Usando o nginx para equilibrar o tráfego HTTP no nível L7, é possível enviar uma solicitação do cliente para o próximo servidor de aplicativos se o destino não retornar uma resposta positiva. Um teste do mecanismo de verificação passiva do status de integridade do servidor de aplicativos mostrou a ambiguidade da documentação e a especificidade dos algoritmos para excluir o servidor do conjunto de servidores de produção.
Resumo do equilíbrio do tráfego HTTP
Existem várias maneiras de equilibrar o tráfego HTTP. Pelos níveis do modelo OSI,
existem tecnologias de balanceamento nos níveis de rede, transporte e aplicativos.
As combinações podem ser usadas dependendo do tamanho do aplicativo.
A tecnologia de balanceamento de tráfego produz efeitos positivos na aplicação e em sua manutenção. Aqui estão alguns deles. Escalonamento horizontal do aplicativo, no qual a
carga é distribuída entre vários nós . Desativação planejada do servidor de aplicativos removendo o fluxo de solicitações do cliente. Implementação da estratégia de teste A / B para a funcionalidade alterada do aplicativo. Melhorando a tolerância a falhas de aplicativos
enviando solicitações para servidores de aplicativos que funcionem corretamente .
A última função é implementada em dois modos. No modo passivo, o balanceador no tráfego do cliente avalia as respostas do servidor de aplicativos de destino e o exclui do conjunto de servidores de produção sob certas condições. No modo ativo, o balanceador envia periodicamente independentemente solicitações para o servidor de aplicativos no URI especificado e, para certos sinais de resposta, decide excluí-lo do conjunto de servidores de produção. Posteriormente, o balanceador, sob certas condições, retorna o servidor de aplicativos para o conjunto de servidores de produção.
Verificação passiva do servidor de aplicativos e sua exclusão do conjunto de servidores de produção
Vamos dar uma olhada na verificação passiva do servidor de aplicativos na edição de freeware do nginx / 1.17.0. Os servidores de aplicativos são selecionados por sua vez pelo algoritmo Round Robin, seus pesos são os mesmos.
O diagrama de três etapas mostra uma seção de tempo começando com o envio de uma solicitação do cliente ao servidor de aplicativos n ° 2. Um indicador luminoso caracteriza as solicitações / respostas entre o cliente e o balanceador. Indicador escuro - solicitações / respostas entre o nginx e os servidores de aplicativos.
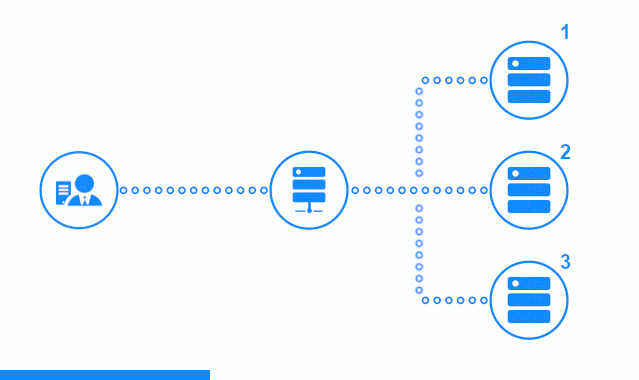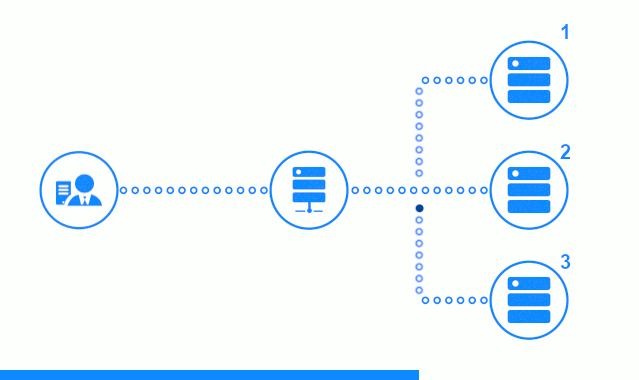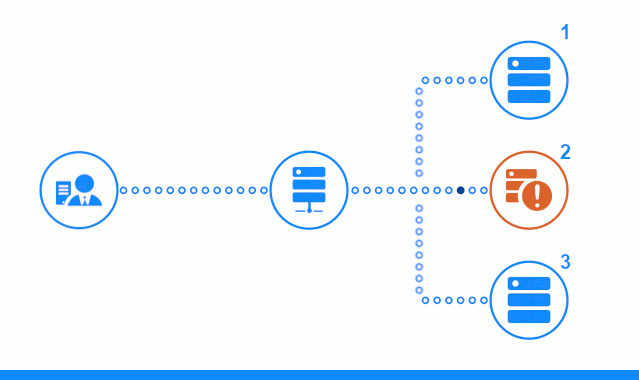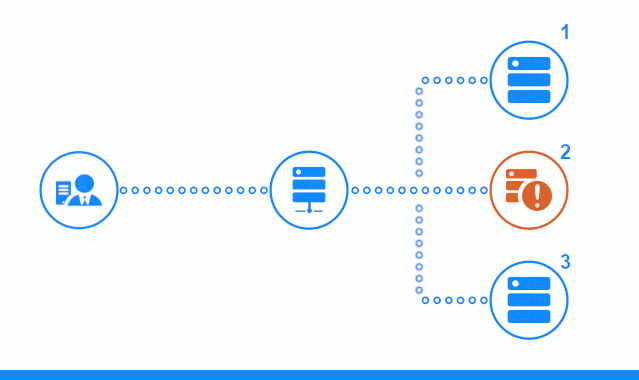
A terceira etapa do diagrama mostra como o balanceador redireciona a solicitação do cliente para o próximo servidor de aplicativos, caso o servidor de destino tenha dado uma resposta de erro ou não tenha respondido.
A lista de erros HTTP e TCP em que o servidor usa o servidor a seguir é especificada na diretiva
proxy_next_upstream .
Por padrão, o nginx redireciona apenas
solicitações com métodos HTTP idempotentes para o próximo servidor de aplicativos.
O que o cliente recebe? Por um lado, a capacidade de redirecionar uma solicitação para o próximo servidor de aplicativos aumenta as chances de fornecer uma resposta satisfatória ao cliente quando o servidor de destino falha. Por outro lado, é óbvio que uma chamada seqüencial primeiro para o servidor de destino e depois para o próximo aumenta o tempo total de resposta ao cliente.
No final,
a resposta do servidor de aplicativos é retornada ao cliente
, onde as tentativas permitidas de proxy_next_upstream_tries tentam terminar .
Ao usar a função de redirecionamento para o próximo servidor ativo, é necessário harmonizar adicionalmente os tempos limite no balanceador e nos servidores de aplicativos. O limite superior do tempo para uma solicitação de “viagem” entre servidores de aplicativos e o balanceador é o tempo limite do cliente ou o tempo de espera especificado pela empresa. Ao calcular tempos limite, também é necessário levar em consideração a margem para eventos de rede (atrasos / perdas durante a entrega de pacotes). Se cada vez que o cliente terminar a sessão por tempo limite, enquanto o balanceador obtiver uma resposta garantida, a boa intenção de tornar o aplicativo confiável será inútil.

A verificação passiva da integridade dos servidores de aplicativos é controlada por diretivas, por exemplo, com as seguintes opções para seus valores:
upstream backend { server app01:80 weight=1 max_fails=5 fail_timeout=100s; server app02:80 weight=1 max_fails=5 fail_timeout=100s; } server { location / { proxy_pass http://backend; proxy_next_upstream timeout http_500; proxy_next_upstream_tries 1; ... } ... }
Em 2 de julho de
2019 , a documentação
estabeleceu que o parâmetro
max_fails define o número de tentativas malsucedidas de trabalhar com o servidor que devem ocorrer dentro do tempo especificado pelo parâmetro
fail_timeout .
O parâmetro
fail_timeout define o tempo durante o qual o número especificado de tentativas sem êxito de trabalhar com o servidor deve ocorrer para que o servidor seja considerado indisponível; e o tempo durante o qual o servidor será considerado indisponível.
No exemplo fornecido, parte do arquivo de configuração, o balanceador está configurado para capturar 5 chamadas com falha em 100 segundos.
Retornando o Servidor de Aplicativos para o Conjunto de Servidores de Produção
Como segue na documentação, o balanceador após
fail_timeout não pode considerar o servidor inoperante. Infelizmente, a documentação não estabelece explicitamente como o desempenho do servidor é avaliado.
Sem um experimento, pode-se supor que o mecanismo de verificação do estado seja semelhante ao descrito anteriormente.
Expectativas e Realidade
Na configuração apresentada, o seguinte comportamento é esperado do balanceador:
- Até que o balanceador exclua o servidor de aplicativos nº 2 do conjunto de servidores de produção, as solicitações do cliente serão enviadas a ele.
- As solicitações retornadas com um erro 500 do servidor de aplicativos nº 2 serão encaminhadas para o próximo servidor de aplicativos e o cliente receberá respostas positivas.
- Assim que o balanceador receber 5 respostas com o código 500 em 100 segundos, ele excluirá o servidor de aplicativos nº 2 do conjunto de servidores de produção. Todas as solicitações após uma janela de 100 segundos serão enviadas imediatamente para os servidores de aplicativos restantes, sem tempo adicional.
- Após 100 segundos, de alguma forma, o balanceador deve avaliar o desempenho do servidor de aplicativos e devolvê-lo ao conjunto de servidores de produção.
Após a realização de testes em espécie, de acordo com as revistas do balanceador, foi estabelecido que a declaração nº 3 não funciona. O balanceador exclui um servidor inativo assim que a condição no parâmetro
max_fails for
atendida . Assim, um servidor com falha é excluído do serviço sem aguardar o tempo decorrido de 100 segundos. O parâmetro
fail_timeout desempenha a função apenas do limite superior do tempo de acumulação de erros.
Como parte da asserção nº 4, verifica-se que o nginx verifica a funcionalidade de um aplicativo que foi anteriormente excluído da manutenção do servidor com apenas uma solicitação. E se o servidor ainda responder com um erro, a próxima verificação
falhará após
fail_timeout .
O que está faltando?
- O algoritmo implementado no nginx / 1.17.0 pode não ser a maneira mais justa de verificar o desempenho do servidor antes de devolvê-lo ao pool de servidores de produção. Pelo menos, de acordo com a documentação atual, não é esperado 1 pedido, mas a quantidade especificada em max_fails .
- O algoritmo de verificação de estado não leva em consideração a velocidade das solicitações. Quanto maior, mais forte o espectro, com tentativas malsucedidas, muda para a esquerda e o servidor de aplicativos sai do pool de servidores em funcionamento muito rapidamente. Suponho que isso possa afetar adversamente os aplicativos que se permitem produzir erros "coágulos de tempo curto". Por exemplo, ao coletar lixo.

Gostaria de perguntar se existe algum benefício prático do algoritmo de verificação de integridade do servidor, que mede a velocidade das tentativas com falha?