Olá pessoal. Neste artigo, falarei sobre nossa experiência em participar do concurso de análise de dados
Data Mining Cup 2019 (DMC) e como conseguimos entrar nas equipes do TOP 10 e participar das finais do campeonato em tempo integral em Berlim.

Vou narrar em nome da nossa equipe, na qual participo (Alexander Perevalov), bem como do meu colega Sergey Bobkov. Somos estudantes de graduação da
Universidade Politécnica de Perm ; em nosso tempo livre do trabalho e estudo, estamos envolvidos na solução de concursos de ciência de dados.
O que é DMC e como descobrimos isso
A Data Mining Cup é um campeonato global de análise de dados de estudantes realizado uma vez por ano. Sua história começou há 20 anos, muito antes do
Kaggle , pode-se dizer que o
DMC realizou competições de análise de dados antes de se tornar mainstream .
O DMC é
hospedado pela empresa alemã
PrudSys , uma empresa de
inteligência de varejo . Anteriormente, apenas a participação de uma mão era permitida no campeonato, então os participantes podiam se unir em equipes da universidade, a propósito, o número máximo de equipes da universidade é de apenas 2. A participação na universidade também é estritamente controlada, para a participação é necessário ter um e-mail com o domínio do seu aluno instituições, além de enviar uma cópia do seu cartão de estudante.
Hoje, se compararmos o nível de participantes no DMC e no Kaggle, é claro, o nível do Kaggle é muito maior. Isso se deve à restrição de estudantes no DMC e à popularidade do Kaggle. Uma característica distintiva do DMC é a
ausência de uma tabela de classificação , que elimina os problemas de ajustá-la.
Aprendi sobre a Data Mining Cup no momento em que fomos a um grupo de nossa universidade para um estágio na Alemanha. Ao chegar em casa, meu amigo e colega de equipe me convidou para participar, em meados de abril. Honestamente, fiquei cético em relação a essa idéia, no entanto, tendo aprendido que este ano os dados e a tarefa são bastante simples - ainda começamos a resolvê-los.
Como resolvemos a tarefa
Em 2019, a tarefa estava no campo de detecção de fraude com auto-pagamento. Certamente você já se deparou com caixas de autoatendimento em supermercados. Esses dispositivos funcionam sob a supervisão de um funcionário da loja e de forma totalmente automática. As caixas registradoras de autoatendimento permitem otimizar os custos com pessoal e minimizar as filas nos supermercados. No entanto, há um problema: a natureza humana é tal que, de uma maneira ou de outra, existe o desejo de "não romper" os bens que queremos ver em nossa geladeira. Para evitar isso, o controle é necessário, mas de forma a não embaraçar ou incomodar os clientes.
Assim, com base nos dados marcados nas transações de auto-checkout, é necessário desenvolver um modelo matemático que classifique automaticamente uma transação específica como fraudulenta ou não fraudulenta. Então, resolvemos o problema de classificação binária.
Os dados foram os seguintes:

O tamanho da amostra de treinamento foi de apenas ~ 1800 exemplos, enquanto a amostra de teste foi de 499000 exemplos. Além disso, a
amostra de treinamento
não foi equilibrada : apenas 4% das transações foram fraudulentas, é óbvio que a
precisão (a parcela de respostas corretas) é inútil aqui. Surpreendentemente, não havia valores ausentes nos dados e alguns dos atributos foram distribuídos igualmente. Com base nisso, podemos concluir que os
dados são gerados artificialmente.Além disso, os organizadores propuseram sua métrica na forma de uma Matriz de Confusão, medida em unidades monetárias:
Depois de analisá-lo, ficou claro para nós que a precisão é mais importante nesse caso, porque
arcaremos com a perda máxima se, por engano, chamarmos um comprador honesto de fraudador.O curso de nossa solução consistiu em estágios clássicos:
- Análise básica de dados
- Análise de sinais, suas estatísticas descritivas e distribuições
- Remoção de outlier
- Geração de Personagem
- Construindo um modelo e definindo parâmetros
- Validação e Previsão Final
Os slides com o conteúdo de nossa solução podem ser encontrados em:
www.docdroid.net/2XEDfYg/dmc-2019-1.pdfO repositório no GitHub está aqui:
github.com/Perevalov/dmc2019 (tudo está espalhado em diferentes ramificações, até que houve tempo para colocar tudo em ordem)
Finais Organizacionais
Depois que enviamos a decisão final no início de maio, começamos a esperar resultados. As condições dos organizadores são tais que as
10 principais equipes são convidadas para uma final presencial em Berlim , realizada como parte da conferência de inteligência de varejo 2019: Decisões inteligentes para o varejo inteligente.
Para referência,
em 2019, 149 equipes de 114 universidades localizadas em 28 países participaram do DMC.Para ser sincero, nem esperávamos chegar à final , mas agora, no final de maio, chega a querida carta convite. Além disso, todos os finalistas foram solicitados a pagar despesas de até 500 Euros e também ofereceram hospedagem em um hotel por uma noite, onde o evento foi realizado.
Sem hesitar, compramos ingressos para Berlim e fomos buscar vistos. Sendo estudantes pobres, o montante de despesas para uma viagem de 2 dias acabou por ser bastante grande para nós. Os custos dos bilhetes e do processamento de vistos Perm-Berlin-Perm eram de cerca de 40.000 rublos. por pessoa, isso é um pouco mais de 500 euros.
Como representamos nossa universidade no evento, decidimos obter apoio material dela. Além disso, a Universidade Politécnica de Perm implementa um programa para o desenvolvimento das relações russo-alemãs e apoia fortemente os estudantes da iniciativa (pareceu-nos isso). Com a aprovação e assinatura do chefe do departamento em que estudamos, fomos ao departamento de ciência e inovação. Começou um épico burocrático de um mês, que terminou com o seguinte:
"Não há dinheiro, mas você aguenta" . Claro que estávamos um pouco chateados, mas não desanimamos. Agora, é ridículo ler várias declarações da alta administração de nossa universidade sobre a "necessidade de apoiar jovens cientistas" e outras bobagens. Bem, é uma digressão.
Temos vistos em apenas 2 semanas. Durante o mesmo período, preparamos um relatório para o discurso e, em 2 de julho à noite, fomos ao aeroporto.
Desempenho na final da Copa de Mineração de Dados e premiação
Chegando a Berlim no dia 3 de julho pela manhã, fomos ao nHow Hotel, onde a conferência foi realizada. O nível de organização, é claro, é alto. De fato, o custo da participação foi de 1000 euros por pessoa (para nós é grátis). E é assim que o hotel se parece:

Nossa apresentação estava marcada para as 16:30. Ocorreu na sala principal de conferências, naturalmente em inglês. A propósito, o desempenho em si não foi levado em consideração na classificação final, foi calculado apenas com base na taxa final, sobre a qual apenas os organizadores tinham dados.
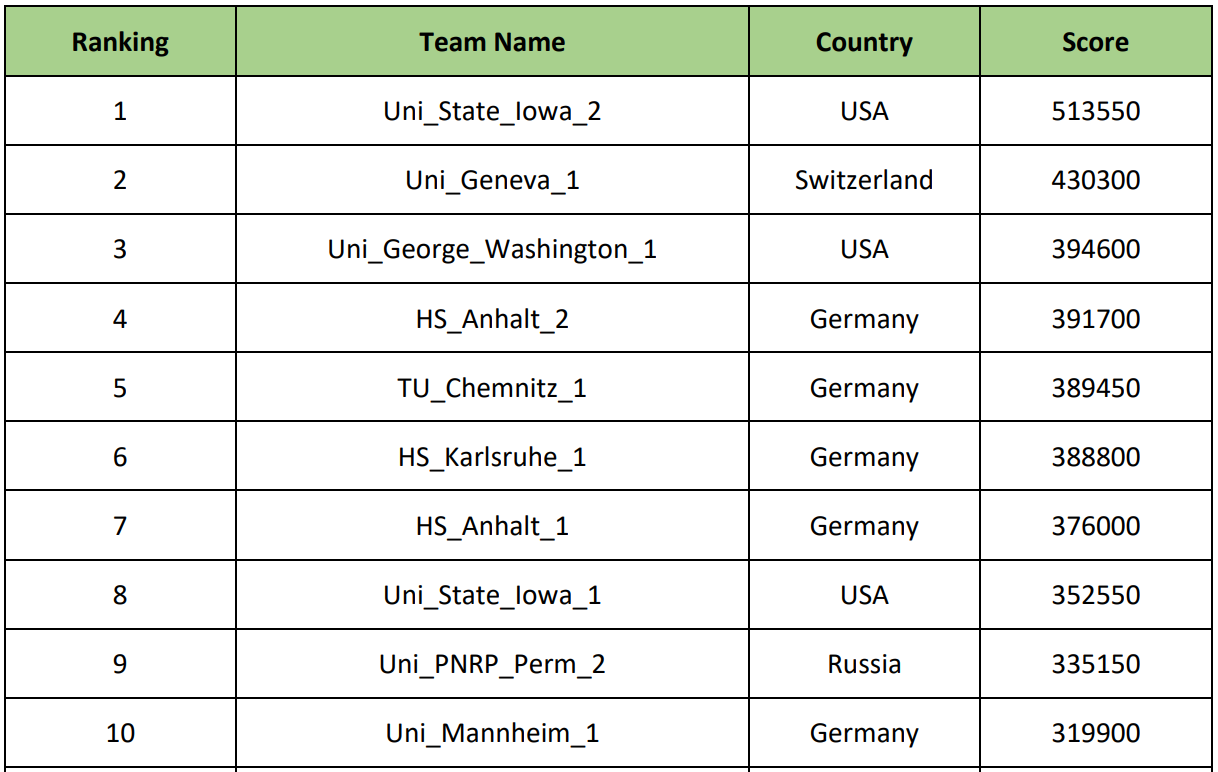
Entre as dez primeiras equipes, havia universidades como: Universidade George Washington (EUA), Universidade de Genebra (Suíça), Universidade Tecnológica de Chemnitz (Alemanha), Universidade de Iowa (EUA), etc. E, claro, nossa Universidade Politécnica de Pesquisa Nacional de Perm.
Era assim que a sala de conferências era:

Um pequeno embaraço foi o fato de eu ter que falar não com slides, mas com um pôster exibido na tela. Portanto, o desempenho dos participantes não foi suficientemente informativo. No entanto, houve uma oportunidade de abordar e visualizar o pôster em papel de cada um dos participantes na sala de conferências. Basicamente, a maioria das pessoas usava
empilhamento, mesclagem e montagem (também estamos entre eles); alguns participantes usavam um
limite aumentado para modelos de classificação; algumas equipes conseguiram não gerar recursos e construíram o modelo na fonte.
A propósito, nós éramos a menor equipe - apenas 2 pessoas.
Após as apresentações, começou um jantar de gala e gratificante. Nós esperávamos por prêmios, mas percebemos que isso era improvável, então nosso desejo mundano era "pelo menos não ter 10 anos". Acabou exatamente como queríamos - ocupamos o honroso 9º lugar. Naturalmente, foi um pouco chato, mas o fato de estarmos na final entre universidades tão sérias já diz muito. Os vencedores foram participantes da Universidade de Iowa (EUA), embora você não possa dizer que eles vieram dos estados (veja a foto):
 Os prêmios para o 1º, 2º e 3º lugares foram de 2.000, 1.000 e 500 euros, respectivamente.
Os prêmios para o 1º, 2º e 3º lugares foram de 2.000, 1.000 e 500 euros, respectivamente. A classificação final é a seguinte:
Conclusões
Não lamentamos o quanto participamos dessa competição. No mínimo, essa é uma conquista de +1 no portfólio, nos contatos mais úteis com pessoas e na oportunidade de representar nossa cidade e país em um evento internacional.
Aconselho todos os cientistas a participarem desses eventos, é legal!