Antigamente, tínhamos apenas alguns serviços, e lançar uma atualização de mais de um deles em produção em um dia foi um grande
sucesso . Então o mundo acelerou, o sistema se tornou mais complexo e nos transformamos em uma organização com arquitetura de microsserviço. Agora, temos cerca de cem serviços e, com o aumento de seu número, a frequência de lançamentos também aumenta - são mais de 250 por semana.
E se novos recursos forem testados nas equipes de produtos, a tarefa da equipe de testes de integração é verificar se as alterações incluídas no release não quebram a funcionalidade do componente, sistema e outros recursos.

Trabalho como engenheiro de automação de teste na Yandex.Money.
Neste artigo, falarei sobre a evolução dos testes de integração de serviços da Web, bem como sobre a adaptação do processo para aumentar o número de componentes do sistema e aumentar a frequência dos lançamentos.
Sobre as mudanças no ciclo de lançamento e o desenvolvimento do mecanismo de cálculo foram descritas por ops e dev em
um dos artigos anteriores . Vou falar sobre o histórico de alterações nos processos de teste durante essa transformação.
Agora, temos cerca de 30 equipes de desenvolvimento. A equipe geralmente inclui o gerente de produto, gerente de projeto, desenvolvedores e testadores de front-end e back-end. Eles são unidos pelo trabalho em tarefas para um produto específico. Pelo serviço, em regra, a equipe é responsável, o que geralmente faz alterações.
Teste de aceitação de ponta a ponta
Há pouco tempo, com o lançamento de cada componente, apenas os testes de unidade e componente foram executados e, depois disso, apenas alguns dos scripts de ponta a ponta mais importantes foram executados em um ambiente de teste completo antes de colocar o serviço em produção. Juntamente com o aumento no número de componentes, o número de conexões entre eles começou a crescer exponencialmente. Frequentemente - conexões completamente não triviais. Lembro-me de como a indisponibilidade do serviço para a emissão de dados de marketing quebrou completamente o registro do usuário (é claro, por um curto período de tempo).
Essa abordagem para verificar as alterações começou a falhar cada vez mais - era necessário cobrir todos os cenários críticos de negócios com autotestes e executá-los em um ambiente de teste completo com uma versão de componente pronta para lançamento.
Ok, os autotestes para cenários críticos apareceram - mas como executá-los? Havia uma tarefa a integrar no ciclo de lançamento, afetando minimamente sua confiabilidade com quedas de teste falsas. Por outro lado, eu queria realizar o estágio de teste de integração o mais rápido possível. Portanto, havia uma infraestrutura para realizar testes de aceitação.
Tentamos aproveitar ao máximo as ferramentas já usadas para executar o componente no ciclo de lançamento e executar tarefas: Jira e Jenkins, respectivamente.
Ciclo de testes de aceitação
Para realizar o teste de aceitação, determinamos o seguinte ciclo:
- monitoramento de tarefas recebidas para teste de aceitação de uma liberação,
- executando o trabalho Jenkins para instalar a compilação do release em um ambiente de teste,
- verifique se o serviço aumentou,
- iniciar o trabalho Jenkins com testes de integração,
- análise dos resultados da corrida,
- teste repetido (se necessário),
- atualização do status da tarefa - concluída ou interrompida, indicando o motivo no comentário.
Todo o ciclo foi realizado manualmente a cada vez. Como resultado, já no décimo lançamento por dia, eu queria jurar executar as mesmas tarefas, na melhor das hipóteses, em voz baixa, segurando minha cabeça e exigindo
cerveja de valeriana.
Monitor Bot
Percebemos que rastrear e relatar novas tarefas no Jira são processos importantes que são rápidos e fáceis de automatizar. Então havia um bot que faz isso.
Os dados para gerar alertas são apresentados na forma de notificações push do Jira. Após o lançamento do bot, paramos de atualizar a página do painel com tarefas de aceitação e a largura do sorriso do autômato aumentou um pouco.
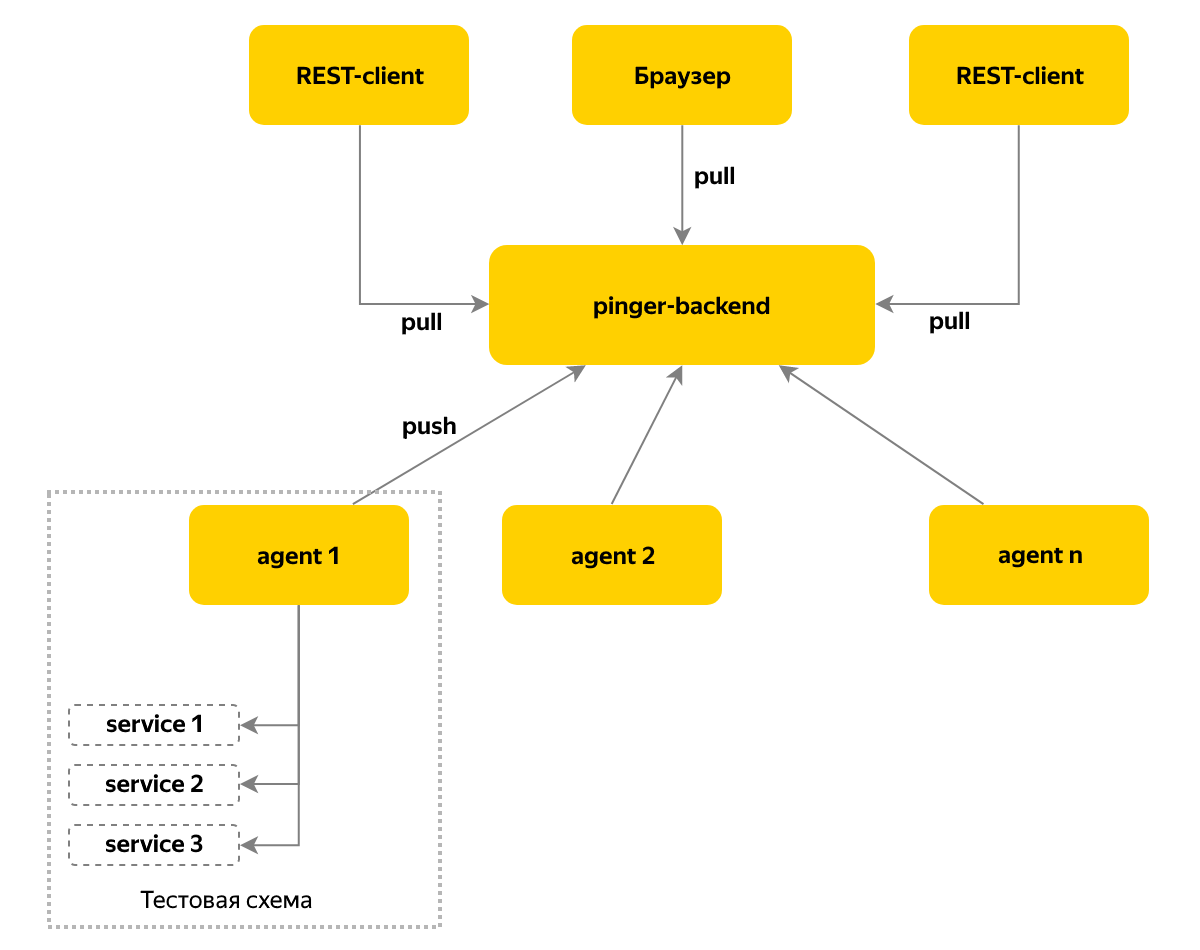
Pinger
Decidimos simplificar a verificação de que durante a implantação no ambiente de teste não ocorreram erros de montagem ou instalação e que a versão desejada do componente foi gerada, e não outra. O componente fornece sua versão e status via HTTP. E verificar se o serviço retorna a versão correta seria simples e compreensível se componentes diferentes não fossem escritos em idiomas diferentes - alguns no Node.js, outros no C #. Além disso, nossos serviços mais populares em Java também forneceram a versão em um formato diferente.
Além disso, eu queria ter informações e notificações em tempo real, não apenas sobre alterações de versão, mas também sobre alterações na disponibilidade de componentes no sistema. Para resolver esse problema, o serviço Pinger apareceu, que coleta informações sobre o status e a versão dos componentes pesquisando-os ciclicamente.
Usamos um modelo push de entrega de mensagens - um agente é implantado em cada instância do ambiente de teste, que coleta informações sobre os componentes desse ambiente e armazena os dados em um nó central a cada 10 segundos. Vamos para este nó para o status atual - essa abordagem nos permite oferecer suporte a mais de cem bancadas de teste.
Armário
Chegou a hora de tarefas mais complexas - atualização automática de componentes e execução de testes. Naquela época, nossa equipe já possuía três bancos de teste no OpenStack para testes de aceitação, e primeiro era necessário resolver o problema de gerenciar os recursos dos bancos de teste: seria desagradável se a atualização do próximo lançamento "rolasse" ao executar testes no sistema. Também acontece que o banco de testes está depurado e você não deve usá-lo para aceitação.
Eu queria poder ver o status do emprego e, se necessário, bloquear manualmente o suporte durante a análise dos testes reprovados ou até a conclusão de outros trabalhos.
Por tudo isso, o serviço Locker apareceu. Ele mantém o status da bancada de testes por um longo período de tempo ("ocupado" / "livre"), permite especificar um comentário sobre "ocupado", para que fique claro que agora estamos depurando, recriando uma cópia do ambiente de teste ou executando testes para a próxima versão. Também começamos a bloquear as arquibancadas à noite - com as quais os administradores executam trabalhos de acordo com a programação, como backups e sincronização de banco de dados.
Ao bloquear, o tempo é sempre definido após o qual o bloqueio expira - agora as pessoas não precisam participar do retorno de estandes para o pool disponível e a máquina faz tudo.
Dever
Para distribuir uniformemente a carga entre os membros da equipe para analisar os resultados das execuções de teste, criamos turnos diários. O atendente trabalha com as tarefas de teste de aceitação de lançamentos, analisa autotestes caídos e relata bugs. Se o atendente entender que não está lidando com o fluxo de tarefas, ele poderá pedir ajuda à equipe. No momento, o restante da equipe está envolvida em tarefas que não estão relacionadas a liberações.
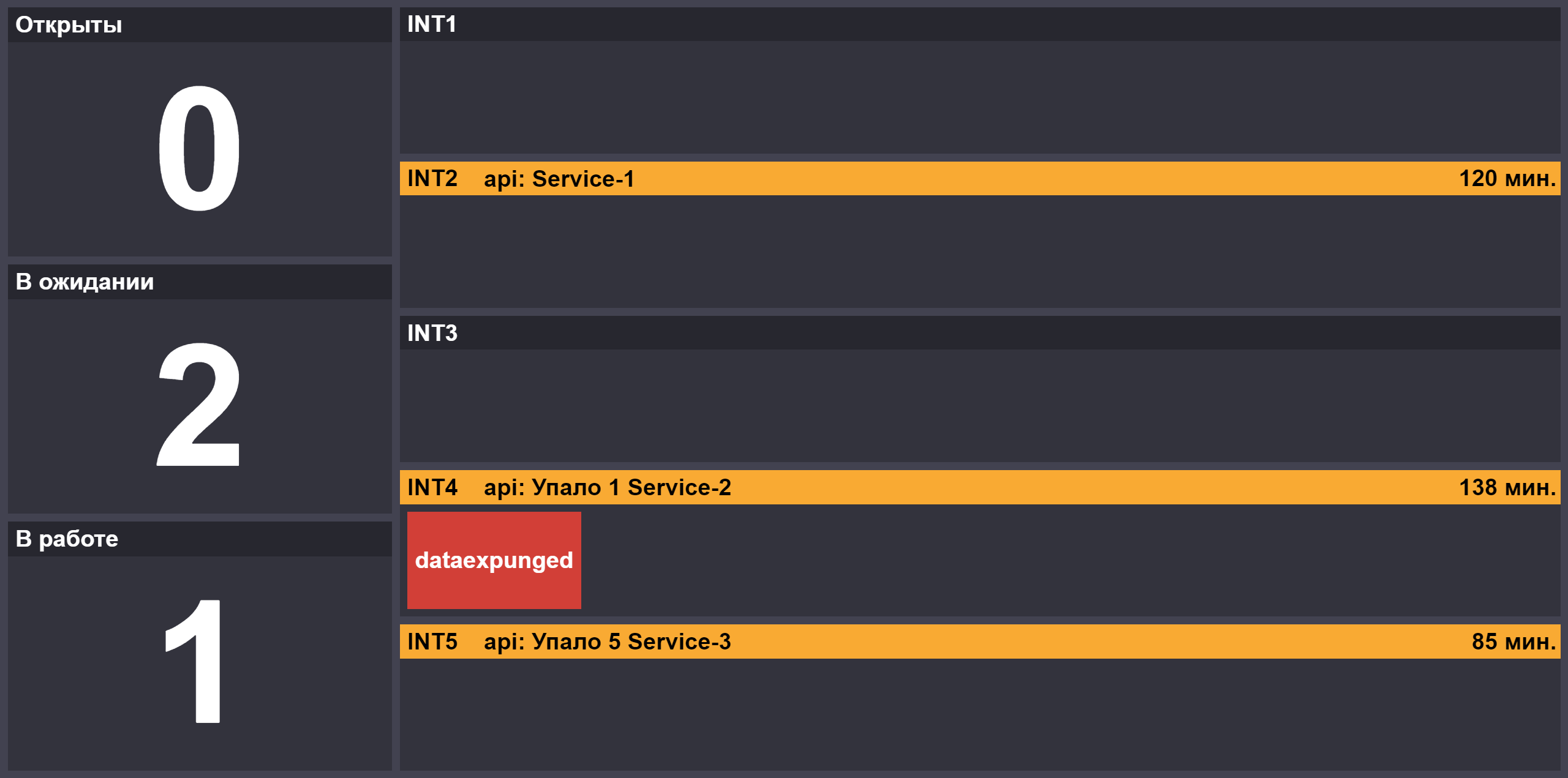
Com o aumento do número de liberações, apareceu o papel do segundo atendente, que se conecta ao principal se houver bloqueios ou se houver liberações críticas na fila. Para fornecer informações sobre o andamento das liberações de teste, criamos uma página com o número de tarefas nos estados "aberto" / "em execução" / "aguardando resposta em serviço", o status dos suportes de teste de bloqueio e os componentes inacessíveis nos suportes:
O trabalho do oficial de serviço exige concentração, para que ele tenha um coque - no dia de serviço, ele pode escolher um local para almoçar para toda a equipe perto do escritório. Os subornos de plantão no estilo parecem especialmente divertidos: "deixe-me ajudá-lo a organizar as tarefas, e hoje iremos para o
meu lugar favorito" =)
Repórter
Uma das tarefas que encontramos quando introduzimos o relógio foi a necessidade de transferir conhecimento de um oficial para outro, por exemplo, sobre testes que caem em um novo release ou os detalhes específicos da atualização de um componente.
Além disso, temos novos recursos de trabalho.
- Havia uma categoria de testes que caíam com maior ou menor frequência devido a problemas nas bancadas de teste. Quedas podem ocorrer devido ao aumento do tempo de resposta de um dos serviços ou ao longo carregamento de recursos no navegador. Não quero desativar os testes; os meios razoáveis para aumentar sua confiabilidade foram esgotados.
- Tivemos um segundo projeto experimental com autoteste, e surgiu a necessidade de analisar as execuções de dois projetos ao mesmo tempo, analisando os relatórios Allure.
- Uma execução de teste pode levar até 20 minutos e você deseja começar a analisar os resultados imediatamente após o início das primeiras quedas. Especialmente se a tarefa for crítica e os membros da equipe responsável pela libertação estiverem atrás de você
, segurando a faca na garganta com olhos tristes.
Foi assim que surgiu o serviço Reporter. Nele, pressionamos os resultados do teste em tempo real durante o processo de teste. O serviço possui um banco de dados de problemas conhecidos ou bugs que estão vinculados a um teste específico. Além disso, foi publicada uma publicação no portal wiki da empresa de um relatório resumido dos resultados da execução do repórter. Isso é conveniente para gerentes que não desejam se aprofundar nos detalhes técnicos com os quais a interface do Reporter ou Allure é abundante.
Se o teste falhar, você pode procurar no Reporter uma lista de bugs relacionados ou corrigir tarefas. Essas informações reduzem o tempo de análise e facilitam a troca de conhecimentos sobre problemas entre os membros de nossa equipe. Os registros das tarefas concluídas são arquivados, mas, se necessário, você pode "espiá-los" em uma lista separada. Para não carregar serviços internos durante o horário comercial, entrevistamos Jira à noite e arquivamos entradas para problemas com o status final.
Um bônus da introdução do Reporter foi o surgimento de um banco de dados de execução, com base no qual você pode analisar a frequência de quedas, classificar os testes de acordo com o nível de estabilidade ou "utilidade" em termos do número de bugs encontrados.
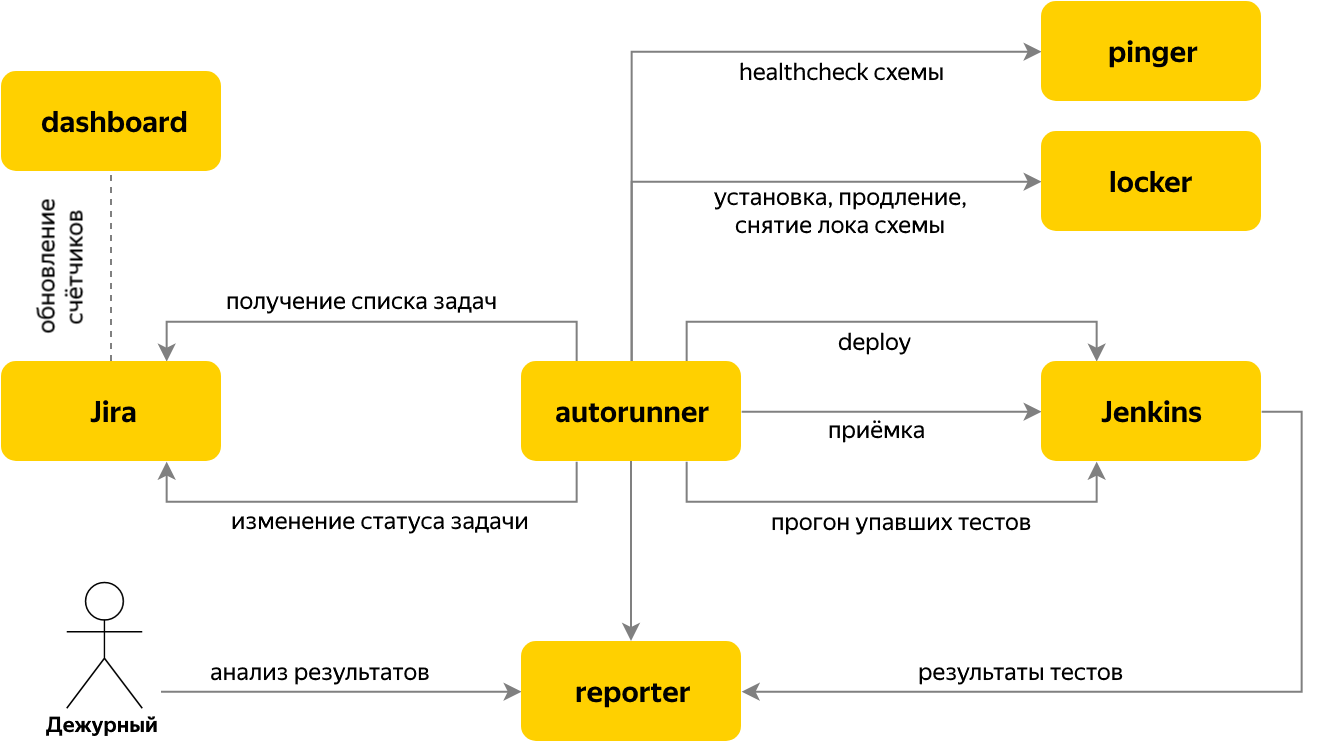
Autorun
Em seguida, passamos a automatizar o lançamento de testes quando o problema do teste de aceitação da versão chegar ao rastreador de problemas. Para esse propósito, o serviço de Execução Automática foi gravado, que verifica se há novas tarefas de aceitação no Jira e, se houver, determina o nome do componente e sua versão com base no conteúdo da tarefa.
Para a tarefa, várias etapas são executadas:
- feche uma das bancadas de teste gratuitas no serviço Locker,
- inicie a instalação do componente necessário no Jenkins, aguarde o componente ser aumentado com a versão necessária,
- executar testes
- aguarde a conclusão da execução do teste, no processo de execução, todos os resultados serão enviados ao Reporter,
- solicitamos ao Reporter o número de testes com falha, excluindo os que caíram devido a problemas conhecidos,
- se 0 caiu - transferimos a tarefa do teste de aceitação para "Concluir" e terminamos de trabalhar com ele. Está tudo pronto =)
- se houver testes "vermelhos" - traduzimos a tarefa em "Aguardando" e vamos ao Reporter para analisá-los.
A alternância entre estágios é organizada pelo princípio de uma máquina de estados finitos. Cada estágio em si conhece as condições para a transição para o próximo. Os resultados do estágio são armazenados no contexto da tarefa, o que é comum para os estágios de uma tarefa.
Tudo isso permite que você transfira automaticamente as liberações ao longo do pipeline de implantação, segundo as quais 100% dos testes são ecológicos. Mas e a instabilidade causada não por problemas no componente, mas pelos recursos "naturais" dos testes de interface do usuário ou pelo aumento de atrasos na rede no banco de testes?
Para fazer isso, implementamos um mecanismo de nova tentativa, que muitas pessoas usam, mas poucas reconhecem isso. Os retrays são organizados como uma execução sequencial de testes no Pipeline Jenkins.
Após a execução, solicitamos uma lista de testes com falha do Reporter da Jenkins - e reiniciamos apenas os com falha. Além disso, reduzimos o número de threads na inicialização. Se o número de testes descartados não diminuiu em comparação com a execução anterior, finalizamos imediatamente o Job. No nosso caso, essa abordagem para reiniciar nos permite aumentar o sucesso do teste de aceitação em cerca de 2 vezes.
Bloqueio rápido
O sistema de teste de aceitação resultante nos permitiu realizar mais de 60% dos lançamentos sem intervenção humana. Mas o que fazer com o resto? Se necessário, o atendente cria um relatório de bug no componente em teste ou na tarefa de corrigir testes na equipe de desenvolvimento. Às vezes - elabora um bug da configuração da bancada de testes para o departamento de operações.
As tarefas para corrigir testes geralmente bloqueiam a passagem correta dos testes automáticos, pois os testes irrelevantes sempre serão "vermelhos". Os testadores das equipes de desenvolvimento são responsáveis por escrever novos testes e atualizar os existentes - fazendo alterações através de solicitações de recebimento do projeto com testes automáticos. Essas edições estão sujeitas a uma revisão obrigatória, que exige algum tempo do revisor e do autor, e quero bloquear temporariamente testes irrelevantes até que a tarefa seja traduzida para seu status final.
Primeiro, implementamos um mecanismo de desligamento baseado em anotações de métodos de teste. Posteriormente, descobriu-se que, devido à presença de uma revisão obrigatória de código, o bloqueio do código nem sempre é conveniente e pode levar mais tempo do que gostaríamos.
Portanto, movemos a lista de tarefas que bloqueiam testes para um novo serviço com uma página da Web - bloqueio rápido. Portanto, os membros da equipe responsável pelo componente podem bloquear rapidamente o teste. Antes da execução, vamos a este serviço e obtemos uma lista de testes em quarentena, que convertemos em status ignorado.
Sumário
Passamos da aceitação de lançamentos no modo manual para um processo quase completamente automático, capaz de realizar testes de aceitação de mais de 50 lançamentos por dia. Isso ajuda a empresa a reduzir o tempo necessário para publicar alterações, e nossa equipe pode encontrar recursos para experimentar e desenvolver ferramentas de teste.
No futuro, planejamos aumentar a confiabilidade do processo, por exemplo, distribuindo solicitações entre um par de instâncias de cada serviço da lista acima. Isso permitirá que você atualize as ferramentas sem tempo de inatividade e inclua novos recursos apenas para parte dos testes de aceitação. Além disso, prestamos atenção à estabilização dos próprios testes. Em desenvolvimento, um gerador de tickets para refatoração de testes com a menor taxa de sucesso.
Melhorar a confiabilidade dos testes não apenas aumentará a confiança neles, mas também agilizará os testes de versões devido à falta de reinicialização de scripts interrompidos.