Nos últimos 3 anos, mais de mil incidentes de diferentes graus épicos ocorreram no Contour. Os motivos são diferentes: por exemplo, 36% são causados por versões de baixa qualidade e 14% - devido à manutenção de ferro no data center. De onde vêm as estatísticas? Após cada incidente, um relatório é escrito - post mortem. Eles foram escritos pelos engenheiros de serviço que responderam à notificação do acidente e foram os primeiros a entender suas causas. Post-mortem são analisadas, identificadas e eliminadas as causas dos incidentes, para que no futuro esses incidentes não ocorram. Mas esse nem sempre foi o caso.
Alexey Kirpichnikov (
BeeVee ) programa em Yandex desde 2008. O engarrafamento, trabalhou em projetos especiais de esportes, foi o líder da equipe do back-end Yandex.Taxi. Desde 2014, ele participa do DevOps e da infraestrutura em
Kontur - ele desenvolve ferramentas que facilitam a vida dos desenvolvedores das equipes de produtos. A idéia de escrever e analisar tópicos post-mortem surgiu há cinco anos e, durante esse período, os tópicos post-mortem estavam repletos de modelos, glossário, memorandos, capturas de tela e análises. Mas isso não é o mais difícil -
foi mais difícil superar a inércia, os medos e o mal-entendido sobre o significado dos relatórios de incidentes entre os engenheiros . O que finalmente aconteceu e que benefício irreparável a "análise do sofá" pode fazer é decifrar o relatório de Alexey.
 Observe - sob as pernas da mesa de diferentes comprimentos, existem os livros "Métricas", "Testes" e "Implementar".
Observe - sob as pernas da mesa de diferentes comprimentos, existem os livros "Métricas", "Testes" e "Implementar".Em Kontur, após a contratação, eles dão um conjunto de lembranças: uma caneta, uma caneca, um caderno. Eu vim para a SKB Kontur para uma nova equipe de infraestrutura há 5 anos, quando a empresa completou 25 anos.

O contorno daqueles tempos, e agora também, é uma empresa de produtos na qual várias dezenas de produtos desenvolveram o mesmo número de equipes, independentes entre si em termos de escolha de tecnologias e ferramentas.
Naquela época, li pela primeira vez o “Projeto '' Phoenix ''” e fui inspirado pelas novas idéias das práticas de DevOps. Comecei a escrever minhas idéias para melhorias em um caderno, e agora é um artefato com manchas de café e registros históricos.
- “ Monitorando! Vamos colocar o Grafana, coletar métricas e criar gráficos. Vamos entender melhor o que está acontecendo na produção ". Para 2014, essa é uma ideia nova e relativamente nova e uma sólida prática de DevOps. ”
- " Travamento automático!" Quantos arquivos zip podem ser carregados na pasta compartilhada, descompacte-os no servidor e execute exe no agendador de tarefas do Windows? "Vamos introduzir um sistema de implantação industrial e lançar versões através dele, CI!"
- “ Post-mortem ! Se houver algum tipo de acidente na produção, vamos descobrir o que foi, descobrir o motivo, escrever um relatório e alterar nossos processos de desenvolvimento, teste e IC para que não ocorram esses incidentes no futuro ”
Por cinco anos, avançamos em todas essas áreas. Temos nosso próprio sistema de alerta
Moira , sistema de orquestração de aplicativos e várias ferramentas. Porém, de todas as opções acima,
escrever relatórios de incidentes acabou sendo a prática de engenharia mais difícil de implementar . Os engenheiros adoram todos os tipos de ferramentas - fixam algum tipo de sistema ou IC de hospedagem, escrevem algo, automatizam e não gostam de escrever relatórios, embora essa prática seja de grande utilidade.
Vou contar como implementamos os sistemas post-mortem e quais os benefícios que obtemos. Talvez o nosso rake ajude a avançar mais rápido e a encher menos cones. Antes de começar a falar sobre post-mortem, entenderemos a definição.
O que é um incidente?
Qual destes é o incidente?
- Exemplo No. 1. Em uma plataforma de blog com um milhão de usuários, como resultado de algum tipo de erro, todas as entradas de um usuário são perdidas.
- Exemplo No. 2. O serviço para funcionários do escritório funciona nos dias úteis das 9 às 6 e, outras vezes, não há usuários. O serviço ficou indisponível na noite de sábado a domingo por duas horas consecutivas, ninguém notou.
- Exemplo No. 3. A Grafana com métricas de produção caiu 15 minutos. Na produção, nada quebrou, mas os gráficos não estavam disponíveis.
Para entender o que é esse fakapy, passamos à experiência dos gurus - Google, Atlassian, PagerDuty. Os gurus sabem como preparar turnos, engenheiros de plantão e como escrever relatórios para entendê-los. Seus guias on-line têm definições de incidentes.
Definição do PagerDuty.
Um incidente é qualquer interrupção ou degradação não planejada de um serviço que afeta a disponibilidade do serviço para os usuários. Um incidente grave é aquele que requer uma resposta coordenada de várias equipes.
Parece lógico, mas a definição é vaga. Na prática, ajuda pouco a entender o que é um incidente e o que não é.
O livro
Engenharia de confiabilidade do
site do Google tem critérios claros:
- Os usuários notaram a degradação do serviço.
- Qualquer dado foi perdido.
- Foi necessária a intervenção do engenheiro de serviço, por exemplo, para reverter manualmente a liberação.
- Resolver o problema levou muito tempo. Se um problema foi resolvido em 2 horas e, em seguida, uma semana foi gasta nele - este é um incidente que requer investigação.
- O monitoramento não funcionou. Por exemplo, você aprendeu sobre um problema com os usuários.
Contour não possui uma definição publicada de fakap, mas formulamos nossos próprios critérios para determinar o que constitui um incidente.
Usuários externos ou internos notaram uma degradação do serviço . O exemplo 3 com Grafana, que estava, é um incidente claro. A produção não parou e os usuários externos não perceberam isso, mas, apesar disso, para o Contour é um fakap, pois as ferramentas internas não funcionaram.
Sorte . No exemplo nº 2, o serviço para funcionários de escritório ficava por duas horas à noite - teve sorte por cair à noite. Na próxima vez, pode ser azarado e, portanto, o incidente noturno também exige julgamento, como se tivesse acontecido durante o dia.
O incidente diz respeito a várias equipes . Tomamos essa definição do PagerDuty. A análise de um incidente é um bom motivo para várias equipes trabalharem juntas. A cultura “Da nossa parte, a bala voou, mas algo quebrou para você - a culpa é sua” é erradicada por uma análise conjunta.
Pelo menos um engenheiro considera isso um incidente . A definição mais vaga, mas também a mais importante. Uma regra simples: se o engenheiro acredita que vale a pena o relatório, então vale a pena o relatório. Se você assusta que os engenheiros começarão a escrever relatórios para qualquer pessoa e chamarem qualquer coisinha de acidente, isso não é verdade.
Engenheiros são pessoas razoáveis, confie neles.Com a definição e os diferentes tipos de danos resolvidos. Vamos passar a como se beneficiar de incidentes.
Qual é o uso do fakap?
As instruções simples que darei mais adiante, você pode se inscrever, mesmo sem passar pelo artigo até o final. Mas ainda leia até o fim.
Instrução clássica
Encontre os culpados primeiro. Em seguida, faça o trabalho “educacional” com os engenheiros.
- Peça para ter mais cuidado da próxima vez.
- Se não ajudar, envie-o para cursos de reciclagem. Talvez eles aprendam a ter mais cuidado lá.
- Se isso não ajudar, retire os autores do trabalho com partes críticas do sistema. Pare de deixar os desenvolvedores entrarem em produção se eles mexerem lá em cima.
- Se nada ajudar, demitir os maus e contratar os competentes.
Se a instrução o incomoda, são boas notícias.
Essa abordagem é considerada tradicional para empresas clássicas de orientação vertical, com um chefe que repreende a todos e pode demiti-lo. Um dos fundamentos do movimento DevOps e da ideologia DevOps é a mudança das organizações verticalmente integradas para as horizontais, com maior confiança nos funcionários.
Ilustrarei essa mudança de paradigma com
instruções de John Alspaw, um dos líderes do movimento DevOps, que anteriormente trabalhava para CTO na Etsy. A instrução foi retirada de seu artigo canônico de 2013, Blameless Post Mortem e uma cultura justa.
Pergunte aos engenheiros:
- quais eventos eles observaram;
- quando e quais ações foram tomadas;
- que resultado era esperado dessas ações;
- de que suposições vieram;
- conforme entendido pela sequência de eventos que ocorreram.
Os engenheiros precisam ser solicitados sem ameaça de punição.
Esta é a principal coisa na recomendação de John.
A ameaça de punição: reciclagem, eliminação da produção ou demissão, motiva as pessoas a mentir. E a verdade é importante para nós. Relatório de incidentes - esse é o elo de feedback muito ausente no processo de desenvolvimento e colocação de recursos em produção.
No antigo paradigma, os desenvolvedores desenvolveram, jogaram a nave por cima dos cercados para os engenheiros de operações e, de alguma forma, tentaram fazê-la funcionar. Eles ficam aborrecidos com qualquer atualização, porque ela pode quebrar tudo, e os engenheiros começaram tudo com tanta dificuldade.
O processo de feedback ajuda a mudar o processo, a infraestrutura, as ferramentas e a abordagem de desenvolvimento para que haja menos falhas na produção.
Isso convencerá os líderes de equipe e os gerentes de desenvolvimento da utilidade do post-mortem. Mas o problema é que é difícil conseguir que os engenheiros façam o que consideram inútil e inútil. Temos uma cultura de engenharia em nossa empresa e não posso simplesmente aceitar o decreto do CEO e exigir que todos escrevam post-mortem. Eu preciso convencer os engenheiros disso.
Como "vender" a idéia de engenheiros post-mortem para engenheiros? Para contornar as objeções, mostrar por que o post-mortem é legal, demonstrar o benefício dos relatórios, que isso não é apenas um cancelamento de assinatura, se apenas o chefe estiver atrasado.
Objeção No. 1: Uma vez
Este é o primeiro problema do engenheiro que desmonta o fakap - a guerra vai acabar, então conversaremos! Quando um fakap ocorre, quero corrigi-lo rapidamente, mas não quero escrever relatórios chatos e incompreensíveis e longos.
Para resolver o problema, há um truque de vida, como escrever algo certo durante um acidente. Ele foi popularizado por Artemy Lebedev:
“Existe uma maneira simples de organizar o tempo - o método“ jeepeg progressivo ”. A qualquer momento, qualquer projeto está 100% pronto, embora possa ser 4% mais desenvolvido. Dependendo do tempo disponível, o projeto pode ser elaborado até um pixel ou pode ser deixado no estágio de desenho conceitual. ”
Ilustrarei o método jeepeg progressivo usando uma figura. Em uma Internet lenta, uma imagem não é baixada imediatamente, mas em etapas.

Durante um incêndio, você não precisa escrever um relatório longo e legal. É o suficiente para você no canto superior esquerdo. Basta marcar as coisas que serão difíceis de recuperar da memória. Não tente escrever um texto literário coerente no momento em que tudo estiver danificado na produção.
Execute uma ação simples - anote a cronologia dos eventos.
Linha do tempo
A linha do tempo é muito difícil de restaurar, se não for gravada imediatamente. Um exemplo de uma gravação de um post-mortem real no circuito.
15.01.18 17:25 YEKT PrefixSearch 50 . , .
Esta é uma observação curta e simples, com registro de data e hora. De acordo com essa cronologia, mais tarde é fácil restaurar a sequência de eventos e encontrar a causa do colapso. Mas se você não gravar nada diretamente durante um incêndio, será difícil ou impossível restaurar os eventos posteriormente.
Screenshots
Uma coisa útil, especialmente ao trabalhar com um site ou aplicativo de desktop. Às vezes, a situação é difícil de descrever em palavras, e uma captura de tela é apenas um clique de uma tecla de acesso.
A primeira objeção deu certo. Gravando informações mínimas, um pequeno relatório durante o incidente não é difícil e não ocupa um tempo valioso. Quando tudo termina, ele precisa ser concluído e executado em um documento compreensível e coerente.
Objeção nº 2: Preguiça
Você não dormiu por dois dias e consertou um acidente grave, ficando fatalmente para trás em todas as tarefas que iria realizar esta semana. Mas acontece que algo mais precisa ser feito, mas o fogo já foi extinto! Neste momento, a preguiça inimaginável alcança.
Para derrotar completamente o problema não vai funcionar. Mas você pode facilitar seu trabalho com antecedência.
Padrão
Este é o primeiro e mais importante. Há um grande medo de um documento vazio que precise ser preenchido com texto significativo. É muito mais fácil se o modelo estiver preparado. Geralmente consiste de seções e perguntas nelas. Nós inserimos as respostas para as perguntas em cada seção e o modelo é preenchido.
Os modelos de relatório de incidentes são grandes. Leia sobre eles em detalhes com o guru. Todos os documentos e livros a que me refiro contêm padrões de incidentes usados pelas empresas. Em nossa experiência, posso adicionar o seguinte.
Crie um memorando com exemplos
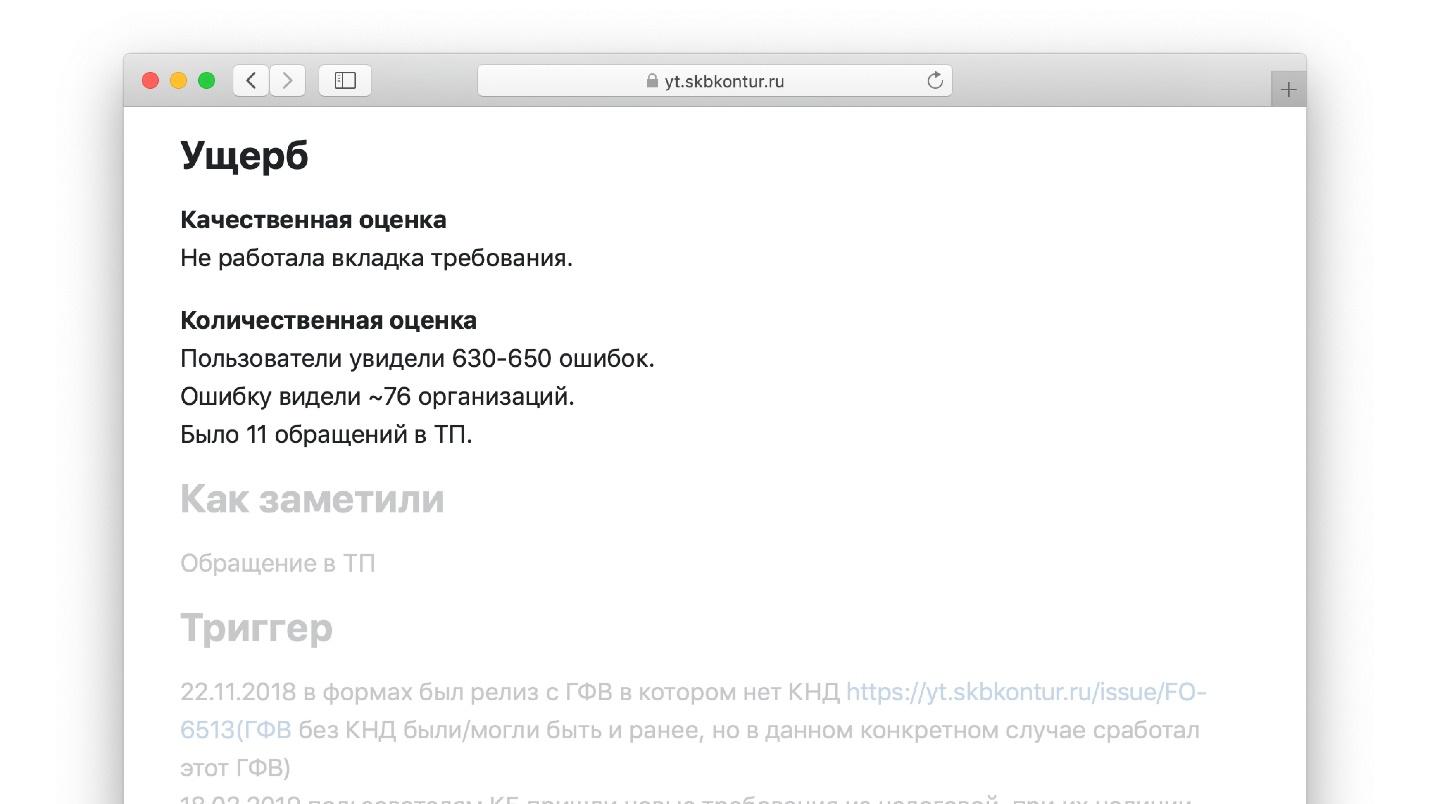
Nosso modelo possui uma seção "Dano" com subseções.
Seção "Avaliação qualitativa". Descreve o que o engenheiro vê à sua frente quando preenche esta parte do modelo:
- que funcionalidade não funcionou, por quanto tempo e para quem;
- se houve perda ou corrupção de dados.
Tendo alcançado esse lugar no modelo, o engenheiro escreve: "Há um milhão de usuários em nossa plataforma de blog, perdemos todas as entradas de um deles". Isso é muito mais fácil do que escrever um ensaio do zero, como em uma lição de literatura.
Seção "Quantificação":- quantos pedidos desapareceram;
- quanta latência cresceu nas métricas de aplicativos e aplicativos de clientes;
- quantas chamadas são perdidas;
- O tamanho da fila para suporte técnico do usuário para o problema.
Um conjunto de tais perguntas é o padrão.
Um exemplo de um dos modelos concluídos.
Adicionar glossário
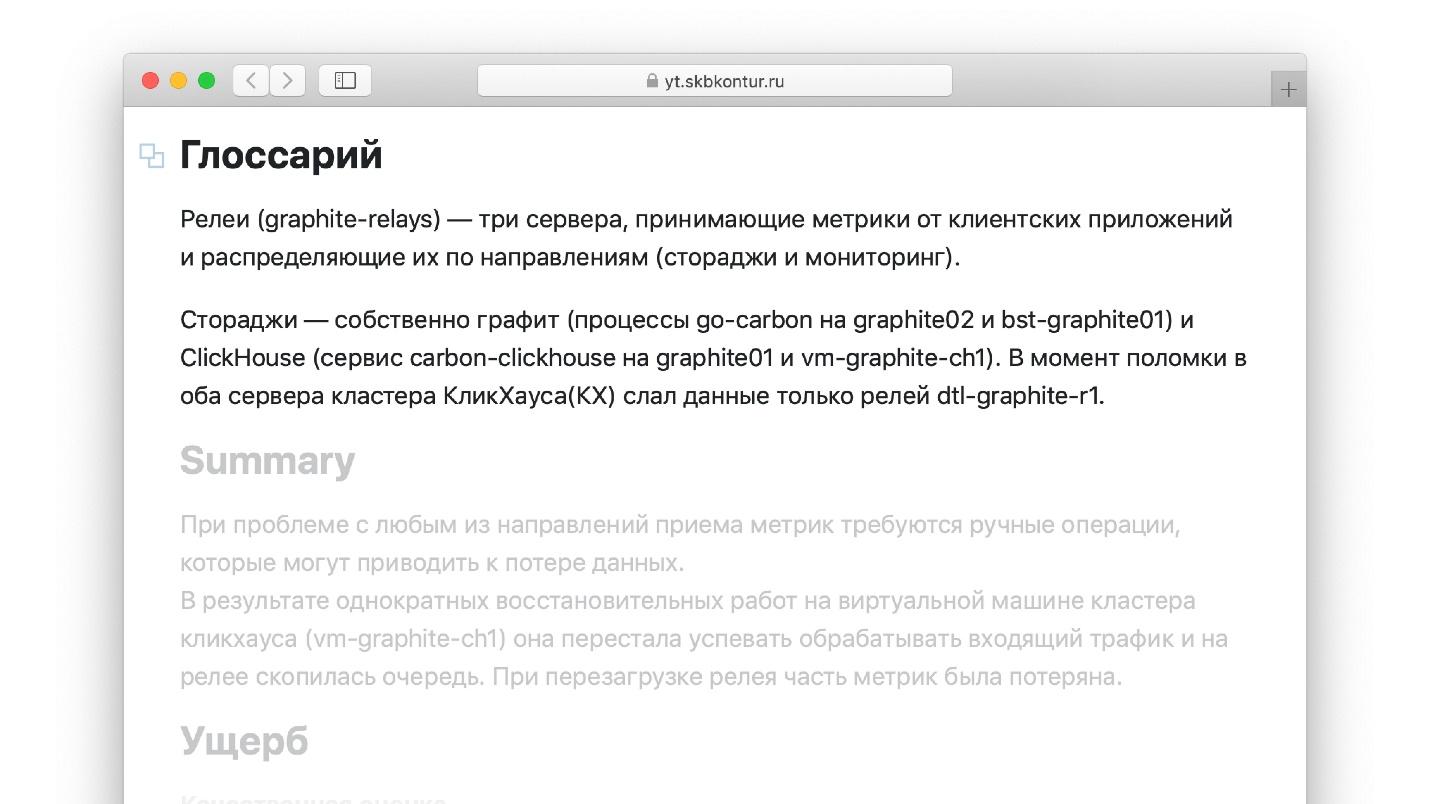
Outro truque da vida para relatórios de acidentes, que eu não vi no livro com o guru. Ao escrever um relatório, é conveniente usar termos que você conhece bem. Por exemplo, se eu trabalho com o Grafite, em que métricas são armazenadas, sei bem o que é "retransmissão". Mas o engenheiro que lerá o relatório em um ano pode não estar familiarizado com o termo. É improvável que ele consiga ler o relatório, que consiste em palavras desconhecidas. Por outro lado, se todos os termos e definições forem constantemente incluídos no relatório, a preguiça simplesmente o assusta e o relatório não será concluído.
Escreva um pequeno glossário descrevendo todos os termos usados no relatório.
Copiar todos os artefatos
Se você anexar artefatos ao relatório: capturas instantâneas no Grafana, o histórico de mensagens no bate-papo, no qual o incidente foi analisado com outros engenheiros, faça cópias. As métricas têm a capacidade de "apodrecer" e os bate-papos mudam. Há um ano, você estava no Slack, agora no Telegram - o link do bate-papo está desatualizado e não funciona, e as métricas de retenção caem - elas são armazenadas por um ano.
Copiar artefatos - esse truque de vida facilita o preenchimento de relatórios.
Objeção nº 3: ninguém lerá
A maior e incompreensível pergunta feita pelos engenheiros é: "Quem lerá esses relatórios?" Suponha que eu superei a preguiça e escrevi uma cronologia de eventos durante o acidente. Depois, reuniu forças e acrescentou um relatório de várias páginas sobre o que aconteceu e as causas do acidente. Mas se não houver um entendimento de quem lerá tudo isso e quem se beneficiará, não haverá desejo de preencher relatórios.
Post-mortem é um feedback no processo de melhoria contínua dos processos de desenvolvimento.
Em qualquer livro de guru, por exemplo, no
Atlassian Incident Handbook , está escrito que, de acordo com os resultados de cada post-mortem, é necessário:
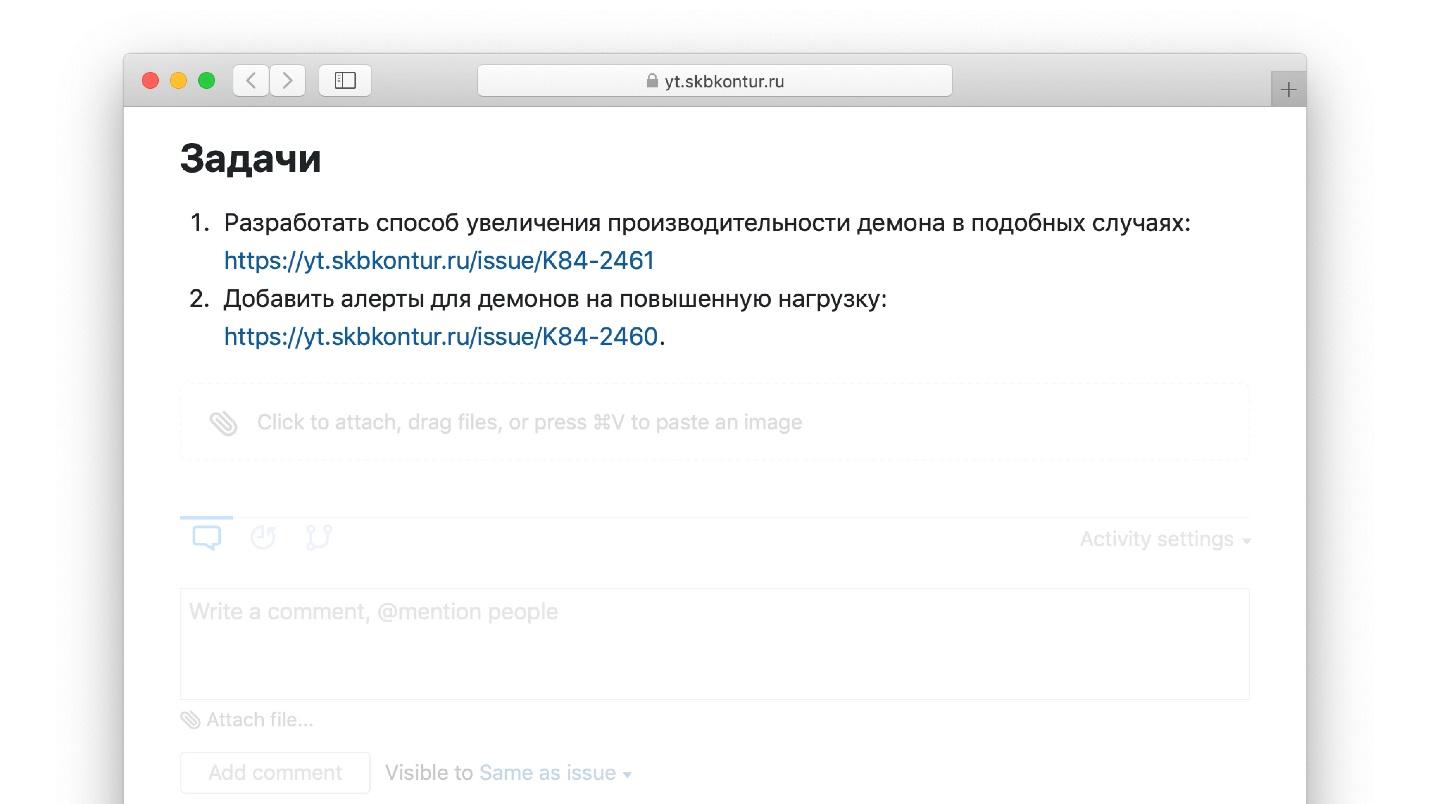
- formular tarefas em desenvolvimento;
- crie tarefas no rastreador de erros a partir do qual seus desenvolvedores as levarão;
- coloque links post-mortem para essas tarefas.
O feedback está fechado : aqui está um post-mortem, aqui nele
itens de ação - tarefas que precisam ser concluídas para que o acidente não aconteça novamente. As tarefas caem no backlog da equipe, a equipe as desenvolve, lança - novamente o fakap e post mortem. A roda do samsara se fechou.
É nisso que todos os gurus convergem. Não há o que discutir - os benefícios são óbvios.
Um exemplo de tarefas de itens de ação de um post-mortem real.
Mas nós da Kontur adicionamos um analista a isso.
Análise de sofá
Costumávamos analisar o incidente isoladamente. A falha ocorreu por conta própria em uma equipe, em um sistema de hospedagem - algo quebrou, nós corrigimos.
Mas há muitos incidentes. Nos últimos três anos, mais de 1.000 relatórios de incidentes foram acumulados no circuito. Gostaria de saber se é possível se beneficiar de toda a massa de relatórios acumulados, e não apenas de cada um individualmente. É possível, com base nisso, calcular as estatísticas do sistema e ver o que melhorar no sistema como um todo.
Uma equipe de infraestrutura especial trabalha em Kontur, que se dedica à análise post-mortem e publica os resultados e conclusões com base em toda a massa de relatórios acumulados. Chamamos isso de "análise do sofá". Darei fragmentos de um dos artigos da equipe, que é publicado em nossa rede interna para funcionários.
O que analisamos na análise de sofá?
Duração Fakap
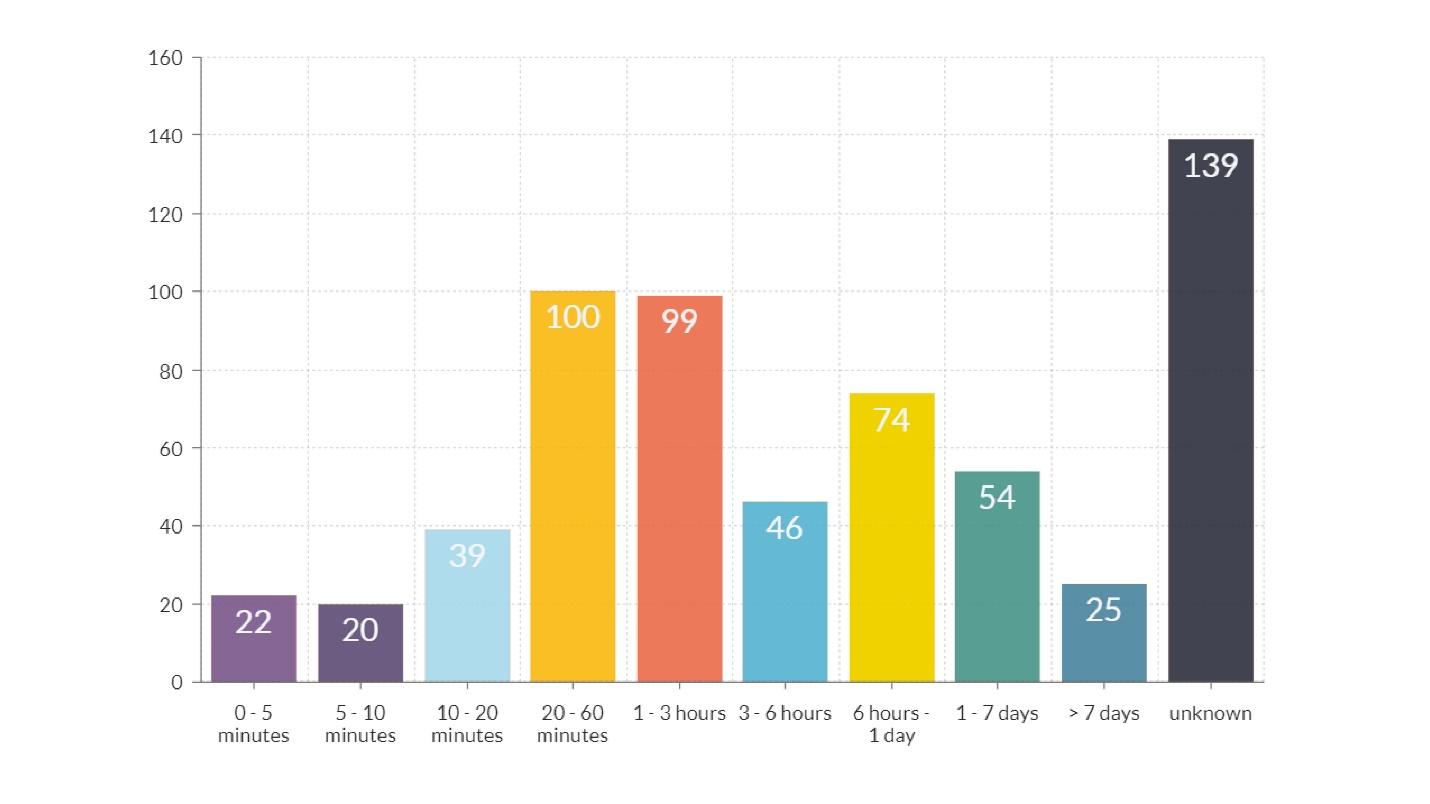 No diagrama, além da última coluna, onde o tempo é desconhecido, existem mais dois picos óbvios.Duração da ordem de uma hora
No diagrama, além da última coluna, onde o tempo é desconhecido, existem mais dois picos óbvios.Duração da ordem de uma hora - barras laranja e vermelhas. Passou a maior parte do tempo transmitindo informações sobre o que aconteceu, desde o engenheiro que percebeu o acidente até o engenheiro que sabe como corrigi-lo.
O problema é a comunicação .
Se consertarmos nossas ferramentas para que o engenheiro que resolve o problema receba as informações mais rapidamente, a duração dos fakaps e os danos deles serão bastante reduzidos. Isso é algo que não reconheceríamos olhando para qualquer fakap individualmente.
Duração cerca de 12 horas - uma coluna amarela. A explicação para o fato de que existem muitos fakaps que duram mais de 12 horas é simples: eles lançaram o lançamento à noite e pela manhã chegaram os usuários e tudo quebrou. A conclusão do que fazer para reduzir o número de fakaps é óbvia.
Dano de qualidade

O dano qualitativo é dividido em várias categorias. Os três principais incluem:
- inacessibilidade, erros;
- freios, latência aumentada;
- comportamento incorreto visível.
Segundo a análise, a grande maioria desses erros. Por um lado, são boas notícias. Três tipos dos erros mais comuns são fáceis de detectar - ajustamos as métricas à latência e ao número de erros e notamos rapidamente essas coisas.
A má notícia é que existem muitos desses erros. Esses são erros técnicos simples, o que significa que poderíamos melhorar algo nos testes de dutos, realizar mais testes de estresse e melhorar o sistema de monitoramento.
Triggers
Foi isso que levou diretamente à avaria, ou seja, não a causa raiz do acidente, mas a “gota d'água”: os troncos encheram o disco e, por isso, tudo quebrou, liberou - tudo explodiu.

Em primeiro lugar, está a "instalação de atualização". Esse motivo nos permite entender onde devemos investir como equipe de infraestrutura. Por exemplo, para melhorar o sistema de implantação e introduzir uma implantação canária. Este é o ponto de esforço que terá o maior impacto na qualidade de nossos sistemas.
Esse é o objetivo de todas as análises - entender onde uma pequena equipe de infraestrutura deve investir agora nas condições de recursos limitados.
O que melhorar - alerta ou implantação? O que fazer - hospedagem ou a beleza dos gráficos?
Aqui está outro bom insight. Em segundo lugar, “a causa é desconhecida”. Este é um indicador de relatórios ruins de relatórios de incidentes.
Possíveis "pílulas"
Isso permite uma solução técnica simples para reduzir o número de acidentes de um determinado tipo. Por exemplo, sabemos que as coisas mais importantes que reduzem o número de fakaps são as notificações do sistema de monitoramento. Se houvesse mais alertas no monitoramento desses eventos, quantos incidentes poderíamos impedir? Porcentagem indica quanto:
- no número de erros de HTTP do cliente - 10%;
- na aparência de novos tipos de erros nos logs: instalação, configurações de notificação - 8%;
- nos recursos do sistema: CPU, memória, disco, threads, GC - 6%.
Se o alerta fosse configurado corretamente e o engenheiro desejado recebesse uma notificação no prazo, 24% dos incidentes não ocorreriam ou teriam uma duração muito menor. Esta conclusão pode ser feita com base na análise de toda a massa de incidentes.
Aqui vou anunciar novamente nosso sistema de alerta
Moira , que está localizado em código aberto.
Se você possui grafite, pode fazer o download e usá-lo. Espero que haja menos incidentes.
Recomendações
Recomendações organizacionais que a equipe pode seguir e também reduzir o número de acidentes. Nosso top 3.
- A semelhança dos sites de teste e combate . 5% dos incidentes ocorreram devido ao fato de o local do teste não ser suficientemente semelhante ao do combate.
- Compatibilidade com versões anteriores em liberações . O lançamento foi deflacionado, não era compatível com o anterior, surgiram migrações de dados - 4% dos erros.
- Recusa de lançamentos noturnos . Se você parar de espalhar lançamentos que quebram, à noite, outros 4% dos incidentes desaparecerão.
Enfatizo que isso não é uma instrução, mas uma história sobre como coletamos análises. Suas análises podem ser diferentes.
Como escrever
Se você perceber que a análise de incidentes é uma coisa interessante e precisar escrever relatórios, eu mostrarei como fazê-lo.
Publicar post-mortem e tarefas em um rastreador de erros
No rastreador de erros, ao contrário do Google Docs ou Wiki, existem campos fixos para os quais você pode definir um conjunto de valores. Isso facilita a análise das estatísticas gráficas posteriormente.
No livro do SRE, o Google fornece um modelo no Google Docs, no qual eles escrevem relatórios em seus documentos internos. Não consigo imaginar como podemos coletar as análises que coletamos de documentos não estruturados do Google.
Escrevemos relatórios no mesmo rastreador de erros que as principais tarefas, porque podemos conectar a tarefa ao post-mortem. Vamos dar uma olhada no post-mortem e ver imediatamente quais tarefas estão fechadas, quais não estão e quais estão por fazer.
Crie campos especiais
Eu já falei sobre campos especiais. Nós temos o seguinte.
- O início e o fim do fakap podem ser analisados automaticamente. Se você colocar carimbos de data e hora legíveis por máquina, poderá plotar a duração do fakap.
- O início e o fim da investigação.
- Gatilho Configure uma lista suspensa de gatilhos, é mais conveniente.
- Como observado.
- Danos quantitativos e qualitativos.
- Equipes e serviços afetados.
Todos os dados de campos especiais permitem entender como sua infraestrutura funciona.
Um exemplo de nosso relatório completo de incidentes.

Os campos da coluna da direita são apenas preenchidos através da seleção nas listas suspensas.
Reúna uma equipe de engenheiros que se preocupam com a qualidade
Para obter relatórios que ajudarão você a entender como desenvolver sua infraestrutura, você precisará de pessoas que se preocupem com a qualidade de seus serviços. Não necessariamente serão os engenheiros envolvidos na análise em tempo integral apenas post-mortem. É importante que essas pessoas estejam muito preocupadas com o que está acontecendo. De tempos em tempos eles se reúnem, analisam toda a massa de incidentes, escrevem grandes artigos e trazem benefícios - feche o círculo de feedback.
Nossa equipe se chama Q-team - da palavra "Quality". Possui 3 pessoas - um dos engenheiros mais talentosos da empresa que trabalha em infraestrutura.
Total
Leia o guru - os artigos de John Allspaw e os livros de gerenciamento de incidentes:
Engenharia de Confiabilidade do Site ,
Processo PagerDuty Post-Mortem ,
Atlassian Incident Handbook .
E quando você vier trabalhar amanhã,
dê os primeiros passos :
- iniciar um projeto para fakaps no bugtracker no qual você realiza tarefas;
- use qualquer modelo - não tente escrever o seu, use o nosso ou no Google no SRE;
- quando algo explodir, basta escrever.
Nesse momento em que você escreve o primeiro, o segundo e o terceiro relatórios, você não terá uma análise bonita com colunas multicoloridas. Mas, depois de um ano ou dois, quando os dados foram acumulados, você olha para trás e agradece a si mesmo pela primeira etapa.
Esperamos que você se lembre e agradeça a Alexei pela história dessa experiência. E, por sua vez, tentaremos coletar novos relatórios úteis no programa DevOpsConf , recomendações das quais você pode aplicar. A conferência será realizada de 30 a 1 de setembro de 2019 , até 20 de agosto, ainda estamos aguardando inscrições dos apoiadores do DevOps, mas 12 já foram aprovadas, ou seja, a competição será mais próxima do prazo.
Se você deseja compartilhar sua experiência, decida-se e envie seus resumos . Se você deseja receber notícias do programa, assine nosso canal de boletim e telegrama .