Olá pessoal! Na próxima segunda-feira, as aulas começarão no novo grupo do curso
Python Developer , o que significa que temos tempo para publicar outro material interessante, o que faremos agora. Boa leitura.

Em 2003, a Intel lançou o novo processador Pentium 4 "HT". Este processador com overclock para 3GHz e suportou a tecnologia hyper-threading.

Nos anos seguintes, Intel e AMD lutaram para alcançar o melhor desempenho de desktop, aumentando a velocidade do barramento, o tamanho do cache L2 e reduzindo o tamanho da matriz para minimizar a latência. Em 2004, o modelo HT com frequência de 3 GHz foi substituído pelo modelo 580 Prescott com overclock para 4 GHz.
Parecia que, para avançar, era apenas necessário aumentar a frequência do relógio; no entanto, os novos processadores sofriam de alto consumo de energia e dissipação de calor.
Seu processador de mesa oferece 4 GHz hoje? É improvável, uma vez que o caminho para melhorar o desempenho acabou por aumentar a velocidade do barramento e aumentar o número de núcleos. Em 2006, o Intel Core 2 substituiu o Pentium 4 e teve uma velocidade de clock muito menor.
Além de liberar processadores com vários núcleos para um amplo público de usuários, outra coisa aconteceu em 2006. Python 2.5 finalmente viu a luz! Ele já veio com uma versão beta da palavra-chave with, que todos vocês conhecem e adoram.
O Python 2.5 teve uma grande limitação no uso do Intel Core 2 ou AMD Athlon X2.
Foi um GIL.
O que é um GIL?
GIL (Global Interpreter Lock) é um valor booleano no interpretador Python protegido por um mutex. O bloqueio é usado no loop de cálculo principal do bytecode do CPython para determinar qual encadeamento está atualmente executando instruções.
O CPython suporta o uso de vários threads em um único intérprete, mas os threads devem solicitar acesso ao GIL para executar operações de baixo nível. Por sua vez, isso significa que os desenvolvedores do Python podem usar código assíncrono, multithreading e não precisam mais se preocupar em bloquear nenhuma variável ou falha no nível do processador durante conflitos.
O GIL simplifica a programação Python multithread.

O GIL também nos diz que, embora o CPython possa ser multiencadeado, apenas um encadeamento por vez pode ser executado. Isso significa que seu processador quad-core faz algo assim (com exceção da tela azul, espero).
A versão atual do GIL
foi escrita em 2009 para oferecer suporte a funções assíncronas e permaneceu inalterada, mesmo após várias tentativas de removê-lo em princípio ou alterar os requisitos para ele.
Qualquer sugestão para remover o GIL foi justificada pelo fato de que o bloqueio global do intérprete não deve prejudicar o desempenho do código de thread único. Qualquer pessoa que tentou ativar o hyperthreading em 2003 entenderá o
que estou falando .
Abandono de Gil no CPython
Se você realmente deseja paralelizar o código no CPython, precisará usar vários processos.
No CPython 2.6, o módulo de
multiprocessamento foi adicionado à biblioteca padrão. O multiprocessamento mascara a geração de processos no CPython (cada processo com seu próprio GIL).
from multiprocessing import Process def f(name): print 'hello', name if __name__ == '__main__': p = Process(target=f, args=('bob',)) p.start() p.join()
Os processos são criados, os comandos são enviados a eles usando módulos compilados e funções Python e, em seguida, são reunidos novamente ao processo principal.
O multiprocessamento também suporta o uso de variáveis através de uma fila ou canal. Ela tem um objeto de bloqueio, que é usado para bloquear objetos no processo principal e gravar de outros processos.
O multiprocessamento tem uma grande desvantagem. Ele carrega uma carga computacional significativa, o que afeta o tempo de processamento e o uso de memória. O tempo de inicialização do CPython, mesmo sem site, é de 100 a 200 ms (consulte
https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b para saber mais).
Como resultado, você pode ter um código paralelo no CPython, mas ainda precisa planejar cuidadosamente o trabalho de processos de longa execução que compartilham vários objetos.
Outra alternativa pode ser usar um pacote de terceiros como o Twisted.
PEP554 e a morte de GIL?
Então, deixe-me lembrá-lo de que o multithreading no CPython é simples, mas na realidade não é paralelismo, mas o multiprocessamento é paralelo, mas implica uma sobrecarga significativa.
E se houver uma maneira melhor?A chave para ignorar o GIL está no nome, o bloqueio global do intérprete faz parte do estado global do intérprete. Os processos CPython podem ter vários intérpretes e, portanto, vários bloqueios, no entanto, essa função raramente é usada, pois o acesso a ele é apenas por meio da C-API.
Um dos recursos do CPython 3.8 é o PEP554, uma implementação de sub-intérpretes e APIs com um novo módulo de
interpreters na biblioteca padrão.
Isso permite criar vários intérpretes a partir do Python em um único processo. Outra inovação do Python 3.8 é que todos os intérpretes terão seu próprio GIL.
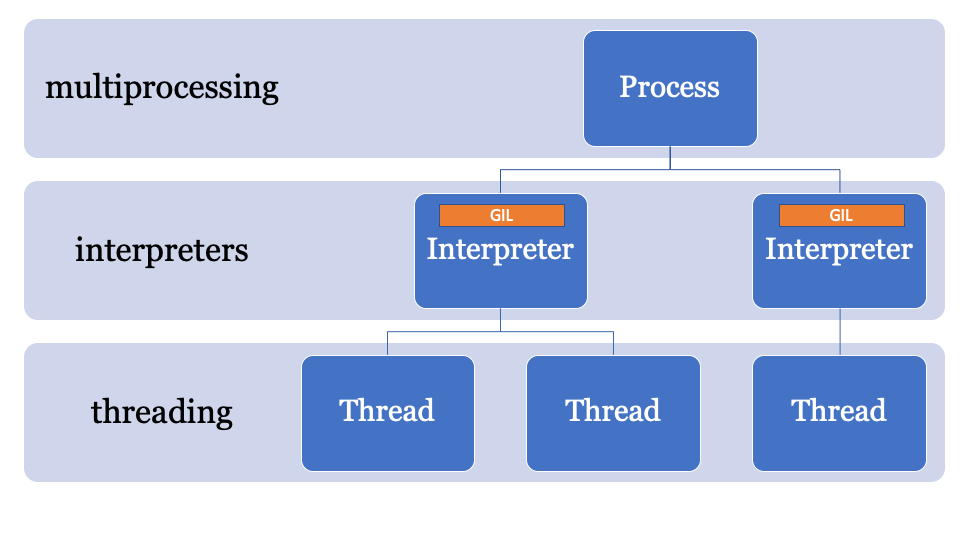
Como o estado do intérprete contém uma região alocada na memória, uma coleção de todos os ponteiros para objetos Python (local e global), os subinterpretadores no PEP554 não podem acessar as variáveis globais de outros intérpretes.
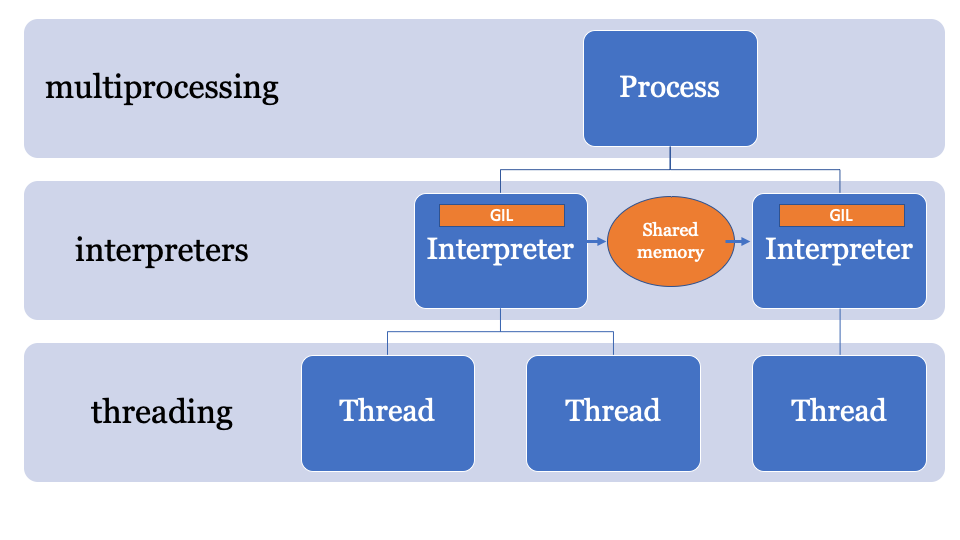
Como o multiprocessamento, os intérpretes que compartilham objetos consistem em serializá-los e usar o formulário IPC (rede, disco ou memória compartilhada). Existem várias maneiras de serializar objetos no Python, por exemplo, o módulo
marshal , o módulo
pickle ou métodos mais padronizados, como
json ou
simplexml . Cada um deles tem seus prós e contras, e todos oferecem uma carga de computação.
Seria melhor ter um espaço de memória comum que possa ser alterado e controlado por um processo específico. Assim, os objetos podem ser enviados pelo intérprete principal e recebidos por outro intérprete. Este será o espaço de memória gerenciado para procurar ponteiros PyObject, que todo intérprete pode acessar, enquanto o processo principal gerenciará os bloqueios.
Uma API para isso ainda está sendo desenvolvida, mas provavelmente será algo como isto:
import _xxsubinterpreters as interpreters import threading import textwrap as tw import marshal
Este exemplo usa NumPy. A matriz numpy é enviada pelo canal, é serializada usando o módulo
marshal , em seguida, o subinterpretador processa os dados (em um GIL separado); portanto, pode haver um problema de paralelismo associado à CPU, ideal para subinterpretadores.
Parece ineficiente
O módulo
marshal funciona muito rápido, mas não tão rápido quanto compartilhar objetos diretamente da memória.
O PEP574 apresenta um novo protocolo de
pickle (v5) que suporta a capacidade de processar buffers de memória separadamente do restante do fluxo de pickle. Para objetos de dados grandes, a serialização de todos de uma só vez e a desserialização de um subinterpretador adicionará muita sobrecarga.
A nova API pode ser implementada (puramente hipoteticamente) da seguinte maneira:
import _xxsubinterpreters as interpreters import threading import textwrap as tw import pickle
Parece padronizado
Em essência, este exemplo é baseado no uso da API de subinterpretadores de baixo nível. Se você não usou a biblioteca de
multiprocessing , alguns problemas lhe parecerão familiares. Não é tão simples quanto o processamento de fluxo, você não pode simplesmente, digamos, executar esta função com uma lista de dados de entrada em intérpretes separados (por enquanto).
Assim que esse PEP se fundir com outros, acho que veremos várias novas APIs no PyPi.
Quanta sobrecarga o subinterpretador possui?
Resposta curta: mais que um fluxo, menos que um processo.
Resposta longa: o intérprete tem seu próprio estado, portanto, será necessário clonar e inicializar o seguinte, apesar do PEP554 simplificar a criação de subinterpretadores:
- Módulos no
importlib __main__ e importlib ; - O conteúdo do dicionário
sys ; - Funções
print() ( print() , assert , etc.); - Córregos;
- Configuração do kernel.
A configuração do kernel pode ser facilmente clonada da memória, mas a importação de módulos não é tão simples. A importação de módulos no Python é lenta, portanto, se criar um subinterpretador significa importar módulos para um espaço de nome diferente a cada vez, os benefícios são reduzidos.
E o assíncio?
A implementação existente do
asyncio eventos
asyncio na biblioteca padrão cria quadros de pilha para avaliação e também
asyncio estado no intérprete principal (e, portanto, compartilha o GIL).
Após combinar o PEP554, provavelmente já no Python 3.9, uma implementação alternativa do loop de eventos pode ser usada (embora ninguém tenha feito isso ainda), que executa métodos assíncronos em subinterpretadores em paralelo.
Parece legal, me envolva também!
Bem, na verdade não.
Como o CPython está em execução no mesmo intérprete há tanto tempo, muitas partes da base de código usam "Runtime State" em vez de "Interpreter State", portanto, se o PEP554 fosse introduzido agora, ainda haveria muitos problemas.
Por exemplo, o estado do coletor de lixo (nas versões 3.7 <) pertence ao tempo de execução.
Nas mudanças durante os sprints do PyCon, o estado do coletor de lixo
começou a passar para o intérprete, de modo que cada subinterpretador tivesse seu próprio coletor de lixo (como deveria ser).
Outro problema é que existem algumas variáveis "globais" que permaneceram na base de código do CPython junto com muitas extensões em C. Portanto, quando as pessoas começaram a paralelizar seu código de repente, vimos alguns problemas.
Outro problema é que os descritores de arquivo pertencem ao processo, portanto, se você tiver um arquivo aberto para gravação em um intérprete, o subinterpretador não poderá acessar esse arquivo (sem alterações adicionais no CPython).
Em resumo, ainda existem muitos problemas que precisam ser resolvidos.
Conclusão: O GIL é mais verdadeiro?
O GIL continuará sendo usado para aplicativos de thread único. Portanto, mesmo ao seguir o PEP554, seu código de thread único repentinamente não ficará paralelo.
Se você deseja escrever código paralelo no Python 3.8, você terá problemas de paralelização associados ao processador, mas este também é um ticket para o futuro!
Quando?
O Pickle v5 e o compartilhamento de memória para multiprocessamento provavelmente estarão no Python 3.8 (outubro de 2019), e os sub-intérpretes aparecerão entre as versões 3.8 e 3.9.
Se você deseja brincar com os exemplos apresentados, criei um ramo separado com todo o código necessário:
https://github.com/tonybaloney/cpython/tree/subinterpreters.O que você acha disso? Escreva seus comentários e até o curso.