O GitHub hospeda mais de 300 linguagens de programação - de linguagens comumente usadas como Python, Java e Javascript a linguagens esotéricas como
Befunge , conhecidas apenas por comunidades muito pequenas.
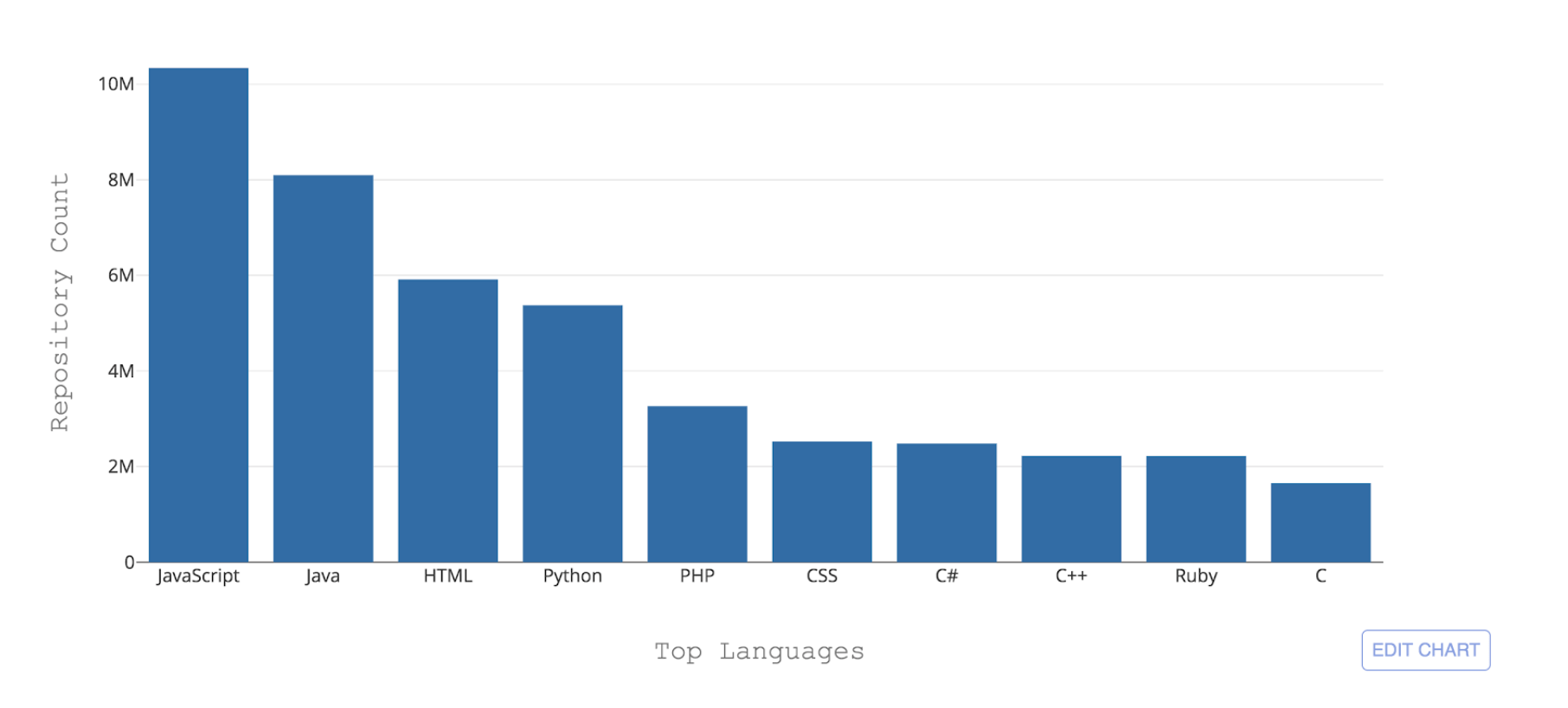 Figura 1: As 10 principais linguagens de programação hospedadas pelo GitHub por contagem de repositórios
Figura 1: As 10 principais linguagens de programação hospedadas pelo GitHub por contagem de repositóriosUm dos desafios necessários que o GitHub enfrenta é poder reconhecer esses diferentes idiomas. Quando algum código é enviado para um repositório, é importante reconhecer o tipo de código adicionado para fins de pesquisa, alerta de vulnerabilidade de segurança e destaque de sintaxe - e mostrar a distribuição de conteúdo do repositório para os usuários.
Linguista é a ferramenta que usamos atualmente para detectar linguagens de codificação no GitHub. Linguista, um aplicativo baseado em Ruby que usa várias estratégias para detecção de idioma, aproveitando as convenções de nomenclatura e as extensões de arquivo, além de levar em consideração as modelagens do Vim ou Emacs, além do conteúdo na parte superior do arquivo (shebang). O linguista lida com a desambiguação da linguagem por meio de heurísticas e, na sua falta, por meio de um classificador Naive Bayes treinado em uma pequena amostra de dados.
Embora o Linguist faça um bom trabalho ao fazer previsões de idiomas no nível do arquivo (precisão de 84%), seu desempenho diminui significativamente quando os arquivos usam convenções de nomes inesperadas e, crucialmente, quando uma extensão de arquivo não é fornecida. Isso torna o linguista inadequado para conteúdo como GitHub Gists ou trechos de código dentro de README, problemas e solicitações pull.
Para tornar a detecção de idioma mais robusta e sustentável a longo prazo, desenvolvemos um classificador de aprendizado de máquina chamado Octo Lingua com base em uma arquitetura de Rede Neural Artificial (RNA) que pode lidar com previsões de idiomas em cenários complicados. A versão atual do modelo é capaz de fazer previsões para os 50 principais idiomas hospedados pelo GitHub e ultrapassa o Linguist em precisão e desempenho.
As porcas e parafusos por trás da OctoLingua
O OctoLingua foi construído do zero usando Python, Keras com back-end TensorFlow - e foi desenvolvido para ser preciso, robusto e fácil de manter. Nesta seção, descrevemos nossas fontes de dados, arquitetura de modelo e benchmark de desempenho para o OctoLingua. Também descrevemos o que é necessário para adicionar suporte a um novo idioma.
Fontes de dados
A versão atual do OctoLingua foi treinada em arquivos recuperados do
Rosetta Code e em um conjunto de repositórios de qualidade com recursos internos de crowdsourcing. Limitamos nosso conjunto de idiomas aos 50 principais idiomas hospedados no GitHub.
O Rosetta Code foi um excelente conjunto de dados para iniciantes, pois continha código-fonte para a mesma tarefa expressa em diferentes linguagens de programação. Por exemplo, a tarefa de gerar uma
sequência de Fibonacci é expressa em C, C ++, CoffeeScript, D, Java, Julia e mais. No entanto, a cobertura entre idiomas não era uniforme, pois alguns idiomas possuem apenas um punhado de arquivos e alguns arquivos foram escassamente preenchidos. Portanto, era necessário aumentar nosso conjunto de treinamento com algumas fontes adicionais e melhorar significativamente a cobertura e o desempenho do idioma.
Nosso processo para adicionar um novo idioma agora está totalmente automatizado. Coletamos programaticamente o código fonte dos repositórios públicos no GitHub. Escolhemos repositórios que atendem a um critério mínimo de qualificação, como ter um número mínimo de garfos, cobrindo o idioma de destino e cobrindo extensões de arquivo específicas. Para esta etapa da coleta de dados, determinamos o idioma principal de um repositório usando a classificação do Linguist.
Características: aproveitando o conhecimento prévio
Tradicionalmente, para problemas de classificação de texto com redes neurais, arquiteturas baseadas em memória como Redes Neurais Recorrentes (RNN) e Redes de Memória de Longo Prazo (LSTM) são frequentemente empregadas. No entanto, considerando que as linguagens de programação têm diferenças de vocabulário, estilo de comentários, extensões de arquivo, estrutura, estilo de importação de bibliotecas e outras pequenas diferenças, optamos por uma abordagem mais simples que aproveite todas essas informações extraindo alguns recursos relevantes em forma de tabela para serem alimentados. nosso classificador. Os recursos atualmente extraídos são os seguintes:
- Os cinco principais caracteres especiais por arquivo
- Os 20 principais tokens por arquivo
- Extensão de arquivo
- Presença de certos caracteres especiais comumente usados em arquivos de código-fonte, como dois pontos, chaves e ponto e vírgula
O modelo de Rede Neural Artificial (RNA)
Utilizamos os recursos acima como entrada para uma Rede Neural Artificial de duas camadas criada usando Keras com back-end Tensorflow.
O diagrama abaixo mostra que a etapa de extração do recurso produz uma entrada tabular n-dimensional para o nosso classificador. À medida que as informações se movem pelas camadas da nossa rede, elas são regularizadas pelo abandono e, finalmente, produzem uma saída em 51 dimensões, que representa a probabilidade prevista de que o código fornecido seja escrito em cada uma das 50 principais linguagens do GitHub, mais a probabilidade de que não seja. escrito em qualquer um desses.
Figura 2: A estrutura da RNA do nosso modelo inicial (50 idiomas + 1 para "outros")Usamos 90% de nosso conjunto de dados para treinamento em aproximadamente oito épocas. Além disso, removemos uma porcentagem de extensões de arquivo de nossos dados de treinamento na etapa de treinamento, para incentivar o modelo a aprender com o vocabulário dos arquivos, e não se adequar demais ao recurso de extensão de arquivo, que é altamente preditivo.
Referência de desempenho
OctoLingua vs. LinguistaNa Figura 3, mostramos o
escore F1 (média harmônica entre precisão e recall) do OctoLingua e Linguist calculado no mesmo conjunto de testes (10% da nossa fonte de dados inicial).
Aqui nós mostramos três testes. O primeiro teste é com o conjunto de testes intocado de qualquer forma. O segundo teste usa o mesmo conjunto de arquivos de teste com as informações de extensão de arquivo removidas e o terceiro teste também usa o mesmo conjunto de arquivos, mas desta vez com extensões de arquivo embaralhadas para confundir os classificadores (por exemplo, um arquivo Java pode ter um ". txt "e um arquivo Python pode ter uma extensão" .java ").
A intuição por trás da codificação ou remoção das extensões de arquivo em nosso conjunto de testes é avaliar a robustez do OctoLingua na classificação de arquivos quando um recurso importante é removido ou é enganoso. Um classificador que não dependa muito da extensão seria extremamente útil para classificar gists e snippets, já que nesses casos é comum as pessoas não fornecerem informações precisas sobre a extensão (por exemplo, muitas gists relacionadas ao código têm uma extensão .txt).
A tabela abaixo mostra como o OctoLingua mantém um bom desempenho em várias condições, sugerindo que o modelo aprenda principalmente com o vocabulário do código, e não com as informações meta (por exemplo, extensão de arquivo), enquanto o Linguista falha assim que as informações sobre extensões de arquivo são alterado.
Figura 3: Desempenho do OctoLingua vs. Linguista no mesmo conjunto de testesEfeito da remoção da extensão do arquivo durante o tempo de treinamentoComo mencionado anteriormente, durante o tempo de treinamento, removemos uma porcentagem de extensões de arquivos de nossos dados de treinamento para incentivar o modelo a aprender com o vocabulário dos arquivos. A tabela abaixo mostra o desempenho do nosso modelo com diferentes frações de extensões de arquivo removidas durante o tempo de treinamento.
 Figura 4: Desempenho do OctoLingua com porcentagem diferente de extensões de arquivo removidas em nossas três variações de teste
Figura 4: Desempenho do OctoLingua com porcentagem diferente de extensões de arquivo removidas em nossas três variações de testeObserve que, sem nenhuma extensão de arquivo removida durante o tempo de treinamento, o desempenho do OctoLingua em arquivos de teste sem extensões e extensões aleatórias diminui significativamente em relação aos dados de teste regulares. Por outro lado, quando o modelo é treinado em um conjunto de dados em que algumas extensões de arquivo são removidas, o desempenho do modelo não diminui muito no conjunto de testes modificado. Isso confirma que a remoção da extensão de arquivo de uma fração dos arquivos no momento do treinamento induz nosso classificador a aprender mais com o vocabulário. Ele também mostra que o recurso de extensão de arquivo, embora altamente preditivo, tendia a dominar e impedia que mais pesos fossem atribuídos aos recursos de conteúdo.
Suportando um novo idioma
A adição de um novo idioma no OctoLingua é bastante direta. Começa com a obtenção de uma grande quantidade de arquivos no novo idioma (podemos fazer isso de forma programática, conforme descrito nas fontes de dados). Esses arquivos são divididos em um conjunto de treinamento e teste e, em seguida, são executados em nosso pré-processador e extrator de recursos. Esse novo conjunto de treinamento e teste é adicionado ao nosso pool existente de dados de treinamento e teste. O novo conjunto de testes nos permite verificar se a precisão do nosso modelo permanece aceitável.
Figura 5: Adicionando um novo idioma com o OctoLinguaNossos planos
A partir de agora, o OctoLingua está no "estágio avançado de prototipagem". Nosso mecanismo de classificação de idiomas já é robusto e confiável, mas ainda não suporta todos os idiomas de codificação em nossa plataforma. Além de ampliar o suporte a idiomas - o que seria bastante direto -, pretendemos permitir a detecção de idiomas em vários níveis de granularidade. Nossa implementação atual já nos permite, com uma pequena modificação em nosso mecanismo de aprendizado de máquina, classificar trechos de código. Não seria muito difícil levar o modelo ao estágio em que ele pode detectar e classificar de forma confiável as linguagens incorporadas.
Também estamos contemplando a possibilidade de abrir o código do nosso modelo e gostaríamos de ouvir a comunidade, se você estiver interessado.
Sumário
Com o OctoLingua, nosso objetivo é fornecer um serviço que permita a detecção robusta e confiável da linguagem do código-fonte em vários níveis de granularidade, do nível do arquivo ou do snippet à detecção e classificação do idioma potencialmente no nível da linha. Eventualmente, esse serviço pode suportar, entre outros, pesquisa de código, compartilhamento de código, destaque de idioma e renderização de diferenças - tudo isso destinado a apoiar os desenvolvedores no trabalho de desenvolvimento diário, além de ajudá-los a escrever um código de qualidade. Se você estiver interessado em alavancar ou contribuir com nosso trabalho, sinta-se à vontade para entrar em contato no Twitter
@github !