O artigo mostra como implementar o tratamento de erros e o log com base no princípio "Feito e Esquecido" no Go. O método foi desenvolvido para microsserviços on Go, trabalhando em um contêiner Docker e construído em conformidade com os princípios da Arquitetura Limpa.
Este artigo é uma versão detalhada de um relatório da recente reunião do Go em Kazan . Se você está interessado em Go e mora em Kazan, Innopolis, na bonita Yoshkar-Ola ou em outra cidade próxima, visite a página da comunidade: golangkazan.imtqy.com .
Na reunião, nossa equipe em dois relatórios mostrou como estamos desenvolvendo microsserviços no Go - quais princípios seguimos e como simplificamos nossas vidas. Este artigo se concentra em nosso conceito de tratamento de erros, que agora estendemos a todos os nossos novos microsserviços.
Acordos de estrutura de microsserviços
Antes de abordar as regras para tratamento de erros, vale a pena decidir quais restrições observamos ao projetar e codificar. Para fazer isso, vale a pena dizer como são os nossos microsserviços.
Antes de tudo, respeitamos a arquitetura limpa. Dividimos o código em três níveis e observamos a regra de dependência: pacotes em um nível mais profundo são independentes de pacotes externos e não existem dependências cíclicas. Felizmente, as dependências diretas de round-robin dos pacotes são proibidas no Go. Dependências indiretas por meio de terminologia de empréstimo, suposições sobre comportamento ou conversão para um tipo ainda podem aparecer; elas devem ser evitadas.
É assim que nossos níveis se parecem:
- O nível do domínio contém regras de lógica de negócios ditadas pela área de assunto.
- às vezes fazemos sem domínio se a tarefa é simples
- regra: o código no nível do domínio depende apenas dos recursos do Go, da biblioteca Go padrão e das bibliotecas selecionadas que estendem o idioma Go
- A camada de aplicativo contém regras de lógica de negócios ditadas pelas tarefas do aplicativo.
- regra: o código no nível do aplicativo pode depender do domínio
- O nível de infraestrutura contém código de infraestrutura que conecta o aplicativo a várias tecnologias de armazenamento (MySQL, Redis), transporte (GRPC, HTTP), interação com o ambiente externo e outros serviços
- regra: o código no nível da infraestrutura pode depender do domínio e do aplicativo
- regra: apenas uma tecnologia por pacote Go
- O pacote principal cria todos os objetos - "singleton vitalício", os conecta e lança corotinas de longa duração - por exemplo, começa a processar solicitações HTTP da porta 8081
É assim que a árvore de diretórios do microsserviço é exibida (a parte onde está o código Go):

Para cada um dos contextos de aplicação (módulos), a estrutura do pacote tem a seguinte aparência:
- o pacote de aplicativos declara uma interface de serviço que contém todas as ações possíveis em um determinado nível que implementa a interface da estrutura de serviço e a função
func NewService(...) Service - o isolamento do trabalho com o banco de dados é alcançado devido ao fato de o domínio ou o pacote de aplicativos declarar a interface do Repositório, que é implementada no nível da infraestrutura no pacote com o nome visual "mysql"
- o código de transporte está localizado no pacote de
infrastructure/transport
- usamos GRPC, para que os stubs do servidor sejam gerados a partir do arquivo proto (ou seja, interface do servidor, estruturas de resposta / solicitação e todo o código de interação do cliente)
Tudo isso é mostrado no diagrama:

Princípios de tratamento de erros
Tudo é simples aqui:
- Acreditamos que erros e pânico ocorram ao processar solicitações à API - o que significa que um erro ou pânico deve afetar apenas uma solicitação
- Acreditamos que os logs são necessários apenas para análise de incidentes (e existe um depurador para depuração); portanto, informações sobre solicitações são recebidas no log e, antes de tudo, erros inesperados ao processar solicitações
- Acreditamos que toda uma infraestrutura foi criada para processar logs (por exemplo, com base no ELK) - e o microsserviço desempenha um papel passivo nela, gravando logs no stderr
Não focaremos no pânico: não se esqueça de lidar com o pânico em todas as goroutines e durante o processamento de cada solicitação, cada mensagem, cada tarefa assíncrona iniciada pela solicitação. Quase sempre, o pânico pode se transformar em um erro para impedir que o aplicativo inteiro seja concluído.
Erros de sentinela de idioma
No nível da lógica de negócios, apenas os erros esperados definidos pelas regras de negócios são processados. Os erros do Sentinel o ajudarão a identificar esses erros - usamos esse idioma em vez de escrever nossos próprios tipos de dados para erros. Um exemplo:
package app import "errors" var ErrNoCake = errors.New("no cake found")
Aqui é declarada uma variável global que, pelo acordo de nossos cavalheiros, não devemos mudar em lugar algum. Se você não gosta de variáveis globais e usa o linter para detectá-las, pode conviver com algumas constantes, como sugere Dave Cheney na publicação de erros Constant :
package app type Error string func (e Error) Error() string { return string(e) } const ErrNoCake = Error("no cake found")
Se você gosta dessa abordagem, pode adicionar o tipo ConstError à sua biblioteca de idiomas Go corporativa.
Composição dos erros
A principal vantagem dos erros do Sentinel é a capacidade de compor erros com facilidade. Em particular, ao criar um erro ou receber um erro de fora, seria bom adicionar um rastreamento de pilha a ele. Para tais fins, existem duas soluções populares.
- pacote xerrors, que no Go 1.13 será incluído na biblioteca padrão como um experimento
- Pacote github.com/pkg/errors por Dave Cheney
- a embalagem está congelada e não se expande, mas é boa
Nossa equipe ainda usa github.com/pkg/errors e os errors.WithStack Funções errors.WithStack (quando não temos nada a acrescentar, exceto errors.Wrap ) ou errors.Wrap (quando temos algo a dizer sobre esse erro). Ambas as funções aceitam um erro na entrada e retornam um novo erro, mas com o rastreamento de pilha. Exemplo da camada de infraestrutura:
package mysql import "github.com/pkg/errors" func (r *repository) FindOne(...) { row := r.client.QueryRow(sql, params...) switch err := row.Scan(...) { case sql.ErrNoRows:
Recomendamos que cada erro seja quebrado apenas uma vez. Isso é fácil se você seguir as regras:
- quaisquer erros externos são agrupados uma vez em um dos pacotes de infraestrutura
- quaisquer erros gerados pelas regras da lógica de negócios são complementados pelo stacktrace no momento da criação
Causa raiz do erro
Todos os erros são divididos em esperados e inesperados. Para lidar com o erro esperado, você precisa se livrar dos efeitos da composição. Os pacotes github.com/pkg/errors e github.com/pkg/errors têm tudo o que você precisa: em particular, o pacote de erros possui a função errors.Cause , que retorna a causa raiz do erro. Essa função em um loop, uma após a outra, recupera erros anteriores, enquanto o próximo erro extraído possui o método de Cause() error .
Um exemplo ao qual extraímos a causa raiz e a comparamos diretamente com o erro sentinela:
func (s *service) SaveCake(...) error { state, err := s.repo.FindOne(...) if errors.Cause(err) == ErrNoCake { err = nil
Tratamento de erros no adiamento
Talvez você esteja usando o linter, o que faz com que você verifique manualmente todos os erros. Nesse caso, você provavelmente está enfurecido quando o linter pede para verificar erros nos métodos .Close() e outros métodos que você defer apenas de defer . Você já tentou lidar corretamente com o erro no adiamento, especialmente se houver outro erro antes disso? E tentamos e estamos com pressa de compartilhar a receita.
Imagine que todo o trabalho com o banco de dados seja estritamente através de transações. De acordo com a regra de dependência, os níveis de aplicativo e domínio não devem depender direta ou indiretamente da infraestrutura e da tecnologia SQL. Isso significa que, nos níveis do aplicativo e do domínio, não há palavra "transação" .
A solução mais simples é substituir a palavra "transação" por algo abstrato; assim nasce o padrão da Unidade de Trabalho. Em nossa implementação, o serviço no pacote de aplicativos recebe a fábrica por meio da interface UnitOfWorkFactory e, durante cada operação, cria um objeto UnitOfWork que oculta a transação. O objeto UnitOfWork permite obter um repositório.
Mais sobre UnitOfWorkPara entender melhor o uso da Unidade de Trabalho, dê uma olhada no diagrama:
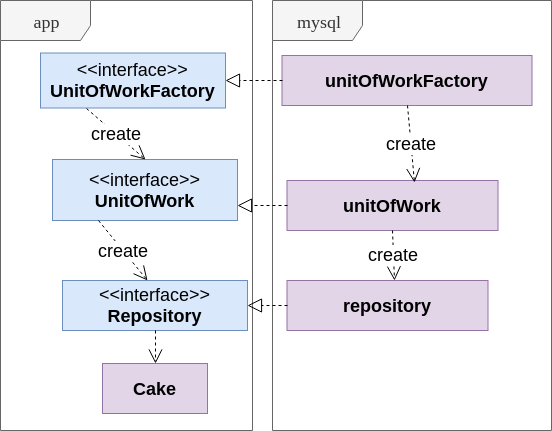
- Repositório representa uma coleção persistente abstrata de objetos (por exemplo, agregados no nível do domínio) de um tipo definido
- UnitOfWork oculta a transação e cria objetos de repositório
- UnitOfWorkFactory simplesmente permite que o serviço crie novas transações sem saber nada sobre transações.
Não é excessivo criar uma transação para cada operação, mesmo inicialmente atômica? Depende de você; Acreditamos que manter a independência da lógica de negócios é mais importante do que economizar na criação de uma transação.
É possível combinar UnitOfWork e Repository? É possível, mas acreditamos que isso viola o princípio da responsabilidade única.
É assim que a interface se parece:
type UnitOfWork interface { Repository() Repository Complete(err *error) }
A interface UnitOfWork fornece o método Complete, que utiliza um parâmetro de entrada e saída: um ponteiro para a interface de erro. Sim, é o ponteiro e o parâmetro in-out - em qualquer outro caso, o código no lado de chamada será muito mais complicado.
Exemplo de operação com unitOfWork:
Cuidado: o erro deve ser declarado como valor de retorno nomeado. Se, em vez do valor de retorno nomeado err, você usar a variável local err, não poderá usá-lo no adiamento! E nem um único linter detectará isso ainda - veja o crítico # 801
func (s *service) CookCake() (err error) { unitOfWork, err := s.unitOfWorkFactory.New() if err != nil { return err } defer unitOfWork.Complete(&err) repo := unitOfWork.Repository() }
Então a conclusão é realizada transações UnitOfWork:
func (u *unitOfWork) Complete(err *error) { if *err == nil {
A função mergeErrors mescla dois erros, mas processa nada sem problemas, em vez de um ou ambos os erros. Ao mesmo tempo, acreditamos que ambos os erros ocorreram durante a execução de uma operação em estágios diferentes, e o primeiro erro é mais importante - portanto, quando os dois erros não são nulos, salvamos o primeiro e apenas a mensagem é salva do segundo erro:
package errors func mergeErrors(err error, nextErr error) error { if err == nil { err = nextErr } else if nextErr != nil { err = errors.Wrap(err, nextErr.Error()) } return err }
Talvez você deva adicionar a função mergeErrors à sua biblioteca corporativa do Go.
Subsistema de registro em log
Lista de verificação do artigo : o que você tinha que fazer antes de iniciar os microsserviços no produto aconselha:
- logs são escritos em stderr
- logs devem estar em JSON, um objeto JSON compacto por linha
- Deve haver um conjunto padrão de campos:
- timestamp - hora do evento em milissegundos , de preferência no formato RFC 3339 (exemplo: "1985-04-12T23: 20: 50.52Z")
- nível - nível de importância, por exemplo, "informações" ou "erro"
- app_name - nome do aplicativo
- e outros campos
Preferimos adicionar mais dois campos às mensagens de erro: "error" e "stacktrace" .
Existem muitas bibliotecas de registro de qualidade para a linguagem Golang, por exemplo, sirupsen / logrus , que usamos. Mas não usamos a biblioteca diretamente. Primeiro de tudo, em nosso pacote de log , reduzimos a interface de biblioteca excessivamente extensa para uma interface do Logger:
package log type Logger interface { WithField(string, interface{}) Logger WithFields(Fields) Logger Debug(...interface{}) Info(...interface{}) Error(error, ...interface{}) }
Se o programador quiser gravar logs, ele deverá obter a interface do Logger de fora, e isso deve ser feito no nível da infraestrutura, não no aplicativo ou no domínio. A interface do criador de logs é concisa:
- reduz o número de níveis de severidade para depuração, informações e erros, como aconselha o artigo.Vamos falar sobre o log.
- ele introduz regras especiais para o método Error: o método sempre aceita um objeto de erro
Essa rigidez permite direcionar os programadores na direção certa: se alguém quiser melhorar o sistema de registro em si, deve fazê-lo levando em consideração toda a infraestrutura de sua coleta e processamento, que só começa no microsserviço (e geralmente termina em Kibana e Zabbix).
No entanto, no pacote de log, há outra interface que permite interromper o programa quando ocorre um erro fatal e, portanto, só pode ser usado no pacote principal:
package log type MainLogger interface { Logger FatalError(error, ...interface{}) }
Pacote Jsonlog
Implementa a interface do Logger em nosso pacote jsonlog , que configura a biblioteca logrus e abstrai o trabalho com ela. Esquematicamente aparece assim:

Um pacote proprietário permite conectar as necessidades de um microsserviço (expresso pela interface log.Logger ), os recursos da biblioteca logrus e os recursos de sua infraestrutura.
Por exemplo, usamos ELK (Elastic Search, Logstash, Kibana) e, portanto, no pacote jsonlog:
- configure o formato
logrus.JSONFormatter para logrus.JSONFormatter
- ao mesmo tempo, definimos a opção FieldMap, com a qual transformamos o campo
"time" em "@timestamp" e o campo "msg" em "message"
- selecione o nível do log
- adicione um gancho que extraia o rastreamento de pilha do objeto de
Error(error, ...interface{}) passado para o método Error(error, ...interface{})
O microsserviço inicializa o logger na função principal:
func initLogger(config Config) (log.MainLogger, error) { logLevel, err := jsonlog.ParseLevel(config.LogLevel) if err != nil { return nil, errors.Wrap(err, "failed to parse log level") } return jsonlog.NewLogger(&jsonlog.Config{ Level: logLevel, AppName: "cookingservice" }), nil }
Tratamento e registro de erros com Middleware
Estamos mudando para o GRPC em nossos microsserviços on Go. Mas mesmo se você usar a API HTTP, os princípios gerais são para você.
Primeiro, o tratamento e registro de erros devem ocorrer no nível da infrastructure do pacote responsável pelo transporte, porque é ele quem combina o conhecimento das regras do protocolo de transporte e o conhecimento dos app.Service interface app.Service . Lembre-se da aparência do relacionamento do pacote:

É conveniente processar erros e manter logs usando o padrão Middleware (Middleware é o nome do padrão Decorator no mundo de Golang e Node.js):
Onde adicionar o Middleware? Quantos devem haver?
Existem diferentes opções para adicionar Middleware, você escolhe:
- Você pode decorar a interface
app.Service , mas não recomendamos fazer isso porque essa interface não recebe informações da camada de transporte, como IP do cliente - Com o GRPC, você pode suspender um manipulador em todas as solicitações (mais precisamente, duas - unárias e steam), mas todos os métodos de API serão registrados no mesmo estilo com o mesmo conjunto de campos
- Com o GRPC, o gerador de código cria para nós uma interface de servidor na qual chamamos o método
app.Service - decoramos essa interface porque ela contém informações em nível de transporte e a capacidade de registrar diferentes métodos de API de maneiras diferentes
Esquematicamente aparece assim:

Você pode criar Middlewares diferentes para tratamento de erros (e pânico) e para criação de log. Você pode cruzar tudo em um. Vamos considerar um exemplo no qual tudo é cruzado em um Middleware, criado dessa maneira:
func NewMiddleware(next api.BackendService, logger log.Logger) api.BackendService { server := &errorHandlingMiddleware{ next: next, logger: logger, } return server }
Nós obtemos a interface api.BackendService como uma api.BackendService e a decoramos, retornando nossa implementação da interface api.BackendService como uma api.BackendService .
Um método de API arbitrário no Middleware é implementado da seguinte maneira:
func (m *errorHandlingMiddleware) ListCakes( ctx context.Context, req *api.ListCakesRequest) (*api.ListCakesResponse, error) { start := time.Now() res, err := m.next.ListCakes(ctx, req) m.logCall(start, err, "ListCakes", log.Fields{ "cookIDs": req.CookIDs, }) return res, translateError(err) }
Aqui, realizamos três tarefas:
- Chame o método ListCakes do objeto decorado
logCall método logCall , transmitindo todas as informações importantes, incluindo um conjunto de campos individualmente selecionados que se enquadram no log- No final, substituímos o erro chamando translateError.
A conversão de erros será discutida mais tarde. E o logCall é realizado pelo método logCall , que simplesmente chama o método correto da interface do Logger:
func (m *errorHandlingMiddleware) logCall(start time.Time, err error, method string, fields log.Fields) { fields["duration"] = fmt.Sprintf("%v", time.Since(start)) fields["method"] = method logger := m.logger.WithFields(fields) if err != nil { logger.Error(err, "call failed") } else { logger.Info("call finished") } }
Erro de tradução
Devemos obter a causa raiz do erro e transformá-lo em um erro compreensível no nível de transporte e documentado na API do seu serviço.
No GRPC, é simples - use a função status.Errorf para criar um erro com um código de status. Se você tiver uma API HTTP (API REST), poderá criar seu próprio tipo de erro que os níveis de aplicativo e domínio não devem estar cientes.
Em uma primeira aproximação, a tradução do erro é semelhante a esta:
Ao validar argumentos de entrada, a interface decorada pode retornar um erro do status.Status Tipo de status com um código de status e a primeira versão do translateError perderá esse código de status.
Vamos fazer uma versão aprimorada convertendo para um tipo de interface (vida longa, digitando duck!):
type statusError interface { GRPCStatus() *status.Status } func isGrpcStatusError(er error) bool { _, ok := err.(statusError) return ok } func translateError(err error) error { if isGrpcStatusError(err) { return err } switch errors.Cause(err) { case app.ErrNoCake: err = status.Errorf(codes.NotFound, err.Error()) default: err = status.Errorf(codes.Internal, err.Error()) } return err }
A função translateError é criada individualmente para cada contexto (módulo independente) em seu microsserviço e converte erros de lógica de negócios em erros no nível de transporte.
Resumir
Oferecemos várias regras para lidar com erros e trabalhar com logs. A decisão de segui-los ou não é com você.
- Siga os princípios da arquitetura limpa, não quebre direta ou indiretamente a regra das dependências. A lógica de negócios deve depender apenas de uma linguagem de programação e não de tecnologias externas.
- Use um pacote que ofereça composição de erro e criação de rastreamento de pilha. Por exemplo, "github.com/pkg/errors" ou o pacote xerrors, que em breve fará parte da biblioteca padrão Go.
- Não use bibliotecas de log de terceiros no microsserviço - crie sua própria biblioteca com os pacotes log e jsonlog, que ocultarão os detalhes da implementação de log
- Use o padrão Middleware para manipular erros e gravar logs na direção de transporte do nível de infraestrutura do programa
Aqui, não dissemos nada sobre as tecnologias de rastreamento de consultas (por exemplo, OpenTracing), monitoramento de métricas (por exemplo, desempenho de consultas ao banco de dados) e outras coisas como registro em log. Você mesmo vai lidar com isso, nós acreditamos em você.