Olá queridos leitores! Neste artigo, quero falar sobre a arquitetura do meu projeto, que refatorei 4 vezes no seu lançamento, pois não estava satisfeito com o resultado. Vou falar sobre as desvantagens das abordagens populares e mostrar as minhas.
Quero dizer imediatamente que este é o meu primeiro artigo, não estou dizendo o que fazer como eu - certo. Eu só quero mostrar o que fiz, contar como cheguei ao resultado final e, o mais importante - obter as opiniões dos outros.
Trabalhei em várias campanhas e vi um monte de tudo o que eu teria feito de diferente.
Por exemplo, muitas vezes vejo a arquitetura N-Layer, há uma camada para trabalhar com dados (DA), há uma camada com lógica de negócios (BL) que funciona usando DA e possivelmente alguns outros serviços, e há também uma camada de exibição \ API na qual uma solicitação é recebida, processada usando BL. Parece conveniente, mas olhando para o código, vejo esta situação:
- [DA] extrai \ grava \ altera dados, mesmo se uma consulta complexa - OK
- [BL] 80% chama 1 método e rola o resultado acima - Por que essa camada vazia?
- [Visualizar] 80% das chamadas O método 1 BL lança o resultado acima - Por que essa camada em branco?
Além disso, está na moda envolver interfaces para que mais tarde você possa bloquear e testar - uau, apenas uau!
- Por que se molhar?
- Bem, para reduzir os efeitos colaterais durante os testes.
- Ou seja, protestaremos sem efeitos colaterais, mas no estímulo com eles?
...
Isso é uma coisa básica que eu não gostei nessa arquitetura, porque resolver um problema como: "Listar curtidas do usuário" é um grande processo, mas, na realidade, 1 consulta no banco de dados e possivelmente no mapeamento.
Solução de amostra1) [DA] Adicionar solicitação ao DA
2) Resposta BL direta do DA
3) [Visualizar] Encaminhar o resultado BA, pode promover
Não esqueça que todos esses métodos ainda precisam ser adicionados à interface, estamos escrevendo um projeto para nos molharmos, e não para uma solução.
Em outros lugares, vi uma implementação de API com uma abordagem CQRS.
A solução não parecia ruim, 1 pasta - 1 recurso. Um desenvolvedor que cria um recurso fica em sua pasta e quase sempre pode esquecer a influência de seu código em outros recursos, mas havia tantos arquivos que era apenas um pesadelo. Modelos de solicitação / resposta, validadores, auxiliares, a própria lógica. A pesquisa no estúdio praticamente se recusou a funcionar, foram colocadas extensões para encontrar as coisas necessárias no código.
Há muito mais a ser dito, mas destaquei os principais motivos que me fizeram recusar
E finalmente ao meu projeto
Como eu disse, refatorei meu projeto várias vezes, naquele momento tive uma “depressão do programador”, não fiquei feliz com meu código e o refatorei repetidamente, no final, comecei a assistir a um vídeo sobre a arquitetura do aplicativo para ver como outros fazem. Encontrei os relatórios de Anton Moldovan sobre DDD e programação funcional e pensei: "Aqui está, eu preciso de F #!".
Depois de passar alguns dias em F #, percebi que, em princípio, faria a mesma coisa em C # e não pior. O vídeo mostrou:
- Aqui está o código C #, é uma merda
- Aqui está F # legal, menos escrito - super.
Mas o truque é que a solução no F # foi implementada de maneira diferente e, contra isso, eles mostraram uma implementação ruim no C #. O princípio principal era que BL não é algo que chama serviços de DA e faz todo o trabalho, mas é uma função pura .
Claro que o F # é bom, gostei de alguns recursos, mas, como o C #, essa é apenas uma ferramenta que pode ser usada de diferentes maneiras.
E voltei para o C # e comecei a criar.
Criei esses projetos na solução:
- API
- Core
- Serviços
- Testes
Também usei recursos do C # 8, especialmente o tipo de referência anulável, mostrarei sua aplicação.
Brevemente sobre as tarefas das camadas que eu lhes dei.
API
1) Recebimento de solicitações, modelos de solicitação + validação, restrições
2) Chamando funções do Core e Serviços
Mais detalhes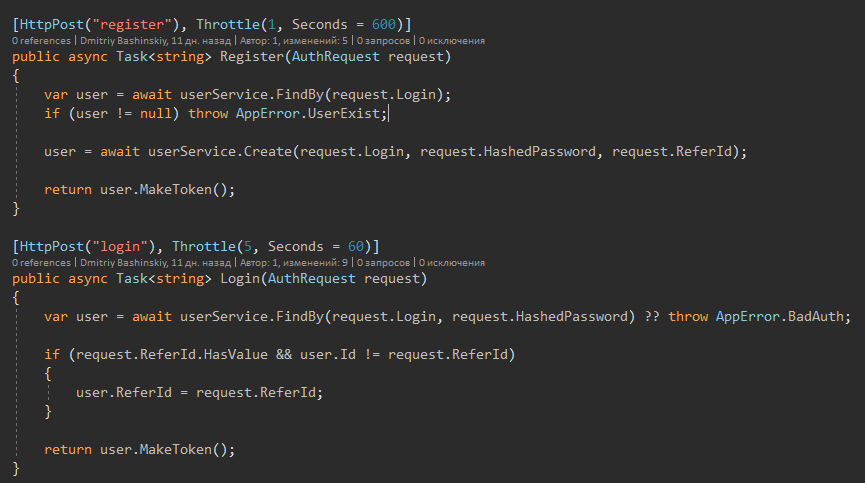
Aqui vemos um código simples e legível, acho que todos entenderão o que está escrito aqui.
Padrão claro observado
1) Obter dados
2) Processar, modificar etc. - Esta parte precisa ser testada.
3) Salve.
3) Mapeamento, se necessário
4) Tratamento de erros (registro + resposta humana)
Mais detalhesEsta classe contém todos os possíveis erros de aplicativo aos quais o manipulador de exceções responde.
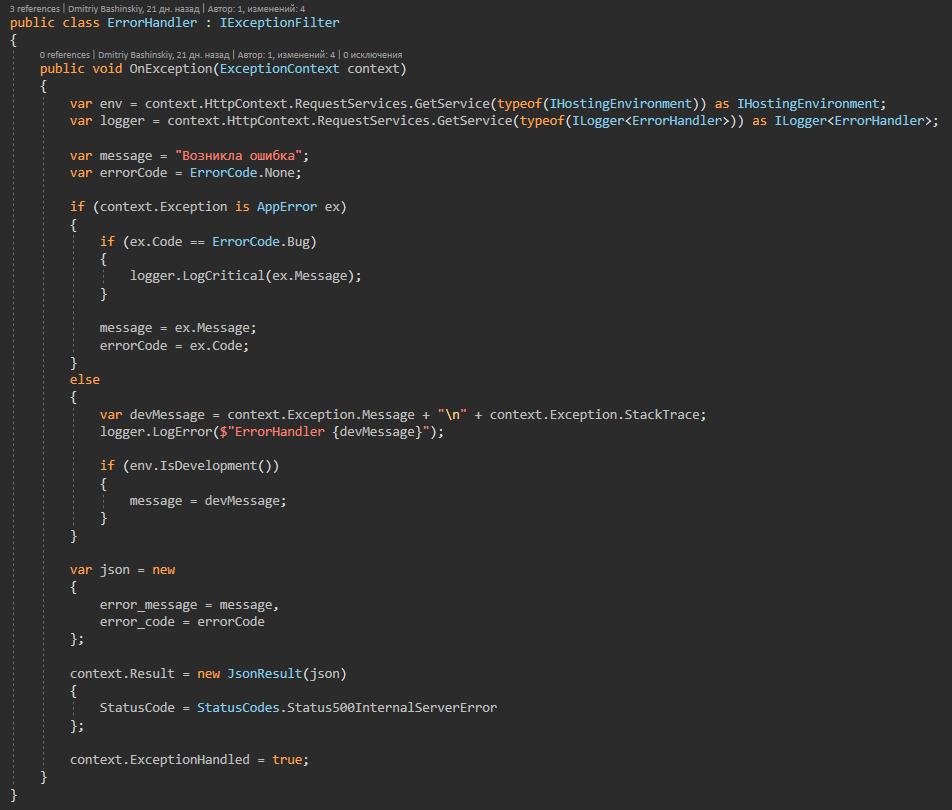
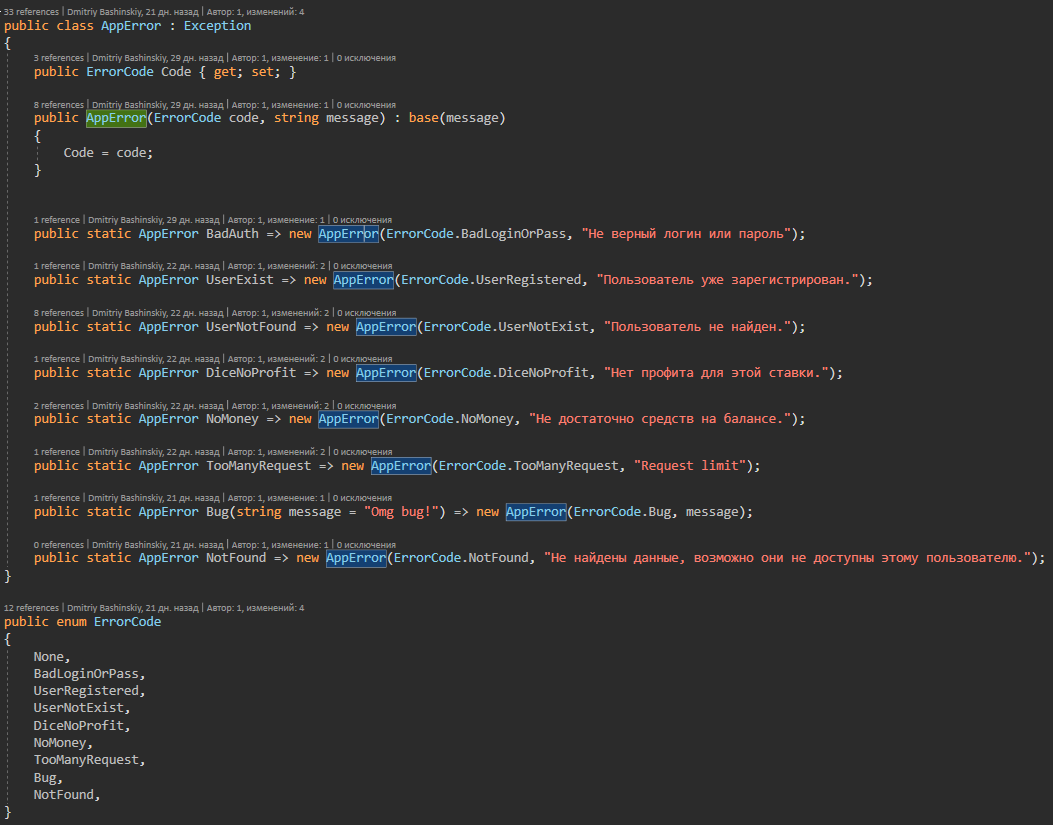
Acontece que o aplicativo funciona ou dá um erro específico, e não os erros processados são um efeito colateral ou um bug, o log de tais erros voa imediatamente para mim em telegrama, em um bate-papo com o bot.
Eu tenho AppError.Bug este erro para um caso claro.
Eu tenho um CallBack de outro serviço, ele terá um userId no meu sistema e, se eu não encontrar um usuário com esse ID, algo aconteceu com o usuário ou não está claro, um erro desse tipo aparece como CRITICAL, em teoria não deveria. para surgir, mas se isso acontecer, requer minha intervenção.
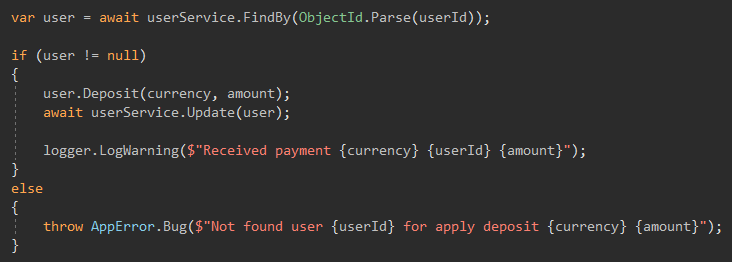
Core, o mais interessante
Eu sempre tive em mente que os BLs são apenas funções que dão o mesmo resultado com a mesma entrada. A complexidade do código nessa camada estava no nível do trabalho de laboratório, não grandes funções que claramente e sem erros fazem seu trabalho. E era importante que não houvesse efeitos colaterais nas funções, tudo o que a função precisava era seu parâmetro.
Se a função precisar de um saldo do usuário, obtemos o saldo e transferimos para a função, e NÃO empurre o serviço do usuário para BL.
1) Ações básicas de entidades
Mais detalhes
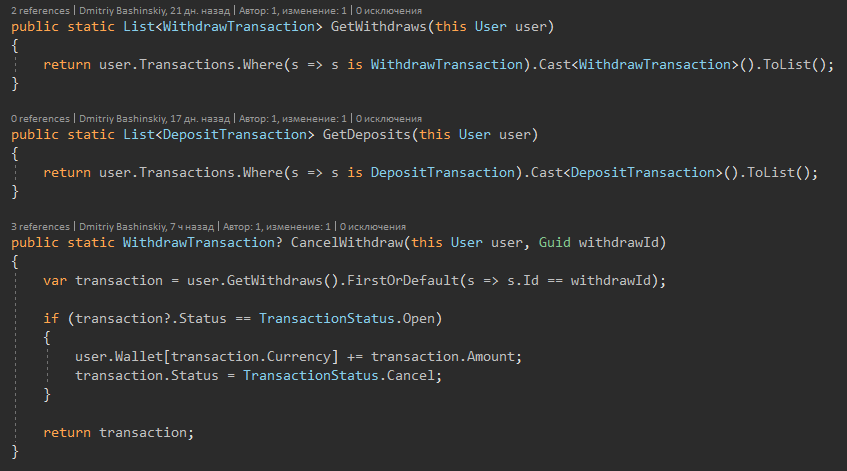
Eu vim com métodos como métodos de extensão para que a classe não incha e a funcionalidade possa ser agrupada por recursos.
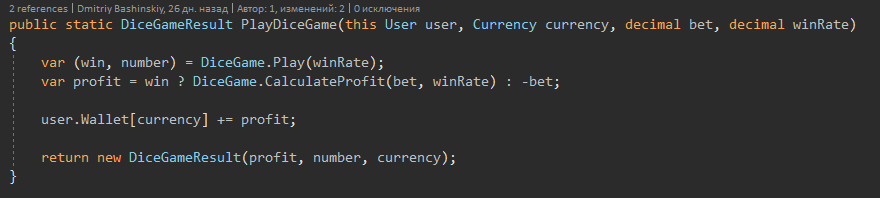
Considero que uma boa construção de modelos de entidades é um tópico igualmente importante.
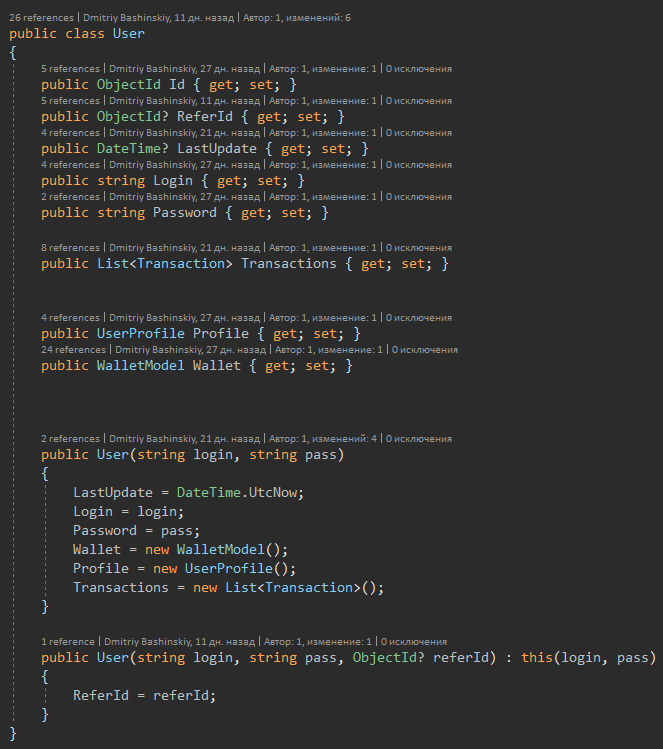
Por exemplo, eu tenho um usuário, o usuário tem saldos em várias moedas. Uma das decisões típicas que tomei sem hesitar é a essência do "Balance" e basta colocar uma série de saldos no usuário. Mas que tipo de conveniência trouxe essa decisão?
1) Adicionando / removendo moedas. Essa tarefa significa imediatamente para nós não apenas a escrita de novo código, mas também a migração, com preenchimento / exclusão de todos os usuários existentes, e essa é a opção mais fácil. Deus permita, para adicionar uma nova moeda, você teria que criar um botão para o usuário, no qual ele clica e inicia a criação de uma nova carteira para algum tipo de processo de negócios. Como resultado, só foi necessário expandir o enum para a nova moeda, e eles escreveram outro recurso para criar carteiras por um botão; eles lançaram outra tarefa para a frente.
2) No código, constantes FirstOrDefault (s => s.Currency == currency) e verificação de null
Minha decisão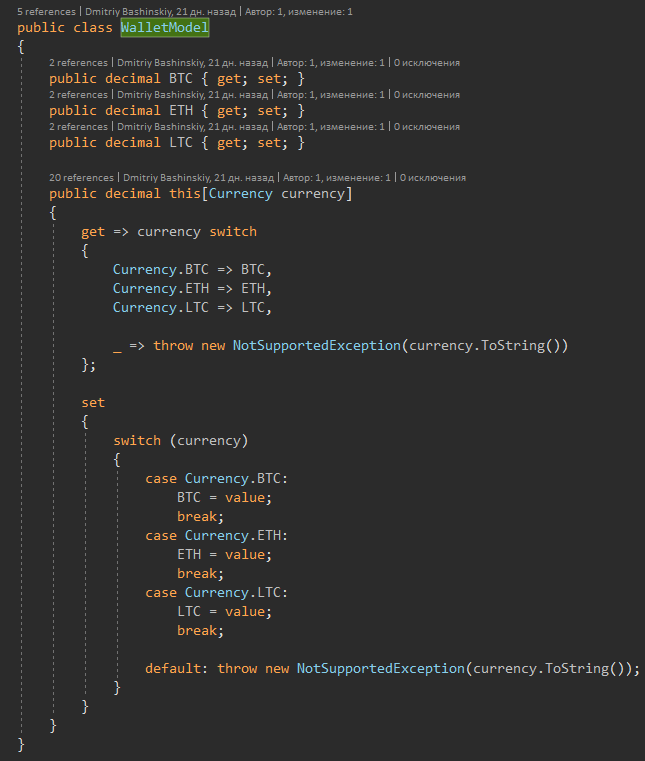
Pelo próprio modelo, garanto a mim mesmo que não haverá saldo nulo e, ao criar o operador indexador, simplifiquei meu código em todos os locais de interação com o saldo.
Serviços
Essa camada fornece ferramentas convenientes para trabalhar com vários serviços.
No meu projeto, uso o MongoDB e, para um trabalho conveniente, envolvi as coleções em um repositório desse tipo.
Mais detalhesRepositório em si
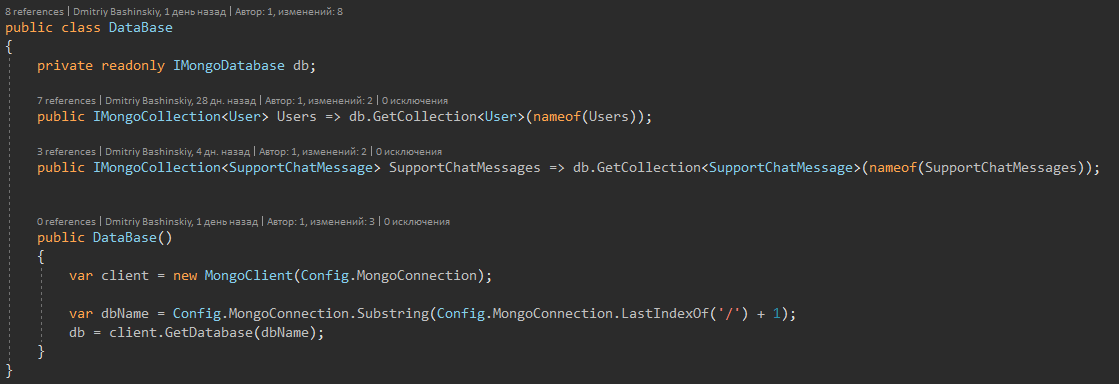
A Monga bloqueia o documento no momento de trabalhar com ele, respectivamente, isso nos ajudará a resolver problemas na competição de solicitações. E no mong existem métodos para procurar uma entidade + atuando nela, por exemplo: "Encontre um usuário com id e adicione 10 ao seu saldo atual"
E agora sobre o recurso do C # 8.
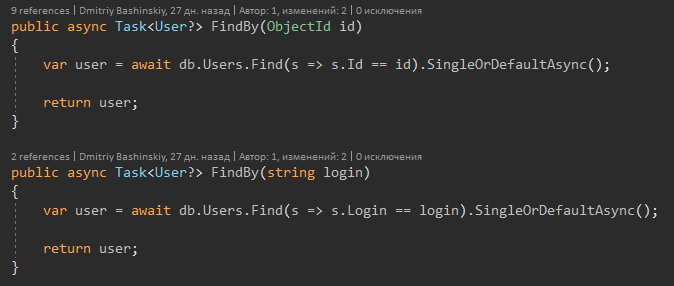
A assinatura do método diz que o Usuário pode retornar e, talvez, Nulo, respectivamente, quando vejo Usuário? Eu recebo imediatamente um aviso do compilador e faço uma verificação nula.
Quando o método retorna Usuário, eu trabalho com ele com confiança.
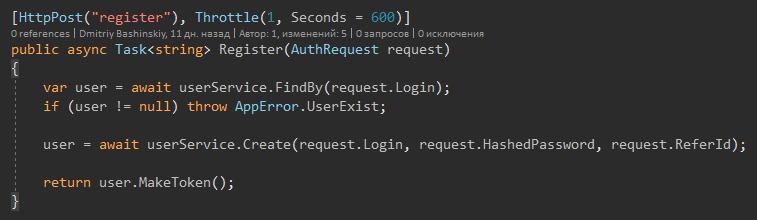
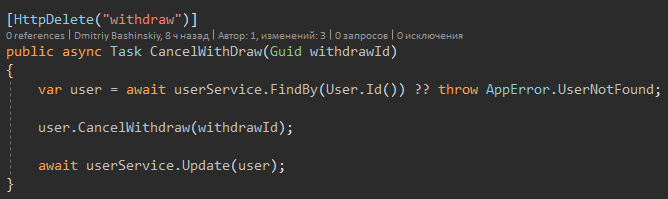
Também quero chamar a atenção para o fato de que não há tentativa de captura, porque as exceções podem ser apenas de "situações estranhas" e dados incorretos que não devem chegar aqui porque há validação. Também não há tentativa de captura na camada da API, há apenas um manipulador de exceção global.
Há apenas um método que lança a exceção é o método Update.
Implementa proteção contra perda de dados no modo multiencadeado.
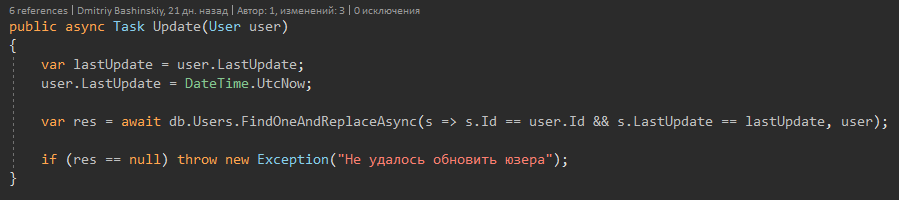
Por que você não usou os métodos monga mencionados acima?
Há lugares em que ainda não sei ao certo se posso trabalhar com o usuário; talvez ele não tenha dinheiro para essa ação; portanto, no começo, levo o usuário para fora e verificá-lo, depois modifico-o e salve-o.
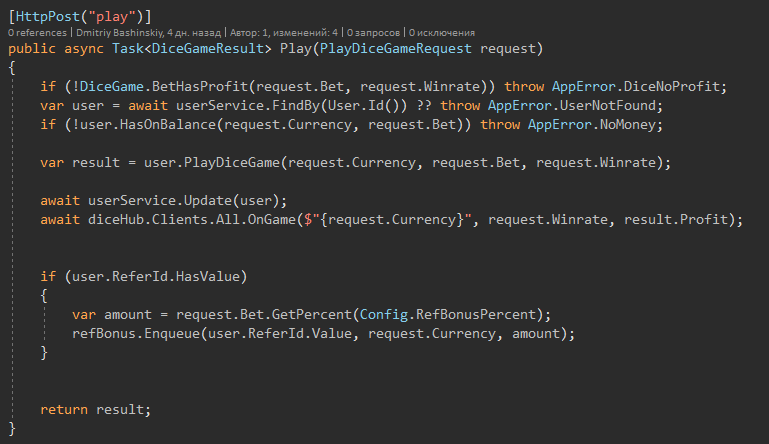
Minha aplicação na teoria mudará o saldo do usuário mais de uma vez por segundo, pois esses serão jogos rápidos.
Mas o próprio modelo do usuário, é claramente visível que a referência do usuário é opcional e você pode trabalhar com todo o resto sem pensar em nulo.
Finalmente testes
Como eu disse, você só precisa testar a lógica, e a lógica de nossa função não tem efeitos colaterais.
Portanto, podemos executar nossos testes muito rapidamente e com parâmetros diferentes.
Mais detalhesEu baixei a pepita FSCheck, que gera dados recebidos aleatoriamente e permite muitos casos diferentes.
Eu só preciso criar vários usuários, alimentar o teste e verificar as alterações.
Existe um pequeno construtor para criar esses usuários, mas é fácil de expandir.

E aqui estão os próprios testes
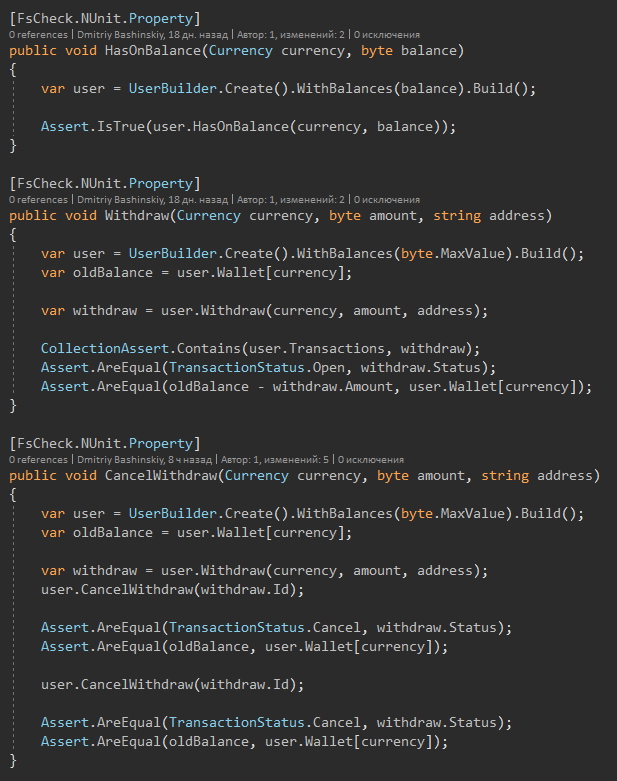
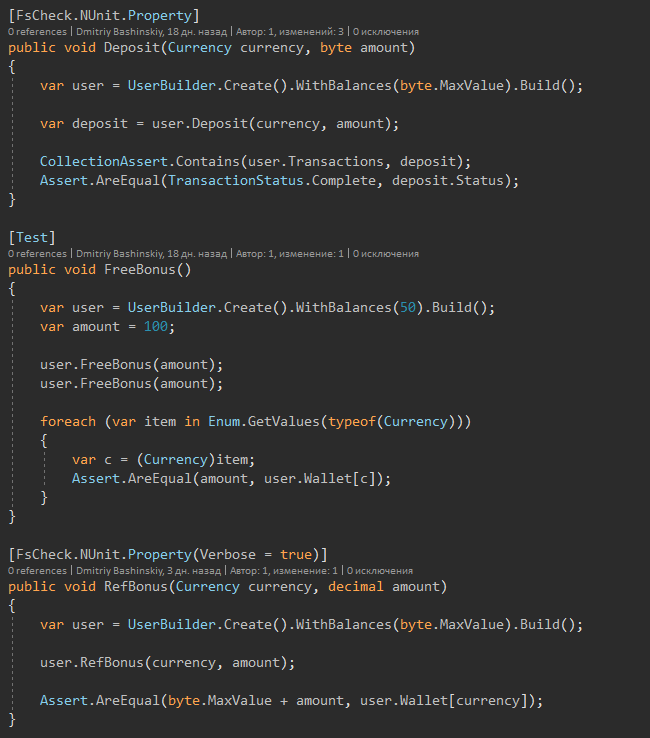
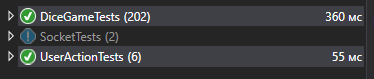
Após algumas alterações, eu executo os testes, após 1-2 segundos vejo que tudo está em ordem.
Também está nos planos de escrever testes E2E para verificar toda a API de fora e garantir que ela funcione como deveria, desde a solicitação até a resposta.
Chips
Coisas legais que você pode precisarCada uma das minhas solicitações é dopada, quando ocorre um erro, encontro requestId e posso reproduzi-lo facilmente repetindo a solicitação, porque minha API não possui um estado e cada solicitação depende apenas dos parâmetros da solicitação.
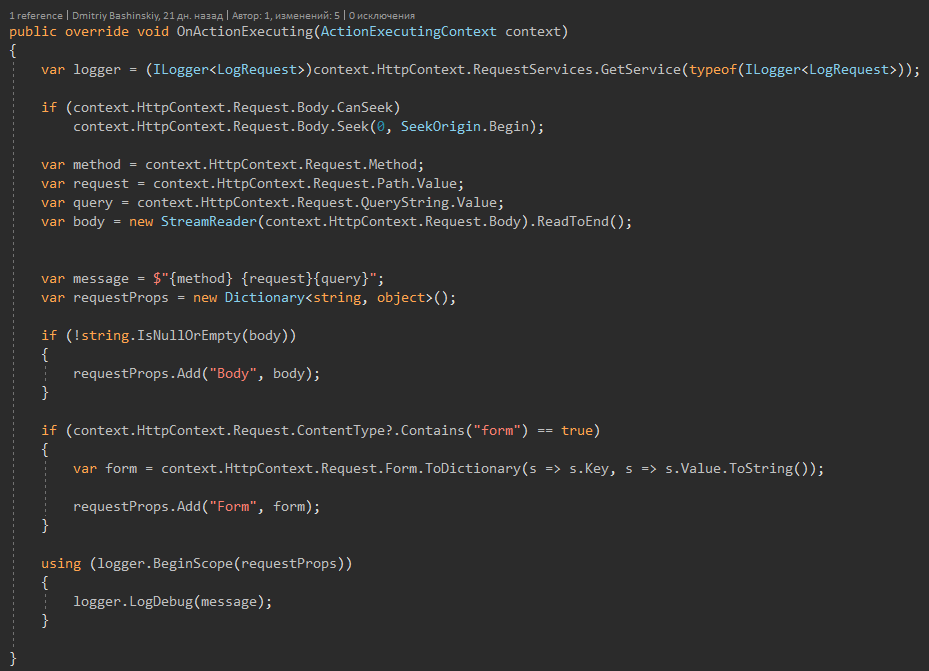
Para resumir.
Nós realmente escrevemos uma solução, e não uma estrutura na qual um monte de abstrações extras, assim como o mok. Fizemos o tratamento de erros em um local e eles devem ocorrer muito raramente. Separamos BL e efeitos colaterais, agora BL é apenas uma lógica local que pode ser reutilizada. Não escrevemos funções extras que simplesmente encaminham a chamada para outras funções. Vou ler ativamente os comentários e complementar o artigo, obrigado!