1. Introdução
Há algum tempo, eu precisava resolver o problema de segmentar pontos em uma nuvem de pontos (nuvens de pontos são dados obtidos de lidares).
Dados de exemplo e a tarefa a ser resolvida:
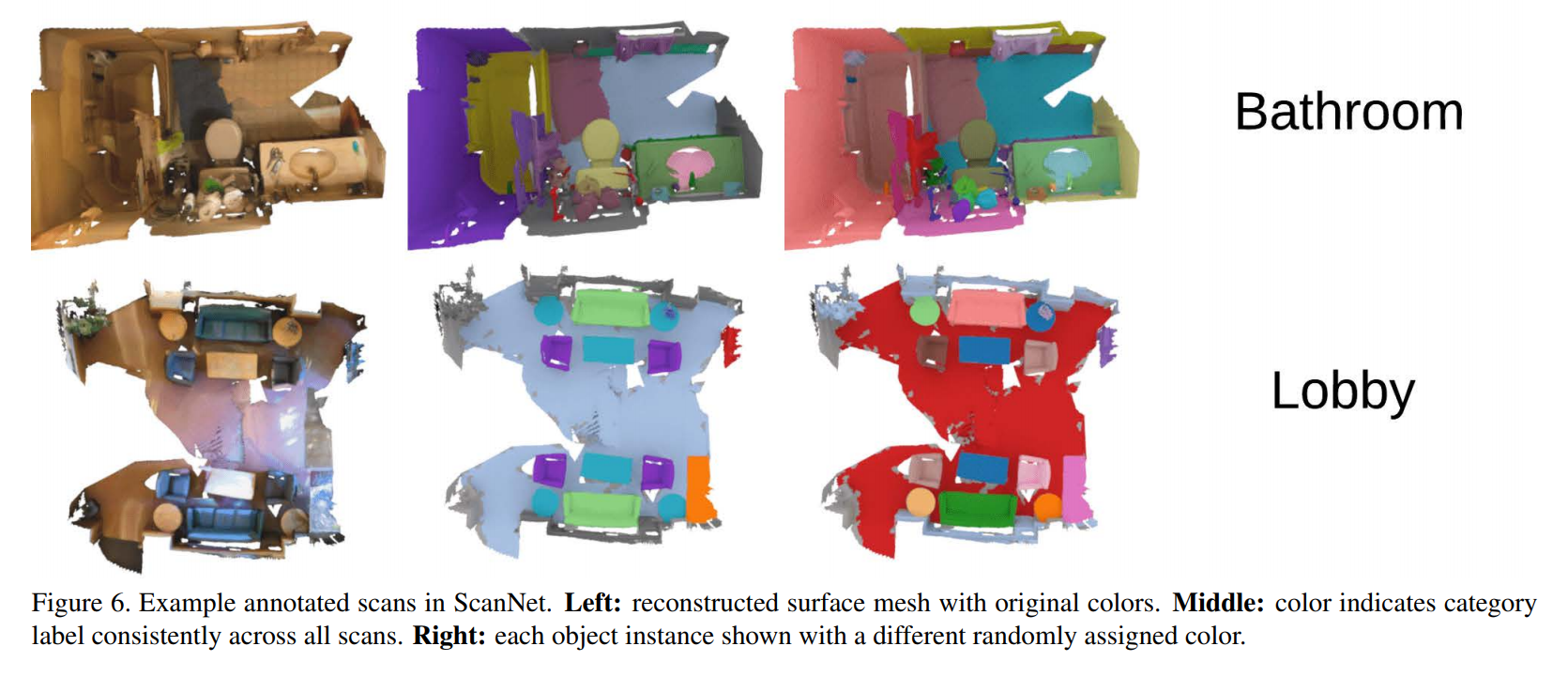
A busca por uma visão geral dos métodos existentes não teve êxito e, por isso, eu mesmo tive que coletar informações. Você pode ver o resultado: aqui são coletados os artigos mais importantes e interessantes (na minha opinião) nos últimos anos. Todos os modelos considerados resolvem o problema de segmentar uma nuvem de pontos (a qual classe cada ponto pertence).
Este artigo será útil para aqueles que estão familiarizados com redes neurais e desejam entender como aplicá-las a dados não estruturados (por exemplo, gráficos).
Conjuntos de dados existentes
Agora, no domínio público, existem os seguintes conjuntos de dados sobre este tópico:
Recursos do trabalho com nuvens de pontos
As redes neurais chegaram a essa área recentemente. E arquiteturas padrão, como redes totalmente conectadas e convolucionais, não são aplicáveis para resolver esse problema. Porque
Porque a ordem dos pontos não é importante aqui. Um objeto é um conjunto de pontos e não importa em que ordem eles são visualizados. Se cada pixel tem seu lugar na imagem, podemos misturar os pontos com segurança e o objeto não muda. O desempenho de redes neurais padrão, em contraste, depende da localização dos dados. Se você misturar pixels na imagem, obterá um novo objeto.
Agora vamos ver como as redes neurais se adaptaram para resolver esse problema.
Artigos Mais Importantes
Não há muitas arquiteturas básicas nessa área. Se você pretende trabalhar com gráficos ou dados não estruturados, precisa ter uma idéia dos seguintes modelos:
Vamos considerá-los com mais detalhes.
- PointNet: Deep Learning sobre conjuntos de pontos para classificação e segmentação 3D
Pioneiros no trabalho com dados não estruturados.
- como eles decidem: O artigo descreve dois modelos: para segmentação de pontos e classificação de um objeto. A parte geral consiste nos seguintes blocos:
- uma rede para determinar a transformação (tradução do sistema de coordenadas), que então se aplica a todos os pontos
- transformação aplicada a cada ponto individualmente (perceptor regular)
- maxpool, que combina informações de diferentes pontos e cria um vetor de recurso global para todo o objeto.
- então as diferenças entre os modelos começam:
- modelo de classificação: um vetor de recurso global vai para a entrada de uma camada totalmente conectada para determinar a classe de toda a nuvem de pontos
- modelo de segmentação: o vetor de recurso global e os recursos calculados para cada ponto vão para a entrada da camada totalmente conectada que define a classe para cada ponto.
- código



Artigos baseados em PointNet e PointNet ++:
A maioria dos artigos difere em termos de contagem de erros ou profundidade e complexidade de blocos complexos.
PointWise: uma rede de aprendizado de recursos pontuais e não supervisionados
Característica do trabalho - treinamento sem professor
- como eles decidem: para cada ponto, o vetor de incorporação é treinado, pelo qual eles são então segmentados.
O postulado principal do artigo é que objetos semelhantes devem ter encravamentos semelhantes (por exemplo, duas pernas diferentes de uma cadeira), apesar de afastados. PointNet é usado como modelo base. A principal inovação é a função de erro. Consiste em duas partes: erros de reconstrução e erros de suavidade.
O erro de reconstrução usa informações de contexto do ponto. Sua tarefa é fazer a incorporação de pontos com o mesmo contexto geométrico semelhante. Para calculá-lo, com base no vetor de incorporação do ponto selecionado, novos pontos próximos a ele são gerados. Ou seja, a descrição do recurso do ponto deve conter informações sobre a forma do objeto ao redor do ponto. Em seguida, considere o quanto os pontos gerados caem da forma real do objeto.
O erro de suavidade é necessário para que as incorporações sejam semelhantes nos pontos adjacentes e diferentes dos pontos distantes. O mais bonito aqui é a medição da proximidade, não apenas como a norma entre dois pontos no espaço euclidiano, mas contando a distância através dos pontos do objeto. Para cada ponto, um ponto é selecionado de k mais próximo e de k adicional.
A incorporação atual deve estar mais próxima do mínimo mais próximo por uma certa margem do que antes.
SGPN: Rede de proposta de grupo de similaridade para segmentação de instância de nuvem de pontos 3D
- como eles decidem: como no PointWise, a coisa mais interessante no cálculo do erro está aqui. O PointNet ++ é a base, primeiro consideramos o vetor de característica e o objeto pertencem a cada ponto individualmente, por analogia com o PointNet ++.
A seguir, com base nas características, consideramos 3 matrizes (similaridade, confiança e segmentação).
O erro de aprendizado será a soma dos três erros calculados pelas matrizes correspondentes: L = L1 + L2 + L3
Seja N o número de pontos
Matriz de similaridade - quadrada, tamanho N * N. O elemento na interseção da i-ésima linha e da j-ésima coluna indica se esses pontos pertencem a um objeto ou não. Pontos pertencentes ao mesmo objeto devem ter vetores de características semelhantes. Os elementos da matriz podem assumir um dos três valores: os pontos i e j pertencem a um objeto, os pontos pertencem a uma classe de objetos, mas a objetos diferentes (tanto a cadeira quanto a cadeira, mas as cadeiras são diferentes), ou geralmente são pontos de objetos de classes diferentes. Essa matriz é calculada de acordo com valores reais.

A matriz de confiança é um vetor de comprimento N. Para cada ponto, é considerada a interseção sobre união (IoU) entre o conjunto de pontos que pertencem ao objeto de acordo com o trabalho do nosso algoritmo e o conjunto de pontos que realmente pertencem ao objeto com o ponto atual. O erro é simplesmente a norma L2 entre a verdade e a matriz calculada. Ou seja, a rede está tentando prever o quão confiante está na previsão de classe para pontos em um objeto.
A matriz de segmentação tem um tamanho - N * o número de classes. O erro aqui é considerado como entropia cruzada no problema de classificação em várias classes. - código

- Saiba o que seus vizinhos fazem: Segmentação semântica 3D de nuvens de pontos
- como eles decidem: No início, eles consideram os sinais por muito tempo, mais complicados do que no PointNet, com várias conexões residuais e quantidades, mas em geral - mas a mesma coisa. Uma pequena diferença - eles contam os sinais para cada ponto nas coordenadas globais e locais.
A principal diferença aqui é a contagem de erros novamente. Isso não é uma cópia cruzada padrão, mas a soma de dois erros:
- perda de distância aos pares - pontos de um objeto devem estar mais próximos que τ_near e pontos de objetos diferentes devem ser maiores que τ_far .
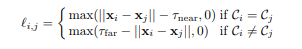
- perda de centróide - os pontos de um objeto devem estar próximos um do outro
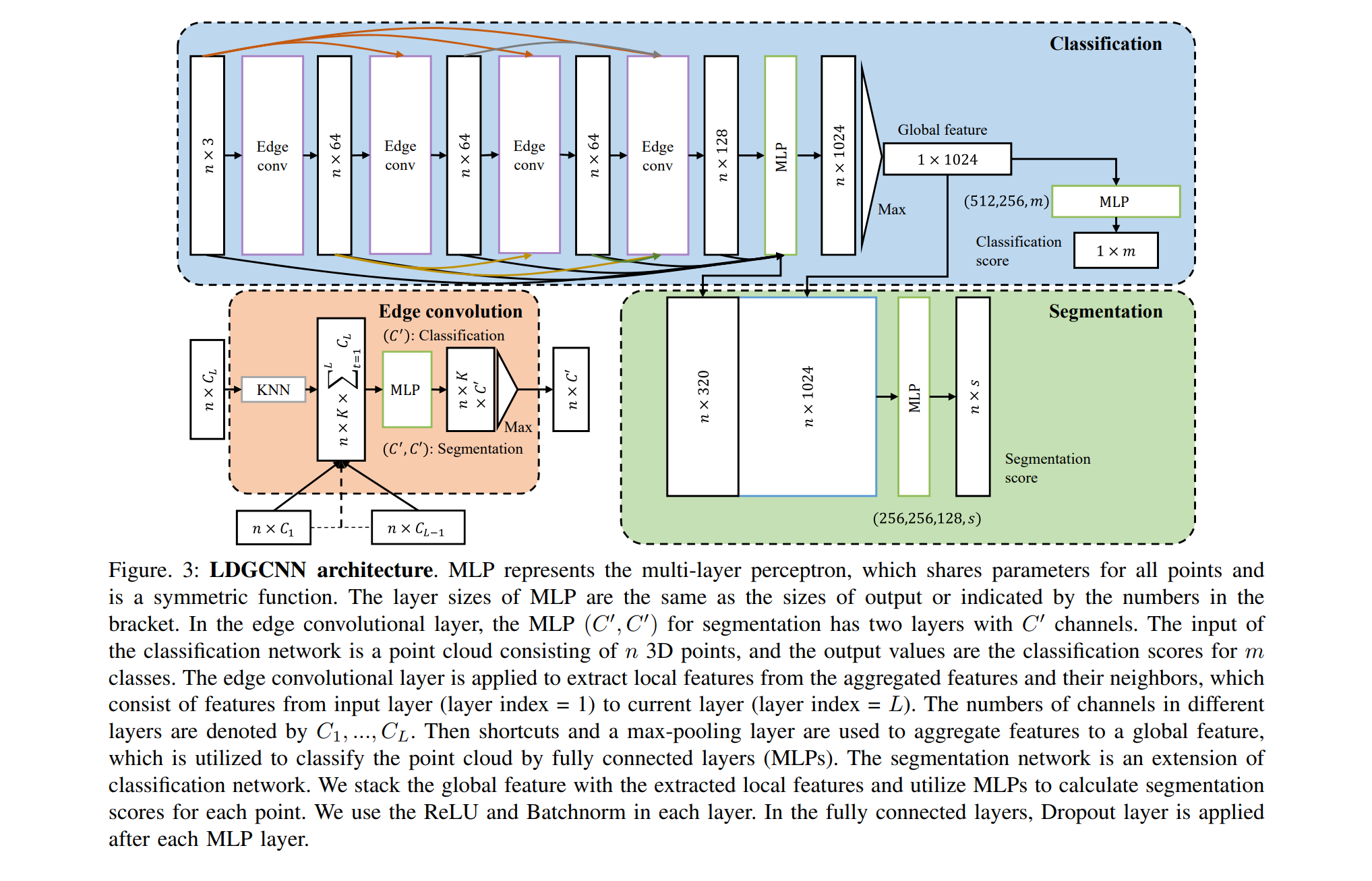
Artigos baseados no DGCNN:
O DGCNN foi publicado recentemente (2018), por isso existem poucos artigos com base nessa arquitetura. Quero chamar sua atenção para uma coisa:
Conclusão
Aqui você pode encontrar informações breves sobre métodos modernos para resolver problemas de classificação e segmentação em nuvens de pontos. Existem dois modelos principais (PointNet ++, DGCNN), cujas modificações são agora usadas para resolver esses problemas. Na maioria das vezes, para modificação, a função de erro é alterada e essas arquiteturas são complicadas adicionando camadas e links.