Cada sistema de monitoramento enfrenta três tipos de problemas de desempenho.
Em primeiro lugar, um bom sistema de monitoramento deve receber, processar e registrar dados muito rapidamente, vindos de fora. A conta vai para microssegundos. Imediatamente, isso pode parecer óbvio, mas quando o sistema se torna grande o suficiente, todas essas frações de segundos são resumidas, transformando-se em atrasos claramente perceptíveis.

A segunda tarefa é fornecer acesso conveniente a grandes matrizes de métricas coletadas anteriormente (em outras palavras, a dados históricos). Os dados históricos são usados em uma ampla variedade de contextos. Por exemplo, relatórios e gráficos são gerados a partir deles, verificações agregadas são construídas sobre eles, gatilhos dependem deles. Se houver algum atraso no acesso ao histórico, isso afetará imediatamente a velocidade de todo o sistema.
Em terceiro lugar, os dados históricos ocupam muito espaço. Mesmo configurações de monitoramento relativamente modestas adquirem muito rapidamente um histórico sólido. Mas dificilmente alguém quer manter o histórico de carga do processador com cinco anos de idade, portanto o sistema de monitoramento deve ser capaz não apenas de gravar bem, mas também de excluir o histórico (no Zabbix, esse processo é chamado de "limpeza"). A exclusão de dados antigos não precisa ser tão eficiente quanto a coleta e análise de novos, mas operações pesadas de exclusão utilizam recursos preciosos de DBMS e podem retardar operações mais críticas.
Os dois primeiros problemas são resolvidos pelo cache. O Zabbix suporta vários caches especializados para acelerar as operações de leitura e gravação de dados. Os mecanismos DBMS em si não são adequados aqui, porque mesmo o algoritmo de cache de propósito geral mais avançado não saberá quais estruturas de dados requerem acesso instantâneo em um determinado momento.
Dados de Monitoramento e Séries Temporais
Tudo está bem desde que os dados estejam na memória do servidor Zabbix. Mas a memória não é infinita e, em algum momento, os dados precisam ser gravados (ou lidos) no banco de dados. E se o desempenho do banco de dados estiver seriamente atrás da velocidade da coleta de métricas, mesmo os algoritmos de cache especiais mais avançados não ajudarão por muito tempo.
O terceiro problema também se resume ao desempenho do banco de dados. Para resolvê-lo, você precisa escolher uma estratégia de exclusão confiável que não interfira com outras operações do banco de dados. Por padrão, o Zabbix exclui dados históricos em lotes de vários milhares de registros por hora. Você pode configurar períodos mais longos de limpeza ou tamanhos de pacotes maiores, se a velocidade da coleta de dados e o local no banco de dados permitir. Porém, com um número muito grande de métricas e / ou uma alta frequência de coleta, a configuração adequada da limpeza pode ser uma tarefa assustadora, pois uma programação de exclusão de dados pode não acompanhar o ritmo de gravação de novas.
Resumindo, o sistema de monitoramento resolve problemas de desempenho em três direções - coletando novos dados e gravando-os no banco de dados usando consultas SQL INSERT, acessando dados usando consultas SELECT e excluindo dados usando DELETE. Vamos ver como uma consulta SQL típica é executada:
- O DBMS analisa a consulta e verifica se há erros de sintaxe. Se a solicitação estiver sintaticamente correta, o mecanismo criará uma árvore de sintaxe para processamento adicional.
- O planejador de consultas analisa a árvore de sintaxe e calcula as várias maneiras (caminhos) para executar a solicitação.
- O planejador calcula a maneira mais barata. No processo, leva em consideração muitas coisas - qual o tamanho das tabelas, é necessário classificar os resultados, existem índices aplicáveis à consulta etc.
- Quando o caminho ideal é encontrado, o mecanismo executa a consulta acessando os blocos de dados desejados (usando índices ou varredura seqüencial), aplica os critérios de classificação e filtragem, coleta o resultado e o retorna ao cliente.
- Para inserir, modificar e excluir consultas, o mecanismo também deve atualizar os índices para as tabelas correspondentes. Para tabelas grandes, essa operação pode demorar mais do que trabalhar com os próprios dados.
- Provavelmente, o DBMS também atualizará as estatísticas internas do uso de dados para chamadas subseqüentes ao agendador de consultas.
Em geral, há muito trabalho. A maioria dos DBMSs fornece várias configurações para otimização de consultas, mas geralmente são focadas em alguns fluxos de trabalho médios nos quais a inserção e exclusão de registros ocorre aproximadamente na mesma frequência da alteração.
No entanto, como mencionado acima, para sistemas de monitoramento, as operações mais comuns são adição e exclusão periódica no modo em lote. A alteração de dados adicionados anteriormente quase nunca ocorre e o acesso aos dados envolve o uso de funções agregadas. Além disso, geralmente os valores das métricas adicionadas são ordenados por tempo. Esses dados são comumente referidos como
séries temporais :
Série temporal é uma série de pontos de dados indexados (ou listados ou grafite) em uma ordem temporária.
Do ponto de vista do banco de dados, as séries temporais têm as seguintes propriedades:
- As séries temporais podem ser localizadas em um disco como uma sequência de blocos ordenados por tempo.
- As tabelas de séries temporais podem ser indexadas usando uma coluna de tempo.
- A maioria das consultas SQL SELECT usará as cláusulas WHERE, GROUP BY ou ORDER BY em uma coluna de indicação de tempo.
- Normalmente, os dados de séries temporais têm uma "data de validade" após a qual podem ser excluídos.
Obviamente, os bancos de dados SQL tradicionais não são adequados para armazenar esses dados, pois as otimizações de uso geral não levam essas qualidades em consideração. Portanto, nos últimos anos, surgiram alguns DBMSs novos e orientados ao tempo, como, por exemplo, o InfluxDB. Mas todos os DBMSs populares para séries temporais têm uma desvantagem significativa - a falta de suporte completo ao SQL. Além disso, a maioria deles nem sequer é CRUD (Criar, Ler, Atualizar, Excluir).
O Zabbix pode usar esses DBMSs de alguma forma? Uma das abordagens possíveis é transferir dados históricos para armazenamento em um banco de dados externo especializado na série temporal. Como a arquitetura do Zabbix suporta back-ends externos para armazenamento de dados históricos (por exemplo, o suporte ao Elasticsearch é implementado no Zabbix), à primeira vista, essa opção parece bastante razoável. Mas se oferecermos suporte a um ou vários DBMS para séries temporais como servidores externos, os usuários terão que considerar os seguintes pontos:
- Outro sistema que precisa ser explorado, configurado e mantido. Outro local para acompanhar configurações, espaço em disco, políticas de armazenamento, desempenho etc.
- Reduzir a tolerância a falhas do sistema de monitoramento, como um novo link aparece na cadeia de componentes relacionados.
Para alguns usuários, os benefícios do armazenamento dedicado dedicado para dados históricos podem compensar o inconveniente de ter que se preocupar com outro sistema. Mas para muitos, isso é uma complicação desnecessária. Também vale lembrar que, como a maioria dessas soluções especializadas possui suas próprias APIs, a complexidade da camada universal para trabalhar com os bancos de dados Zabbix aumentará acentuadamente. E, idealmente, preferimos criar novas funções, em vez de lutar contra outras APIs.
Surge a pergunta - existe uma maneira de tirar proveito do DBMS para séries temporais, mas sem perder a flexibilidade e as vantagens do SQL? Naturalmente, não existe uma resposta universal, mas uma solução específica ficou muito próxima da resposta -
TimescaleDB .
O que é o TimescaleDB?
O TimescaleDB (TSDB) é uma extensão do PostgreSQL que otimiza o trabalho com séries temporais em um banco de dados normal do PostgreSQL (PG). Embora, como mencionado acima, não haja escassez de soluções de séries temporais bem escalonáveis no mercado, um recurso exclusivo do TimescaleDB é sua capacidade de trabalhar bem com séries temporais sem sacrificar a compatibilidade e os benefícios dos bancos de dados relacionais CRUD tradicionais. Na prática, isso significa que obtemos o melhor dos dois mundos. O banco de dados sabe quais tabelas devem ser consideradas como séries temporais (e aplica todas as otimizações necessárias), mas você pode trabalhar com elas da mesma maneira que nas tabelas regulares. Além disso, os aplicativos não precisam saber que os dados são controlados pelo TSDB!
Para marcar uma tabela como uma tabela de séries temporais (no TSDB isso é chamado de hipertabela), basta chamar o procedimento TSDB create_ hypertable (). Sob o capô, o TSDB divide esta tabela nos chamados fragmentos (o termo em inglês é chunk) de acordo com as condições especificadas. Fragmentos podem ser representados como seções controladas automaticamente de uma tabela. Cada fragmento tem um intervalo de tempo correspondente. Para cada fragmento, o TSDB também define índices especiais para que trabalhar com um intervalo de dados não afete o acesso a outros.
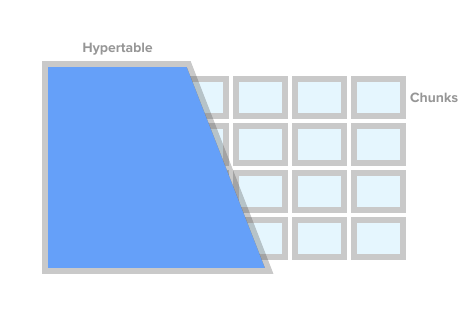 Imagem de hipertabela de timescaledb.com
Imagem de hipertabela de timescaledb.comQuando o aplicativo adiciona um novo valor para a série temporal, a extensão direciona esse valor para o fragmento desejado. Se o intervalo para o tempo do novo valor não for definido, o TSDB criará um novo fragmento, atribua o intervalo desejado e insira o valor nele. Se um aplicativo solicitar dados de uma hipertabela, antes de executá-lo, a extensão verificará quais fragmentos estão associados a esse pedido.
Mas isso não é tudo. O TSDB complementa o robusto e testado ecossistema PostgreSQL com uma série de alterações de desempenho e escalabilidade. Isso inclui a rápida adição de novos registros, consultas rápidas e exclusões em lote praticamente gratuitas.
Conforme observado anteriormente, para controlar o tamanho do banco de dados e cumprir as políticas de retenção (ou seja, não armazenar dados por mais tempo que o necessário), uma boa solução de monitoramento deve excluir efetivamente uma grande quantidade de dados históricos. Com o TSDB, podemos excluir a história desejada simplesmente excluindo certos fragmentos da hipertabela. Nesse caso, o aplicativo não precisa rastrear fragmentos por nome ou outros links, o TSDB excluirá todos os fragmentos necessários de acordo com a condição de tempo especificada.
TimescaleDB e PostgreSQL Particionamento
À primeira vista, pode parecer que o TSDB é um bom invólucro em torno do particionamento padrão de tabelas PG (
particionamento declarativo , como é chamado oficialmente no PG10). De fato, para armazenar dados históricos, você pode usar o particionamento padrão PG10. Mas se você observar com atenção, os fragmentos da seção TSDB e PG10 estão longe de serem conceitos idênticos.
Para começar, configurar o particionamento no PG requer uma compreensão mais profunda dos detalhes, o que o próprio aplicativo ou o DBMS deve fazer de uma maneira boa. Primeiro, você precisa planejar sua hierarquia de seções e decidir se deseja usar partições aninhadas. Em segundo lugar, você precisa criar um esquema de nomeação de seção e, de alguma forma, transferi-lo para os scripts para criar o esquema. Muito provavelmente, o esquema de nomeação incluirá a data e / ou hora, e esses nomes precisarão ser automatizados de alguma forma.
Em seguida, você precisa pensar em como excluir dados expirados. No TSDB, você pode simplesmente chamar o comando drop_chunks (), que determina os fragmentos a serem excluídos por um determinado período de tempo. No PG10, se você precisar remover um determinado intervalo de valores das seções PG padrão, será necessário calcular a lista de nomes de seções para esse intervalo. Se o esquema de particionamento selecionado envolver seções aninhadas, isso complicará ainda mais a exclusão.
Outro problema que precisa ser resolvido é o que fazer com dados que vão além dos intervalos de tempo atuais. Por exemplo, os dados podem vir de um futuro para o qual as seções ainda não foram criadas. Ou do passado para seções já excluídas. Por padrão, na PG10, adicionar esse registro não funcionará e simplesmente perderemos os dados. No PG11, você pode definir uma seção padrão para esses dados, mas isso apenas oculta temporariamente o problema e não o resolve.
Obviamente, todos os problemas acima podem ser resolvidos de uma maneira ou de outra. Você pode pendurar a base com gatilhos, cron-jabs e polvilhar livremente com scripts. Será feio, mas funcional. Não há dúvida de que as seções do PG são melhores que as tabelas monolíticas gigantes, mas o que definitivamente não é resolvido por meio de scripts e gatilhos são as melhorias de séries temporais que o PG não possui.
I.e. Comparadas às seções PG, as tabelas de TSDB são distinguidas favoravelmente, não apenas salvando os nervos dos administradores de banco de dados, mas também otimizando o acesso aos dados e adicionando novos. Por exemplo, fragmentos no TSDB são sempre uma matriz unidimensional. Isso simplifica o gerenciamento de fragmentos e acelera inserções e seleções. Para adicionar novos dados, o TSDB usa seu próprio algoritmo de roteamento no fragmento desejado, que, diferente do PG padrão, não abre imediatamente todas as seções. Com um grande número de seções, a diferença no desempenho pode variar significativamente. Detalhes técnicos sobre a diferença entre o particionamento padrão no PG e no TSDB podem ser encontrados
neste artigo .
Zabbix e TimescaleDB
De todas as opções, o TimescaleDB parece ser a opção mais segura para o Zabbix e seus usuários:
- O TSDB foi projetado como uma extensão do PostgreSQL, e não como um sistema independente. Portanto, não requer hardware adicional, máquinas virtuais ou quaisquer outras alterações na infraestrutura. Os usuários podem continuar usando as ferramentas escolhidas para o PostgreSQL.
- O TSDB permite salvar quase todo o código para trabalhar com o banco de dados no Zabbix inalterado.
- O TSDB melhora significativamente o desempenho do sincronizador de histórico e governanta.
- Baixo limite de entrada - Os conceitos básicos do TSDB são simples e diretos.
- A fácil instalação e configuração da extensão em si e do Zabbix ajudará bastante os usuários de sistemas pequenos e médios.
Vamos ver o que precisa ser feito para iniciar o TSDB com um Zabbix recém-instalado. Após instalar o Zabbix e executar os scripts de criação do banco de dados PostgreSQL, você precisará baixar e instalar o TSDB na plataforma desejada. Consulte as instruções de instalação
aqui . Após instalar a extensão, é necessário ativá-la para a base do Zabbix e, em seguida, execute o script timecaledb.sql que acompanha o Zabbix. Ele está localizado no banco de dados / postgresql / timecaledb.sql se a instalação for da origem ou em /usr/share/zabbix/database/timecaledb.sql.gz se a instalação for de pacotes. Isso é tudo! Agora você pode iniciar o servidor Zabbix e ele funcionará com o TSDB.
O script timescaledb.sql é trivial. Tudo o que ele faz é converter as tabelas históricas regulares do Zabbix em hypertables TSDB e alterar as configurações padrão - define os parâmetros Substituir período do histórico do item e Substituir período da tendência do item. Agora (versão 4.2), as seguintes tabelas do Zabbix funcionam sob o controle TSDB - history, history_uint, history_str, history_log, history_text, trends and trends_uint. O mesmo script pode ser usado para migrar essas tabelas (observe que o parâmetro migrate_data está definido como true). É preciso ter em mente que a migração de dados é um processo muito longo e pode levar várias horas.
O parâmetro chunk_time_interval => 86400 também pode exigir alterações antes da execução do timecaledb.sql .. Chunk_time_interval é o intervalo que limita o tempo dos valores que caem nesse fragmento. Por exemplo, se você definir o intervalo chunk_time_interval como 3 horas, os dados do dia inteiro serão distribuídos em 8 fragmentos, com o primeiro fragmento nº 1 cobrindo as primeiras 3 horas (0: 00-2: 59), o segundo fragmento nº 2 - as segundas 3 horas ( 3: 00-5: 59), etc. O último fragmento nº 8 conterá valores com um tempo de 21: 00 a 23: 59. 86400 segundos (1 dia) é o valor padrão médio, mas os usuários dos sistemas carregados podem querer reduzi-lo.
Para estimar aproximadamente os requisitos de memória, é importante entender quanto espaço uma peça pode ocupar em média. O princípio geral é que o sistema deve ter memória suficiente para organizar pelo menos um fragmento de cada hipertabela. Nesse caso, é claro, a soma dos tamanhos dos fragmentos não deve caber apenas na memória com uma margem, mas também deve ser menor que o valor do parâmetro shared_buffers do postgresql.conf. Informações adicionais sobre este tópico podem ser encontradas na documentação do TimescaleDB.
Por exemplo, se você possui um sistema que coleta principalmente métricas inteiras e decide dividir a tabela history_uint em fragmentos de 2 horas e dividir o restante das tabelas em fragmentos de um dia, é necessário alterar essa linha no timecaledb.sql:
SELECT create_hypertable('history_uint', 'clock', chunk_time_interval => 7200, migrate_data => true);
Após uma certa quantidade de dados históricos ter sido acumulada, você pode verificar os tamanhos dos fragmentos para a tabela history_uint chamando chunk_relation_size ():
zabbix=> SELECT chunk_table,total_bytes FROM chunk_relation_size('history_uint'); chunk_table | total_bytes -----------------------------------------+------------- _timescaledb_internal._hyper_2_6_chunk | 13287424 _timescaledb_internal._hyper_2_7_chunk | 13172736 _timescaledb_internal._hyper_2_8_chunk | 13344768 _timescaledb_internal._hyper_2_9_chunk | 13434880 _timescaledb_internal._hyper_2_10_chunk | 13230080 _timescaledb_internal._hyper_2_11_chunk | 13189120
Essa chamada pode ser repetida para encontrar os tamanhos de fragmento para todas as tabelas de hipertensão. Se, por exemplo, constatou-se que o tamanho do fragmento de history_uint é 13 MB, os fragmentos para outras tabelas de histórico, digamos 20 MB, e para as tabelas de tendências 10 MB, o requisito de memória total é 13 + 4 x 20 + 2 x 10 = 113MB. Também devemos deixar espaço no shared_buffers para armazenar outros dados, digamos 20%. Em seguida, o valor de shared_buffers deve ser definido como 113MB / 0.8 = ~ 140MB.
Para um ajuste mais preciso do TSDB, o utilitário timescaledb-tune apareceu recentemente. Ele analisa o postgresql.conf, o correlaciona com a configuração do sistema (memória e processador) e, em seguida, fornece recomendações sobre a configuração de parâmetros de memória, parâmetros para processamento paralelo, WAL. O utilitário altera o arquivo postgresql.conf, mas você pode executá-lo com o parâmetro -dry-run e verificar as alterações propostas.
Vamos nos concentrar nos parâmetros Zabbix: Substituir período do histórico do item e Substituir período da tendência do item (disponível em Administração -> Geral -> Serviço de limpeza). Eles são necessários para excluir dados históricos como fragmentos inteiros de hipertensas TSDB, não registros.
O fato é que o Zabbix permite definir o período de manutenção para cada elemento de dados (métrica) individualmente. No entanto, essa flexibilidade é obtida varrendo a lista de elementos e calculando períodos individuais em cada iteração da limpeza. Se o sistema tiver períodos de manutenção individuais para elementos individuais, obviamente, o sistema não poderá ter um único ponto de corte para todas as métricas juntas e o Zabbix não poderá dar o comando correto para excluir os fragmentos necessários. Assim, ao desativar o Substituir histórico para métricas, o Zabbix perderá a capacidade de excluir rapidamente o histórico chamando o procedimento drop_chunks () para tabelas history_ * e, consequentemente, desabilitar Substituir tendências perderá a mesma função para as tabelas trends_ *.
Em outras palavras, para aproveitar ao máximo o novo sistema de limpeza, você precisa tornar as duas opções globais. Nesse caso, o processo de limpeza não lerá as configurações dos itens de dados.
Desempenho com TimescaleDB
É hora de verificar se tudo isso realmente funciona na prática. Nosso ambiente de teste é o Zabbix 4.2rc1 com PostgreSQL 10.7 e TimescaleDB 1.2.1 para Debian 9. A máquina de teste é um Intel Xeon de 10 núcleos com 16 GB de RAM e 60 GB de espaço de armazenamento no SSD. Pelos padrões de hoje, essa é uma configuração muito modesta, mas nosso objetivo é descobrir a eficácia do TSDB na vida real. Nas configurações com um orçamento ilimitado, você pode simplesmente inserir 128-256 GB de RAM e colocar a maioria (se não toda) do banco de dados na memória.
Nossa configuração de teste consiste em 32 agentes Zabbix ativos que transferem dados diretamente para o Servidor Zabbix. Cada agente atende a 10.000 itens. O cache histórico do Zabbix está definido para 256 MB e o PG shared_buffers está definido para 2 GB. Essa configuração fornece carga suficiente no banco de dados, mas ao mesmo tempo não cria uma carga grande nos processos do servidor Zabbix. Para reduzir o número de partes móveis entre as fontes de dados e o banco de dados, não usamos o Zabbix Proxy.
Aqui está o primeiro resultado obtido no sistema PG padrão:
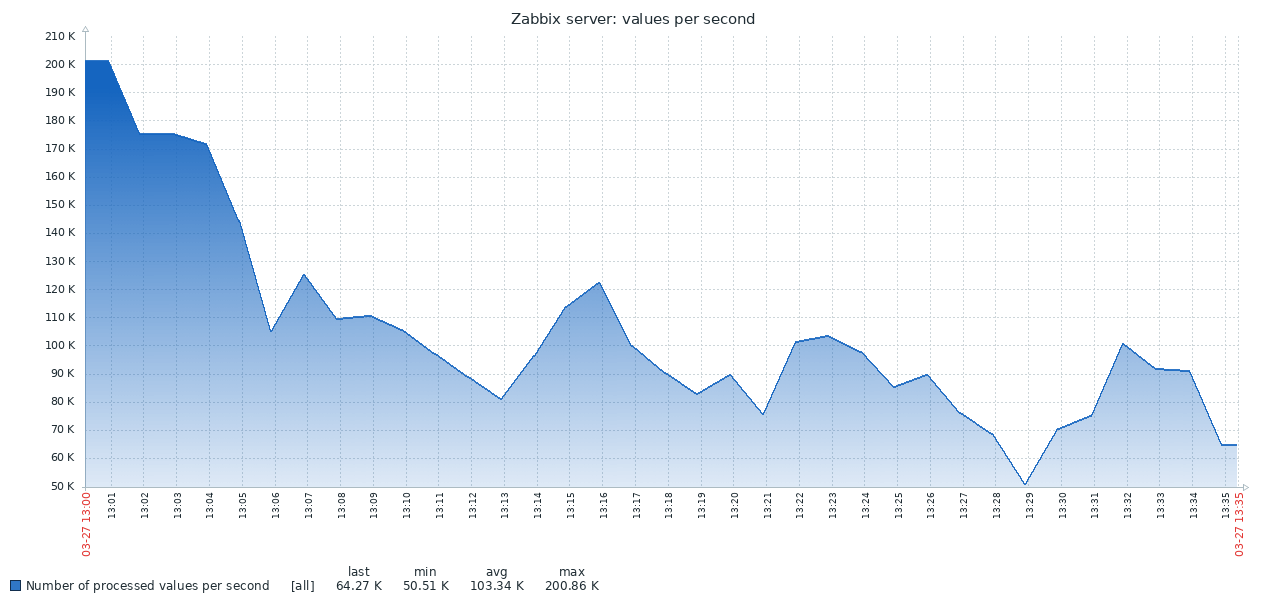
O resultado do TSDB é completamente diferente:

O gráfico abaixo combina os dois resultados. O trabalho começa com valores NVPS razoavelmente altos em 170-200K, porque Leva algum tempo para preencher o cache do histórico antes do início da sincronização com o banco de dados.
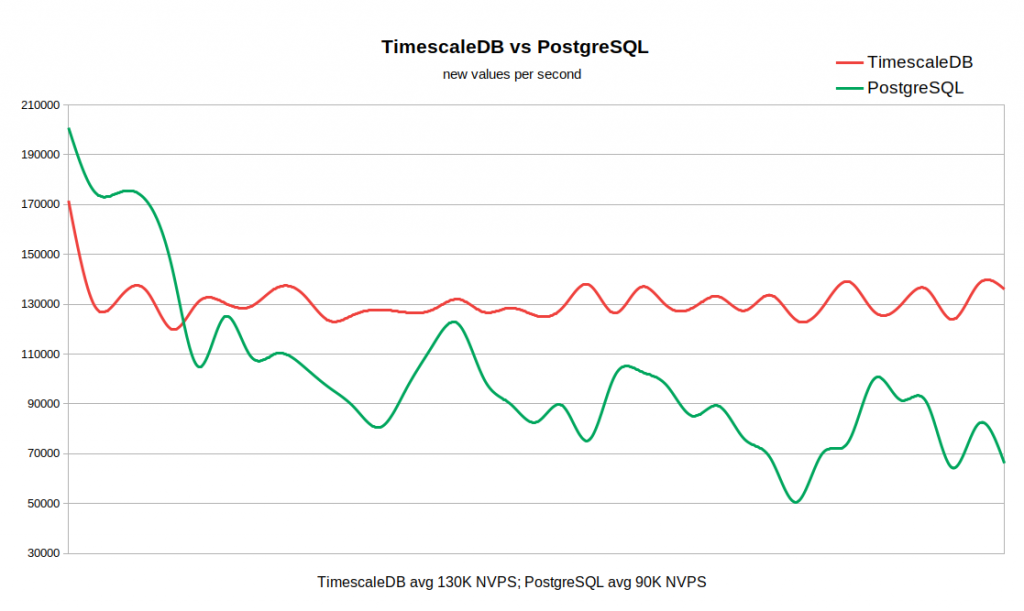
Quando a tabela de histórico está vazia, a velocidade de gravação no TSDB é comparável à velocidade de gravação no PG e mesmo com uma pequena margem deste último. Assim que o número de registros na história atinge 50-60 milhões, a taxa de transferência do PG cai para 110K NVPS, mas, o que é mais desagradável, continua a mudar inversamente com o número de registros acumulados na tabela histórica. Ao mesmo tempo, o TSDB mantém uma velocidade estável de 130K NVPS durante o teste, de 0 a 300 milhões de registros.
No total, em nosso exemplo, a diferença no desempenho médio é bastante significativa (130 mil versus 90 mil sem levar em consideração o pico inicial). Também é visto que a taxa de inserção no PG padrão varia em uma ampla faixa. Portanto, se um fluxo de trabalho exigir o armazenamento de dezenas ou centenas de milhões de registros no histórico, mas não houver recursos para estratégias de cache muito agressivas, o TSDB será um forte candidato para substituir o PG padrão.
A vantagem do TSDB já é óbvia para este sistema relativamente modesto, mas provavelmente a diferença se tornará ainda mais visível em grandes matrizes de dados históricos. Por outro lado, esse teste não é de forma alguma uma generalização de todos os cenários possíveis de trabalho com o Zabbix. Naturalmente, existem muitos fatores que influenciam os resultados, como configurações de hardware, configurações do sistema operacional, configurações do servidor Zabbix e carga adicional de outros serviços em execução em segundo plano. Ou seja, sua milhagem pode variar.
Conclusão
O TimescaleDB é uma tecnologia muito promissora. Já foi operado com sucesso em ambientes de produção sérios. O TSDB funciona bem com o Zabbix e oferece vantagens significativas sobre o banco de dados PostgreSQL padrão.
O TSDB tem alguma falha ou motivo para adiar o uso? Do ponto de vista técnico, não vemos nenhum argumento contra. Mas deve-se ter em mente que a tecnologia ainda é nova, com um ciclo de lançamento instável e uma estratégia pouco clara para o desenvolvimento da funcionalidade. Em particular, novas versões com alterações significativas são lançadas a cada mês ou dois. Algumas funções podem ser removidas, como, por exemplo, ocorreu com o chunking adaptável. Separadamente, como outro fator de incerteza, vale mencionar a política de licenciamento. É muito confuso, pois existem três níveis de licenciamento. O kernel do TSDB é fabricado sob a licença Apache, algumas funções são liberadas sob sua própria licença de escala de tempo, mas também há uma versão fechada do Enterprise.
Se você usa o Zabbix com o PostgreSQL, não há motivo pelo menos para não experimentar o TimescaleDB. Talvez isso o surpreenda agradavelmente :) Lembre-se de que o suporte ao TimescaleDB no Zabbix ainda é experimental - por enquanto, coletamos análises de usuários e obtemos experiência.