No final de junho, uma equipe da Universidade Carnegie Mellon nos mostrou a XLNet, disponibilizando imediatamente a
publicação , o
código e o modelo finalizado (
XLNet-Large , Cased: 24 camadas, 1024 oculto, 16 cabeças). Este é um modelo pré-treinado para resolver vários problemas do processamento de linguagem natural.
Na publicação, eles imediatamente indicaram uma comparação de seu modelo com o
BERT do Google. Eles escrevem que o XLNet é superior ao BERT em um grande número de tarefas. E mostra resultados em 18 tarefas de última geração.
BERT, XLNet e transformadores
Uma das tendências recentes da aprendizagem profunda é a aprendizagem por transferência. Nós treinamos modelos para resolver problemas simples em uma enorme quantidade de dados e depois usamos esses modelos pré-treinados, mas para resolver outros problemas mais específicos. O BERT e o XLNet são exatamente essas redes pré-treinadas que podem ser usadas para resolver problemas de processamento de linguagem natural.
Esses modelos desenvolvem a idéia de
transformadores - a abordagem atualmente dominante na construção de modelos para trabalhar com sequências. Muito detalhado e com exemplos de código em transformadores e o mecanismo de Atenção estão escritos em
The Annotated Transformer .
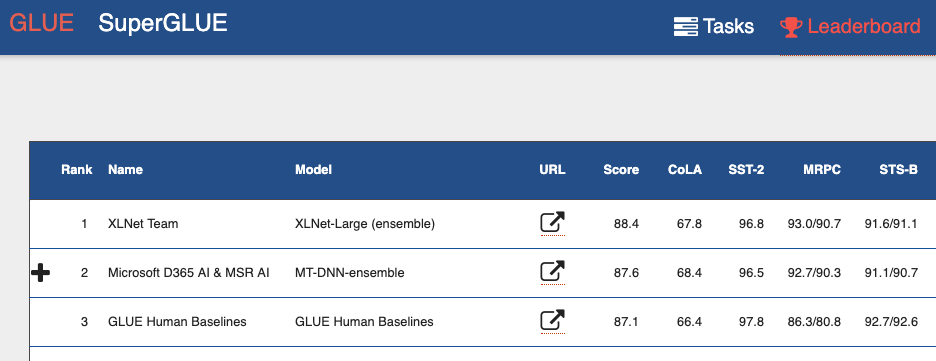
Se você olhar para o
Quadro de Referência do benchmark Avaliação de Entendimento de Idioma Geral (GLUE) , poderá ver de cima muitos modelos baseados em transformadores. Incluindo os dois modelos que mostram melhores resultados que os humanos. Podemos dizer que, com os transformadores, estamos testemunhando uma mini-revolução no processamento da linguagem natural.
Desvantagens do BERT
O BERT é um codificador automático (autoencoder, AE). Ele esconde e estraga algumas palavras na sequência e tenta restaurar a sequência original de palavras do contexto.
Isso leva a desvantagens do modelo:
- Cada palavra oculta é prevista individualmente. Perdemos informações sobre os possíveis relacionamentos entre palavras mascaradas. O artigo fornece um exemplo chamado "Nova York". Se tentarmos prever independentemente essas palavras no contexto, não levaremos em consideração o relacionamento entre elas.
- Inconsistência entre as fases de treinamento do modelo BERT e o uso do modelo pré-treinado BERT. Quando treinamos o modelo - temos palavras ocultas (tokens [MASK]), quando usamos o modelo pré-treinado, já não fornecemos esses tokens para a entrada.
E, no entanto, apesar desses problemas, o BERT mostrou resultados de ponta em muitas tarefas de processamento de linguagem natural.
Recursos XLNet
XLNet é uma modelagem de linguagem autoregressiva, AR LM. Ela está tentando prever o próximo token a partir da sequência dos anteriores. Nos modelos autoregressivos clássicos, essa sequência contextual é tomada independentemente de duas direções da sequência original.
A XLNet generaliza esse método e forma o contexto de diferentes locais na sequência de origem. Como ele faz isso? Ele pega todas as permutações possíveis (em teoria) da sequência original e prediz cada token na sequência das anteriores.
Aqui está um exemplo do artigo de como o token x3 de várias permutações da sequência original é previsto.
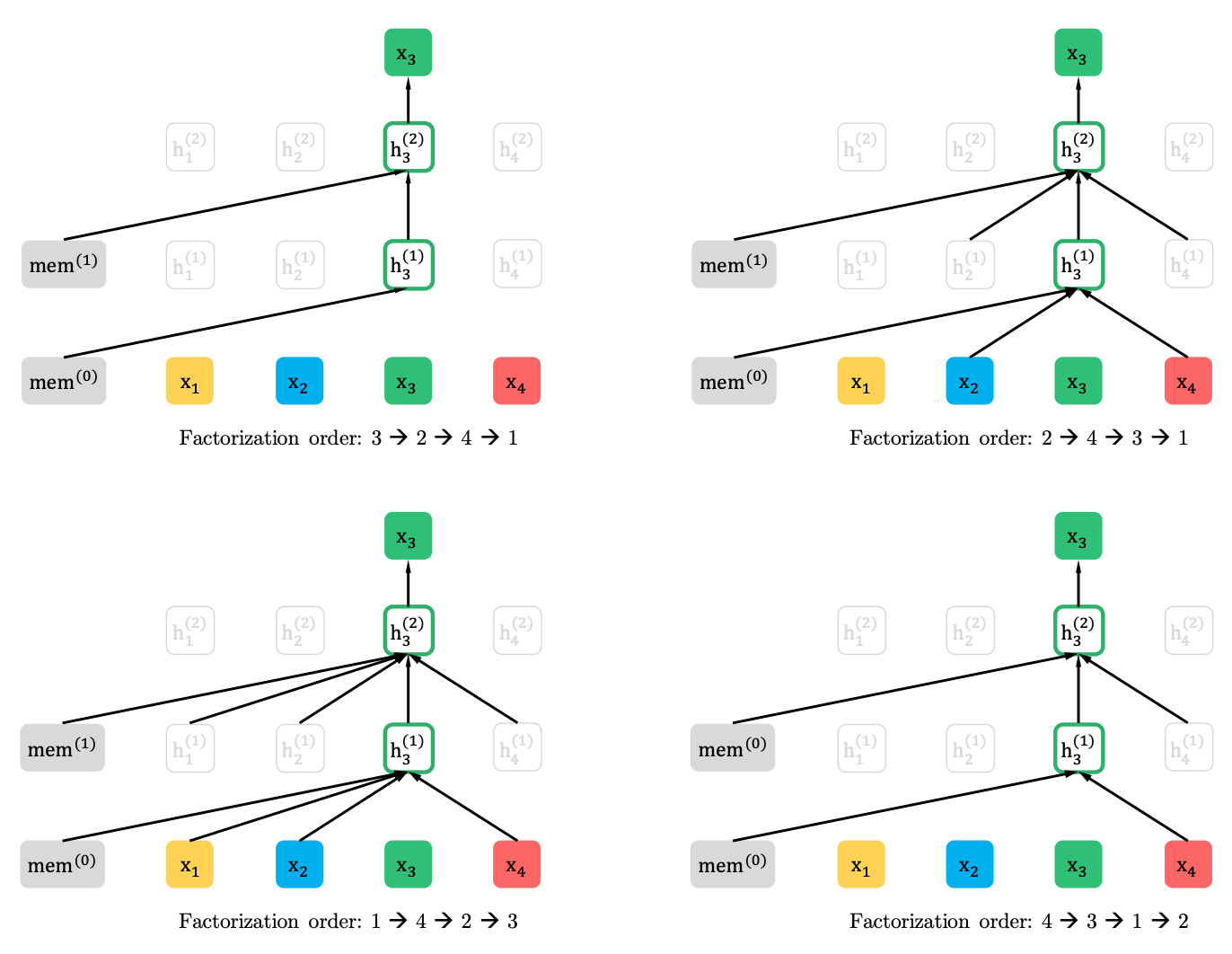
Além disso, o contexto não é um saco de palavras. Informações sobre o pedido inicial de tokens também são fornecidas ao modelo.
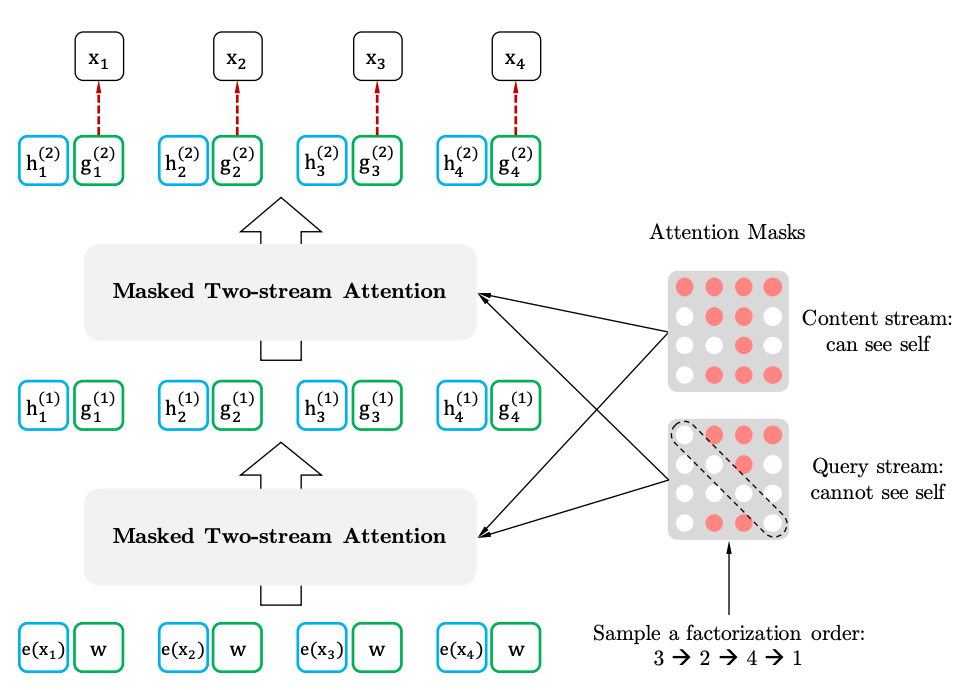
Se traçarmos analogias com o BERT, verifica-se que não ocultamos os tokens antecipadamente, mas usamos diferentes conjuntos de tokens ocultos para diferentes permutações. Ao mesmo tempo, o segundo problema do BERT desaparece - a falta de tokens ocultos ao usar o modelo pré-treinado. No caso do XLNet, a sequência inteira, sem máscaras, já está inserida.
De onde vem o XL no nome. XL - porque o XLNet usa o mecanismo de atenção e as idéias do modelo Transformer-XL. Embora as linguagens malignas afirmem que o XL sugere a quantidade de recursos necessários para treinar a rede.
E sobre os recursos. No Twitter, eles publicaram o
cálculo do custo da formação da rede com os parâmetros do artigo. Foram 245.000 dólares. É verdade que um engenheiro do Google veio e
corrigiu que o artigo menciona 512 chips de TPU, quatro dos quais estão no dispositivo. Ou seja, o custo já é de 62.440 dólares, ou mesmo 32.720 dólares, dados os 512 núcleos, também mencionados no artigo.
XLNet vs BERT
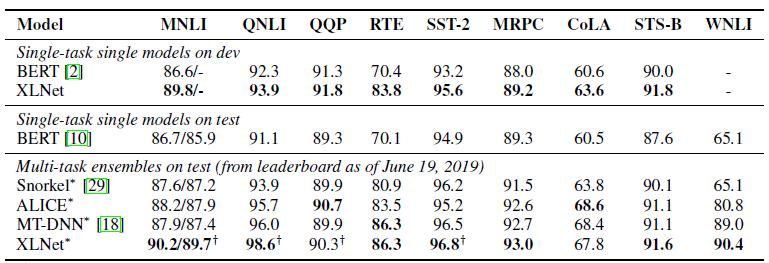
Até agora, apenas um modelo pré-treinado para inglês foi apresentado para o artigo (XLNet-Large, Cased). Mas o artigo também menciona experimentos com modelos menores. E em muitas tarefas, os modelos XLNet mostram melhores resultados em comparação com modelos BERT semelhantes.
O advento do BERT e, especialmente, dos modelos pré-treinados, atraiu muita atenção dos pesquisadores e levou a um grande número de trabalhos relacionados. Agora aqui é XLNet. É interessante ver se, por algum tempo, se tornará o padrão de fato na PNL, ou vice-versa, estimulará os pesquisadores na busca de novas arquiteturas e abordagens para o processamento de linguagem natural.