Durante a sessão de treinamento (maio-junho e dezembro-janeiro), os usuários solicitam a verificação de empréstimos de até 500 documentos por minuto. Os documentos vêm em arquivos de vários formatos, cuja complexidade de trabalhar com cada um deles é diferente. Para verificar um documento para empréstimo, primeiro precisamos extrair o texto do arquivo e, ao mesmo tempo, lidar com a formatação. A tarefa é implementar a extração de alta qualidade de meio mil textos com formatação por minuto, enquanto cai com pouca frequência (ou melhor, não cai), consome poucos recursos e não paga metade do orçamento galáctico para o desenvolvimento e operação da ideia final.
Sim, sim, é claro, sabemos que de três coisas - de forma rápida, barata e eficiente - você precisa escolher duas. Mas o mais desagradável é que, no nosso caso, não podemos excluir nada. A questão é quão bem fizemos isso ...

Fonte da imagem: Wikipedia
Muitas vezes nos dizem que o destino das pessoas depende da qualidade do nosso trabalho. Portanto, você tem que educar em si mesmo perfeccionistas. Obviamente, estamos constantemente melhorando a qualidade do sistema (em todos os aspectos), à medida que autores inescrupulosos criam novas maneiras de contornar. E espero que esteja próximo o dia em que a complexidade do engano, por um lado, e a sensação de satisfação com um trabalho bem feito, por outro lado, levem a grande maioria dos estudantes a abandonar seu desejo amado de brincar. Ao mesmo tempo, entendemos que o preço do erro pode ser o possível sofrimento de pessoas inocentes se, de repente, fingirmos.
Por que eu estou? Se fôssemos perfeccionistas, abordaríamos cuidadosamente uma série de artigos sobre o trabalho do sistema anti-plágio . Formularíamos minuciosamente um plano de publicação para declarar tudo da maneira mais lógica e esperada para o leitor:
- Primeiro, falaríamos sobre como nosso Sistema está estruturado (a quinta publicação em Habré) e descreveríamos os três principais estágios do processamento de um documento quando ele é verificado quanto a empréstimos:
- Extraia o texto do documento (você está aqui!);
- Pesquise empréstimos (peças já estão em vários de nossos artigos );
- Construindo um relatório no documento (nos planos).
- Além disso, começaríamos a dedicar o leitor ao dispositivo de interessantes mecanismos auxiliares, como a busca por empréstimos transferíveis ( primeiro artigo ), definição de paráfrase ( quarto ) e classificação temática ( segundo ).
- E, finalmente, chegamos ao mecanismo de busca - o índice de telhas ( sétimo artigo ).
Um leitor atento deve ter notado que ainda não sofremos de perfeccionismo excessivo; portanto, é hora de avançar para o primeiro estágio - extrair texto e formatar documentos. É o que faremos hoje, pensando na mortalidade do ser e na luz no fim do túnel, na inexistência de algo ideal e na busca pela excelência, em ter um plano e segui-lo e nos compromissos aos quais a vida sempre nos inclina.
No começo era a palavra
Inicialmente, extraímos dos documentos apenas o mais necessário para a verificação dos empréstimos - o texto dos próprios documentos. Os principais formatos foram suportados - docx, doc, txt, pdf, rtf, html. Em seguida, foram adicionados os menos comuns ppt, pptx, odt, epub, fb2, djvu, no entanto, era necessário recusar-se a trabalhar com a maioria deles no futuro . Cada um deles foi processado à sua maneira - em algum lugar em uma biblioteca separada, em algum lugar em seu próprio analisador. Em média, a extração de texto durou cerca de centenas de milissegundos. Parece que a principal e quase única dificuldade na extração de texto é a "análise" do próprio formato, o que é especialmente verdadeiro para os formatos binários de pdf e doc (e a natureza proprietária deste último torna o trabalho com ele ainda mais problemático). No entanto, já nessa fase, quando nossos desejos eram limitados apenas à extração do texto, ficou claro que qualquer maneira de ler os formatos de que precisávamos traz consigo vários recursos desagradáveis. O mais significativo deles:
- As exceções são mesmo ao processar alguns documentos válidos, sem mencionar o processamento de documentos "quebrados" incorretamente formados. O que cria ainda mais problemas é que o código nativo pode cair e lidar com essas situações no código .net é difícil;
- Consumo de memória insuficientemente alto, que pode prejudicar os processos vizinhos e o atual, processando o documento “problemático” (falta de memória no código gerenciado ou não gerenciado);
- Processamento muito longo do documento, que é exacerbado pela falta de mecanismos de cancelamento para a maioria das bibliotecas e, algumas vezes, pela complexidade (leitura: quase impossibilidade) de cancelar uma chamada de código não gerenciada de uma gerenciada;
- "Extração de texto de documentos." Gerar o texto de um documento PDF (e esse formato é a chave para nós), cuja análise já foi feita, ao contrário das expectativas, é uma tarefa não trivial. O fato é que o formato pdf foi originalmente desenvolvido principalmente para a apresentação eletrônica de materiais de impressão. O texto em pdfs é um conjunto de blocos de texto localizados nas páginas de um documento. Além disso, o bloco pode ser um parágrafo de texto ou um único caractere. A tarefa de restaurar o texto em sua forma original desse conjunto de blocos é da biblioteca (código / programa) que lê o documento. Sim, o formato, começando com uma determinada versão, fornece a capacidade de especificar a ordem dos blocos, mas, infelizmente, documentos com sequência marcada de blocos de texto são bastante raros. Portanto, as bibliotecas de leitura de texto em PDF contêm várias heurísticas (bem, é padrão aqui: aprendizado de máquina,
bigdata, blockchain , ...) que permitem restaurar o texto na forma correta com um grau ou outro e, como esperado, o resultado obtido difere de biblioteca para biblioteca .

Fonte da imagem inferior: artigo
Fonte da imagem superior: Hmm ...
Precisa de mais dados!
Se, para analisar um documento para empréstimo, o fundo textual do documento foi suficiente para nós, a implementação de vários novos recursos é impossível ou muito difícil sem extrair dados adicionais do documento. Hoje, além do plano de fundo do texto, também extraímos a formatação de documentos e renderizamos imagens de página. Usamos o último para reconhecimento óptico de texto ( OCR ), bem como para identificar alguns tipos de desvios.
A formatação de um documento inclui o arranjo geométrico de todas as palavras e caracteres nas páginas, bem como o tamanho da fonte de todos os caracteres. Esta informação nos permite:
- Exiba belamente o relatório de verificação do documento, desenhando empréstimos detectados diretamente no documento original;

- Determinar os blocos de documentos (página de rosto, bibliografia ) com maior precisão e recuperar seus metadados (autores, cargo, ano e local de trabalho, etc.);
- Detectar tentativas de desvio do sistema.
Para unificar o processamento de documentos e um conjunto de dados extraídos, convertemos documentos de todos os formatos suportados por nós em pdf. Assim, o procedimento para extrair dados do documento é realizado em duas etapas:
- Converta um documento para pdf;
- Extrair dados de pdf.
Converta para pdf. Seleção da biblioteca
Como não é tão fácil pegar e converter um documento em pdf, decidimos não reinventar a roda e explorar soluções prontas, escolhendo a mais adequada para nós. Foi em 2017.
Critérios para seleção de candidatos:
- Biblioteca em .net, idealmente .net core e multiplataforma
Spoiler!Como resultado, naquele momento, o ideal era inatingível
- Suporte para os formatos necessários - doc, docx, rtf, odf, ppt, pptx
- Estabilidade
- Desempenho
- Qualidade do suporte técnico
- Preço de emissão
Analisamos as soluções disponíveis, selecionando entre elas as 6 mais adequadas para nossas tarefas:
A interoperabilidade do MS Word, o Neevia Document Converter Pro e o DynamicPdf exigem a instalação do MS Office na produção, o que poderia nos vincular de maneira definitiva e irrevogável ao Windows. Portanto, não consideramos mais essas opções.
Portanto, temos três candidatos principais restantes e apenas um deles suporta totalmente todos os formatos de que precisamos. Bem, é hora de ver do que eles são capazes.
Para testar as bibliotecas, formamos uma amostra de 120 mil documentos de usuários reais, a proporção dos formatos nos quais aproximadamente corresponde ao que vemos todos os dias na produção.
Então a primeira rodada. Vamos ver qual proporção de documentos pode ser convertida com sucesso em bibliotecas pdf em consideração. Com êxito, no nosso caso, não é lançar uma exceção, cumprir o tempo limite de 3 minutos e retornar um texto não vazio.
O Syncfusion se destacou imediatamente, que não apenas foi capaz de processar com sucesso o menor número de documentos, mas também descartou todo o processo em alguns documentos (gerando exceções como OutOfMemoryException ou exceções do código nativo que não foram capturadas sem dançar com um pandeiro).
Os GroupDocs falharam ao processar cerca de 5,5 vezes mais documentos que o DevExpress (tudo está visível na placa acima). Isso ocorre apesar de uma licença de desenvolvedor único do GroupDocs ser aproximadamente 9 vezes mais cara que uma licença de desenvolvedor único do DevExpress. A propósito, é assim.
O segundo teste sério é o tempo de conversão, os mesmos 120 mil documentos:
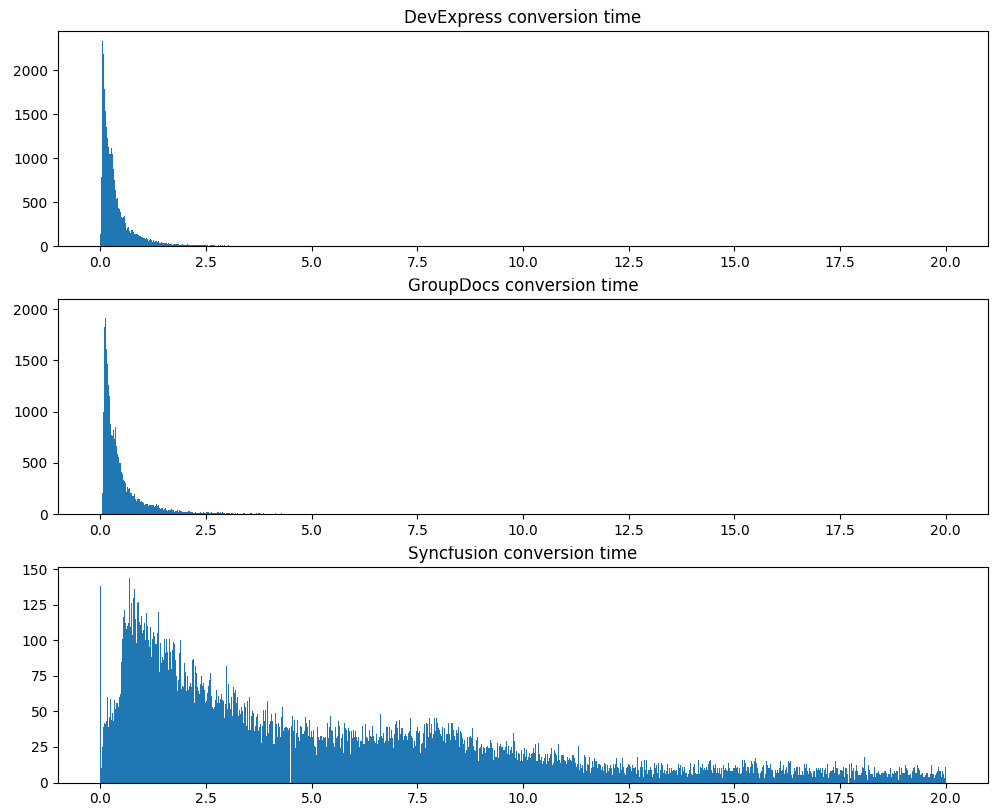
Observe que o DevExpress não apenas processa documentos mais rapidamente, em média, mas também mostra um tempo de processamento muito mais estável.
Mas estabilidade e velocidade de processamento não significam nada se a saída for ruim em pdf. Talvez o DevExpress pule metade do texto? Nós verificamos. Assim, os mesmos 120 mil documentos, desta vez, calcularemos o volume total do texto extraído e a participação média das palavras do dicionário (quanto mais palavras extraídas forem dicionário, menos lixo / texto extraído incorretamente):
Em parte, a suposição estava correta. Como se viu, os GroupDocs, diferentemente do DevExpress, podem trabalhar com notas de rodapé. O DevExpress simplesmente os ignora ao converter um documento para pdf. A propósito, sim, o texto do pdf'ok recebido em todos os casos é extraído usando o DevExpress'a.
Assim, estudamos a velocidade e a estabilidade das bibliotecas em questão, agora avaliamos cuidadosamente a qualidade da conversão de documentos em pdf. Para isso, analisaremos não apenas o volume do texto a ser extraído e a proporção de palavras do dicionário, mas compararemos os textos extraídos dos PDFs recebidos com os textos em PDF obtidos no MS Word. Aceitamos o resultado da conversão de um documento usando o MS Word como pdf de referência . Aproximadamente 4.500 pares de " documento, referência pdf'ka " foram preparados para este teste.
Para cada par “ pdf de referência, resultado da conversão ”, calculamos a semelhança no comprimento do texto extraído e nas frequências das palavras extraídas. Naturalmente, essas métricas foram obtidas apenas nos casos em que a conversão foi bem-sucedida. Portanto, não consideramos os resultados do Syncfusion aqui. O DevExpress e o GroupDocs apresentaram aproximadamente o mesmo desempenho. No lado do DevExpress, há uma porcentagem significativamente maior de conversões bem-sucedidas, no lado do GD, o trabalho correto com notas de rodapé.
Dados os resultados, a escolha foi óbvia. Até hoje, estamos usando a solução do DevExpress e em breve planejamos atualizar para a 19ª versão.
Existe um pdf, extrair texto com formatação
Assim, podemos converter documentos em pdf. Agora temos outra tarefa: usar o DevExpress para extrair o texto, sabendo sobre cada palavra todas as informações que precisamos. Ou seja:
- Em qual página está a palavra;
- A localização da palavra na página (emoldurando um retângulo);
- O tamanho da fonte da palavra (caracteres da palavra).
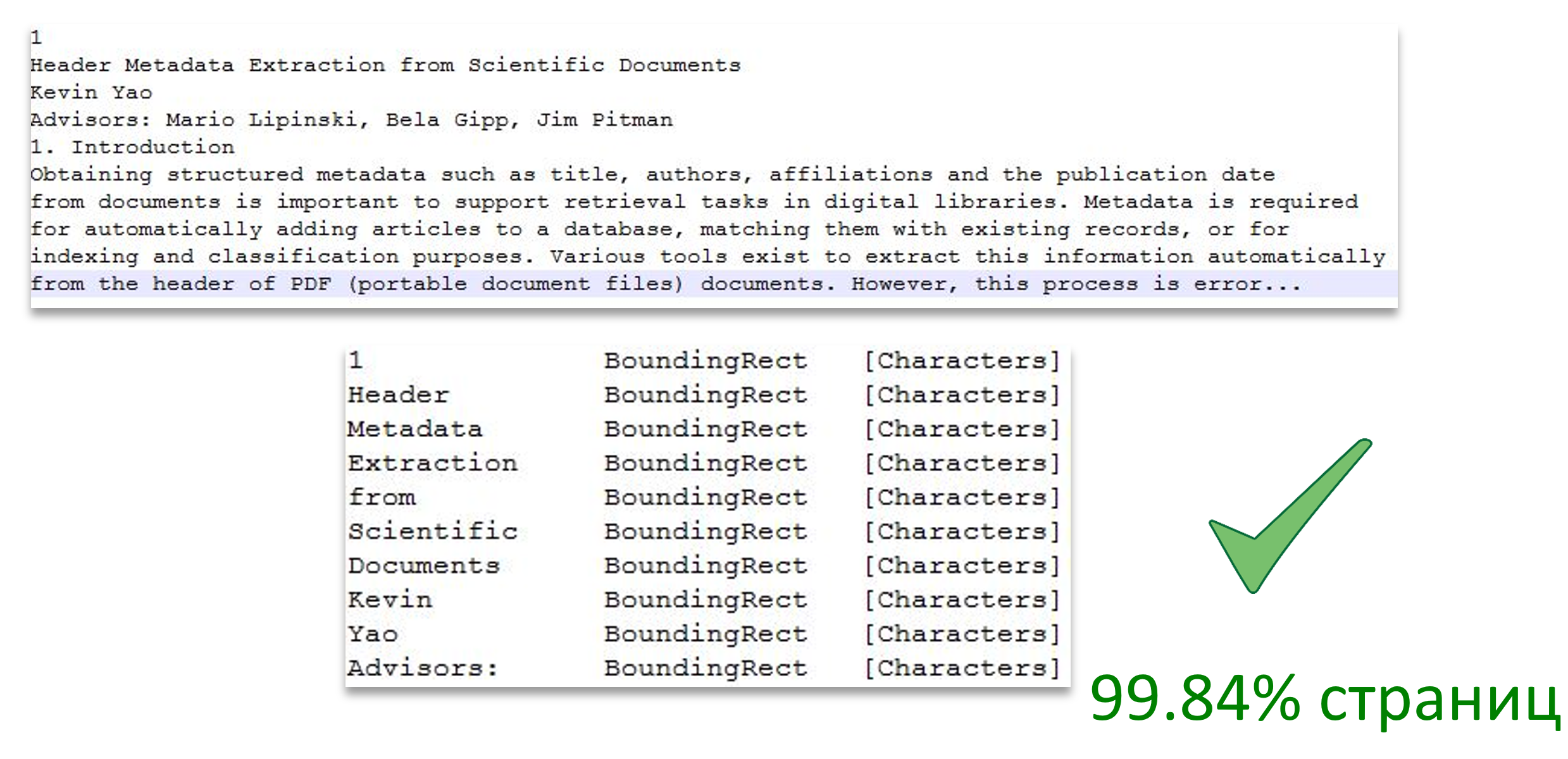
A imagem mostra a divisão do texto em páginas e também mostra a correspondência de uma palavra de texto na área da página.

Fonte da imagem: Extração de metadados de cabeçalho de documentos científicos
Parece que tudo deve ser simples. Examinamos o que a API DevExpress nos fornece:
- Temos um método que retorna o texto de todo o documento. String simples;
- Temos a capacidade de iterar de acordo com o documento. Para cada palavra, podemos obter:
- Texto da palavra;
- A página na qual a palavra está localizada;
- O retângulo de enquadramento da palavra;
- Informações sobre os caracteres individuais da palavra (o significado do caractere que enquadra o retângulo, tamanho da fonte, ...).
Ok, tudo parece estar lá. Somente aqui é como obter os dados necessários para cada palavra no texto do documento que o DevExpress retorna? Realmente não queremos coletar o texto do documento a partir de palavras, pois, por exemplo, não temos informações onde há apenas um espaço entre as palavras e onde está o feed da linha. Teremos que apresentar heurísticas com base na localização das palavras ... O texto é - aqui está, diante de nós, já montado.

Fonte da imagem: Eureka!
A solução óbvia é combinar as palavras com o texto do documento. Observamos - de fato, no texto do documento, as palavras são organizadas na mesma ordem em que são retornadas pelo iterador, de acordo com as palavras do documento.
Implementamos rapidamente um algoritmo simples para combinar palavras com o texto do documento, adicionar verificações de que tudo está correspondendo corretamente, iniciar ...
De fato, tudo funciona corretamente na grande maioria das páginas, mas, infelizmente, não em todas as páginas.

Top Image Source: Você tem certeza?
Na parte dos documentos, vemos que as palavras no texto não estão na ordem em que vão quando iteram sobre as palavras do documento. Além disso, pode-se ver que o colchete de abertura no texto na lista de palavras é representado como colchete de fechamento e está em outra “palavra”. A exibição correta desse fragmento de texto pode ser vista abrindo o documento no MS Word. Mais interessante, se você não converter o documento em pdf, mas extrair diretamente o texto do documento, obteremos a terceira versão do fragmento de texto que não corresponde à ordem correta ou às duas outras ordens recebidas da biblioteca. Nesse fragmento, como na maioria dos demais, em que surge um problema semelhante, o ponto está nos caracteres "RTL" invisíveis, que alteram a ordem dos caracteres / palavras adjacentes.
Aqui, vale lembrar que chamamos a qualidade do suporte técnico importante ao escolher uma biblioteca. Como a prática demonstrou, nesse aspecto, a interação com o DevExpress é bastante eficaz. O problema com o documento enviado foi rapidamente corrigido após a criação do ticket correspondente. Também foram corrigidos vários outros problemas relacionados a exceções / alto consumo de memória / processamento de documentos longos.
No entanto, embora o DevExpress não forneça uma maneira direta de obter o texto com as informações necessárias para cada palavra, continuamos a comparar algumas vezes incomparáveis. Se não conseguimos construir uma correspondência exata entre palavras e texto, usamos várias heurísticas que permitem pequenas permutações de palavras. Se nada ajudar, o documento permanece sem formatação. Raramente, mas isso acontece.
Tchau :)