Os principais problemas do trabalho com o banco de dados estão relacionados aos recursos do dispositivo do sistema operacional no qual o banco de dados trabalha. O Linux agora é o principal sistema operacional para bancos de dados. Solaris, Microsoft e até HPUX ainda são usados na empresa, mas nunca ocupam o primeiro lugar, mesmo combinados. O Linux está ganhando terreno com confiança, porque há cada vez mais bancos de dados de código aberto. Portanto, a questão da interação do banco de dados com o sistema operacional é obviamente sobre bancos de dados Linux. Isso é sobreposto ao eterno problema do banco de dados - desempenho de E / S. É bom que, nos últimos anos, o Linux tenha passado por uma grande reforma na pilha de E / S e haja esperança de iluminação.
Ilya Kosmodemyansky (
hydrobiont ) trabalha para a Data Egret, uma empresa que
consulta e oferece suporte ao PostgreSQL, e sabe muito sobre a interação entre o SO e os bancos de dados. Em um relatório sobre o HighLoad ++, Ilya falou sobre a interação de IO e bancos de dados usando o exemplo do PostgreSQL, mas também mostrou como outros bancos de dados funcionam com IO. Eu olhei para a pilha de E / S do Linux, que coisas novas e boas apareciam nela e por que nem tudo é como era há alguns anos atrás. Como um lembrete útil - uma lista de verificação das configurações do PostgreSQL e Linux para obter o desempenho máximo do subsistema IO nos novos kernels.
O vídeo do relatório contém muito inglês, a maioria dos quais traduzimos no artigo.Por que falar sobre IO?
E / S rápida é a coisa mais crítica para os administradores de banco de dados . Todo mundo sabe o que pode ser alterado ao trabalhar com a CPU, que a memória pode ser expandida, mas a E / S pode estragar tudo. Se estiver ruim com discos e com E / S em excesso, o banco de dados irá gemer. IO se tornará um gargalo.
Para que tudo funcione bem, você precisa configurar tudo.
Não apenas o banco de dados ou apenas o hardware - é isso. Até o Oracle de alto nível, que em si é um sistema operacional em alguns lugares, requer configuração. Lemos as instruções no "Guia de instalação" da Oracle: altere esses parâmetros do kernel, alteramos outros - existem muitas configurações. Além do fato de que no Unbreakable Kernel, muito já está por padrão conectado ao Oracle Linux.
Para PostgreSQL e MySQL, são necessárias ainda mais alterações. Isso ocorre porque essas tecnologias contam com mecanismos do SO. Um DBA que funcione com PostgreSQL, MySQL ou NoSQL moderno deve ser um engenheiro de operações do Linux e girar nozes diferentes do SO.
Todo mundo que quer lidar com as configurações do kernel, vira para o
LWN . O recurso é engenhoso, minimalista, contém muitas informações úteis, mas foi
escrito por desenvolvedores de kernel para desenvolvedores de kernel . O que os desenvolvedores do kernel escrevem bem? O núcleo, não o artigo, como usá-lo. Portanto, tentarei explicar tudo para os desenvolvedores e permitir que eles escrevam o kernel.
Tudo é complicado muitas vezes pelo fato de que inicialmente o desenvolvimento do kernel Linux e o processamento de sua pilha estavam atrasados, e nos últimos anos eles foram muito rápidos. Nem ferro nem desenvolvedores com artigos atrás dele acompanham.
Banco de dados típico
Vamos começar com os exemplos do PostgreSQL - aqui está a E / S em buffer. Ele possui memória compartilhada, que é alocada no
espaço do
usuário do ponto de vista do sistema operacional e possui o mesmo cache no cache do kernel no
espaço do kernel .
 A principal tarefa de um banco de dados moderno
A principal tarefa de um banco de dados moderno :
- pegue as páginas do disco na memória;
- quando ocorrer uma alteração, marque as páginas como sujas;
- gravar no Write-Ahead Log;
- depois sincronize a memória para que fique consistente com o disco.
Em uma situação do PostgreSQL, esta é uma viagem de ida e volta constante: da memória compartilhada que o PostgreSQL controla no kernel do cache de página e depois no disco através de toda a pilha do Linux. Se você usar um banco de dados em um sistema de arquivos, ele funcionará neste algoritmo com qualquer sistema semelhante ao UNIX e com qualquer banco de dados. As diferenças são, mas insignificantes.
O uso do Oracle ASM será diferente - o próprio Oracle interage com o disco. Mas o princípio é o mesmo: com o Direct IO ou com o cache de página, mas a tarefa é
desenhar páginas por toda a pilha de E / S o mais rápido possível , seja ele qual for. E problemas podem surgir em todas as etapas.
Dois problemas de IO
Embora tudo seja
somente leitura , não há problemas. Eles lêem e, se houver memória suficiente, todos os dados que precisam ser lidos são colocados na RAM. O fato de que, no caso do PostgreSQL no
Buffer Cache, é o mesmo, não estamos muito preocupados.
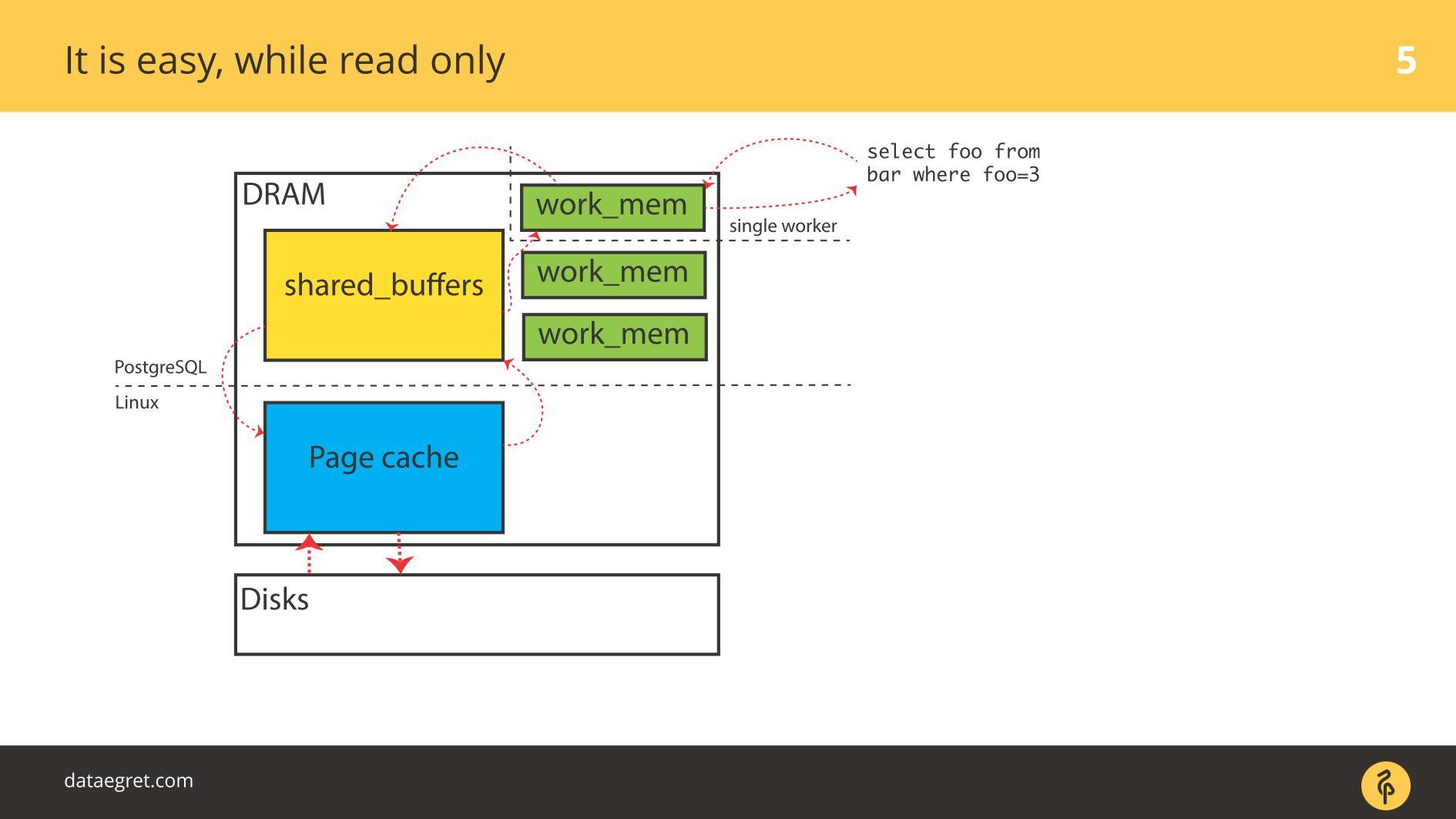 O primeiro problema com o IO é a sincronização de cache.
O primeiro problema com o IO é a sincronização de cache. Ocorre quando a gravação é necessária. Nesse caso, você terá que dirigir para frente e para trás muito mais memória.
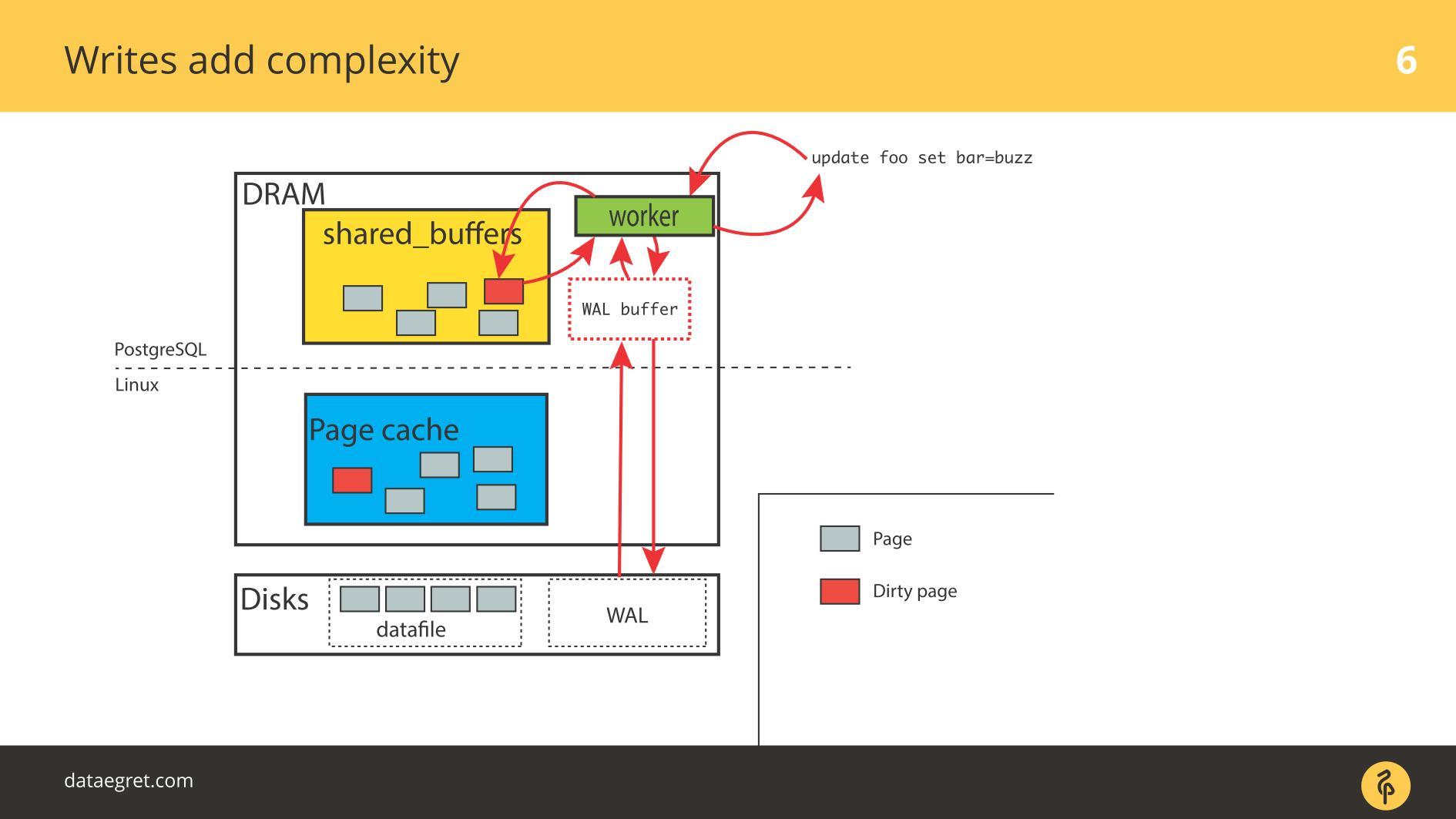
Portanto, você precisa configurar o PostgreSQL ou MySQL para que tudo chegue ao disco a partir da memória compartilhada. No caso do PostgreSQL - você ainda precisa ajustar a trapaça em segundo plano das páginas sujas no Linux para enviar tudo para o disco.
O segundo problema comum é a falha de gravação do log Write-Ahead . Aparece quando a carga é tão poderosa que até um log gravado seqüencialmente fica no disco. Nesta situação, ele também precisa ser gravado rapidamente.
A situação não é muito diferente da
sincronização de cache . No PostgreSQL, trabalhamos com um grande número de buffers compartilhados, o banco de dados possui mecanismos para gravação eficiente de registros Write-Ahead Log, otimizados até o limite. A única coisa que pode ser feita para tornar o log mais eficiente é alterar as configurações do Linux.
Os principais problemas de trabalhar com o banco de dados
O segmento de memória compartilhada pode ser muito grande . Comecei a falar sobre isso em conferências em 2012. Então eu disse que a memória caiu de preço, mesmo existem servidores com 32 GB de RAM. Em 2019, já pode haver mais em laptops, com mais e mais frequência nos servidores 128, 256 etc.
Realmente muita memória . A gravação banal leva tempo e recursos, e as
tecnologias que usamos para isso são conservadoras . Os bancos de dados são antigos, foram desenvolvidos por um longo tempo, estão evoluindo lentamente. Os mecanismos nos bancos de dados não estão exatamente corretos com a tecnologia mais recente.
Sincronizar páginas na memória com o disco resulta em grandes operações de E / S. Quando sincronizamos os caches, um grande fluxo de E / S surge e outro problema surge -
não podemos distorcer algo e observar o efeito. Em um experimento científico, os pesquisadores alteram um parâmetro - obtém o efeito, o segundo - obtém o efeito, o terceiro. Nós não teremos sucesso. Torcemos alguns parâmetros no PostgreSQL, configuramos pontos de verificação - não vimos o efeito. Em seguida, configure novamente a pilha inteira para obter pelo menos algum resultado. Torcer um parâmetro não funciona - somos forçados a configurar tudo de uma vez.
A maioria das E / S do PostgreSQL gera sincronização de página: pontos de verificação e outros mecanismos de sincronização. Se você trabalhou com o PostgreSQL, pode ter visto picos nos pontos de verificação quando uma “serra” aparece periodicamente nos gráficos. Anteriormente, muitos enfrentavam esse problema, mas agora existem manuais sobre como corrigi-lo, ficou mais fácil.
Hoje, os SSDs salvam bastante a situação. No PostgreSQL, algo raramente repousa diretamente no registro de valor. Tudo depende da sincronização: quando ocorre um ponto de verificação, o fsync é chamado e existe um tipo de "acertar" um ponto de verificação no outro. Muito IO. Um ponto de verificação ainda não terminou, não concluiu todos os seus fsyncs, mas já ganhou outro ponto de verificação e começou!
O PostgreSQL possui um recurso exclusivo -
vácuo automático. Este é um longo histórico de muletas para arquitetura de banco de dados. Se o autovacuum falhar, eles geralmente o configuram para que ele funcione de forma agressiva e não interfira com o resto: há muitos trabalhadores de autovacuum, frequentemente acionando um pouco, processando tabelas rapidamente. Caso contrário, haverá problemas com DDL e com bloqueios.
Mas quando o Autovacuum é agressivo, ele começa a mastigar IO.
Se o vácuo automático for sobreposto nos pontos de verificação, na maioria das vezes os discos são quase 100% reciclados, e essa é a fonte dos problemas.
Curiosamente, há um problema de
recarga de cache . Ela é geralmente menos conhecida por DBA. Um exemplo típico: o banco de dados foi iniciado e, por algum tempo, tudo diminui tristemente. Portanto, mesmo se você tiver muita RAM, compre bons discos para que a pilha aqueça o cache.
Tudo isso afeta seriamente o desempenho. Os problemas começam não imediatamente após a reinicialização do banco de dados, mas posteriormente. Por exemplo, o ponto de verificação passou e muitas páginas estão sujas em todo o banco de dados. Eles são copiados para o disco porque você precisa sincronizá-los. Em seguida, os pedidos solicitam uma nova versão das páginas do disco e o banco de dados afunda. Os gráficos mostrarão como o refil do cache após cada ponto de verificação contribui com uma certa porcentagem para a carga.
A coisa mais desagradável na entrada / saída do banco de dados é o
IO do Trabalhador. Quando cada trabalhador que você solicita, começa a gerar seu IO. No Oracle, é mais fácil, mas no PostgreSQL é um problema.
Há muitos motivos para problemas com o
Worker IO : não há cache suficiente para "postar" novas páginas do disco. Por exemplo, acontece que todos os buffers são compartilhados, todos sujos, os pontos de verificação ainda não foram. Para que o trabalhador execute a seleção mais simples, você precisa levar o cache de algum lugar. Para fazer isso, primeiro você precisa salvar tudo em disco. Você não possui um processo especializado de checkpointer, e o trabalhador inicia o fsync para liberá-lo e preenchê-lo com algo novo.
Isso levanta um problema ainda maior: o trabalhador é uma coisa não especializada e todo o processo não é otimizado. É possível otimizar em algum lugar no nível do Linux, mas no PostgreSQL isso é uma medida de emergência.
Problema de E / S principal para DB
Que problema resolvemos quando montamos algo? Queremos maximizar o deslocamento de páginas sujas entre o disco e a memória.
Mas muitas vezes acontece que essas coisas não tocam diretamente o disco. Um caso típico - você vê uma média de carga muito grande. Porque Porque alguém está esperando pelo disco e todos os outros processos também estão esperando. Parece que não há utilização explícita do disco, apenas algo bloqueou o disco e o problema está na entrada / saída.
Os problemas de E / S do banco de dados nem sempre dizem respeito apenas a discos.
Tudo está envolvido neste problema: discos, memória, CPU, Agendadores de E / S, sistemas de arquivos e configurações de banco de dados. Agora vamos examinar a pilha, ver o que fazer com ela e que coisas boas foram inventadas no Linux para que tudo funcione melhor.
Discos
Por muitos anos, os discos ficaram terrivelmente lentos e ninguém esteve envolvido na latência ou otimização dos estágios de transição. Otimizar fsyncs não fazia sentido. O disco estava girando, as cabeças se movendo ao longo dele como um registro fonográfico, e o fsyncs era tão longo que os problemas não surgiram.
A memória
É inútil olhar para as principais consultas sem ajustar o banco de dados. Você configurará uma quantidade suficiente de memória compartilhada, etc., e terá uma nova consulta superior - precisará configurá-la novamente. Aqui está a mesma história. Toda a pilha do Linux foi feita a partir deste cálculo.
Largura de banda e latência
Maximizar o desempenho de IO maximizando o rendimento é fácil até certo ponto. Um processo auxiliar do PageWriter foi inventado no PostgreSQL que descarregava o ponto de verificação. O trabalho tornou-se paralelo, mas ainda há bases para a adição do paralelismo. E minimizar a latência é a tarefa da última milha, para a qual são necessárias super tecnologias.
Essas super tecnologias são SSDs. Quando eles apareceram, a latência caiu acentuadamente. Mas em todos os outros estágios da pilha, surgiram problemas: tanto do lado dos fabricantes de bancos de dados quanto dos fabricantes de Linux. Problemas precisam ser resolvidos.
O desenvolvimento do banco de dados se concentrou em maximizar a produtividade, assim como o desenvolvimento do kernel do Linux. Muitos métodos para otimizar a era de E / S de discos giratórios não são tão bons para SSDs.
No meio, fomos forçados a fazer backup da infraestrutura atual do Linux, mas com novos discos. Assistimos a testes de desempenho do fabricante com um grande número de IOPS diferentes e o banco de dados não melhorou, porque o banco de dados não é apenas e nem tanto sobre IOPS. Muitas vezes acontece que podemos pular 50.000 IOPS por segundo, o que é bom. Mas se não sabemos a latência, não sabemos sua distribuição, não podemos dizer nada sobre desempenho. Em algum momento, o banco de dados começará a ponto de verificação e a latência aumentará dramaticamente.
Por um longo tempo, como agora, esse tem sido um grande problema de desempenho em bancos de dados virtuais. O IO virtual é caracterizado por latência desigual, o que, é claro, também envolve problemas.
Pilha de E / S. Como era antes
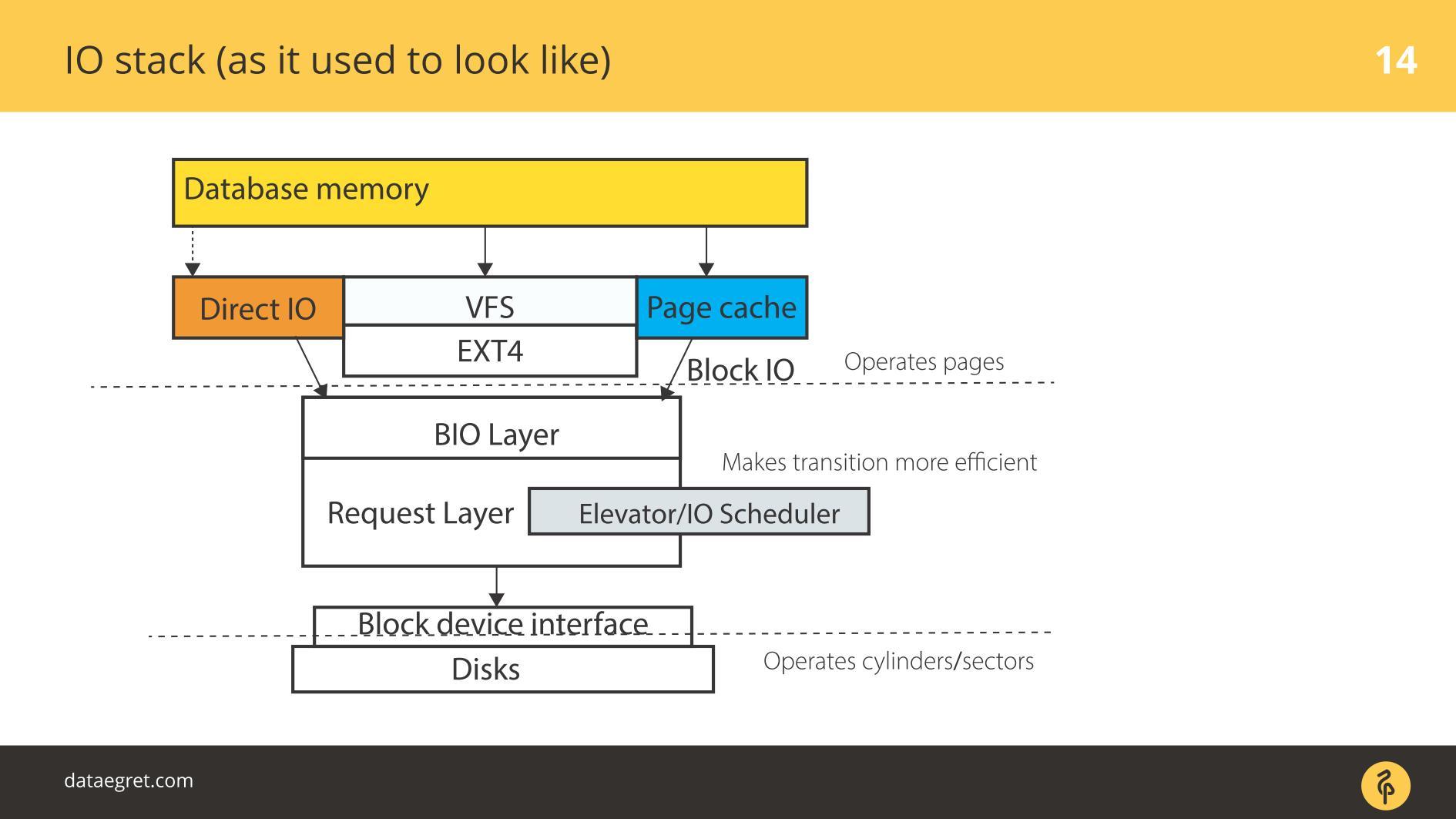
Há espaço para o usuário - essa memória, que é gerenciada pelo próprio banco de dados. Em um banco de dados configurado para que tudo funcionasse como deveria. Isso pode ser feito em um relatório separado, e nem em um. Então tudo passa inevitavelmente pelo cache de página ou pela interface Direct IO que entra na
camada Block Input / Output .
Imagine uma interface do sistema de arquivos. As páginas que estavam no cache de buffer, como estavam originalmente no banco de dados, ou seja, os blocos, saem dele. A camada IO do bloco lida com o seguinte. Há uma estrutura C que descreve um bloco no kernel. A estrutura pega esses blocos e coleta deles vetores (matrizes) de solicitações de entrada ou saída. Abaixo da camada BIO, está a camada solicitante. Os vetores são coletados nessa camada e vão além.
Por um longo tempo, essas duas camadas no Linux foram aprimoradas para gravação eficiente em discos magnéticos. Era impossível ficar sem uma transição. Existem blocos convenientes para gerenciar no banco de dados. É necessário montar esses blocos em vetores que são convenientemente gravados no disco para que fiquem em algum lugar próximo. Para que isso funcionasse efetivamente, eles criaram Elevadores, ou Agendadores IO.
Elevadores
Os elevadores estavam envolvidos principalmente na combinação e na classificação de vetores. Tudo em ordem para que o driver SD do bloco - o driver quase-disco - os blocos de gravação cheguem na ordem conveniente para ele. O driver foi traduzido dos blocos para seus setores e gravado no disco.
O problema era que era necessário fazer várias transições e, a cada uma delas, implementar sua própria lógica do processo ótimo.
Elevadores: até o kernel 2.6
Antes do kernel 2.6, havia o Linus Elevator - o IO Scheduler mais primitivo, escrito por você adivinha quem. Por um longo tempo, ele foi considerado absolutamente inabalável e bom, até que eles desenvolveram algo novo.
O Linus Elevator teve muitos problemas.
Ele combinou e classificou de acordo com a forma de gravar com mais eficiência . No caso de discos mecânicos rotativos, isso levou ao surgimento de "
fome" : uma situação em que a eficiência da gravação depende da rotação do disco. Se de repente você precisar ler efetivamente ao mesmo tempo, mas já estiver errado, será mal lido nesse disco.
Gradualmente, ficou claro que essa é uma maneira ineficiente. Portanto, a partir do kernel 2.6, um zoológico inteiro de agendadores começou a aparecer, destinado a tarefas diferentes.
Elevadores: entre 2,6 e 3
Muitas pessoas confundem esses agendadores com agendadores de sistema operacional porque eles têm nomes semelhantes.
CFQ - Enfileiramento completamente justo não é o mesmo que agendadores de SO. Apenas os nomes são semelhantes. Foi cunhado como um agendador universal.
O que é um agendador universal? Você acha que tem uma carga média ou, pelo contrário, uma carga única? Os bancos de dados têm uma versatilidade muito baixa. A carga universal pode ser imaginada como um laptop comum. Tudo acontece lá: ouvimos música, tocamos, digitamos texto. Para isso, apenas agendadores universais foram escritos.
A principal tarefa do planejador universal: no caso do Linux, para cada terminal e processo virtual, crie uma fila de solicitações. Quando queremos ouvir música em um reprodutor de áudio, as entradas e saídas do reprodutor ficam em uma fila. Se queremos fazer backup de algo usando o comando cp, algo mais está envolvido.
No caso de bancos de dados, ocorre um problema. Como regra, um banco de dados é um processo iniciado e, durante a operação, surgiram processos paralelos que sempre terminam na mesma fila de E / S. O motivo é que esse é o mesmo aplicativo, o mesmo processo pai. Para cargas muito pequenas, essa programação era adequada; para o resto, não fazia sentido. Era mais fácil desligar e não usar, se possível.
Gradualmente, o
agendador de prazos apareceu - ele funciona de maneira mais esperta, mas basicamente é mesclagem e classificação para discos giratórios. Dado o design de um subsistema de disco específico, coletamos vetores de blocos para escrevê-los da maneira ideal. Ele tinha menos problemas com a
fome , mas eles estavam lá.
Portanto, mais perto do terceiro kernel do Linux apareceu
noop ou
none , o que funcionou muito melhor com a expansão dos SSDs. Incluindo o planejador noop, na verdade desabilitamos o planejamento: não há classificações, mesclagens e coisas semelhantes que o CFQ e o prazo fizeram.
Isso funciona melhor com os SSDs, porque eles são inerentemente paralelos: possui células de memória. Quanto mais desses elementos forem amontoados em uma placa PCIe, mais eficiente ele funcionará.
O agendador de algumas de suas considerações de outro mundo, do ponto de vista do SSD, coleta alguns vetores e os envia para algum lugar. Tudo termina com um funil. Portanto, matamos a simultaneidade de SSDs, não os usamos ao máximo. Portanto, um desligamento simples, quando os vetores vão aleatoriamente sem nenhuma classificação, funcionou melhor em termos de desempenho. Por esse motivo, acredita-se que leituras aleatórias e gravações aleatórias sejam melhores em SSDs.
Elevadores: 3.13 em diante
Começando com o kernel 3.13, o
blk-mq apareceu . Um pouco antes, havia um protótipo, mas na versão 3.13, uma versão de trabalho apareceu pela primeira vez.
O Blk-mq começou como um agendador, mas é difícil chamá-lo de agendador - ele fica sozinho arquitetonicamente. Esta é uma substituição para a camada de solicitação no kernel. Lentamente, o desenvolvimento do blk-mq levou a uma grande revisão de toda a pilha de E / S do Linux.
A idéia é a seguinte: vamos usar a capacidade nativa dos SSDs para fazer simultaneidade eficiente para E / S. , / , , as is SSD. CPU .
blk-mq . . , 4 ,
blk-mq — 5-10%, .
blk-mq — , SSD.
blk-mq NVMe driver Linux. Linux, Microsoft.
blk-mq NVMe driver — Linux, .
, . - PCIe SSD. , .
blk-mq NVMe , . .
, , . NVMe , , .
elevators

: CPU, , - .
Elevators -. CPU . - , , , , IO .
elevators
blk-mq — . CPU, NUMA- / . , , , . SD , , .
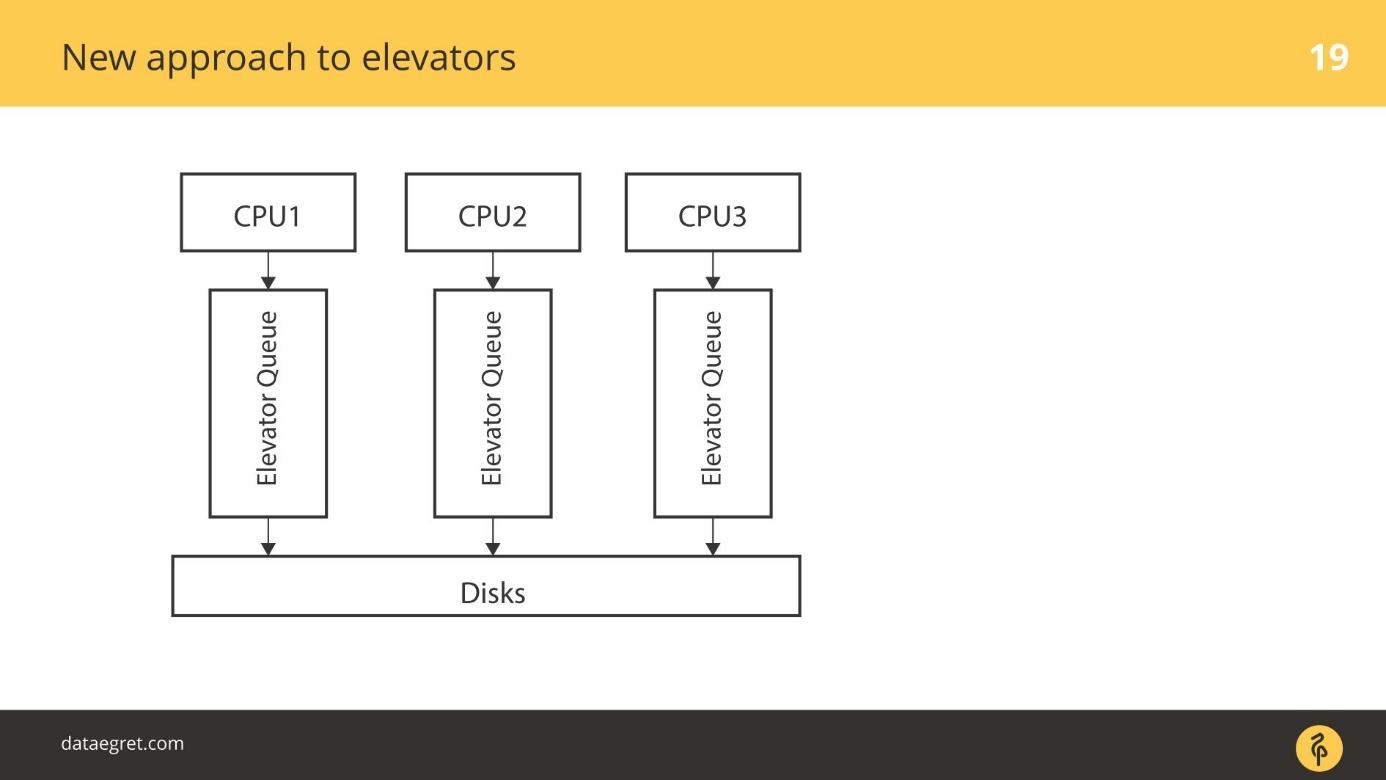
. - RAID- , RAID. SSD — . SD- , blq-mq.
blk-mq
.

. , . / , , Block IO-.
blk-mq , , scheduler.
3.13 , . schedulers
blk-mq , . Linux schedulers IO — Kyber BFQ.
blk-mq .
BFQ — Budget Fair Queueing — FQ . , . BFQ — scheduler . IO. IO, / . , . — . BFQ, , .
Kyber — . BFQ, . Kyber scheduler . — CPU . Kyber .
—
blk-mq SD- . , , , IO-. blk-mq NVMe driver . .
— latency, . SSD, — . -, , NVMe-, blk-mq , . .
Linux IO
/ Linux.
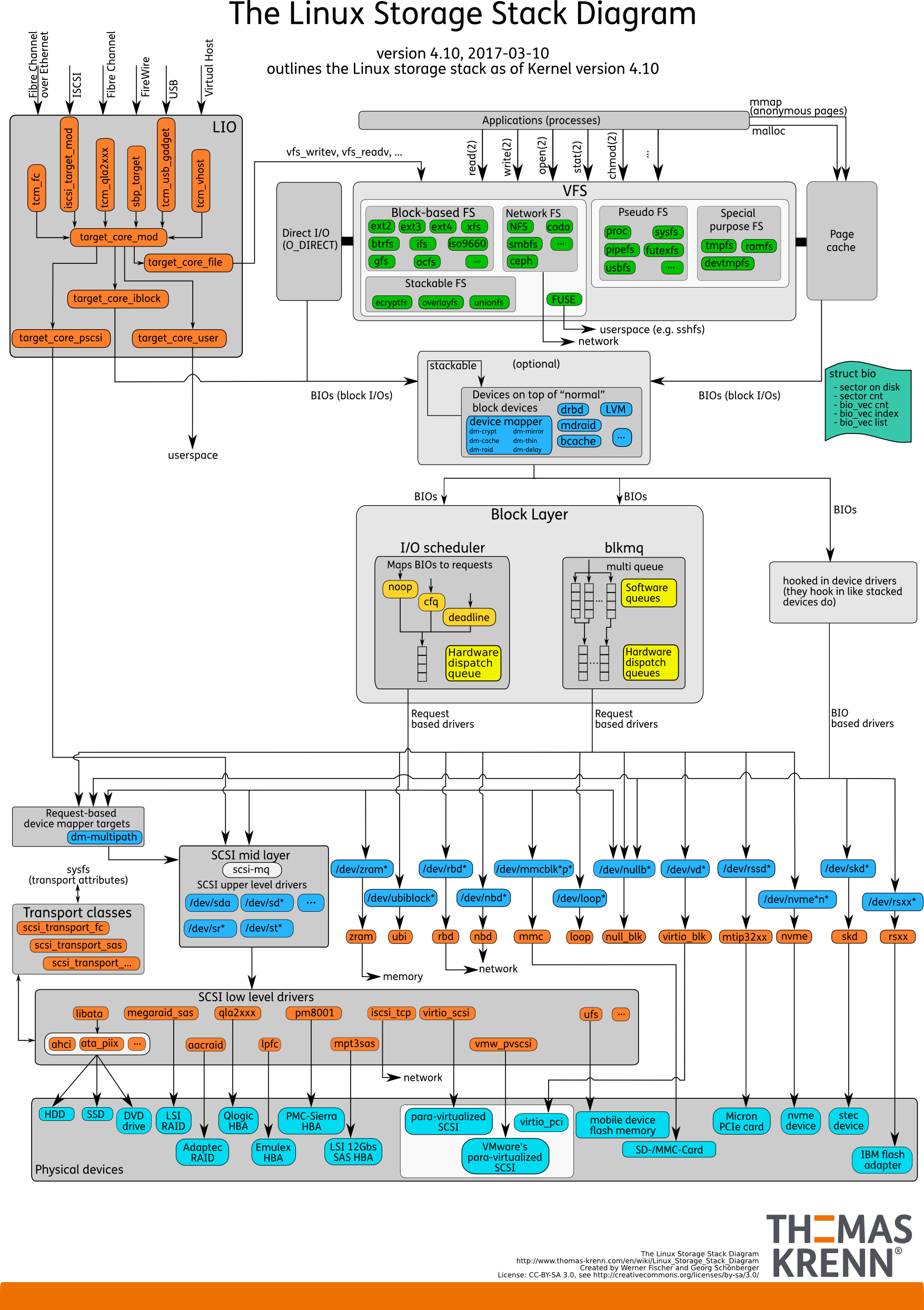
, , , Elevators, .
, , .
NVM Express
NVM Express ou NVMe é uma especificação, um conjunto de padrões que ajudam você a usar melhor os SSDs. A especificação está bem implementada no Linux. O Linux é uma das forças motrizes do padrão.Agora em produção é a terceira versão. O driver desta versão, de acordo com a especificação, pode passar em torno de 20 GB / s por bloco SSD e o NVMe da quinta versão, que ainda não está disponível, até 32 GB / s . O driver SD não possui interfaces nem mecanismos internos para fornecer essa largura de banda.Essa especificação é significativamente mais rápida do que qualquer coisa que era antes.
Depois que os bancos de dados foram escritos para discos rotativos e orientados a eles - eles têm índices na forma de uma árvore B, por exemplo. Surge a pergunta:
os bancos de dados estão prontos para o NVMe ? Os bancos de dados são capazes de mastigar essa carga?
Ainda não, mas eles estão se adaptando. A lista de discussão do PostgreSQL recentemente teve alguns
pwrite() e coisas semelhantes. Os desenvolvedores do PostgreSQL e MySQL interagem com os desenvolvedores do kernel. Claro, eu gostaria de mais interação.
Desenvolvimentos Recentes
No último ano e meio, o NVMe adicionou
pesquisas de E / S.
No início, havia discos giratórios com alta latência. Depois vieram os SSDs, que são muito mais rápidos. Mas havia um batente: o fsync continua, a gravação é iniciada e, em um nível muito baixo - no fundo do driver, uma solicitação é enviada diretamente para o hardware - anote-a.
O mecanismo era simples - eles enviaram e esperamos até que a interrupção seja processada. Aguardar o processamento da interrupção não é um problema comparado à gravação em um disco giratório. Demorou tanto tempo para esperar que, assim que a gravação terminou, a interrupção funcionou.
Desde que o SSD grava muito rapidamente, apareceu um mecanismo para pesquisar o hardware sobre a gravação. Nas primeiras versões, o aumento na velocidade de E / S atingiu 50% devido ao fato de não estarmos esperando uma interrupção, mas estamos perguntando ativamente ao ferro sobre o registro.
Esse mecanismo é chamado de pesquisa de entrada / saída .
Foi introduzido em versões recentes. Na versão 4.12, os
agendadores de E /
S apareceram, especialmente aprimorados para trabalhar com
blk-mq e NVMe, sobre os quais eu disse
Kyber e BFQ . Eles já estão oficialmente no kernel, eles podem ser usados.
Agora, de uma forma utilizável, existe a chamada
marcação IO . Principalmente os fabricantes de nuvens e máquinas virtuais contribuirão para esse desenvolvimento. Grosso modo, a entrada de um aplicativo específico pode ser abordada e dar prioridade a ele. Os bancos de dados ainda não estão prontos para isso, mas fique atento. Eu acho que será mainstream em breve.
Notas diretas de IO
O PostgreSQL não oferece suporte ao Direct IO, e há vários problemas que dificultam a ativação do suporte . Agora, isso é suportado apenas por valor e somente se a replicação não estiver ativada. É necessário
escrever muito código específico do SO e , por enquanto, todos se abstêm disso.
Apesar do fato de o Linux jurar pesadamente a idéia do Direct IO e como ele é implementado, todos os bancos de dados vão para lá. No Oracle e MySQL, o Direct IO é muito usado. O PostgreSQL é o único banco de dados que o Direct IO não tolera.
Lista de verificação
Como se proteger de surpresas com o fsync no PostgreSQL:
- Configure pontos de verificação para serem menos frequentes e maiores.
- Configure o gravador de plano de fundo para ajudar no ponto de verificação.
- Puxe o vácuo automático para que não haja E / S falsa desnecessária.
Segundo a tradição, em novembro, aguardamos desenvolvedores profissionais de serviços altamente carregados no Skolkovo no HighLoad ++ . Ainda há um mês para solicitar um relatório, mas já aceitamos os primeiros relatórios para o programa . Assine nossa newsletter e aprenda sobre novos tópicos em primeira mão.