a ele. O monólito ainda interage com a parte destacável para leitura.

Posteriormente removeremos essa conexão, ou seja, a leitura dos dados do aplicativo monolítico das tabelas separadas também será transferida para a API.
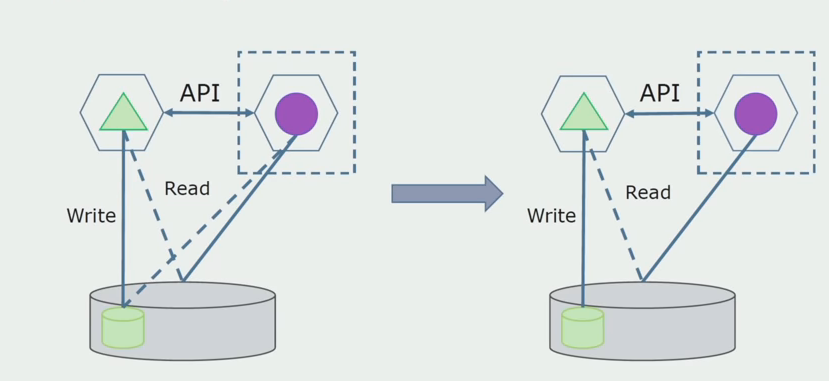
A seguir, selecionamos no banco de dados geral as tabelas com as quais apenas o novo microsserviço funciona. Podemos colocar tabelas em um esquema separado ou mesmo em um banco de dados físico separado. Havia uma conexão para leitura entre o microsserviço e o banco de dados monolítico, mas não há com o que se preocupar, pois nessa configuração ele pode permanecer por um longo tempo.
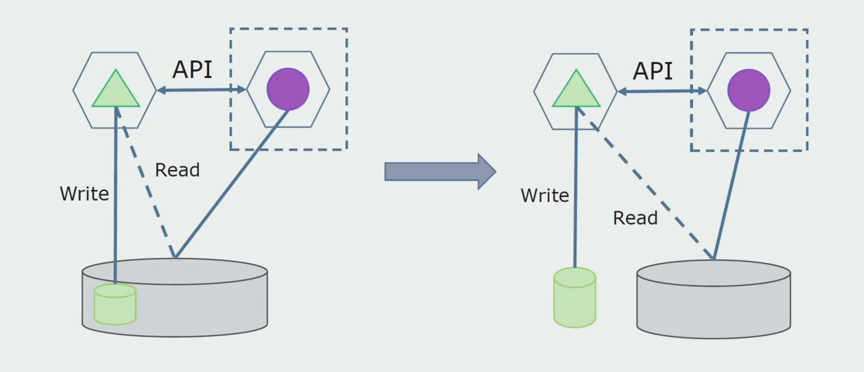
O último passo é remover completamente todas as conexões. Nesse caso, talvez seja necessário migrar dados do banco de dados principal. Às vezes, queremos reutilizar em vários bancos de dados alguns dados ou diretórios replicados de sistemas externos. Periodicamente, encontramos isso.
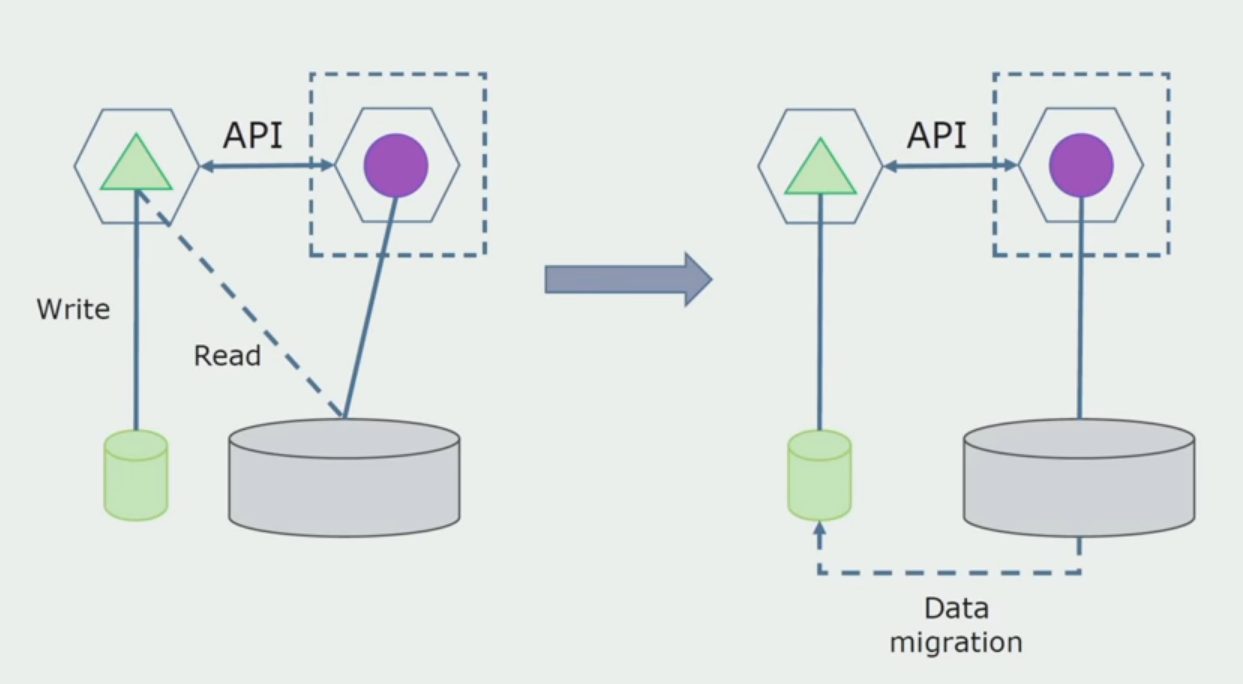 Departamento de processamento.
Departamento de processamento. Este método é muito semelhante ao primeiro, apenas na ordem inversa. Temos imediatamente um novo banco de dados e um novo microsserviço que interage com o monólito por meio da API. Mas, ao mesmo tempo, ainda existe um conjunto de tabelas de banco de dados que queremos excluir no futuro. Não precisaremos mais dele, no novo modelo o substituímos.
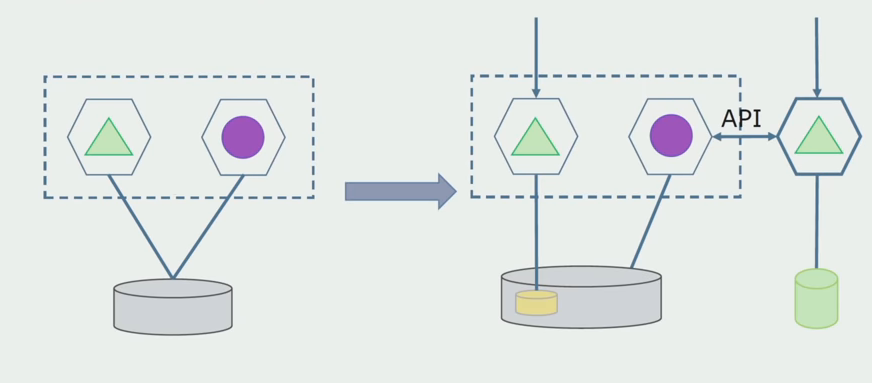
Para que esse esquema funcione, provavelmente precisaremos de um período de transição.
Existem duas abordagens possíveis.
Primeiro : duplicamos todos os dados nos bancos de dados novos e antigos. Nesse caso, temos redundância de dados, pode haver problemas com a sincronização. Mas então podemos atender dois clientes diferentes. Um irá trabalhar com a nova versão, o outro com a antiga.
Segundo : compartilhamos dados de acordo com alguma característica do negócio. Por exemplo, em nosso sistema, havia 5 produtos armazenados no banco de dados antigo. O sexto como parte de uma nova tarefa de negócios, colocamos em um novo banco de dados. Mas precisamos da API do Gateway, que sincroniza esses dados e mostra ao cliente onde e o que levar.
Ambas as abordagens estão funcionando, escolha de acordo com a situação.
Depois de garantir que tudo funcione, a parte do monólito que funciona com as estruturas antigas do banco de dados pode ser desativada.
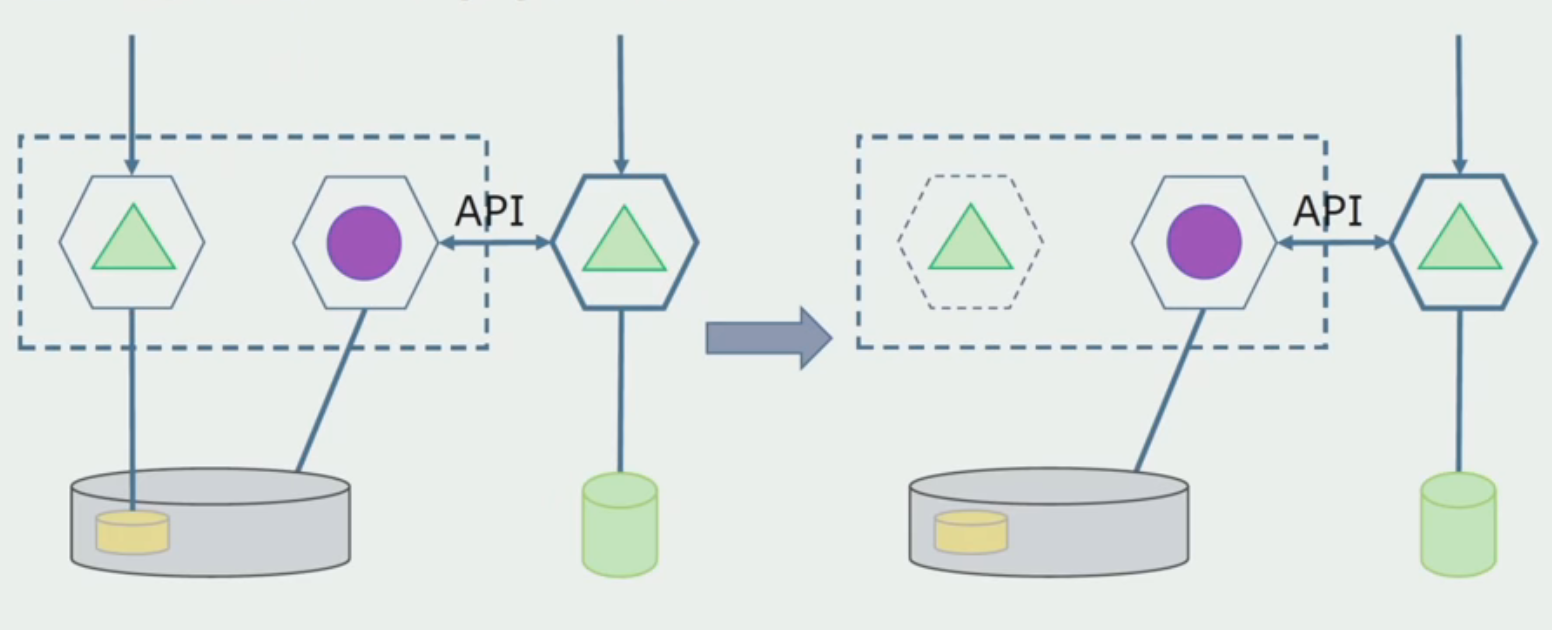
A etapa final é remover as estruturas de dados antigas.

Resumindo, podemos dizer que temos problemas com o banco de dados: é difícil trabalhar com ele comparado ao código fonte, é mais difícil separar, mas isso pode e deve ser feito. Encontramos algumas maneiras que permitem que isso seja feito com segurança, mas é mais fácil cometer um erro com os dados do que com o código-fonte.
Trabalhando com código fonte
É assim que o diagrama do código fonte era quando começamos a analisar um projeto monolítico.

Pode ser condicionalmente dividido em três camadas. Essa é uma camada de módulos, plugins, serviços e atividades individuais lançados. De fato, esses eram os pontos de entrada na solução monolítica. Todos eles estavam fortemente ligados a uma camada comum. Ele tinha lógica comercial compartilhada entre serviços e muitas conexões. Cada serviço e plug-in usava até 10 ou mais assemblies comuns, dependendo do tamanho e da consciência dos desenvolvedores.
Tivemos sorte, tínhamos bibliotecas de infraestrutura que podiam ser usadas separadamente.
Às vezes, surgiu uma situação em que alguns dos objetos Comuns na verdade não pertenciam a essa camada, mas eram bibliotecas de infraestrutura. Isso foi decidido renomeando.
Mais preocupado com contextos limitados. Costumava ser que 3-4 contextos se misturavam em uma montagem comum e se usavam nas mesmas funções de negócios. Era necessário entender onde isso pode ser dividido e em quais limites, e o que fazer em seguida com o mapeamento dessa separação em assemblies de código-fonte.
Nós formulamos várias regras para o processo de separação de código.
Primeiro : não queríamos mais compartilhar a lógica de negócios entre serviços, atividades e plugins. Eles queriam tornar a lógica de negócios independente dentro da estrutura de microsserviços. Por outro lado, os microsserviços, no caso ideal, são percebidos como serviços que existem de forma completamente independente. Acredito que essa abordagem seja um pouco inútil, e é difícil alcançá-la, porque, por exemplo, os serviços em C # serão, em qualquer caso, conectados por uma biblioteca padrão. Nosso sistema está escrito em C #, outras tecnologias ainda não foram usadas. Portanto, decidimos que podemos dar ao luxo de usar conjuntos técnicos comuns. O principal é que eles não possuem fragmentos da lógica de negócios. Se você tiver um invólucro conveniente sobre o ORM usado, copiá-lo de serviço para serviço é muito caro.
Nossa equipe é fã do design orientado ao assunto, portanto a "arquitetura da cebola" é perfeita para nós. A base de nossos serviços não era uma camada de acesso a dados, mas uma montagem com lógica de domínio, que contém apenas lógica de negócios e é desprovida de conexões de infraestrutura. Ao mesmo tempo, podemos modificar independentemente o conjunto do domínio para resolver os problemas associados às estruturas.
Nesta fase, encontramos o primeiro problema sério. O serviço deveria se referir a um assembly de domínio, queríamos tornar a lógica independente e, aqui, o princípio DRY interferiu fortemente conosco. Para evitar duplicação, os desenvolvedores queriam reutilizar classes de assemblies vizinhos e, como resultado, os domínios começaram a se comunicar novamente. Analisamos os resultados e decidimos que talvez o problema também esteja na área do dispositivo de armazenamento do código-fonte. Tínhamos um grande repositório no qual estavam todos os códigos-fonte. A solução para todo o projeto foi muito difícil de montar em uma máquina local. Portanto, pequenas soluções separadas foram criadas para as partes do projeto e ninguém proibiu a adição de nenhum assembly Comum ou de domínio a elas e a sua reutilização. A única ferramenta que não nos permitiu fazer isso foi o código de revisão. Mas às vezes ele também caiu.
Então começamos a mudar para um modelo com repositórios separados. A lógica comercial deixou de fluir de serviço em serviço; os domínios se tornaram verdadeiramente independentes. Contextos limitados são suportados com mais clareza. Como reutilizamos as bibliotecas de infraestrutura? Nós os alocamos em um repositório separado e os colocamos nos pacotes Nuget que colocamos no Artifactory. Com qualquer alteração, a montagem e a publicação ocorrem automaticamente.
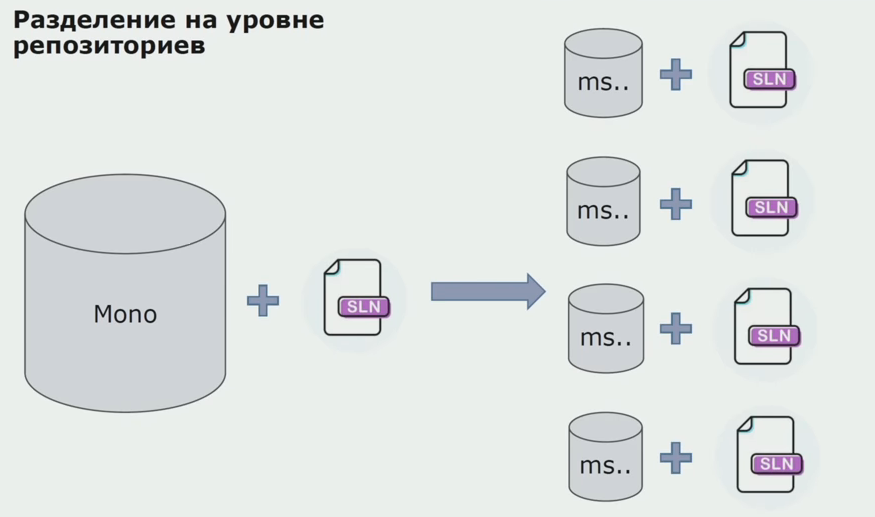
Nossos serviços começaram a se referir a pacotes de infraestrutura interna da mesma maneira que a externos. Fazemos o download de bibliotecas externas do Nuget. Para trabalhar com o Artifactory, onde colocamos esses pacotes, usamos dois gerenciadores de pacotes. Em pequenos repositórios, também usamos o Nuget. Nos repositórios com vários serviços, usamos o Paket, que fornece mais consistência de versão entre os módulos.
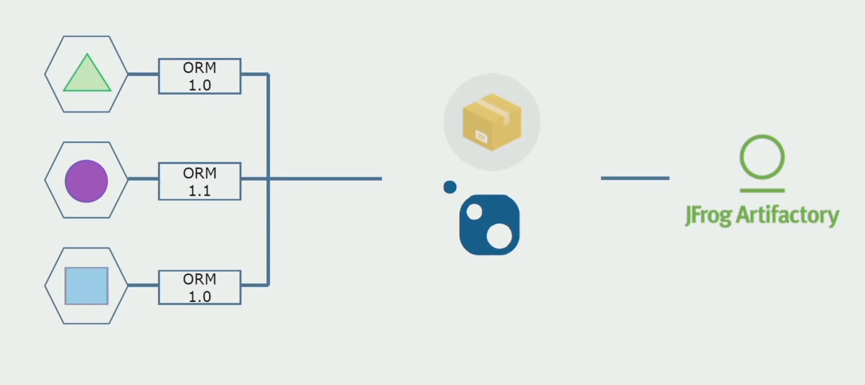
Assim, trabalhando no código fonte, alterando ligeiramente a arquitetura e compartilhando repositórios, tornamos nossos serviços mais independentes.
Problemas de infraestrutura
A maioria das desvantagens da mudança para microsserviços está relacionada à infraestrutura. Você precisará de implantação automatizada, novas bibliotecas para a infraestrutura.
Instalação manual em ambientesInicialmente, instalamos a solução no ambiente manualmente. Para automatizar esse processo, criamos um pipeline de CI / CD. Escolhemos o processo de entrega contínua, porque a implantação contínua para nós ainda não é aceitável do ponto de vista dos processos de negócios. Portanto, o envio para operação é realizado pelo botão e para teste - automaticamente.
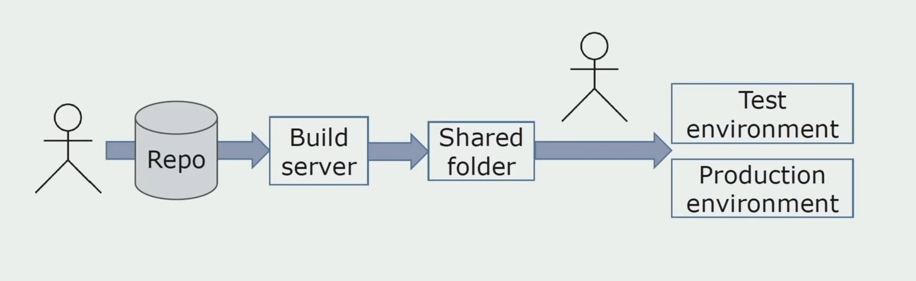
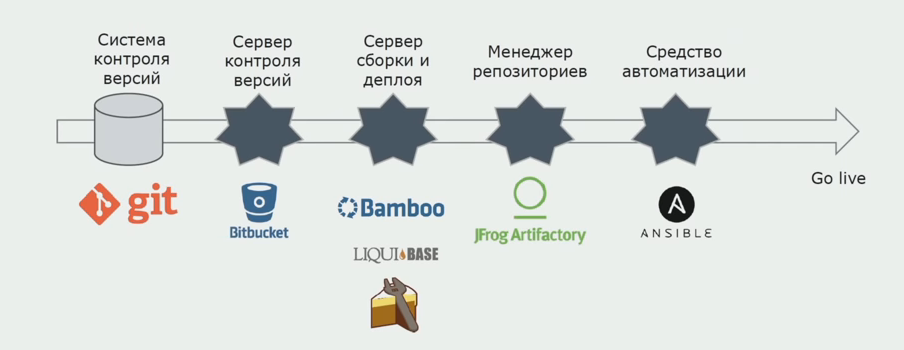
Usamos Atlassian, Bitbucket para armazenar o código-fonte e Bamboo para montagem. Gostamos de escrever scripts de montagem no Cake, porque é o mesmo C #. Pacotes prontos chegam ao Artifactory, e o Ansible chega automaticamente aos servidores de teste, após o que eles podem ser testados imediatamente.
Log separado
Ao mesmo tempo, uma das idéias do monólito era o fornecimento de exploração conjunta. Também precisamos entender o que fazer com os logs individuais que se encontram nos discos. Os registros são gravados para nós em arquivos de texto. Decidimos usar a pilha ELK padrão. Não gravamos diretamente no ELK por meio de provedores, mas decidimos finalizar os logs de texto e anotar o ID de rastreamento neles como um identificador, adicionando o nome do serviço para que esses logs pudessem ser analisados.

Usando o Filebeat, temos a oportunidade de coletar nossos logs dos servidores e convertê-los, usando o Kibana para criar solicitações na interface do usuário e observar como foi a chamada entre os serviços. O ID de rastreamento ajuda muito nisso.
Serviços relacionados a teste e depuração
Inicialmente, não entendemos completamente como depurar serviços desenvolvidos. Tudo era simples com o monólito, rodamos na máquina local. No início, eles tentaram fazer o mesmo com os microsserviços, mas às vezes para iniciar completamente um microsserviço, é necessário iniciar vários outros, o que é inconveniente. , , , . , prod. , , . , , .
, production- . , .
Specflow. NUnit Ansible. , . - . , , Jira.
, . JMeter, — InfluxDB, — Grafana.
?
-, «». , production-, -. 1,5 , , .
. , , . .
. , .
, . , . Scrum-. , .
- . , , , . .
- . , , . , , , Scrum.
- — . . . legacy, , .
: . . , , , , , , , — , . . , , .
PS ( ) – .
.