
Entrada
Ao longo dos anos desenvolvendo projetos de ML e DL, nosso estúdio acumulou uma grande base de códigos, muita experiência e idéias e conclusões interessantes. Ao iniciar um novo projeto, esse conhecimento útil ajuda você a iniciar pesquisas com mais confiança, reutilizar métodos úteis e obter os primeiros resultados mais rapidamente.
É muito importante que todos esses materiais não estejam apenas na mente dos desenvolvedores, mas também em forma legível no disco. Isso permitirá um treinamento mais eficaz dos novos funcionários, atualizá-los e mergulhar no projeto.
Obviamente, esse nem sempre foi o caso. Enfrentamos muitos problemas nos estágios iniciais
- Cada projeto foi organizado de maneira diferente, especialmente se eles foram iniciados por pessoas diferentes.
- Eles não acompanharam o que o código estava fazendo, como executá-lo e quem era o autor.
- Eles não usaram a virtualização no nível adequado, frequentemente impedindo que seus colegas instalassem bibliotecas existentes de uma versão diferente.
- As conclusões tiradas das cartas que se estabeleceram e morreram na montanha de cadernos de anotações foram esquecidas.
- Relatórios perdidos sobre os resultados e progresso do projeto.
Para resolver esses problemas de uma vez por todas, decidimos que precisamos trabalhar tanto em uma organização unificada e adequada do projeto quanto em virtualização, abstração de componentes individuais e reutilização de código útil. Gradualmente, todo o nosso progresso nessa área se transformou em uma estrutura independente - o oceano.
Cereja no bolo - os logs do projeto, que são agregados e transformados em um site bonito, coletados automaticamente usando um comando.
No artigo, mostraremos um pequeno exemplo artificial de quais partes o Ocean consiste e como usá-lo.
Por que oceano
No mundo da ML, existem outras opções que consideramos. Antes de tudo, precisamos mencionar o cookiecutter-data-science (a seguir CDS) como um inspirador ideológico. Vamos começar com o bom: o CDS não apenas oferece uma estrutura de projeto conveniente, mas também informa como gerenciar o projeto para que tudo fique bem - portanto, recomendamos que você discorde e analise as principais idéias principais dessa abordagem no artigo original do CDS .
Armado com o CDS no rascunho de trabalho, imediatamente trouxemos várias melhorias: adicionamos um conveniente registrador de arquivos, uma classe de coordenador responsável pela navegação no projeto e um gerador automático de documentação do Sphinx. Além disso, vários comandos foram enviados ao Makefile, de modo que mesmo um não iniciado nos detalhes do gerente de projeto era conveniente para executá-los.
No entanto, no processo, começaram a surgir as desvantagens da abordagem CDS:
- A pasta de dados pode aumentar, mas qual dos scripts ou blocos de anotações gera o próximo arquivo não está completamente claro. Em um grande número de arquivos, é fácil ficar confuso. Não está claro se, no âmbito da implementação da nova funcionalidade, é necessário usar alguns arquivos dos existentes, uma vez que a descrição ou documentação de sua finalidade não é armazenada em nenhum lugar.
- Nos dados, não há subpasta de recursos suficientes na qual você pode armazenar sinais: estatísticas calculadas, vetores e outras características a partir das quais diferentes representações finais dos dados seriam coletadas. Isso já foi notavelmente escrito em um post do blog.
- src é outra pasta com problemas. Possui funções relevantes para todo o projeto, por exemplo, preparando e limpando os dados do módulo src.data . Mas também existe o módulo src.models , que contém todos os modelos de todos os experimentos, e pode haver dezenas deles. Como resultado, o src é atualizado com muita frequência, expandindo-se com mudanças muito pequenas e, de acordo com a filosofia do CDS, após cada atualização, você precisa reconstruir o projeto, e este é também o momento ..., - bem, você entende.
- são apresentadas referências , mas ainda há uma pergunta em aberto: quem, quando e de que forma deve levar os materiais para lá. E você pode dizer muito no decorrer do projeto: que trabalho foi realizado, qual é o resultado deles, quais são os planos futuros.
Para resolver os problemas acima, a seguinte essência é apresentada em Ocean: experiment . Um experimento é um repositório de todos os dados envolvidos no teste de alguma hipótese. Isso pode incluir: quais dados foram usados, quais dados (artefatos) resultaram, a versão do código, o horário de início e término do experimento, o arquivo executável, parâmetros, métricas e logs. Algumas dessas informações podem ser rastreadas usando utilitários especiais, por exemplo, MLFlow. No entanto, a estrutura dos experimentos apresentados no Ocean é mais rica e flexível.
O módulo de uma experiência é o seguinte:
<project_root> └── experiments ├── exp-001-Tree-models │ ├── config <- yaml- │ ├── models <- │ ├── notebooks <- │ ├── scripts <- , , train.py predict.py │ ├── Makefile <- │ ├── requirements.txt <- │ └── log.md <- │ ├── exp-002-Gradient-boosting ...
Compartilhamos a base de código: o código bom reutilizável, relevante durante todo o projeto, permanece no módulo src do nível do projeto. Raramente é atualizado; portanto, com menos frequência, é necessário criar um projeto. E o módulo de scripts de um experimento deve conter código relevante apenas para o experimento atual. Assim, pode ser alterado com frequência: não afeta o trabalho dos colegas em outros experimentos.
Vamos considerar as possibilidades de nossa estrutura usando o exemplo de um projeto abstrato de ML / DL.
Fluxo de trabalho do projeto
Inicialização
Assim, o cliente - a polícia de Chicago - nos enviou os dados e a tarefa: analisar os crimes cometidos na cidade durante o período 2011-2017 e tirar conclusões.
Vamos começar! Vamos ao terminal e executamos o comando:
ocean project new -n Crimes
A estrutura criou a pasta do projeto de crimes correspondente. Nós olhamos para sua estrutura:
crimes ├── crimes <- src- , ├── config <- , ├── data <- ├── demos <- ├── docs <- Sphinx- ├── experiments <- ├── notebooks <- EDA ├── Makefile <- ├── log.md <- ├── README.md └── setup.py
O coordenador do módulo com o mesmo nome, que já está escrito e pronto, ajuda a navegar por todas essas pastas. Para usá-lo, o projeto precisa ser montado:
make package
Isso é um bug : se os comandos make não quiserem ser executados, adicione o sinalizador -B a eles, por exemplo, "make -B package". Isso se aplica a todos os outros exemplos.
Logs e experimentos
Começamos com o fato de que os dados do cliente, no nosso caso, o arquivo crimes.csv , são colocados na pasta data / raw .
No site de Chicago, existem mapas com as divisões da cidade em postos ("batidas" - o menor local para o qual um carro-patrulha é designado), setores ("setores", que consistem em 3-5 postos), seções ("distritos", consistem em 3 setores), distritos administrativos (“enfermarias”) e, finalmente, áreas públicas (“área comunitária”). Esses dados podem ser usados para visualização. Ao mesmo tempo, os arquivos json com as coordenadas das seções de polígono de cada tipo não são dados enviados pelo cliente, portanto, os colocamos em dados / externos .
Em seguida, você precisa introduzir o conceito de experimento. Tudo é simples: consideramos uma tarefa separada como um experimento separado. Precisa analisar / bombear dados e prepará-los para uso futuro? Vale a pena fazer um experimento. Preparar muitas visualizações e relatórios? Experiência separada. Teste a hipótese preparando um modelo? Bem, você entendeu.
Para criar nosso primeiro experimento a partir da pasta do projeto, realizamos:
ocean exp new -n Parsing -a ivanov
Agora, uma nova pasta com o nome exp-001-Parsing apareceu na pasta crimes / experimentos , cuja estrutura é dada acima.
Depois disso, você precisa examinar os dados. Para fazer isso, crie um laptop na pasta de cadernos correspondente. No Surf, seguimos a nomeação "número do laptop - nome", e o laptop criado será chamado 001-Parse-data.ipynb . Dentro, prepararemos dados para trabalhos futuros.
Código de preparação de dados import numpy as np import pandas as pd pd.options.display.max_columns = 100
Para que seus colegas estejam cientes do que você fez e se seus resultados podem ser usados por eles, é necessário comentar sobre isso no log: o arquivo log.md. A estrutura do log (que é essencialmente um arquivo de remarcação familiar) é a seguinte:

As peças preenchidas à mão são destacadas em cores. O principal meta do experimento (cor clara da ameixa) é o autor e a explicação de sua tarefa, o resultado para o qual o experimento está sendo realizado. Links para dados, obtidos e gerados no processo (cor verde), ajudam a monitorar arquivos de dados e a entender quem, dentro do quê e por que os usa. O próprio registro (cor amarela) informa o resultado do trabalho, as conclusões e o raciocínio. Todos esses dados posteriormente se tornarão o conteúdo do site de log do projeto.
A seguir, é apresentado o estágio da EDA ( Análise Exploratória de Dados - “análise de dados de inteligência” ). Talvez seja conduzido por pessoas diferentes e, é claro, precisaremos de resultados na forma de relatórios e gráficos posteriormente. Esses argumentos são uma ocasião para criar um novo experimento. Realizamos:
ocean exp new -n Eda -a ivanov
Na pasta de blocos de anotações do experimento, crie o bloco de anotações 001-EDA.ipynb . O código completo não faz sentido, mas não é necessário, por exemplo, pelos seus colegas. Mas você precisa de gráficos e conclusões. Um monte de código sai no notebook e, por si só, não é o que se deseja mostrar ao cliente. Portanto, registraremos nossas descobertas e informações no arquivo log.md e salvaremos as imagens dos gráficos nas referências .
Aqui, por exemplo, há um mapa das áreas seguras de Chicago, se o destino o levar até lá:
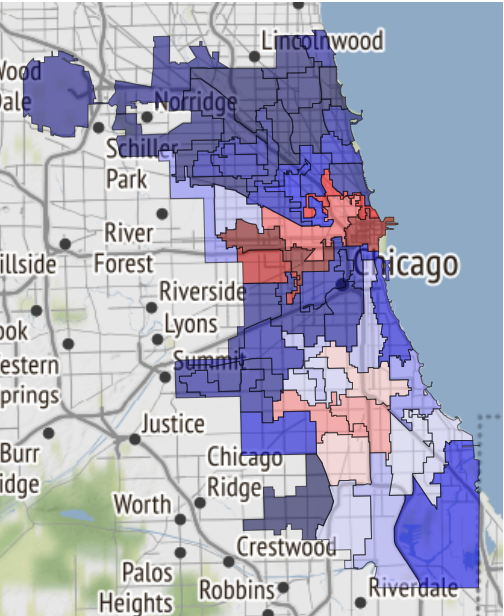
Foi apenas recebido em um caderno e transferido para referências .
A seguinte entrada foi adicionada ao log:
19.02.2019, 18:15 EDA conclusion: * The most common and widely spread crimes are theft (including burglary), battery and criminal damage done with firearms. * In 1 case out of 4 the suspect will be set free after detention. [!Criminal activity in different beats of the city](references/beats_activity.jpg) Actual exploration you can check in [the notebook](notebooks/001-Eda.ipynb)
Observe: o gráfico foi projetado exatamente como inserir uma imagem em um arquivo md. E se você deixar um link para o notebook, ele será convertido para o formato html e salvo como uma página separada no site.
Para coletá-lo dos logs de experimentos, executamos o seguinte comando no nível do projeto:
ocean log new
Depois disso, a pasta crime / project_log é criada e index.html nela é o log do projeto.
Isso é um bug : quando exibido no Jupyter, o site é implementado como um iframe para maior segurança e, portanto, as fontes não são exibidas corretamente. Portanto, usando o Ocean, você pode criar imediatamente um arquivo com uma cópia do site, para que seja conveniente baixá-lo e abri-lo em um computador local ou enviá-lo por correio. Assim:
ocean log archive [-n NAME] [-p PASSWORD]
A documentação
Vamos dar uma olhada na criação de documentação usando o Sphinx. Crie uma função no arquivo crimes / my_cool_module.py e documente-a. Observe que o Sphinx usa o formato de texto reestruturado (RST):
my_cool_module.py def my_super_cool_random(max_value): ''' Returns a random number from [0; max_value) interval. Considers the number to be taken from uniform distribution. :param max_value: Maximum value that defines range. :returns: Random number. ''' return 4
E então tudo é muito simples: no nível do projeto, executamos a equipe de geração de documentação e você está pronto:
ocean docs new
Pergunta da platéia : Por que, se coletamos o projeto através do make , você precisa coletar a documentação através do ocean ?
Resposta : o processo de geração da documentação não é apenas a execução do comando Sphinx, que pode ser colocado em make . A Ocean assume a varredura do catálogo de seus códigos-fonte, cria um índice para o Sphinx a partir deles e somente então o próprio Sphinx começa a trabalhar.
A documentação html pronta espera por você no caminho crimes / docs / _build / html / index.html . E nosso módulo com comentários já apareceu lá:

Modelos
O próximo passo é construir o modelo. Realizamos:
ocean exp new -n Model -a ivanov
E dessa vez, dê uma olhada no que está na pasta de scripts dentro do experimento. O arquivo train.py está em branco para o processo de treinamento futuro. O arquivo já contém o código padrão que faz várias coisas ao mesmo tempo.
- A função de aprendizado utiliza vários caminhos de arquivo:
- Para o arquivo de configuração, para o qual é razoável transferir os parâmetros do modelo, os parâmetros de treinamento e outras opções convenientes para o controle externo, sem se aprofundar no código.
- Para o arquivo de dados.
- O caminho para o diretório em que você deseja salvar o dump do modelo final.
- Rastreia as métricas obtidas no processo de aprendizagem no mlflow . Tudo o que foi solicitado pode ser visualizado por meio do mlflow da interface do usuário executando o comando
make dashboard na pasta da experiência. - Envia um alerta ao seu telegrama de que o processo de aprendizado foi concluído. Para implementar esse mecanismo, o bot Alarmerbot foi usado . Para fazer isso funcionar, você precisa fazer um pouco: envie o comando / start para o bot e transfira o token emitido pelo bot para o arquivo crimes / config / alarm_config.yml . A string pode ficar assim:
ivanov: a5081d-1b6de6-5f2762 - É controlado a partir do console.
Por que gerenciar nosso script a partir do console? Tudo é organizado para que o processo de aprendizado ou obtenção de previsões de qualquer modelo seja facilmente organizado por um desenvolvedor externo que não esteja familiarizado com os detalhes da implementação do seu experimento. Para que todas as peças do quebra-cabeça se encaixem , após o design do train.py, você precisa organizar o Makefile . Ele contém o comando train em branco, e você só precisa definir corretamente os caminhos para os arquivos de configuração necessários listados acima e listar todos os que desejam receber notificações do Telegram no valor do parâmetro username. Em particular, o alias funciona, o que enviará um alerta a todos os membros da equipe.
Quando tudo estiver pronto, nosso experimento começa com o make train , de maneira simples e elegante.
Caso você queira usar as redes neurais de outras pessoas, os ambientes virtuais ( venv ) ajudarão. Criar e excluí-los como parte de um experimento é muito fácil:
ocean env new criará um novo ambiente. Por padrão, ele não é apenas ativo, mas também cria um kernel (kernel) adicional para notebooks e para pesquisas adicionais. Será chamado da mesma maneira que o nome do experimento.ocean env list exibe uma lista de núcleos.ocean env delete ambiente criado no experimento.
O que está faltando?
- Ocean não é amigo de conda (
porque nós não usamos ) - Modelo de projeto apenas em inglês.
- O problema de localização ainda se aplica ao site: a construção do log do projeto pressupõe que todos os logs estejam em inglês.
Conclusão
O código fonte do projeto está aqui .
Se você estiver interessado - ótimo! Você pode encontrar mais informações no README no repositório Ocean .
E, como costumam dizer nesses casos, contribuições são bem-vindas, só ficaremos felizes se você participar da melhoria do projeto.