Em 27 de abril, na conferência
Strike-2019 , dentro da estrutura da seção DevOps, foi elaborado um relatório intitulado "Escalonamento automático e gerenciamento de recursos no Kubernetes". Ele fala sobre como usar o K8s para garantir alta disponibilidade de aplicativos e garantir seu desempenho máximo.

Por tradição, temos o prazer de apresentar um
vídeo com um relatório (44 minutos, muito mais informativo que o artigo) e o aperto principal em forma de texto. Vamos lá!
Analisaremos o tópico do relatório de acordo com as palavras e começaremos do final.
Kubernetes
Vamos ter contêineres Docker no host. Porque Para garantir repetibilidade e isolamento, que por sua vez permite uma implantação simples e boa, o CI / CD. Temos muitas dessas máquinas com contêineres.
O que neste caso dá ao Kubernetes?
- Paramos de pensar nessas máquinas e começamos a trabalhar com a “nuvem”, um cluster de contêineres ou vagens (grupos de contêineres).
- Além disso, nem pensamos em pods individuais, mas gerenciamos mais grupos grandes. Essas primitivas de alto nível permitem dizer que existe um modelo para iniciar uma certa carga de trabalho, mas o número necessário de instâncias para seu lançamento. Se posteriormente mudarmos o modelo, todas as instâncias também serão alteradas.
- Usando a API declarativa, em vez de executar uma sequência de comandos específicos, descrevemos o "dispositivo mundial" (em YAML) que o Kubernetes cria. E novamente: quando a descrição muda, sua exibição real também muda.
Gerenciamento de recursos
CPU
Vamos rodar nginx, php-fpm e mysql no servidor. Esses serviços realmente terão ainda mais processos em execução, cada um dos quais requer recursos de computação:
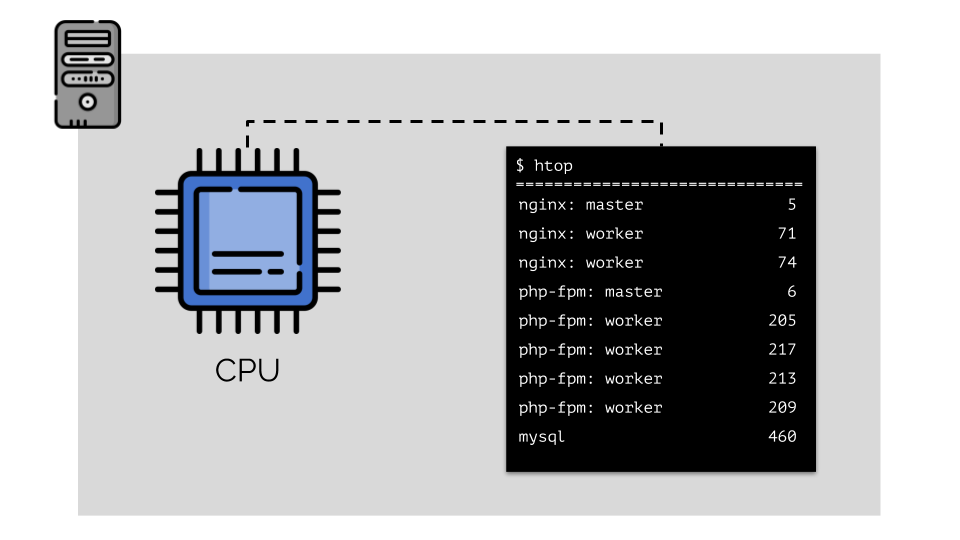 (os números no slide são "papagaios", a necessidade abstrata de cada processo de poder computacional)
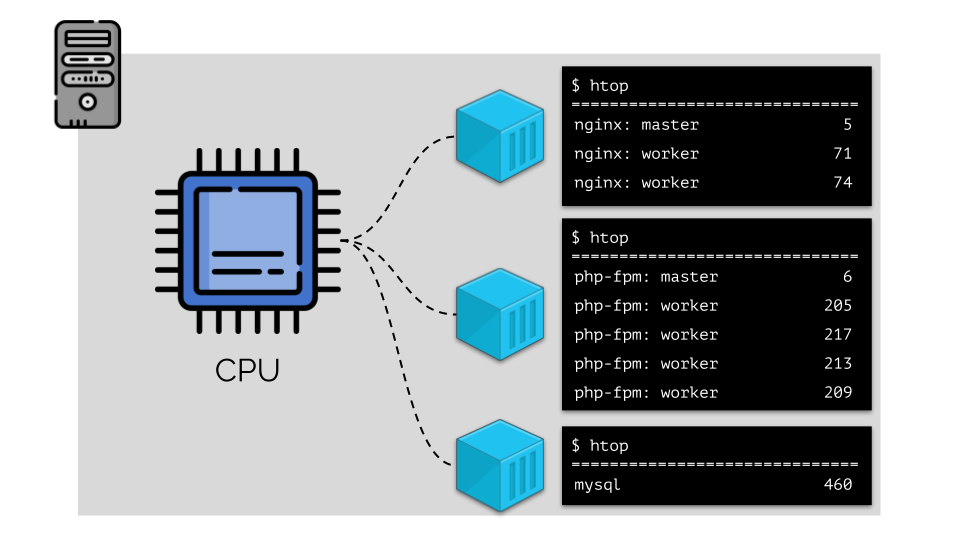
(os números no slide são "papagaios", a necessidade abstrata de cada processo de poder computacional)Para tornar conveniente trabalhar com isso, é lógico combinar processos em grupos (por exemplo, todos os processos nginx em um grupo "nginx"). Uma maneira simples e óbvia de fazer isso é colocar cada grupo em um contêiner:
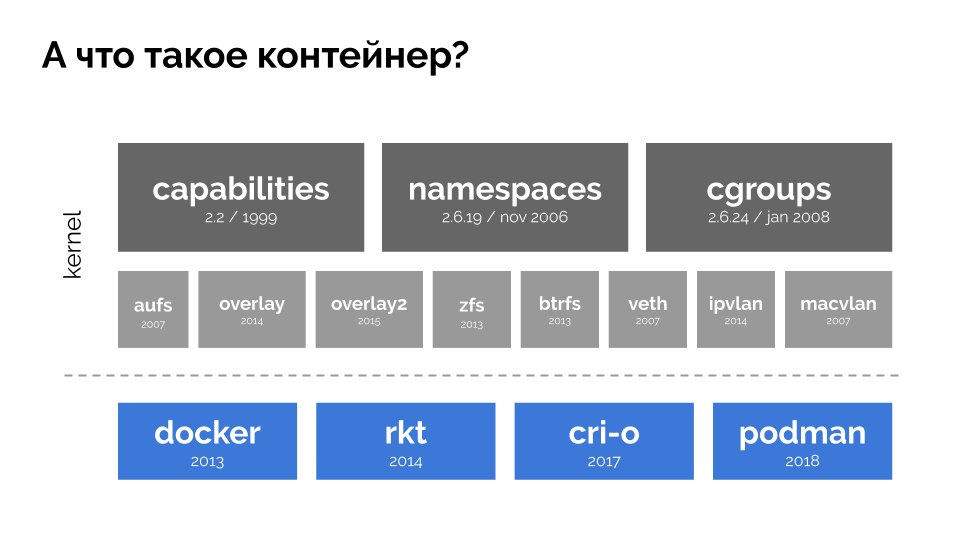
Para continuar, você precisa se lembrar do que é um contêiner (no Linux). Sua aparência foi possível graças a três recursos principais do kernel, implementados por um longo tempo:
recursos ,
namespaces e
cgroups . E outras tecnologias (incluindo "conchas" convenientes, como o Docker) contribuíram para o desenvolvimento futuro:
No contexto do relatório, estamos interessados apenas em
cgroups , porque grupos de controle fazem parte da funcionalidade de contêineres (Docker, etc.) que implementa o gerenciamento de recursos. Os processos, unidos em grupos, como queríamos, são os grupos de controle.
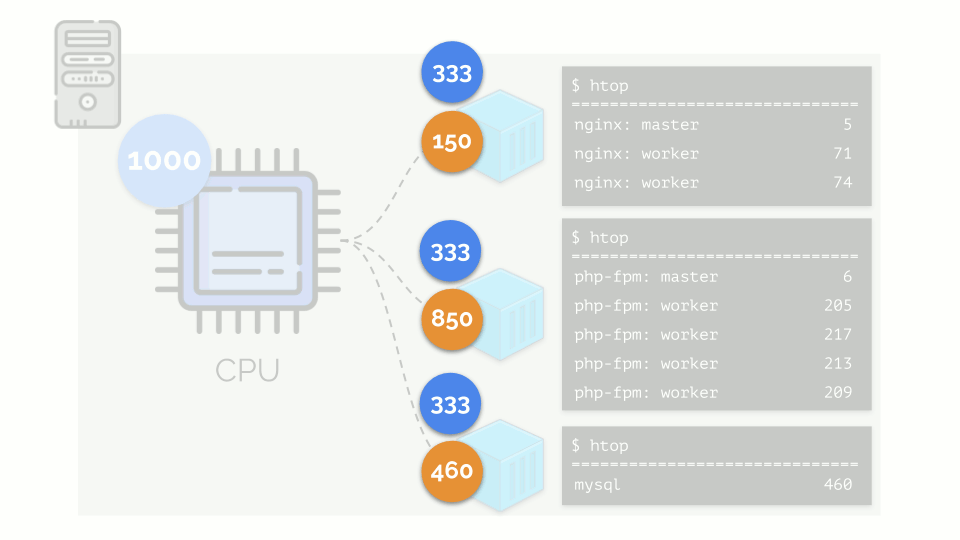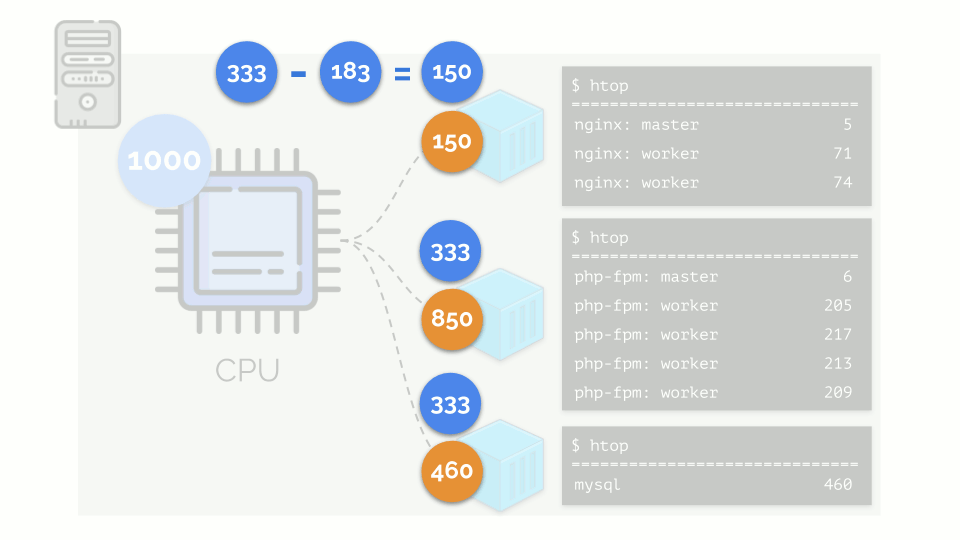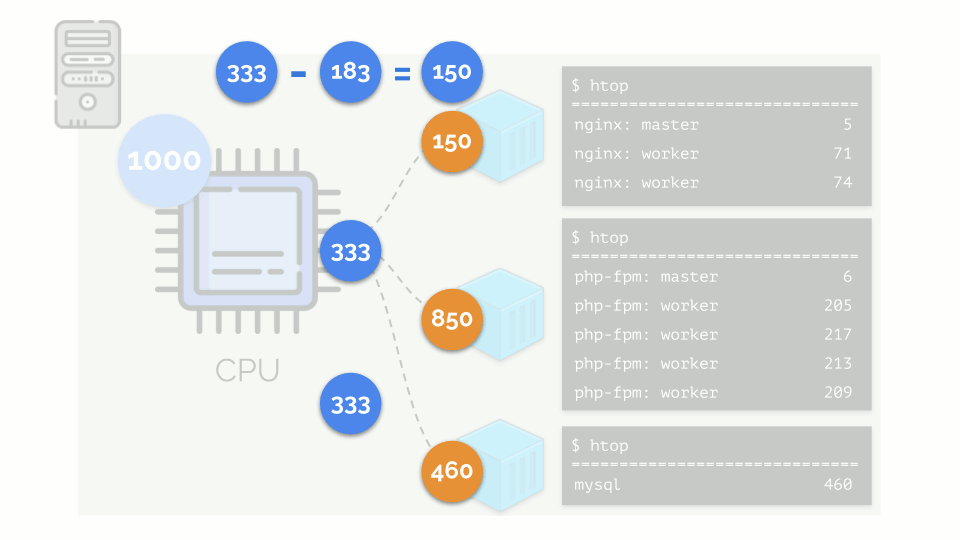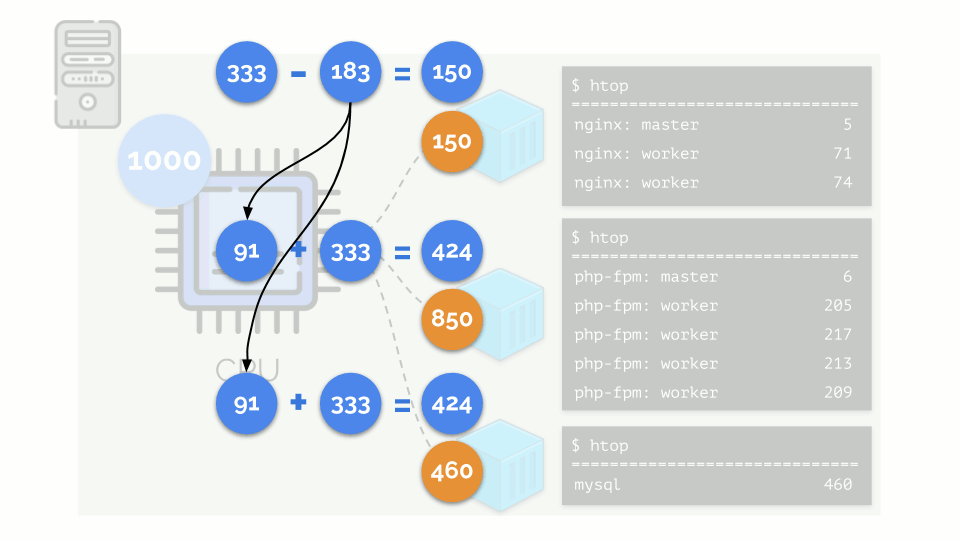
Vamos retornar aos requisitos de CPU para esses processos e agora para os grupos de processos:
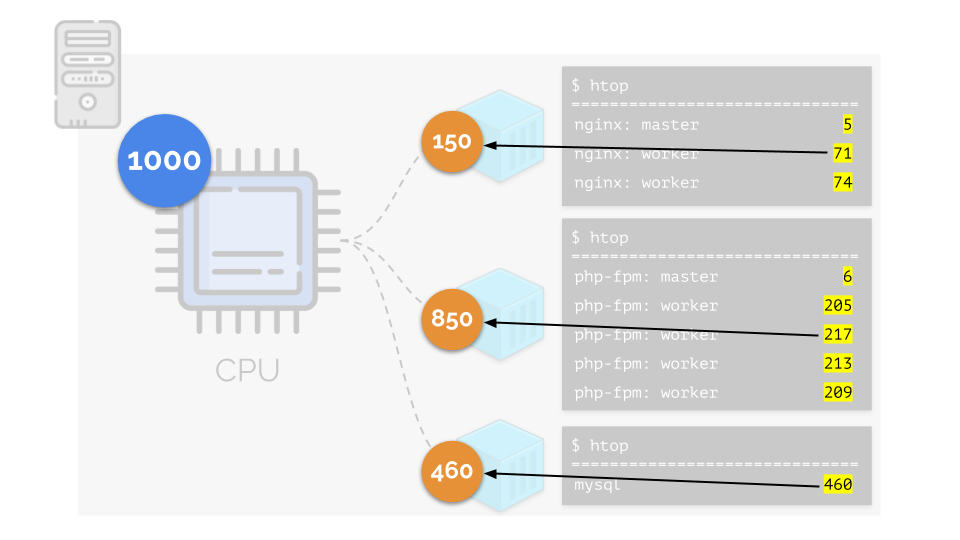 (Repito que todos os números são uma expressão abstrata dos requisitos de recursos)
(Repito que todos os números são uma expressão abstrata dos requisitos de recursos)Ao mesmo tempo, a própria CPU possui um determinado recurso final
(no exemplo, é 1000) , o que pode não ser suficiente para todos (a soma das necessidades de todos os grupos é 150 + 850 + 460 = 1460). O que acontecerá neste caso?
O kernel começa a distribuir recursos e o faz "honestamente", distribuindo a mesma quantidade de recursos para cada grupo. Porém, no primeiro caso, existem mais do que o necessário (333> 150), portanto o excesso (333-150 = 183) permanece em reserva, que também é distribuído igualmente entre outros dois contêineres:
Como resultado: o primeiro contêiner tinha recursos suficientes, o segundo - não foi suficiente, o terceiro - não foi suficiente. Este é o resultado do
planejador "honesto" no Linux -
CFS . Seu trabalho pode ser regulado atribuindo
peso a cada um dos contêineres. Por exemplo, assim:
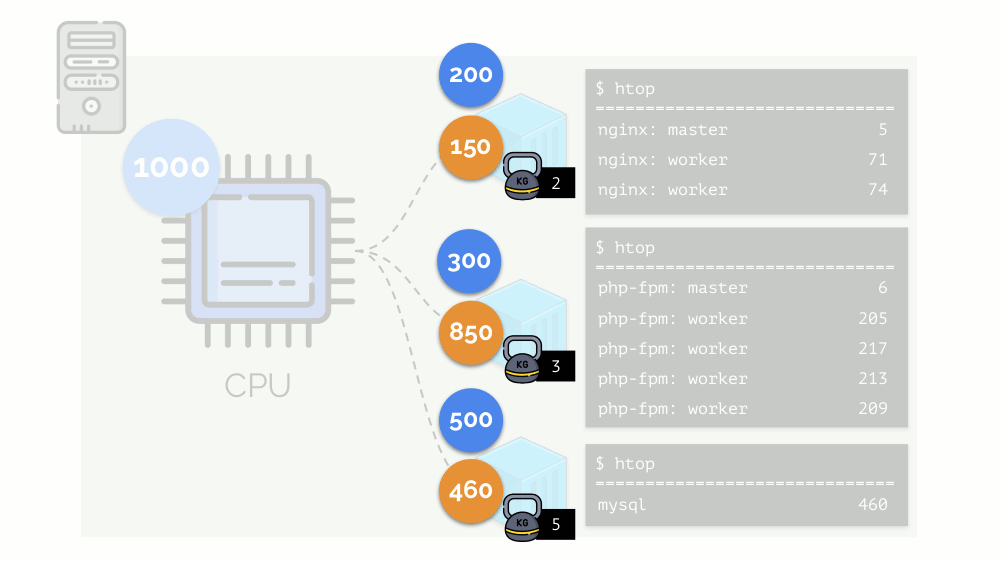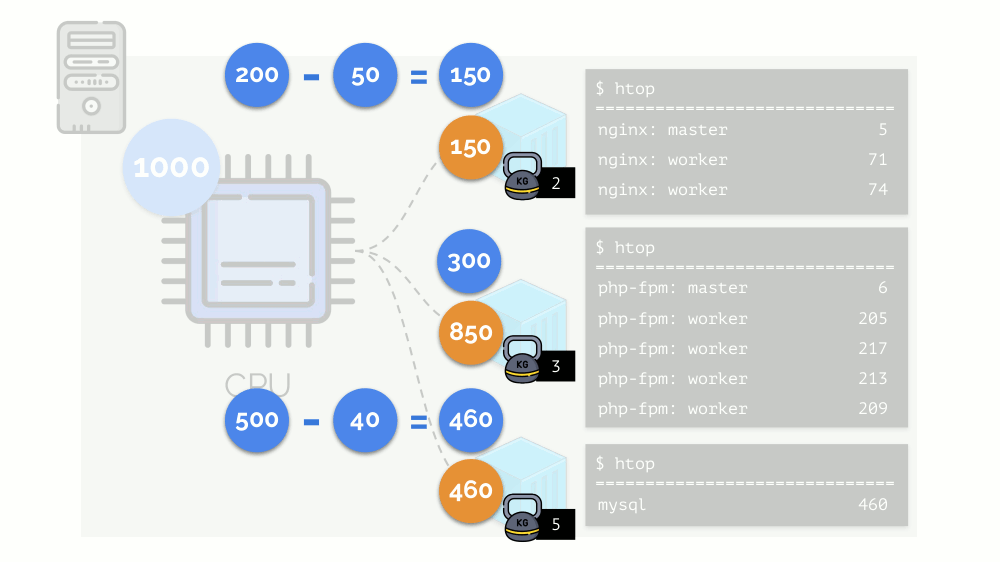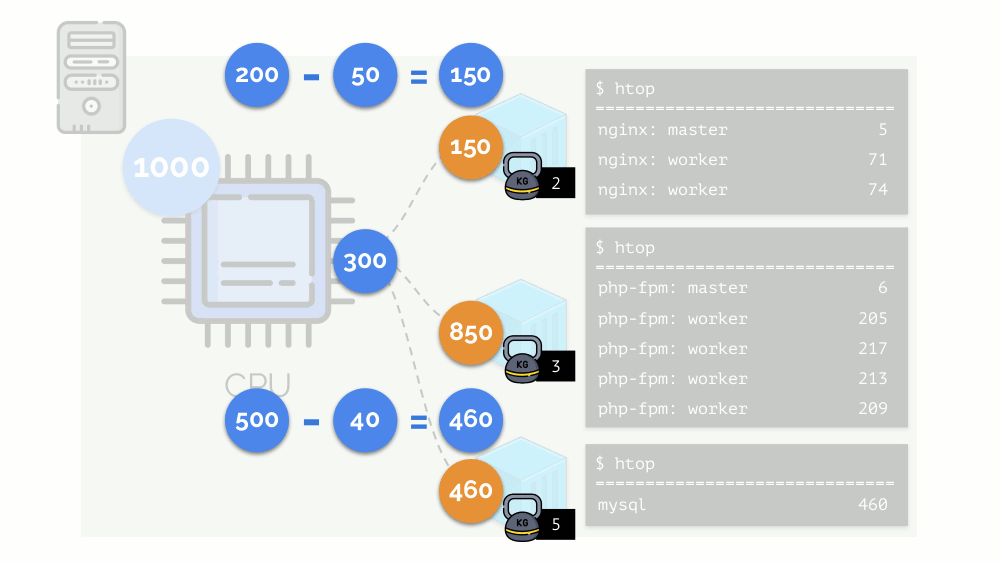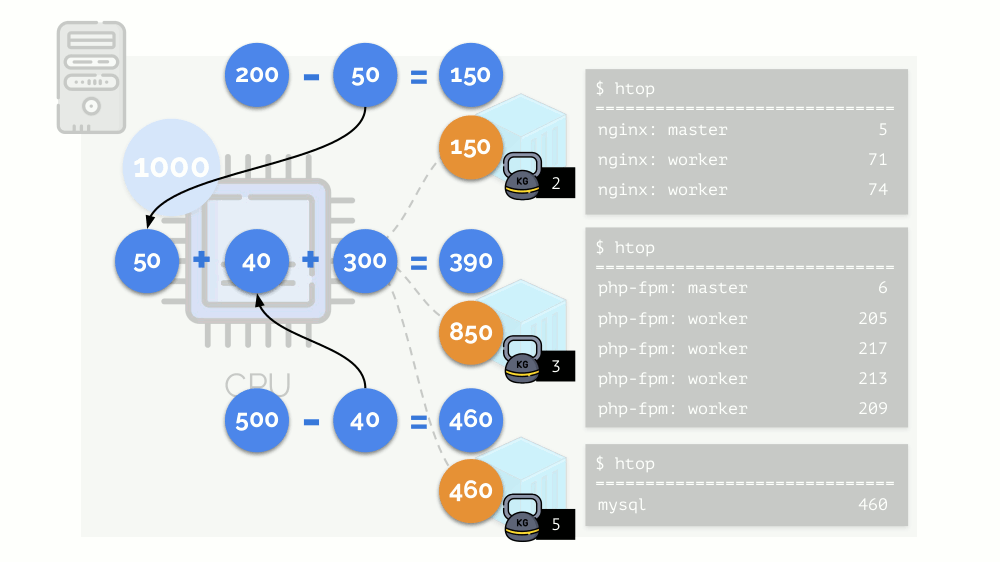
Vejamos o caso de falta de recursos no segundo contêiner (php-fpm). Todos os recursos de contêiner são distribuídos entre os processos igualmente. Como resultado, o processo mestre funciona bem e todos os funcionários ficam mais lentos, recebendo menos da metade do necessário:
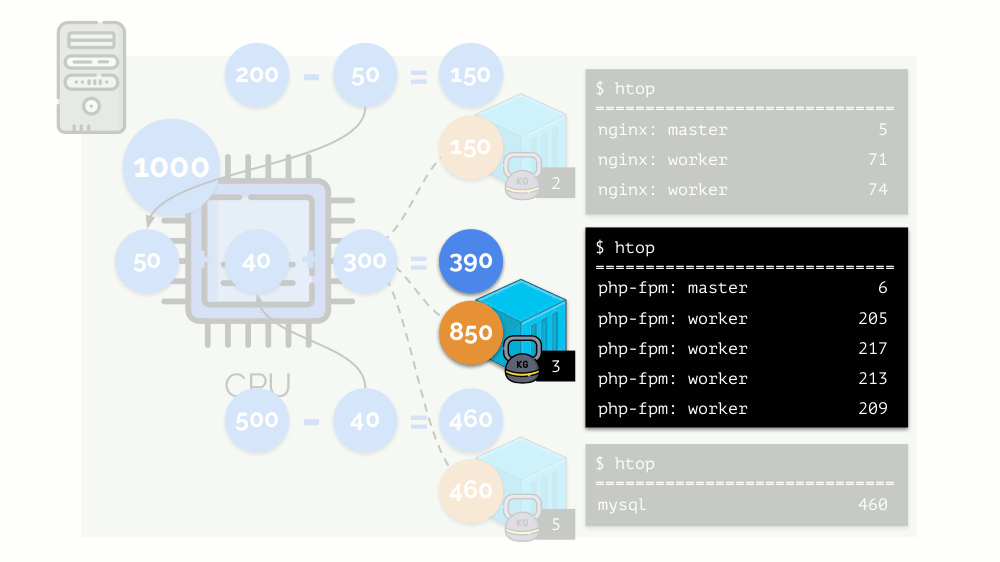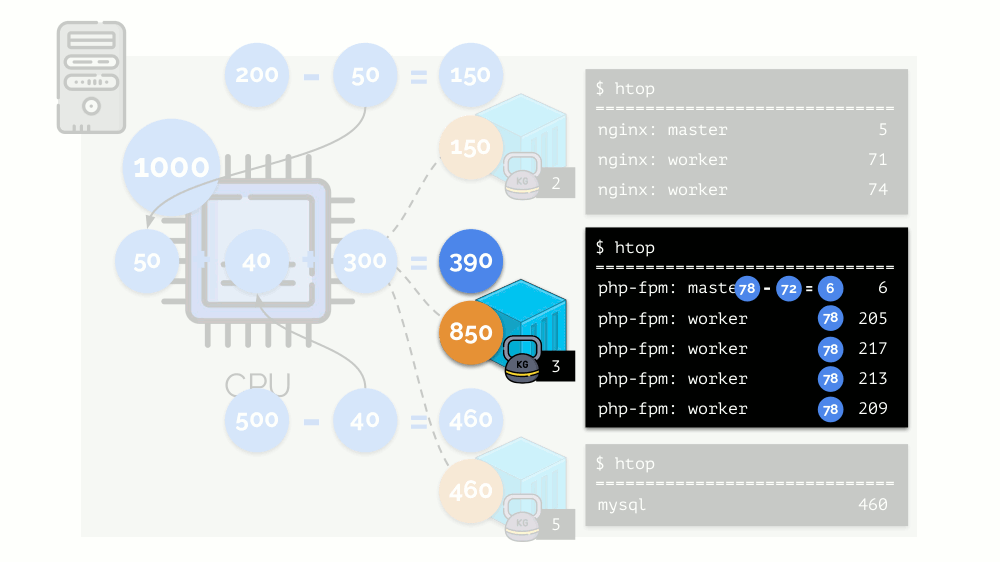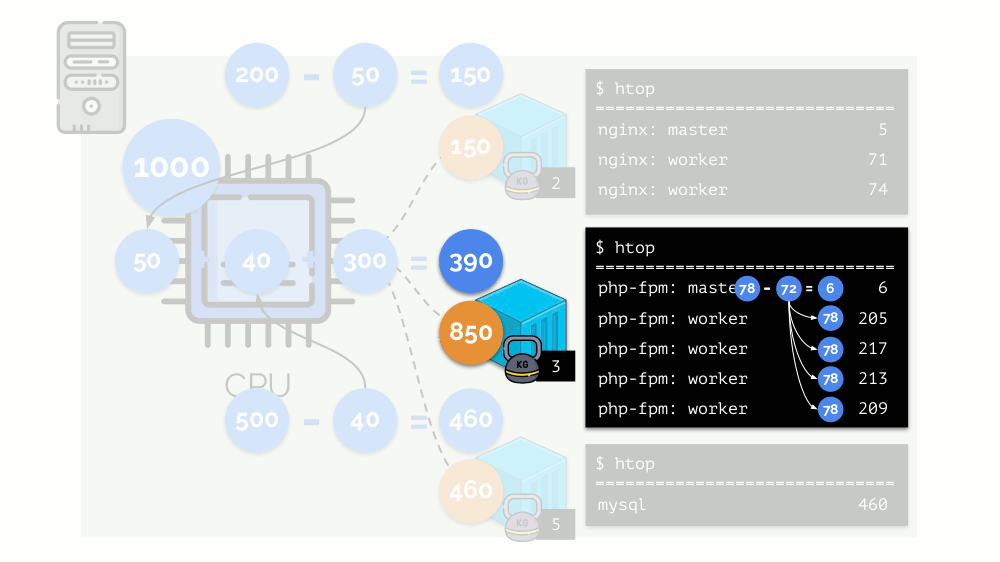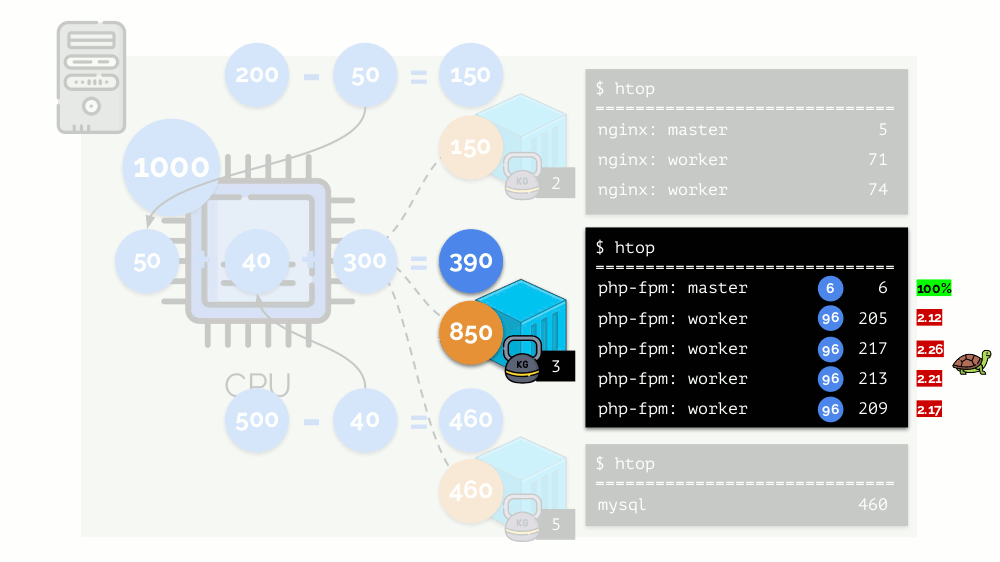
É assim que o agendador do CFS funciona. Os pesos que atribuímos aos contêineres serão chamados de
solicitações no futuro. Por que isso - veja abaixo.
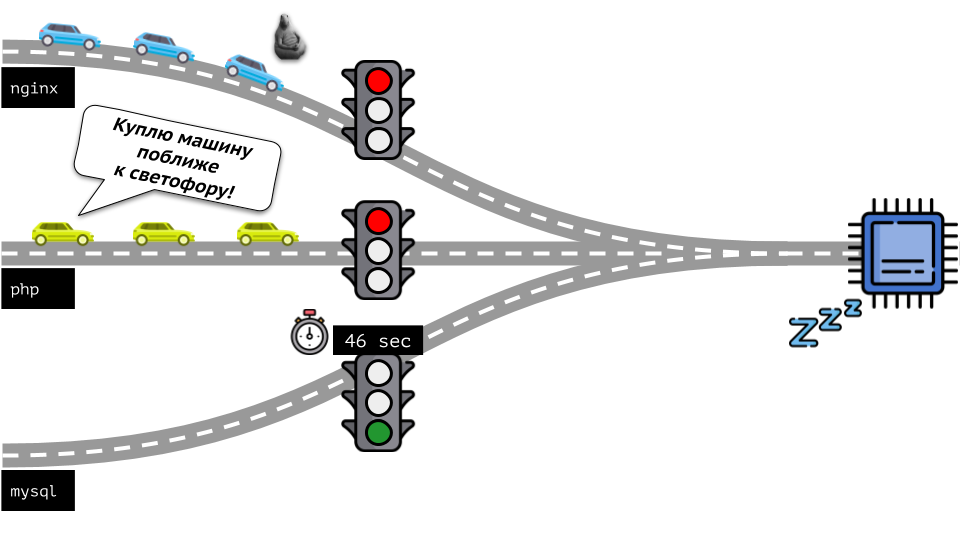
Vamos dar uma olhada em toda a situação do outro lado. Como você sabe, todas as estradas levam a Roma e, no caso de um computador, à CPU. Uma CPU, muitas tarefas - você precisa de um semáforo. A maneira mais fácil de gerenciar recursos é “semáforo”: eles dão a um processo um tempo de acesso fixo à CPU, depois ao próximo, etc.
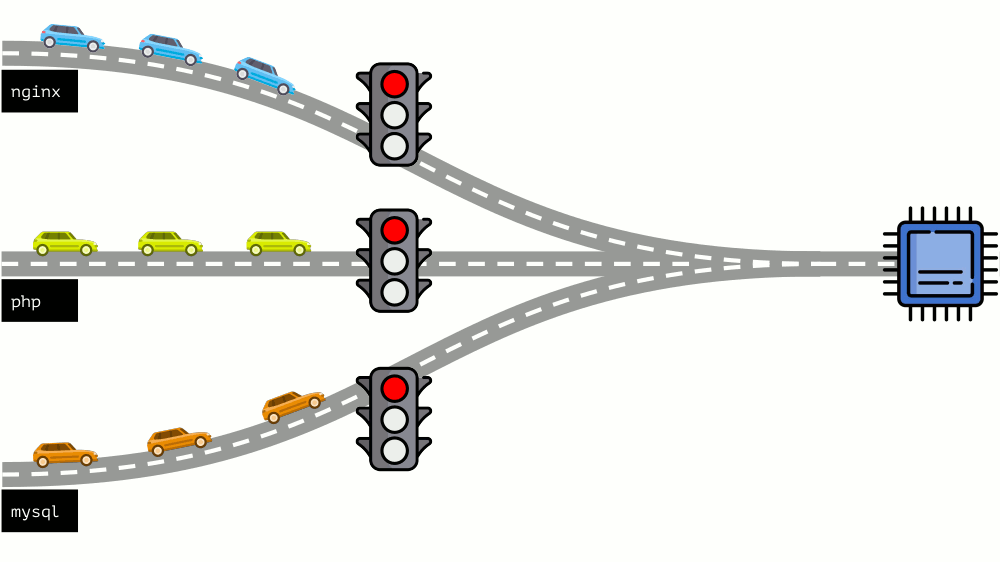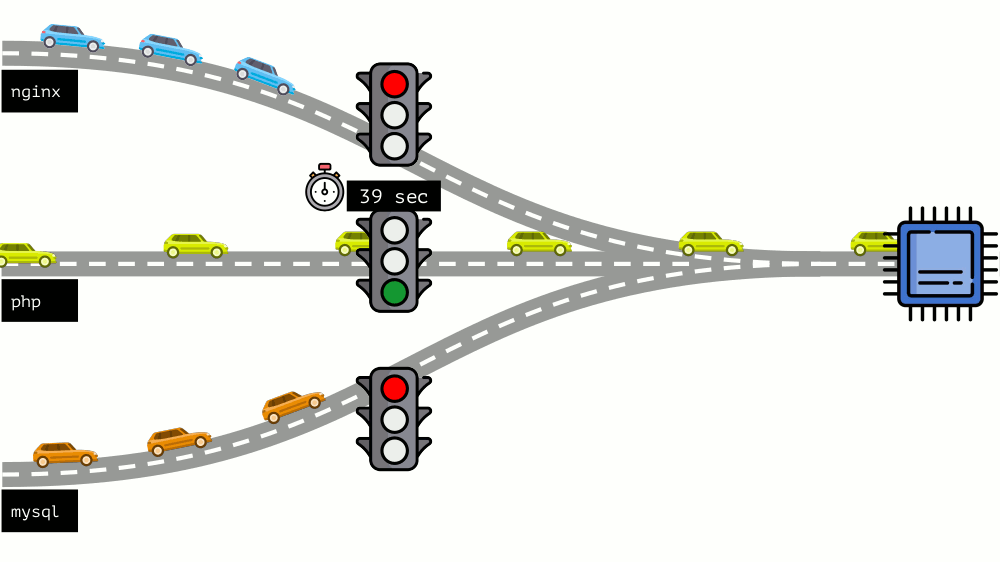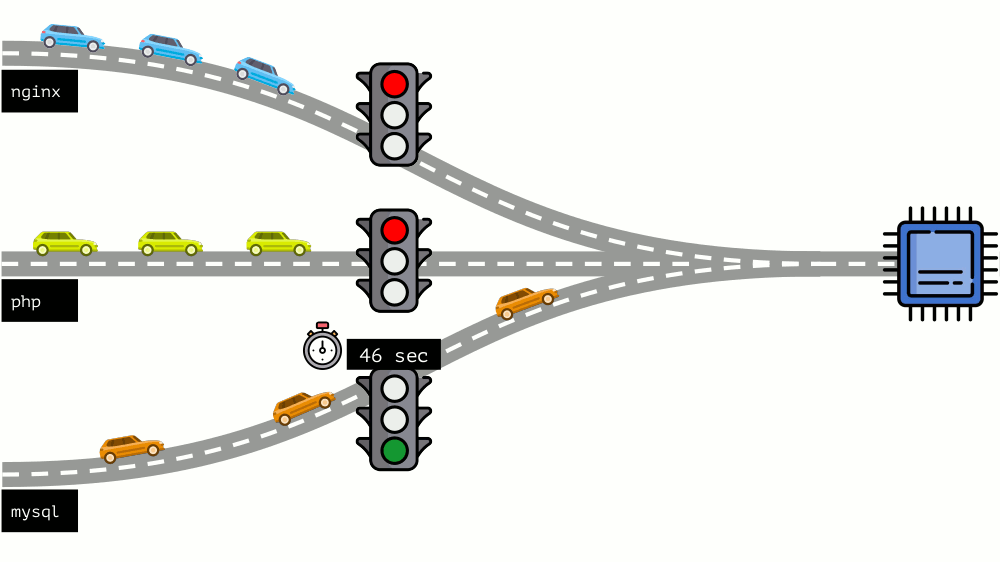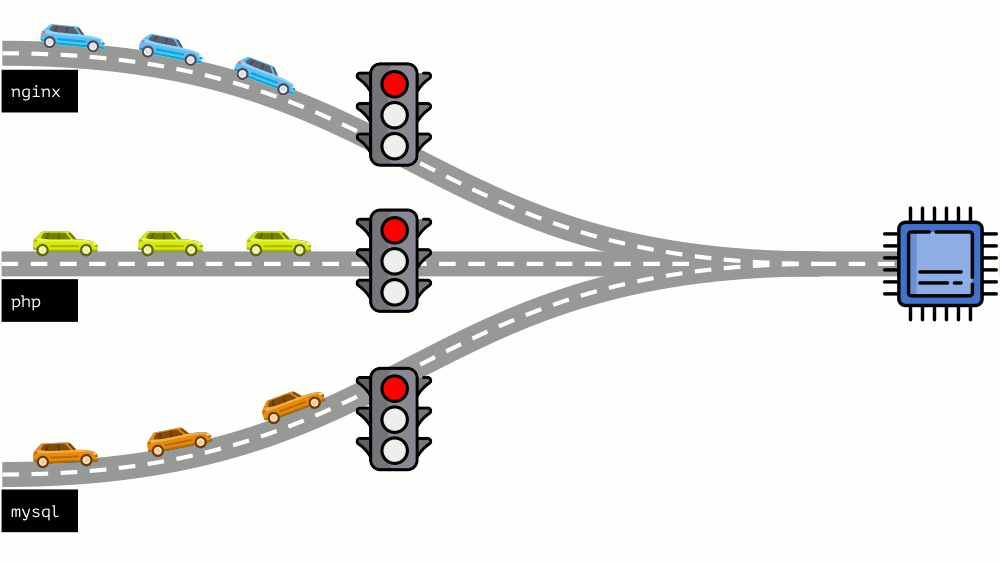
Essa abordagem é chamada de
limitação total . Lembre-se apenas como
limites . No entanto, se você distribuir limites para todos os contêineres, surge um problema: o mysql estava viajando pela estrada e em algum momento sua necessidade de uma CPU foi encerrada, mas todos os outros processos foram forçados a esperar enquanto a CPU estava
ociosa .
Vamos voltar ao kernel do Linux e sua interação com a CPU - a imagem geral é a seguinte:
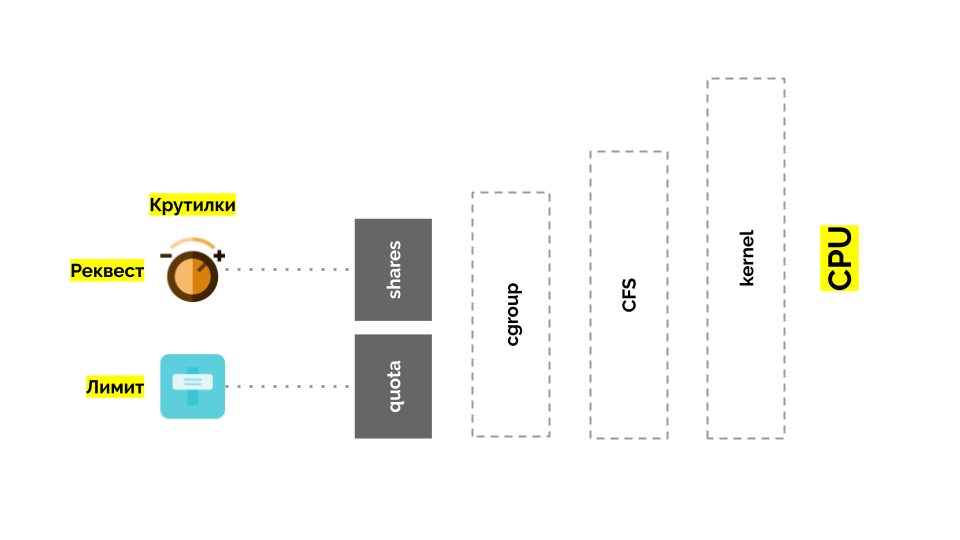
O Cgroup possui duas configurações - na verdade, são duas "reviravoltas" simples que permitem determinar:
- peso para o contêiner (solicitação) é ações ;
- uma porcentagem do tempo total da CPU para trabalhar em tarefas de contêiner (limites) é cota .
Como medir a CPU?
Existem diferentes maneiras:
- O que são papagaios , ninguém sabe - toda vez que você precisa concordar.
- O interesse é mais claro, mas relativo: 50% de um servidor com 4 núcleos e 20 núcleos são coisas completamente diferentes.
- Você pode usar os pesos já mencionados que o Linux conhece, mas eles também são relativos.
- A opção mais adequada é medir os recursos de computação em segundos . I.e. em segundos do tempo do processador em relação aos segundos do tempo real: eles gastaram 1 segundo do tempo do processador em 1 segundo real - este é um núcleo inteiro da CPU.
Para facilitar ainda mais, eles começaram a medir diretamente nos
núcleos , significando o tempo da CPU em relação ao real. Como o Linux entende pesos em vez de tempo / núcleos do processador, era necessário um mecanismo de conversão de um para o outro.
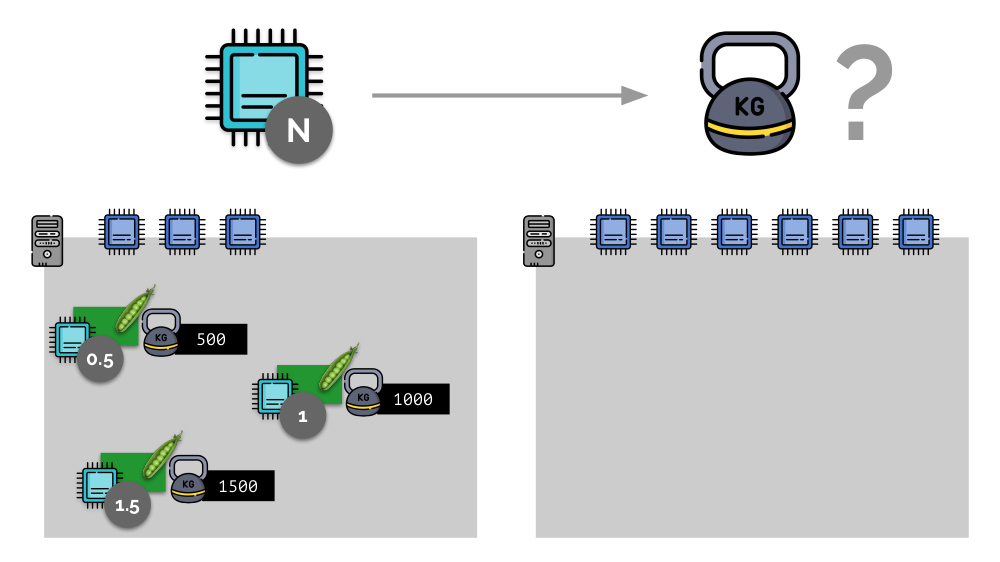
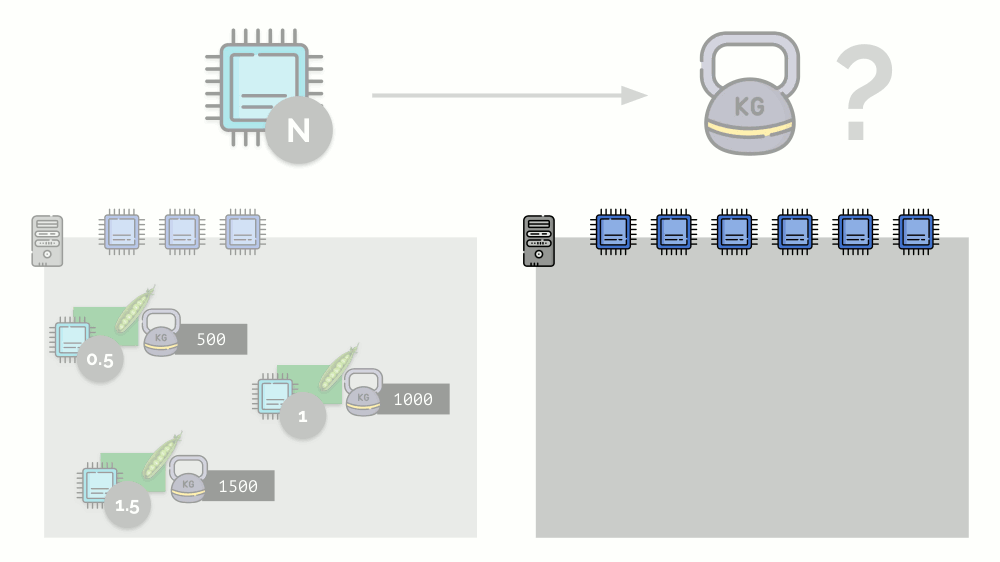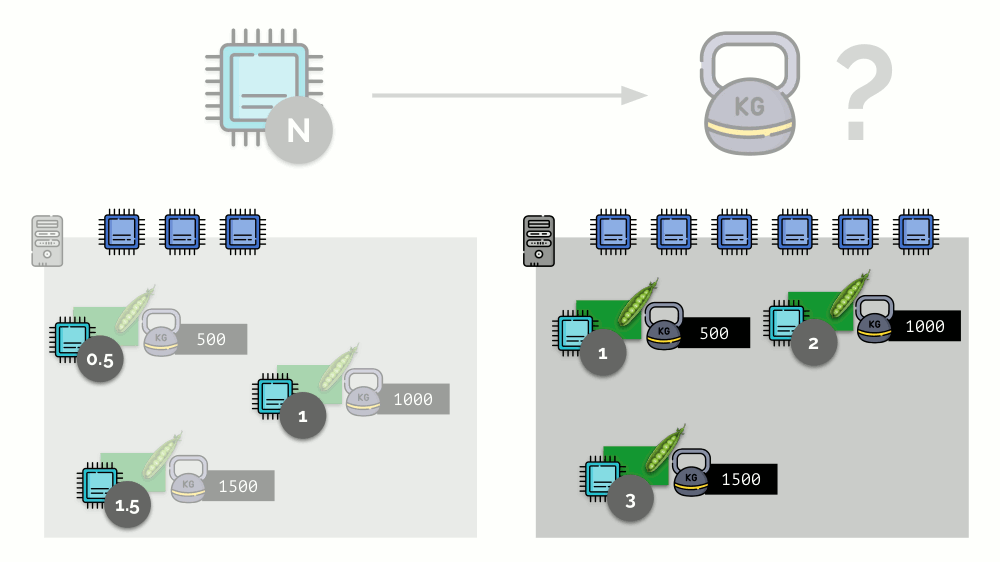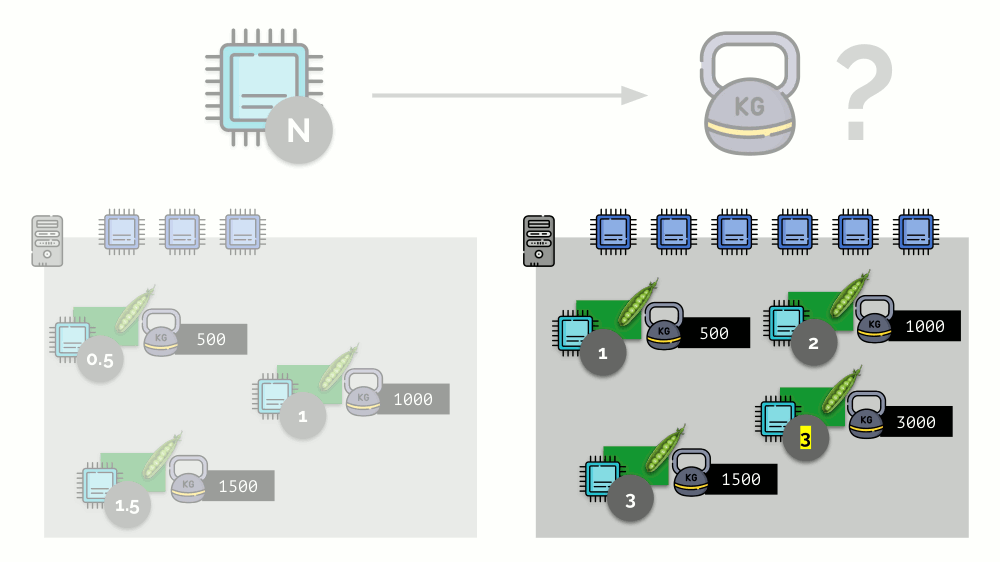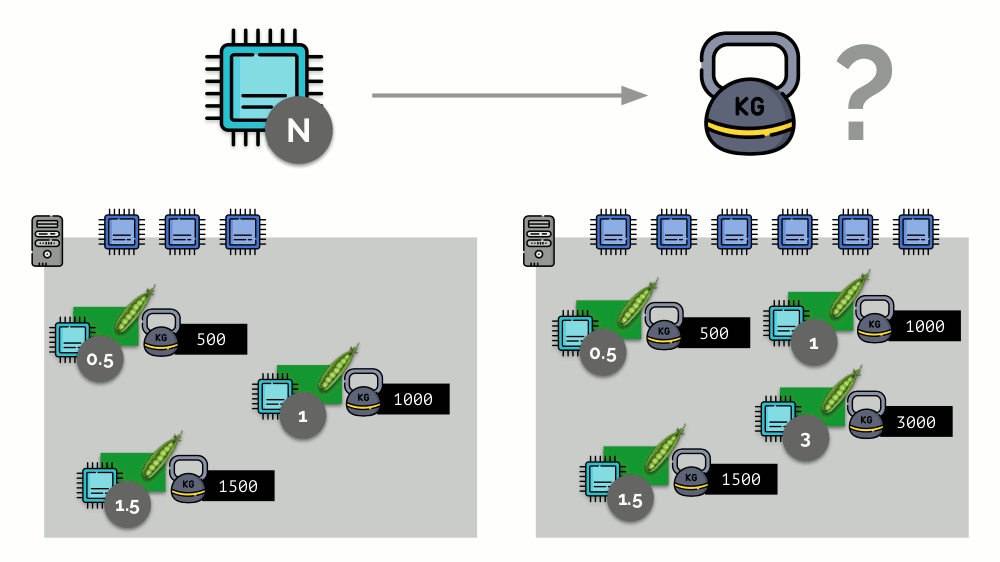
Considere um exemplo simples com um servidor com 3 núcleos de CPU, em que três pods selecionam pesos (500, 1000 e 1500) que são facilmente convertidos nas partes correspondentes dos núcleos alocados a eles (0,5, 1 e 1,5).
Se você pegar um segundo servidor, onde haverá o dobro de núcleos (6), e colocar os mesmos pods lá, a distribuição de núcleos poderá ser facilmente calculada simplesmente multiplicando por 2 (1, 2 e 3, respectivamente). Mas o ponto importante acontece quando o quarto pod aparece neste servidor, cujo peso é de 3000. Por conveniência, ele retira alguns recursos da CPU (metade dos núcleos) e o restante dos pods os recontam (metade):
Kubernetes e recursos de CPU
No Kubernetes, os recursos da CPU geralmente são medidos em
mili-núcleos , ou seja, 0,001 kernels são tomados como peso base.
(A mesma coisa na terminologia Linux / cgroups é chamada compartilhamento de CPU, embora, para ser mais preciso, 1000 CPU = 1024 compartilhamentos de CPU.) O K8s se certifica de não colocar mais pods no servidor do que os recursos da CPU para a soma de pesos. todos os pods.
Como está indo isso? Quando um servidor é adicionado a um cluster Kubernetes, ele informa quantos núcleos de CPU estão disponíveis para ele. E ao criar um novo pod, o agendador do Kubernetes sabe quantos núcleos esse pod precisa. Assim, o pod será definido no servidor, onde há núcleos suficientes.
O que acontecerá se a solicitação
não for especificada (ou seja, o pod não determina o número de kernels necessários)? Vamos ver como o Kubernetes geralmente conta os recursos.
O pod pode especificar solicitações (planejador CFS) e limites (lembra do semáforo?):
- Se forem iguais, a classe de QoS garantida é atribuída ao pod. Essa quantidade de grãos sempre disponíveis para ele é garantida.
- Se a solicitação for menor que o limite, a classe QoS poderá ser estourada . I.e. esperamos que o pod, por exemplo, sempre use 1 núcleo, mas esse valor não é uma limitação para ele: às vezes, o pod pode usar mais (quando houver recursos livres no servidor para isso).
- Também há a melhor classe de QoS de esforço - aqueles pods para os quais a solicitação não está especificada pertencem a ela. Os recursos são dados a eles por último.
A memória
A situação é semelhante com a memória, mas um pouco diferente - afinal, a natureza desses recursos é diferente. Em geral, a analogia é a seguinte:
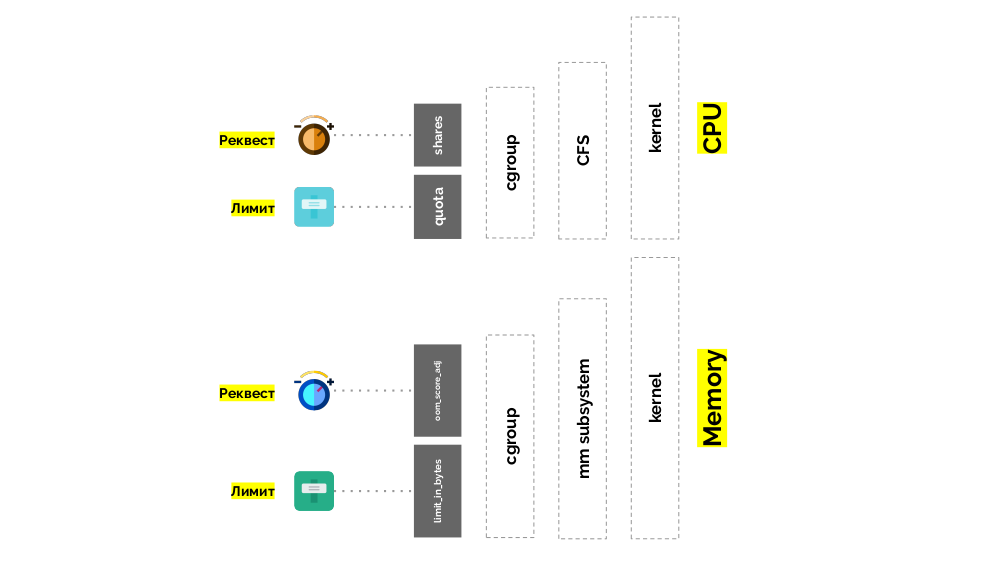
Vamos ver como as solicitações são implementadas na memória. Deixe os pods viverem no servidor, alterando a memória consumida, até que um deles fique tão grande que a memória acabe. Nesse caso, o assassino do OOM aparece e mata o maior processo:
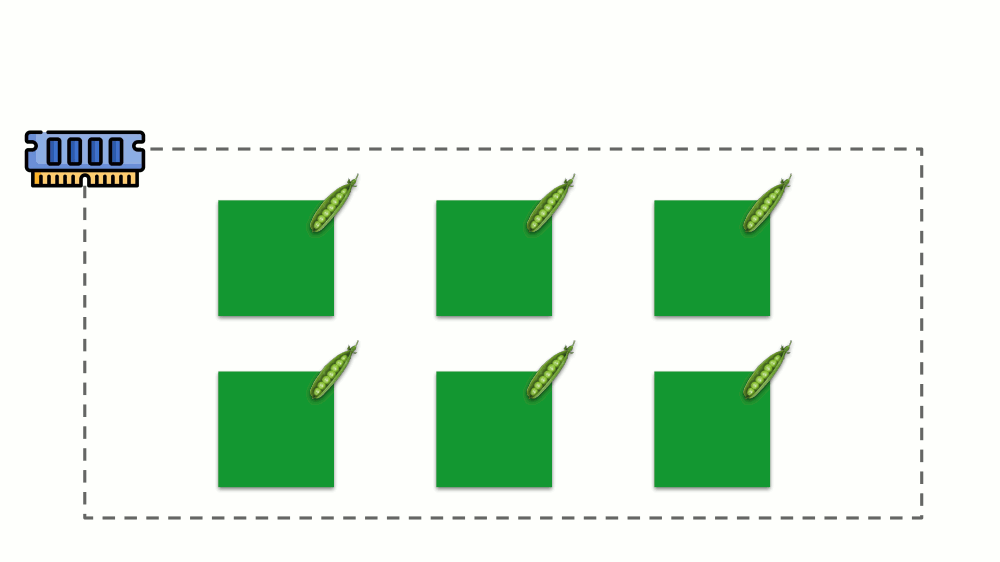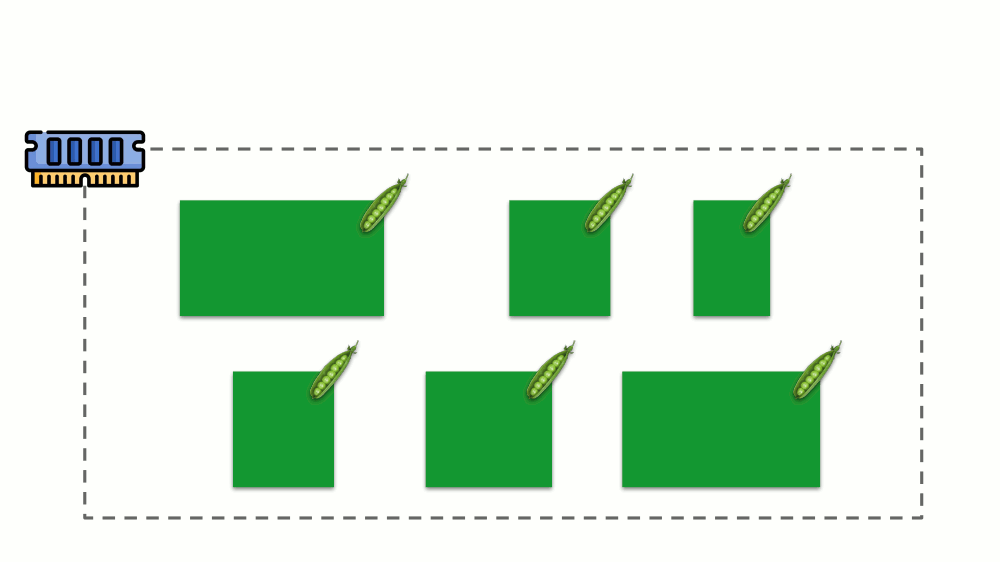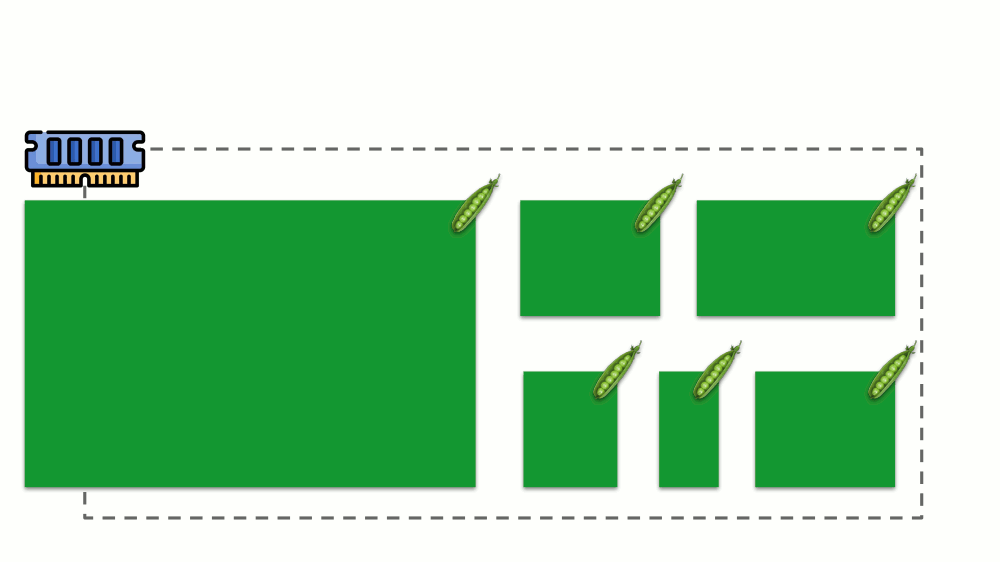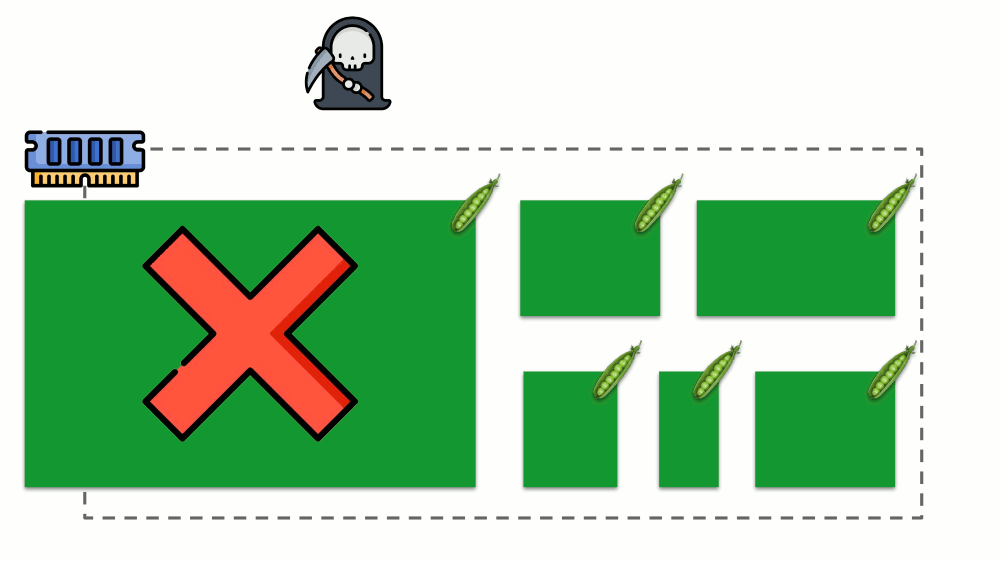
Isso nem sempre nos convém, portanto, é possível regular quais processos são importantes para nós e não devem ser eliminados. Para fazer isso, use o parâmetro
oom_score_adj .
Vamos voltar às classes de QoS da CPU e fazer uma analogia com os valores oom_score_adj, que determinam as prioridades de consumo de memória para os pods:
- O valor mais baixo oom_score_adj de um pod é -998, o que significa que esse pod deve ser eliminado em último lugar, isso é garantido .
- O maior - 1000 - é o melhor esforço , essas cápsulas são mortas antes de qualquer outra pessoa.
- Para calcular o restante dos valores ( expansível ), existe uma fórmula cuja essência se resume ao fato de que quanto mais o pod solicitou recursos, menor a chance de que ele seja eliminado.

O segundo "toque" -
limit_in_bytes - para limites. Tudo é mais simples: simplesmente atribuímos a quantidade máxima de memória a ser emitida e aqui (ao contrário da CPU) não há dúvida em que medida (memória) é medida.
Total
Solicitações e
limits são definidos para cada pod no Kubernetes - ambos os parâmetros para a CPU e para a memória:
- com base em solicitações, o agendador Kubernetes funciona, que distribui os pods pelos servidores;
- com base em todos os parâmetros, a classe QodS do pod é determinada;
- Os pesos relativos são calculados com base em solicitações de CPU;
- Com base em solicitações de CPU, um agendador CFS está configurado;
- Com base em solicitações de memória, o OOM killer está configurado;
- Com base nos limites da CPU, um “semáforo” é configurado;
- com base nos limites de memória, um limite é definido no cgroup.
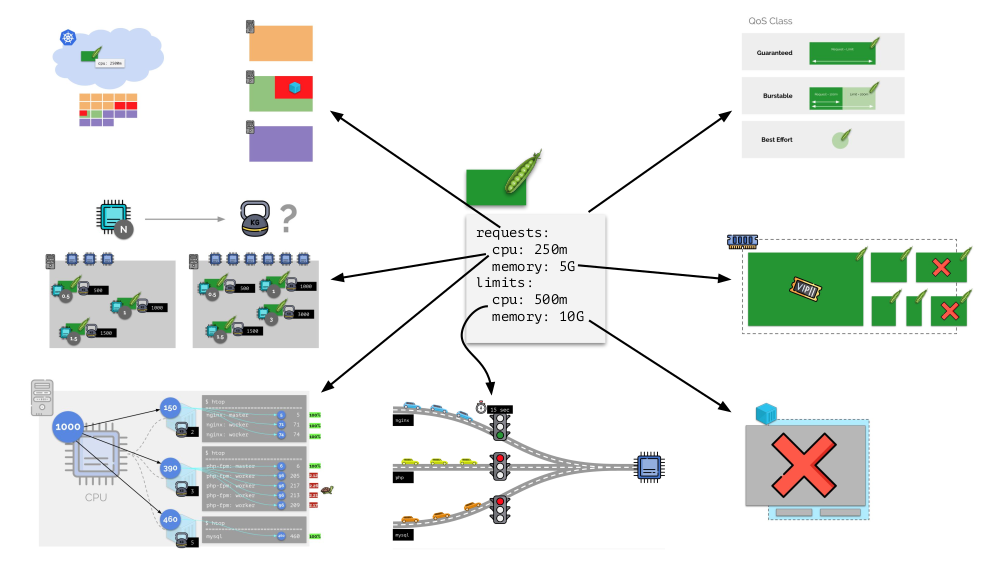
Em geral, esta imagem responde a todas as perguntas sobre como ocorre a parte principal do gerenciamento de recursos no Kubernetes.
Escalonamento automático
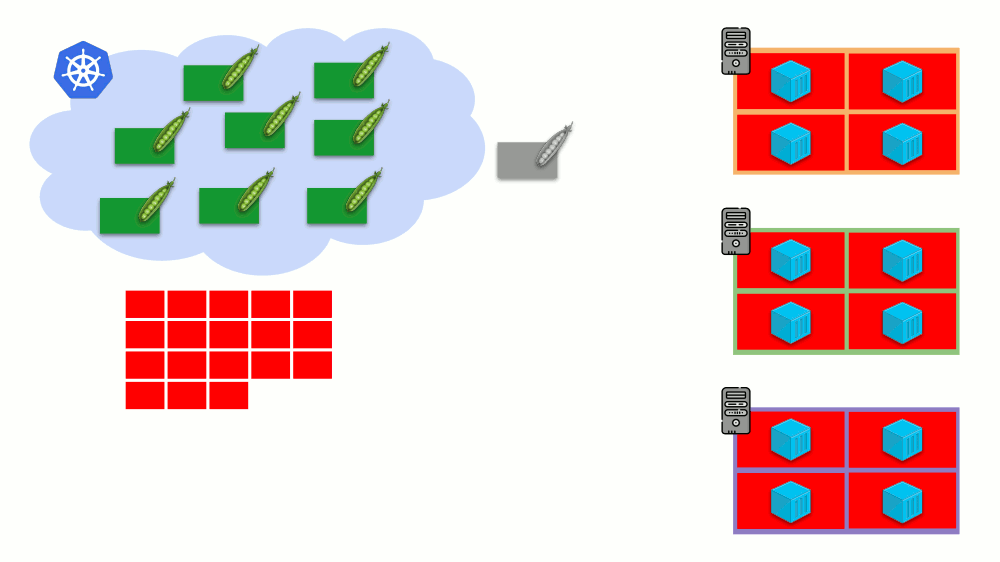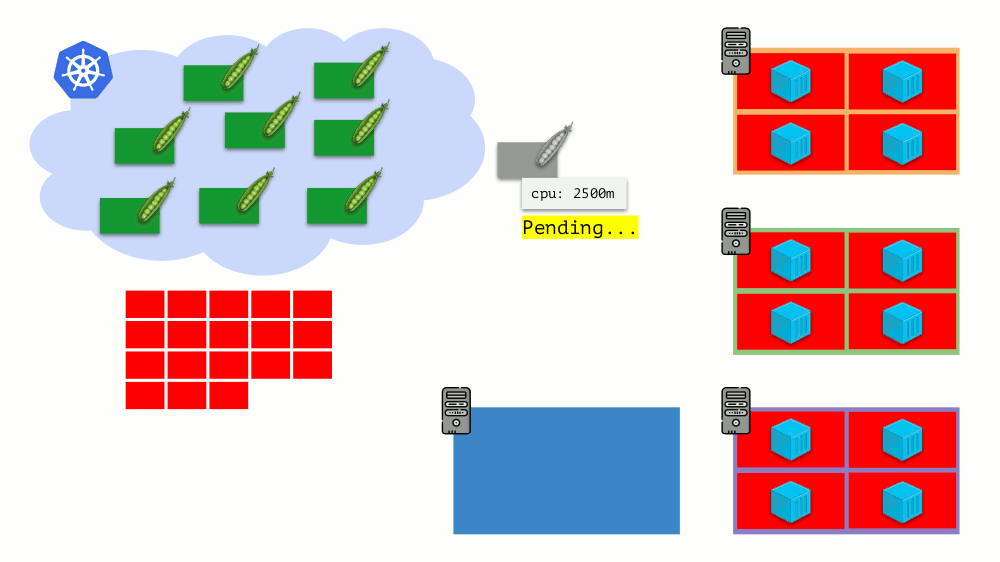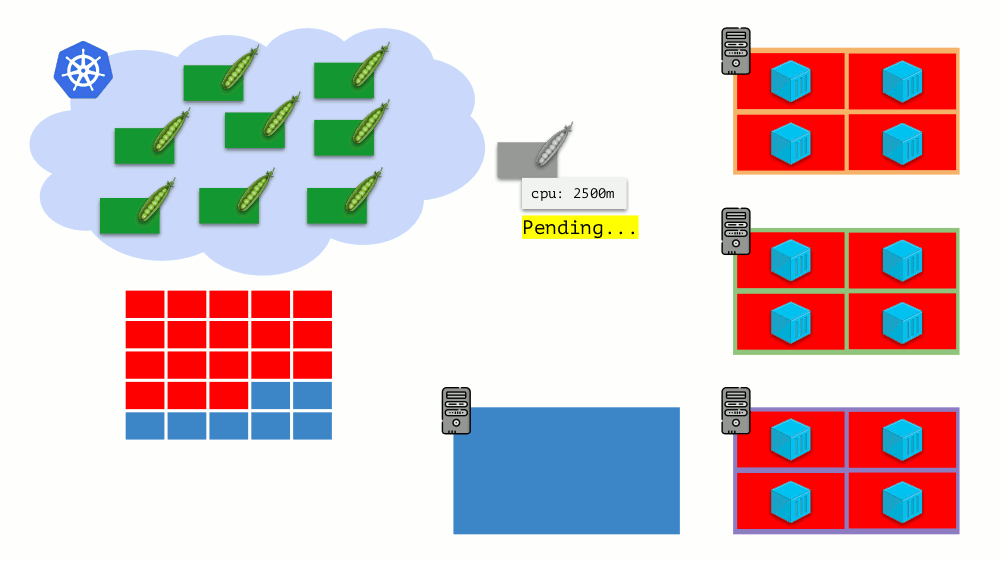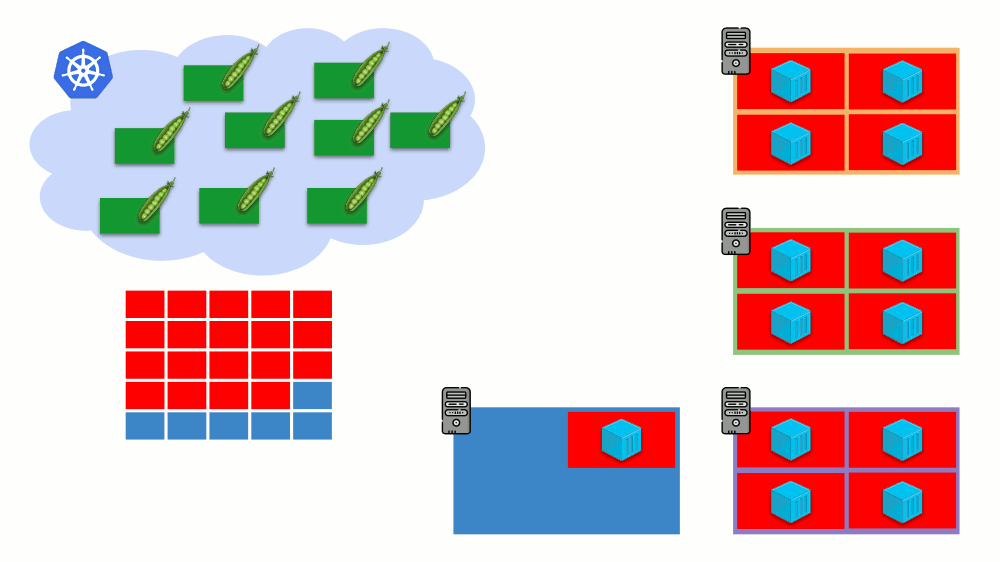
Autoescalador de cluster K8s
Imagine que o cluster inteiro já esteja ocupado e um novo pod deve ser criado. Embora o pod não possa aparecer, ele fica no status
Pendente . Para que apareça, podemos conectar um novo servidor ao cluster ou ... colocar cluster-autoscaler, o que fará isso por nós: solicite uma máquina virtual do provedor de nuvem (por solicitação da API) e conecte-a ao cluster, após o qual o pod será adicionado .
Esse é o dimensionamento automático do cluster Kubernetes, que funciona muito bem (em nossa experiência). No entanto, como em outros lugares, existem algumas nuances aqui ...
Enquanto aumentávamos o tamanho do cluster, tudo estava bem, mas o que acontece quando o cluster
começou a ser liberado ? O problema é que a migração de pods (para liberar hosts) é tecnicamente difícil e cara em termos de recursos. Kubernetes tem uma abordagem completamente diferente.
Considere um cluster de 3 servidores nos quais há implantação. Ele tem 6 pods: agora são 2 para cada servidor. Por alguma razão, queríamos desativar um dos servidores. Para fazer isso, use o comando
kubectl drain , que:
- proíbe o envio de novos pods para este servidor;
- remova os pods existentes no servidor.
Como o Kubernetes monitora a manutenção do número de pods (6), ele os
recriará simplesmente em outros nós, mas não no desconectado, pois já está marcado como inacessível para a colocação de novos pods. Esta é a mecânica fundamental para o Kubernetes.

No entanto, há uma nuance aqui. Em uma situação semelhante para StatefulSet (em vez de Implantação), as ações serão diferentes. Agora já temos um aplicativo com estado - por exemplo, três pods com MongoDB, um dos quais teve algum tipo de problema (os dados foram incorretos ou algum outro erro que impedia que o pod fosse iniciado corretamente). E, novamente, decidimos desconectar um servidor. O que vai acontecer?
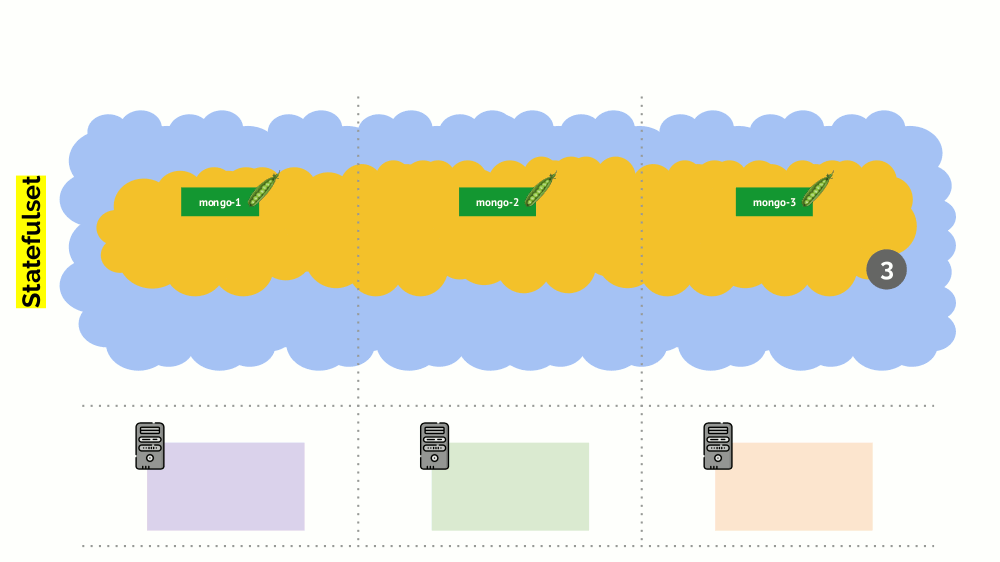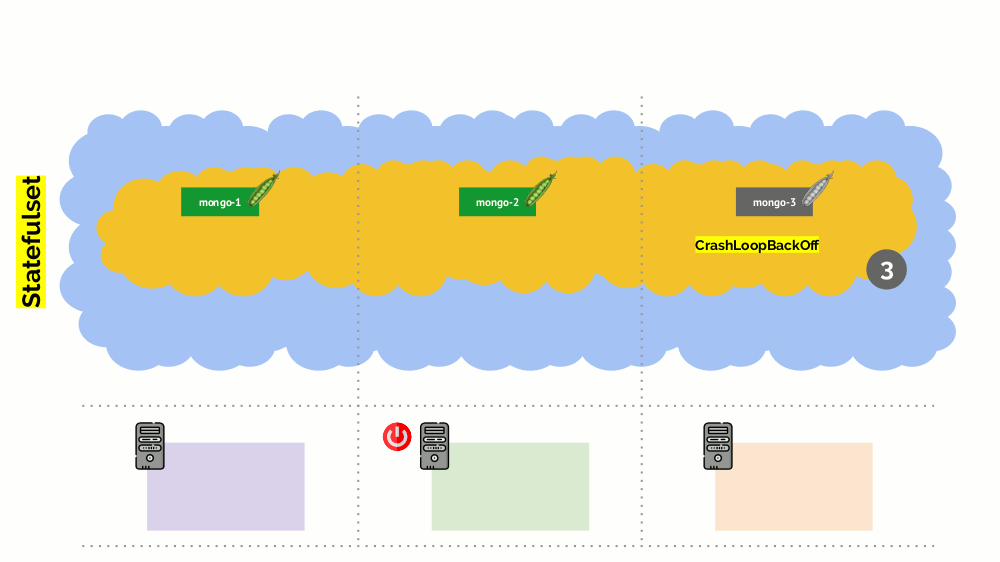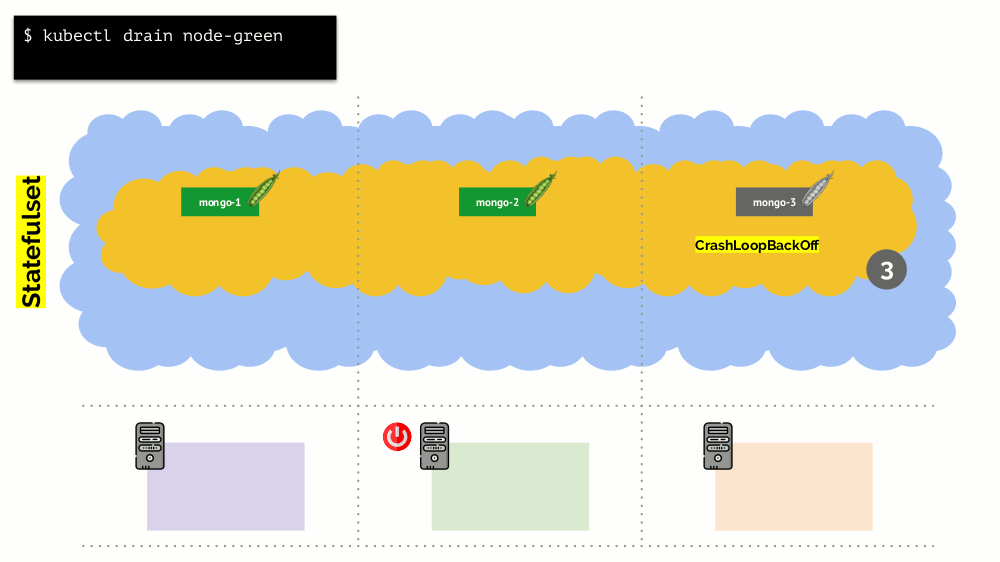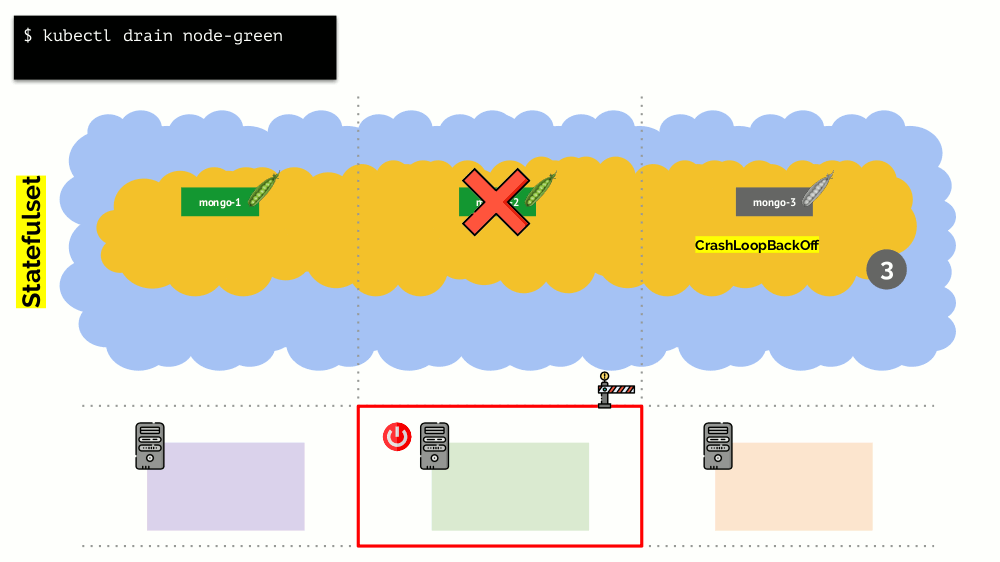
O MongoDB
pode morrer porque precisa de um quorum: para um cluster de três instalações, pelo menos duas devem funcionar. No entanto, isso
não acontece - graças ao
PodDisruptionBudget . Este parâmetro determina o número mínimo necessário de pods de trabalho. Sabendo que um dos pods com MongoDB não está mais funcionando, e como minAvailable está definido para MongoDB em
minAvailable: 2 , o Kubernetes não permitirá que você remova o pod.
Conclusão: para mover (e realmente recriar) pods corretamente quando o cluster for lançado, você precisará configurar o PodDisruptionBudget.
Escala horizontal
Considere uma situação diferente. Há um aplicativo em execução como Implantação no Kubernetes. O tráfego do usuário chega aos seus pods (por exemplo, existem três), e medimos um certo indicador neles (por exemplo, carga da CPU). Quando a carga aumenta, corrigimos o cronograma e aumentamos o número de pods para distribuir solicitações.
Hoje, no Kubernetes, você não precisa fazer isso manualmente: você pode aumentar / diminuir automaticamente o número de pods, dependendo dos valores dos indicadores de carga medidos.
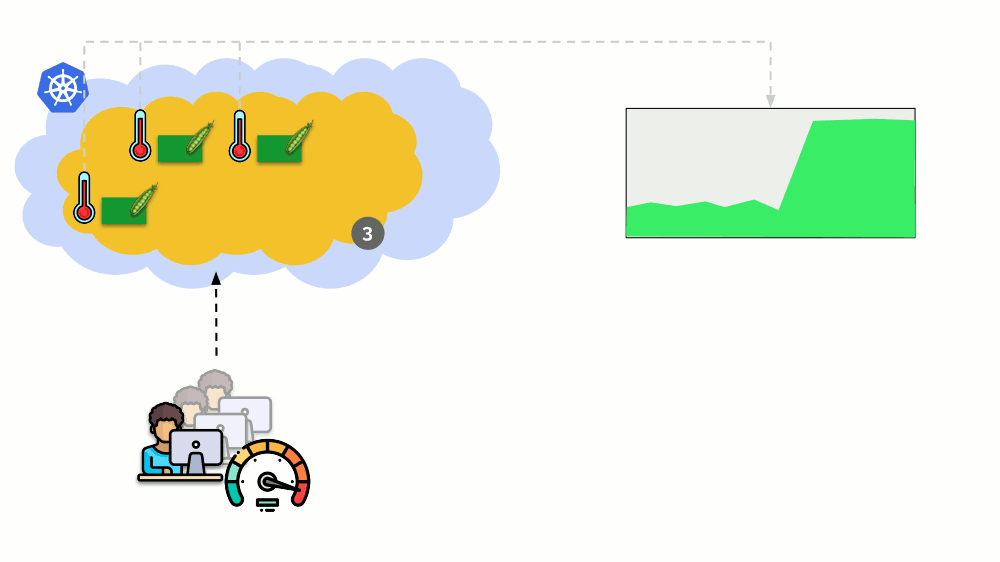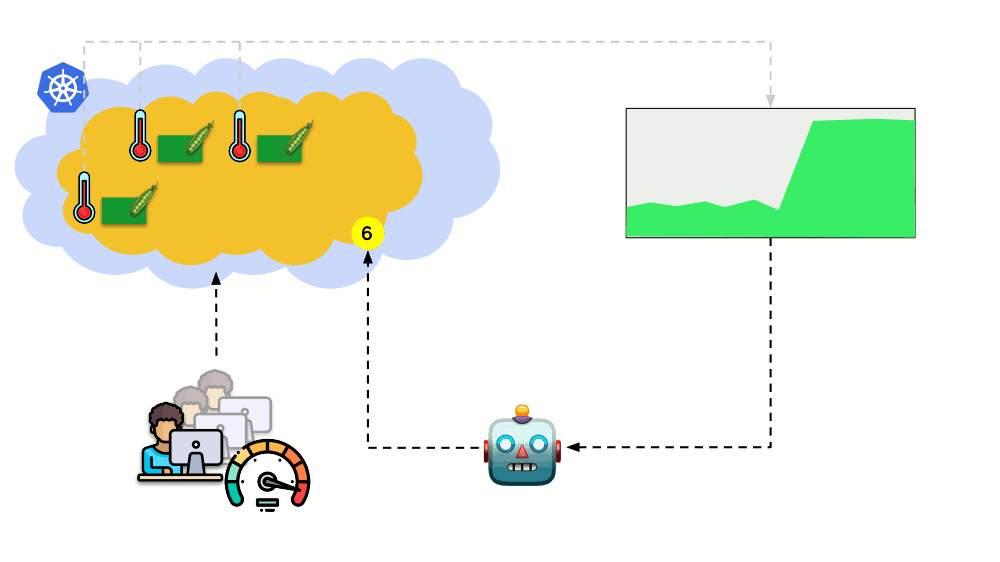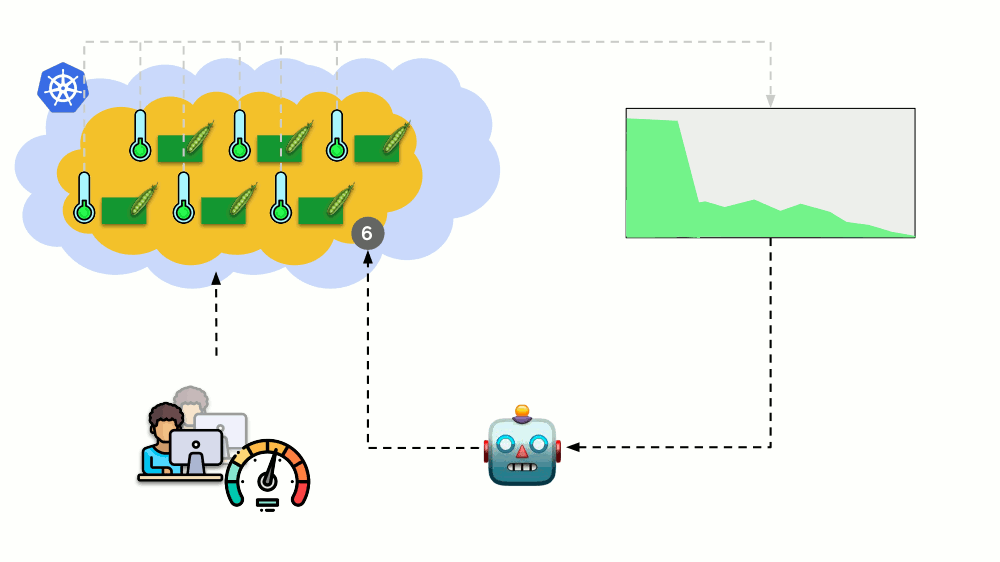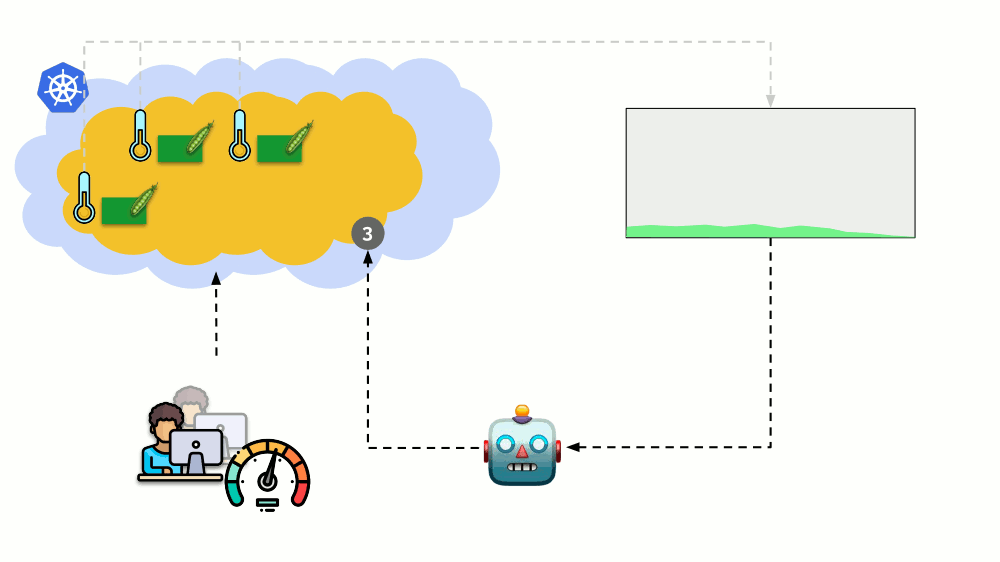
As principais perguntas aqui são o
que exatamente medir e
como interpretar os valores obtidos (para tomar uma decisão sobre a alteração do número de pods). Você pode medir muito:

Como fazer isso tecnicamente - colete métricas etc. - Falei detalhadamente no relatório sobre
monitoramento e Kubernetes . E o principal conselho para escolher os parâmetros ideais é
experimentar !
Existe
um método USE (Utilização Saturação e Erros ), cujo significado é o seguinte. Em que base faz sentido escalar, por exemplo, php-fpm? Com base no fato de que os trabalhadores terminam, é a
utilização . E se os trabalhadores terminarem e novas conexões não forem aceitas - isso é
saturação . Ambos os parâmetros precisam ser medidos e, dependendo dos valores, a escala deve ser realizada.
Em vez de uma conclusão
O relatório tem uma continuação: sobre dimensionamento vertical e sobre como escolher os recursos certos. Falarei sobre isso em vídeos futuros em
nosso YouTube - inscreva-se para não perder!
Vídeos e slides
Vídeo da apresentação (44 minutos):
Apresentação do relatório:
PS
Outros relatórios do Kubernetes em nosso blog: