Meu nome é Stas Kirillov, sou um desenvolvedor líder no grupo de plataformas ML em Yandex. Estamos desenvolvendo ferramentas de aprendizado de máquina, dando suporte e desenvolvendo infraestrutura para elas. Abaixo está minha recente conversa sobre como a biblioteca CatBoost funciona. No relatório, falei sobre os pontos de entrada e os recursos do código para quem deseja entendê-lo ou se tornar nosso colaborador.
- O CatBoost vive no GitHub sob a licença Apache 2.0, ou seja, é aberto e gratuito para todos. O projeto está em desenvolvimento ativo, agora nosso repositório tem mais de quatro mil estrelas. O CatBoost é escrito em C ++, é uma biblioteca para aumento de gradiente em árvores de decisão. Ele suporta vários tipos de árvores, incluindo as chamadas árvores "simétricas", que são usadas na biblioteca por padrão.
Qual é o lucro de nossas árvores alheias? Eles aprendem rapidamente, aplicam-se rapidamente e ajudam a aprender a ser mais resistente à alteração de parâmetros em termos de alterações na qualidade final do modelo, o que reduz bastante a necessidade de seleção de parâmetros. Nossa biblioteca é para facilitar o uso na produção, aprender rápido e obter boa qualidade imediatamente.

O aumento de gradiente é um algoritmo no qual construímos preditores simples que melhoram nossa função objetivo. Ou seja, em vez de construir imediatamente um modelo complexo, criamos muitos modelos pequenos por sua vez.

Como está o processo de aprendizado no CatBoost? Eu vou te dizer como isso funciona em termos de código. Primeiro, analisamos os parâmetros de treinamento que o usuário passa, os validamos e depois verificamos se precisamos carregar os dados. Como os dados já podem ser carregados - por exemplo, em Python ou R. Em seguida, carregamos os dados e construímos uma grade a partir das bordas para quantificar os recursos numéricos. Isso é necessário para acelerar o aprendizado.
Características categóricas, processamos um pouco diferente. Categorizamos os recursos desde o início e, em seguida, renumeramos os hashes de zero ao número de valores exclusivos do recurso categórico para ler rapidamente combinações de recursos categóricos.
Em seguida, lançamos o ciclo de treinamento diretamente - o principal ciclo de nosso aprendizado de máquina, onde iterativamente construímos árvores. Após esse ciclo, o modelo é exportado.
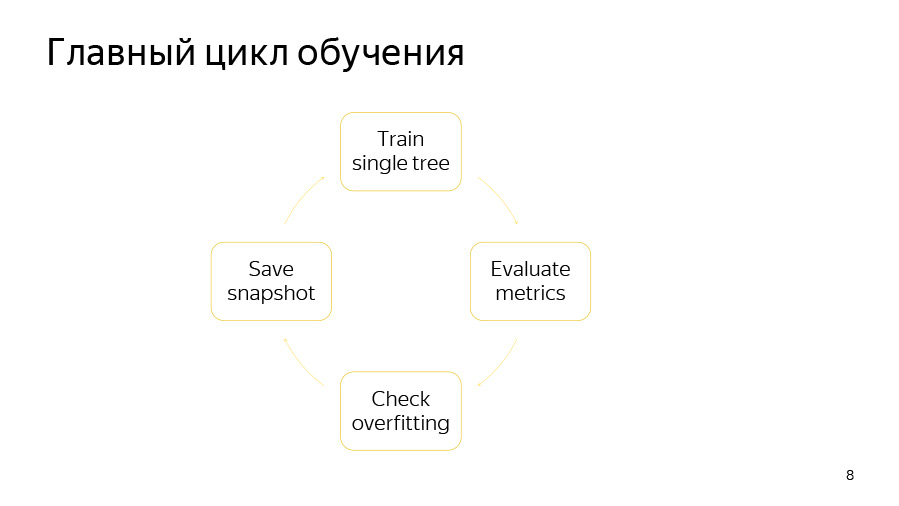
O próprio ciclo de treinamento consiste em quatro pontos. Primeiro, estamos tentando construir uma árvore. Em seguida, analisamos que tipo de aumento ou diminuição da qualidade isso oferece. Em seguida, verificamos se nosso detector de reciclagem funcionou. Então, se for a hora certa, salvamos o instantâneo.

Aprender uma única árvore é um ciclo através dos níveis das árvores. No início, selecionamos aleatoriamente uma permutação de dados se usarmos o reforço ordenado ou tivermos recursos categóricos. Então contamos os contadores nessa permutação. Em seguida, tentamos escolher avidamente boas divisões nesta árvore. Por divisões, queremos dizer simplesmente certas condições binárias: tal e tal característica numérica é maior que tal ou tal valor, ou tal e tal contador por característica categórica é maior que tal e tal valor.
Como é organizado o ciclo de nível de árvore gananciosa? No início, a inicialização é feita - nós pesamos novamente ou amostramos os objetos, após o qual apenas os objetos selecionados serão usados para construir a árvore. O Bootstrap também pode ser recontado antes de selecionar cada divisão, se a opção de amostragem em cada nível estiver ativada.
Em seguida, agregamos as derivadas em histogramas, como fazemos para cada candidato dividido. Usando histogramas, tentamos avaliar a mudança na função objetivo que ocorrerá se selecionarmos esse candidato dividido.
Selecionamos o candidato com a melhor velocidade e o adicionamos à árvore. Em seguida, calculamos as estatísticas usando essa árvore selecionada nas permutações restantes, atualizamos o valor nas folhas nessas permutações, calculamos os valores nas folhas para o modelo e prosseguimos para a próxima iteração do loop.

É muito difícil destacar um local onde o treinamento é realizado; portanto, neste slide - você pode usá-lo como um ponto de entrada - os principais arquivos que usamos para o treinamento estão listados. Trata-se de greedy_tensor_search, no qual vivemos o próprio procedimento para a seleção gananciosa de divisões. Este é o train.cpp, onde temos a principal fábrica de treinamento de CPU. Isto é aprox_calcer, onde estão as funções de atualização dos valores nas folhas. E também score_calcer - uma função para avaliar algum candidato.
Partes igualmente importantes são catboost.pyx e core.py. Esse é o código do wrapper python, provavelmente muitos de vocês incorporarão algum tipo de material no wrapper python. Nosso wrapper python é escrito em Cython, o Cython é traduzido em C ++, portanto esse código deve ser rápido.
Nosso wrapper R está na pasta R-package. Talvez alguém tenha que adicionar ou consertar algumas opções; para opções, temos uma biblioteca separada - catboost / libs / options.
Viemos de Arcadia para o GitHub, por isso temos muitos artefatos interessantes que você encontrará.


Vamos começar com a estrutura do repositório. Temos uma pasta util onde as primitivas básicas são: vetores, mapas, sistemas de arquivos, trabalho com strings, streams.
Temos uma biblioteca na qual as bibliotecas compartilhadas usadas pelo Yandex estão localizadas - muitas, não apenas o CatBoost.
A pasta CatBoost e contrib é o código das bibliotecas de terceiros às quais vinculamos.
Vamos agora falar sobre as primitivas de C ++ que você encontrará. O primeiro são indicadores inteligentes. No Yandex, usamos THolder desde std :: unique_ptr, e MakeHolder é usado em vez de std :: make_unique.

Nós temos nosso próprio SharedPtr. Além disso, ele existe em duas formas, SimpleSharedPtr e AtomicSharedPtr, que diferem no tipo de contador. Em um caso, é atômico, o que significa que como se vários fluxos pudessem possuir um objeto. Portanto, será seguro do ponto de vista da transferência entre fluxos.
Uma classe separada, IntrusivePtr, permite que você possua objetos herdados da classe TRefCounted, ou seja, classes que possuem um contador de referência incorporado. Isso é para alocar esses objetos por vez, sem alocar adicionalmente um bloco de controle com um contador.
Também temos nosso próprio sistema de entrada e saída. IInputStream e IOutputStream são interfaces para entrada e saída. Eles têm métodos úteis, como ReadTo, ReadLine, ReadAll, em geral, tudo o que é esperado de InputStreams. E temos implementações desses fluxos para trabalhar com o console: Cin, Cout, Cerr e Endl separadamente, que é semelhante ao std :: endl, ou seja, libera o fluxo.

Também temos nossas próprias implementações de interface para arquivos: TInputFile, TOutputFile. Esta é uma leitura em buffer. Eles implementam leitura em buffer e gravação em buffer em um arquivo, para que você possa usá-los.
Util / system / fs.h possui os métodos NFs :: Exists e NFs :: Copy, se você precisar copiar algo repentinamente ou verificar se realmente existe algum arquivo.

Nós temos nossos próprios contêineres. Eles passaram a usar std :: vector há algum tempo, ou seja, eles simplesmente herdam de std :: vector, std :: set e std :: map, mas também temos nosso próprio THashMap e THashSet, que em parte possuem interfaces compatíveis com unordered_map e unordered_set. Mas, para algumas tarefas, eles se mostraram mais rápidos, por isso ainda os usamos.

As referências de matriz são análogas ao std :: span do C ++. É verdade que ele apareceu conosco não no vigésimo ano, mas muito antes. Nós o usamos ativamente para transferir referências a matrizes, como se alocadas em buffers grandes, para não alocar buffers temporários todas as vezes. Suponha que, para contar derivadas ou algumas aproximações, possamos alocar memória em algum buffer grande pré-alocado e passar apenas TArrayRef para a função de contagem. É muito conveniente e usamos muito.

O Arcadia usa seu próprio conjunto de classes para trabalhar com strings. Primeiro, TStingBuf - um análogo de str :: string_view do C ++ 17.
TString não é de todo std :: sting, é uma string CopyOnWrite, portanto você precisa trabalhar com ela com muito cuidado. Além disso, TUtf16String é o mesmo TString, apenas seu tipo base não é char, mas wchar de 16 bits.
E temos ferramentas para converter de string para string. Este é o ToString, que é um análogo de std :: to_string e FromString emparelhado com o TryFromString, que permite transformar a string no tipo que você precisa.

Nós temos nossa própria estrutura de exceção, a exceção básica nas bibliotecas de arcade é a exceção, que herda de std :: exception. Temos uma macro ythrow que adiciona informações sobre o local onde a exceção foi lançada na yexception, é apenas um invólucro conveniente.
Existe um análogo de std :: current_exception - CurrentExceptionMessage, essa função lança a exceção atual como uma string.
Existem macros para afirmações e verificações - são Y_ASSERT e Y_VERIFY.

E nós temos nossa própria serialização embutida, é binária e não se destina a transferir dados entre diferentes revisões. Em vez disso, essa serialização é necessária para transferir dados entre dois binários da mesma revisão, por exemplo, no aprendizado distribuído.
Aconteceu que temos duas versões de serialização no CatBoost. A primeira opção funciona através dos métodos de interface Salvar e Carregar, que serializam no fluxo. Outra opção é usada em nosso treinamento distribuído: ele usa uma biblioteca BinSaver interna bastante antiga, conveniente para serializar objetos polimórficos que devem ser registrados em uma fábrica especial. Isso é necessário para o treinamento distribuído, sobre o qual é improvável que tenhamos tempo para conversar aqui.

Também temos nosso próprio boost_optional analógico ou std :: optional - TMaybe. Análogo de std :: variant - TVariant. Você precisa usá-los.

Há uma certa convenção de que, dentro do código CatBoost, lançamos uma TCatBoostException em vez de uma yexception. Essa é a mesma exceção, apenas o rastreamento de pilha é sempre adicionado quando é lançado.
E também usamos a macro CB_ENSURE para verificar convenientemente algumas coisas e lançar exceções, se não forem executadas. Por exemplo, geralmente usamos isso para analisar opções ou analisar parâmetros passados pelo usuário.

Antes de começar, recomendamos que você se familiarize com o estilo do código, que consiste em duas partes. O primeiro é um estilo de código de arcada geral, que fica diretamente na raiz do repositório no arquivo CPP_STYLE_GUIDE.md. Também na raiz do repositório há um guia separado para nossa equipe: catboost_command_style_guide_extension.md.
Estamos tentando formatar o código Python usando o PEP8. Nem sempre funciona, porque para o código Cython, o linter não funciona para nós e, às vezes, algo acontece com o PEP8.

Quais são as características da nossa montagem? O conjunto Arcadia foi originalmente destinado a coletar os aplicativos mais herméticos, ou seja, que haveria um mínimo de dependências externas devido à vinculação estática. Isso permite que você use o mesmo binário em diferentes versões do Linux sem recompilar, o que é bastante conveniente. As metas de montagem são descritas nos arquivos ya.make. Um exemplo de ya.make pode ser visto no próximo slide.

Se de repente você quiser adicionar algum tipo de biblioteca, programa ou outra coisa, você pode, primeiro, apenas olhar nos arquivos ya.make vizinhos e, em segundo lugar, usar este exemplo. Aqui listamos os elementos mais importantes do ya.make. No início do arquivo, dizemos que queremos declarar uma biblioteca e, em seguida, listamos as unidades de compilação que queremos colocar nessa biblioteca. Aqui podem estar os dois arquivos cpp e, por exemplo, arquivos pyx para os quais o Cython será iniciado automaticamente e, em seguida, o compilador. As dependências da biblioteca são listadas através da macro PEERDIR. Ele simplesmente grava os caminhos para a pasta com a biblioteca ou com outro artefato, relativo à raiz do repositório.
Existe uma coisa útil, GENERATE_ENUM_SERIALIZATION, necessária para gerar métodos ToString, FromString para classes de enumeração e enumerações descritas em algum arquivo de cabeçalho que você passa para essa macro.

Agora, a coisa mais importante - como compilar e executar algum tipo de teste. Na raiz do repositório está o script ya, que baixa os kits de ferramentas e ferramentas necessárias, e possui o comando ya make, o subcomando make, que permite criar uma versão -r com uma opção -d e uma versão de depuração com a opção -d. Os artefatos são transmitidos e separados por um espaço.
Para criar o Python, apontei imediatamente aqui bandeiras que podem ser úteis. Estamos falando de criar com o sistema Python, neste caso com o Python 3. Se você repentinamente tiver um CUDA Toolkit instalado em seu laptop ou máquina de desenvolvimento, para uma montagem mais rápida, recomendamos especificar o sinalizador –d have_cuda no. O CUDA é desenvolvido por algum tempo, especialmente em sistemas de 4 núcleos.

Ya ide já deve funcionar. Esta é uma ferramenta que irá gerar uma solução clion ou qt para você. E para aqueles que vieram com o Windows, temos uma solução Microsoft Visual Studio, que fica na pasta msvs.
Ouvinte:
- Você tem todos os testes através do wrapper Python?
Stas:
- Não, temos separadamente testes que estão na pasta pytest. Estes são testes da nossa interface CLI, ou seja, do nosso aplicativo. É verdade que eles funcionam através do pytest, ou seja, são funções do Python nas quais fazemos uma chamada de verificação de subprocesso e verificamos que o programa não falha e funciona corretamente com alguns parâmetros.
Ouvinte:
- E os testes de unidade em C ++?
Stas:
- Também temos testes de unidade em C ++. Eles geralmente estão na pasta lib em subpastas ut. E eles são escritos assim - teste de unidade ou teste de unidade para. Existem exemplos. Existem macros especiais para declarar uma classe de teste de unidade e registros separados para a função de teste de unidade.
Ouvinte:
- Para verificar se nada quebrou, é melhor iniciar esses e aqueles?
Stas:
Sim. A única coisa é que nossos testes de código aberto são verdes apenas no Linux. Portanto, se você compilar, por exemplo, no Mac, se cinco testes falharem, não haverá motivo para preocupação. Devido à diferente implementação do expositor em diferentes plataformas ou outras diferenças menores, os resultados podem ser muito diferentes.

Por um exemplo, vamos fazer uma tarefa. Eu gostaria de mostrar um exemplo. Temos um arquivo com tarefas - open_problems.md. Vamos resolver o problema №4 de open_problems.md. Ele é formulado da seguinte maneira: se o usuário definir a taxa de aprendizado como zero, devemos cair de TCatBoostException. Você precisa adicionar a validação de opções.
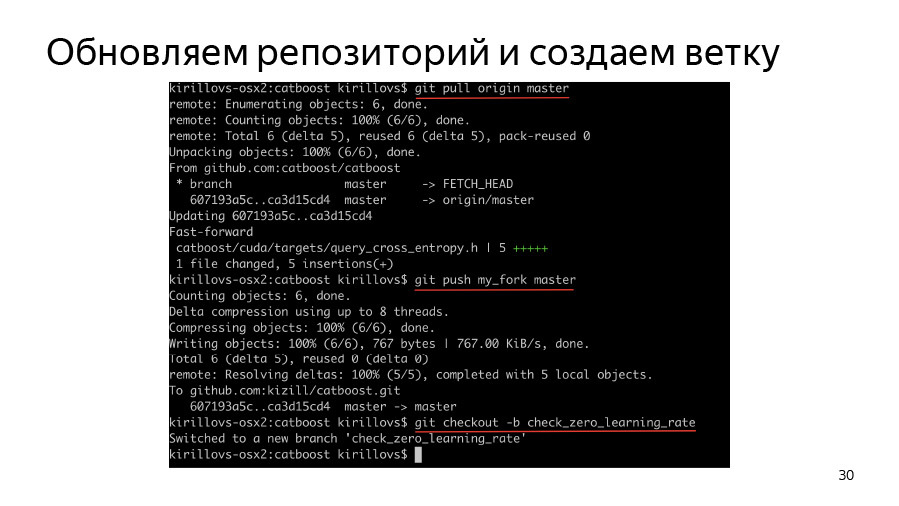
Primeiro, precisamos criar uma ramificação, clonar nosso fork, origem do clone, origem pop, executar a origem no fork e, em seguida, criar um branch e começar a trabalhar nele.
Como a análise de opções funciona? Como eu disse, temos uma importante pasta catboost / libs / options onde a análise de todas as opções é armazenada.

Temos todas as opções armazenadas no wrapper TOption, o que nos permite entender se a opção foi substituída pelo usuário. Caso contrário, ele mantém algum valor padrão em si. Em geral, o CatBoost analisa todas as opções na forma de um grande dicionário JSON, que durante a análise se transforma em dicionários e estruturas aninhados.

De alguma forma, descobrimos - por exemplo, pesquisando com um grep ou lendo o código - que temos a taxa de aprendizado em TBoostingOptions. Vamos tentar escrever um código que simplesmente adicione CB_ENSURE, que nossa taxa de aprendizado seja mais que std :: numeric_limits :: epsilon, que o usuário inseriu algo mais ou menos razoável.

Aqui apenas usamos a macro CB_ENSURE, escrevemos algum código e agora queremos adicionar testes.

Nesse caso, adicionamos um teste na interface da linha de comandos. Na pasta pytest, temos o script test.py, onde já existem alguns exemplos de testes e você pode escolher um que se pareça com a sua tarefa, copiá-lo e alterar os parâmetros para que comece a cair ou não cair, dependendo dos parâmetros que você passou. Nesse caso, apenas pegamos e criamos um pool simples de duas linhas. (Chamamos os conjuntos de dados no Yandex. Essa é a nossa peculiaridade.) E depois verificamos se nosso binário realmente cai se passarmos a taxa de aprendizado 0,0.

Também adicionamos um teste ao python-package, localizado em atBoost / python-package / ut / medium. Também temos grandes e grandes testes relacionados a testes para a criação de pacotes de roda python.

Além disso, temos chaves para você criar - -t e -A. -t executa testes, -A força todos os testes a serem executados, independentemente de terem tags grandes ou médias.
Aqui, por beleza, também usei um filtro chamado test. É definido usando a opção -F e o nome do teste especificado posteriormente, que podem ser caracteres de caracteres selvagens. Nesse caso, usei test.py::test_zero_learning_rate*, porque, observando nossos testes de pacotes python, você verá: quase todas as funções usam um dispositivo de tipo de tarefa. Isso é feito de acordo com o código, nossos testes de pacotes python têm a mesma aparência para aprendizado de CPU e GPU e podem ser usados para testes de instrutor de GPU e CPU.

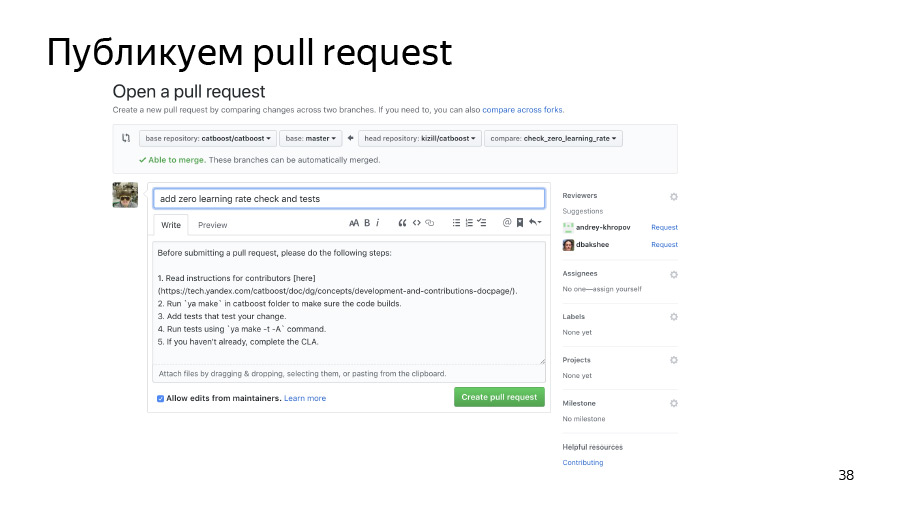
Em seguida, confirme nossas alterações e envie-as para o repositório bifurcado. Publicamos a solicitação de pool. Ele já entrou, está tudo bem.