
Expresse o que as palavras não podem transmitir; Sinta as mais diversas emoções entrelaçadas em um furacão de sentimentos; romper com a terra, o céu e até o próprio Universo, partindo em uma jornada onde não há mapas, estradas, sinais; inventar, contar e reviver uma história inteira que sempre será única e inimitável. Tudo isso permite que você faça música - uma arte que existe há muitos milhares de anos e encanta nossos ouvidos e corações.
No entanto, a música, ou melhor, as obras musicais, pode servir não apenas ao prazer estético, mas também à transmissão de informações codificadas nelas, destinadas a qualquer dispositivo e invisíveis ao ouvinte. Hoje, encontraremos um estudo muito incomum, no qual estudantes de graduação da Escola Técnica Superior Suíça de Zurique foram capazes de inserir imperceptivelmente determinados dados em obras musicais para o ouvido humano, devido ao qual a própria música se torna um canal de transmissão de dados. Como exatamente eles perceberam sua tecnologia, as melodias são muito diferentes com e sem dados incorporados, e quais são os testes práticos mostrados? Aprendemos sobre isso com o relatório dos pesquisadores. Vamos lá
Base de estudo
Os pesquisadores chamam sua tecnologia de técnica de transmissão acústica de dados. Quando o falante reproduz a melodia alterada, uma pessoa a percebe como de costume, mas, por exemplo, um smartphone pode ler informações codificadas entre linhas, mais precisamente entre notas, se assim posso dizer. O aspecto mais importante na implementação desse método de transferência de dados, os cientistas (o fato de esses caras ainda serem estudantes de pós-graduação não os impede de serem cientistas) chama a velocidade e a confiabilidade da transmissão, mantendo o nível desses parâmetros, independentemente do arquivo de áudio selecionado. A psicoacústica, estudando os aspectos psicológicos e fisiológicos da percepção humana dos sons, ajuda a lidar com essa tarefa.
O núcleo da transmissão acústica de dados pode ser chamado OFDM (multiplexação por divisão de frequência ortogonal), que, juntamente com a adaptação de subportadoras à música original ao longo do tempo, possibilitou maximizar o uso do espectro de frequência transmitido para a transmissão de informações. Graças a isso, foi possível atingir uma velocidade de transmissão de 412 bits / s a uma distância de 24 metros (taxa de erro <10%). Experimentos práticos envolvendo 40 voluntários confirmaram o fato de que é quase impossível ouvir a diferença entre a melodia original e aquela em que a informação foi incorporada.
Onde essa tecnologia pode ser aplicada na prática? Os pesquisadores têm sua própria resposta: quase todos os smartphones, laptops e outros dispositivos portáteis modernos estão equipados com microfones e, em muitos locais públicos (cafés, restaurantes, shopping centers, etc.), há alto-falantes com música de fundo. Por exemplo, os dados para conectar-se a uma rede Wi-Fi podem ser incorporados nessa melodia de fundo sem a necessidade de executar ações adicionais.
As características gerais da transmissão acústica de dados se tornaram claras para nós, agora nos voltamos para um estudo detalhado da estrutura deste sistema.
Descrição do sistema
A incorporação de dados em uma melodia ocorre devido ao mascaramento de frequência. Em intervalos de tempo, as frequências de mascaramento são identificadas e as subportadoras OFDM próximas a esses elementos de mascaramento são preenchidas com dados.
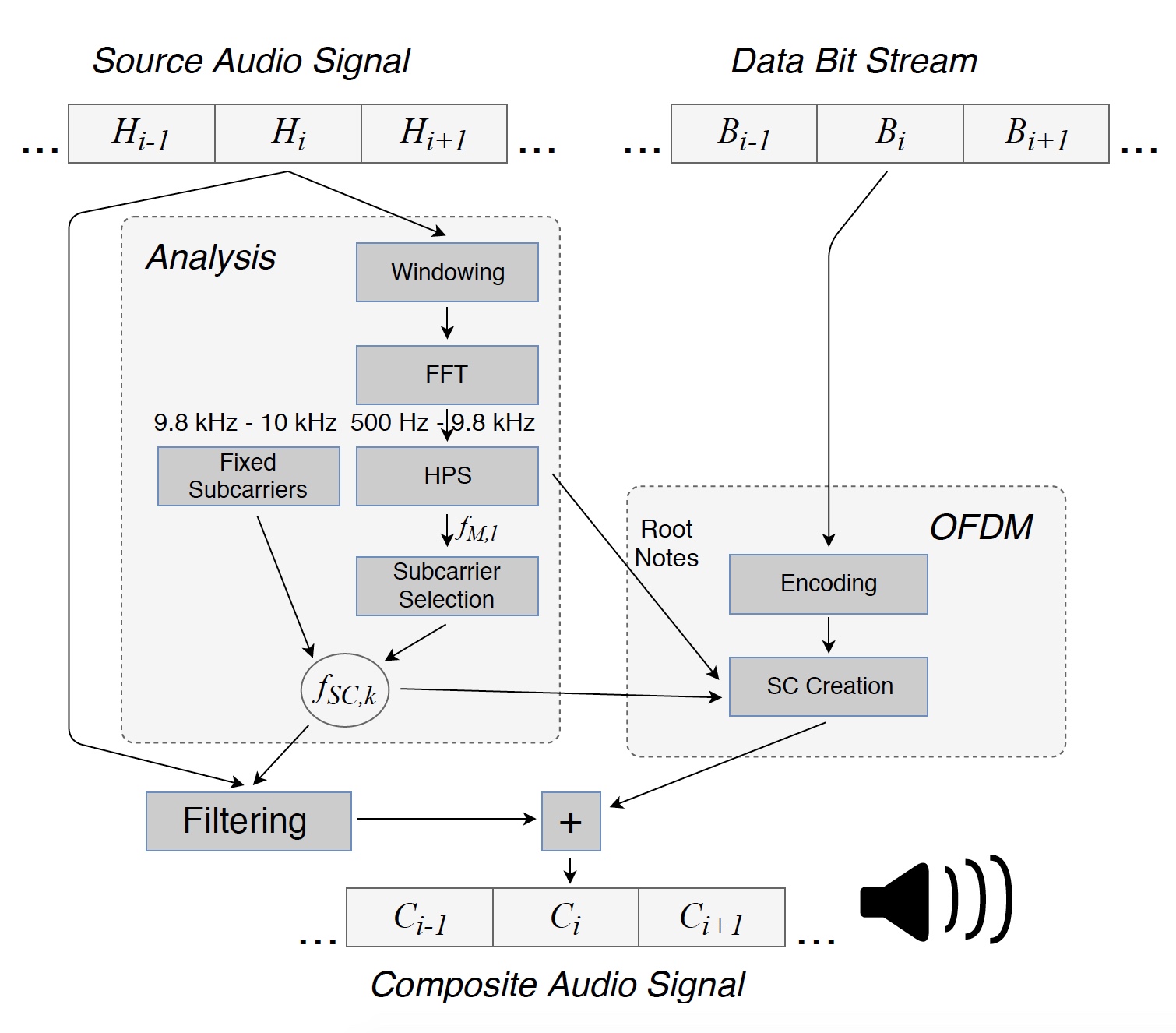 Imagem 1: converta o arquivo de origem em um sinal composto (melodia + dados) transmitido pelos alto-falantes.
Imagem 1: converta o arquivo de origem em um sinal composto (melodia + dados) transmitido pelos alto-falantes.Para começar, o sinal de áudio original é dividido em segmentos consecutivos para análise. Cada segmento (Hi) de L = 8820 amostras, igual a 200 ms, é multiplicado por uma
janela * para minimizar os efeitos de contorno.
Janela * é a função de peso usada para controlar os efeitos devido à presença de lobos laterais nas estimativas espectrais.
Em seguida, as frequências dominantes do sinal inicial foram encontradas na faixa de 500 Hz a 9,8 kHz, o que possibilitou a obtenção de frequências de mascaramento f
M, l para este segmento. Além disso, os dados foram transmitidos no pequeno intervalo de 9,8 a 10 kHz para determinar a localização das subportadoras no receptor. O limite superior da faixa de frequência usada foi definido para 10 kHz devido à baixa sensibilidade do microfone do smartphone em altas frequências.
As frequências de mascaramento foram determinadas individualmente para cada segmento analisado. Utilizando o método HPS (espectro harmônico de produtos), três frequências dominantes foram estabelecidas, após o que foram arredondadas para as notas mais próximas da escala cromática harmônica. Foi assim que as notas principais f
F, i = 1 ... 3, localizadas entre as teclas C0 (16,35 Hz) e B0 (30,87 Hz) foram obtidas. Com base no fato de que as notas principais são muito baixas para uso na transmissão de dados, na faixa de 500 Hz ... 9,8 kHz, suas oitavas mais altas 2
k f
F, foram calculadas. Muitas dessas frequências (f
O, l1 ) foram mais pronunciadas devido à natureza do HPS.
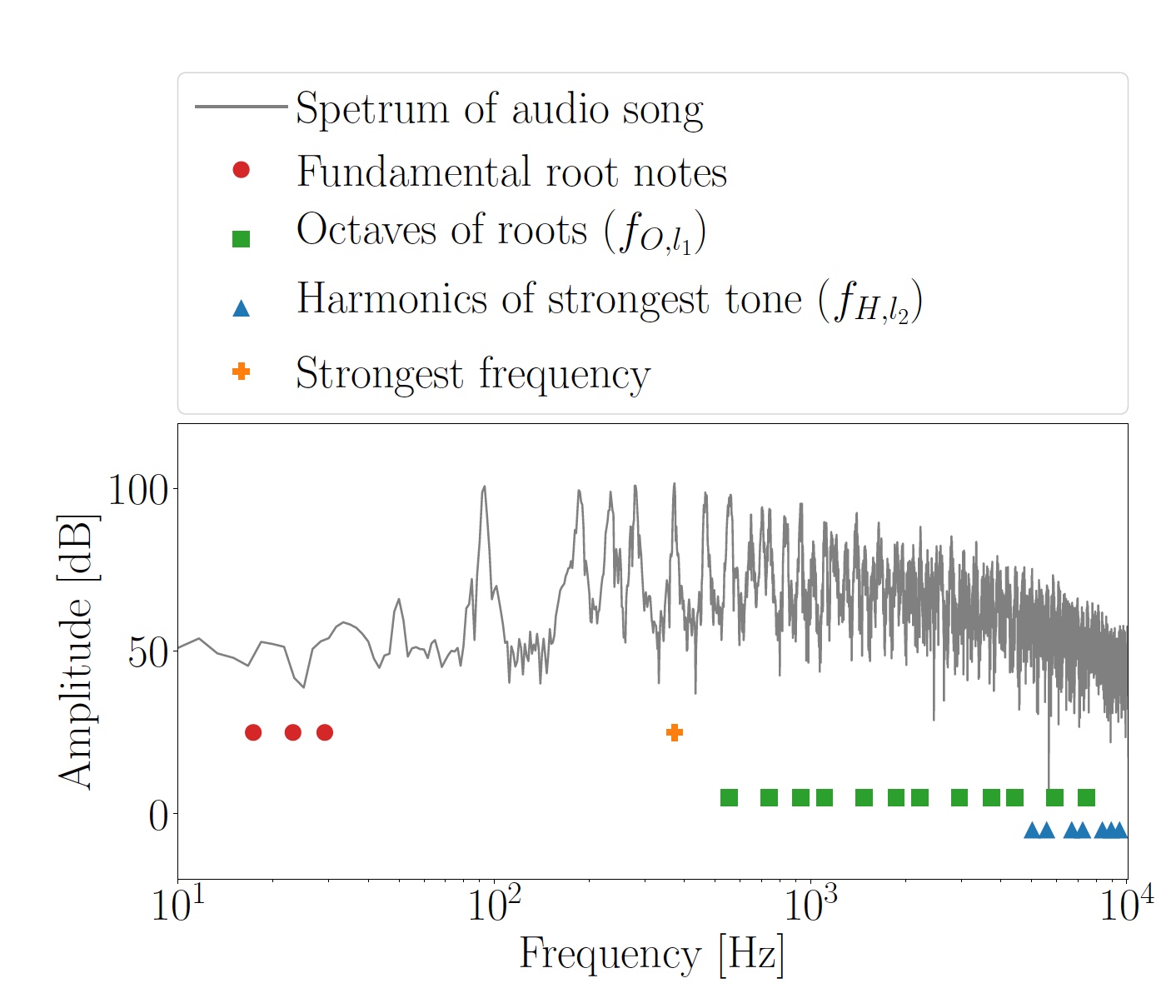 Imagem No. 2: oitavas calculadas f O, l 1 para as notas principais e harmônicas f H, l 2 do tom mais forte.
Imagem No. 2: oitavas calculadas f O, l 1 para as notas principais e harmônicas f H, l 2 do tom mais forte.A totalidade das oitavas e harmônicos foi usada como frequências de mascaramento, com base nas quais foram obtidas frequências OFDM da subportadora f
SC, k . Abaixo e acima de cada frequência de mascaramento, dois subportadores foram inseridos.
Em seguida, o espectro do segmento de áudio Hi foi filtrado nas frequências da subportadora f
SC, k . Então, com base nos bits de informação em Bi, um símbolo OFDM foi criado, devido ao qual o segmento composto Ci podia ser transmitido através do alto-falante. Os valores e as fases das subportadoras devem ser selecionados para que o receptor possa recuperar os dados transmitidos, enquanto o ouvinte não percebe alterações na melodia.
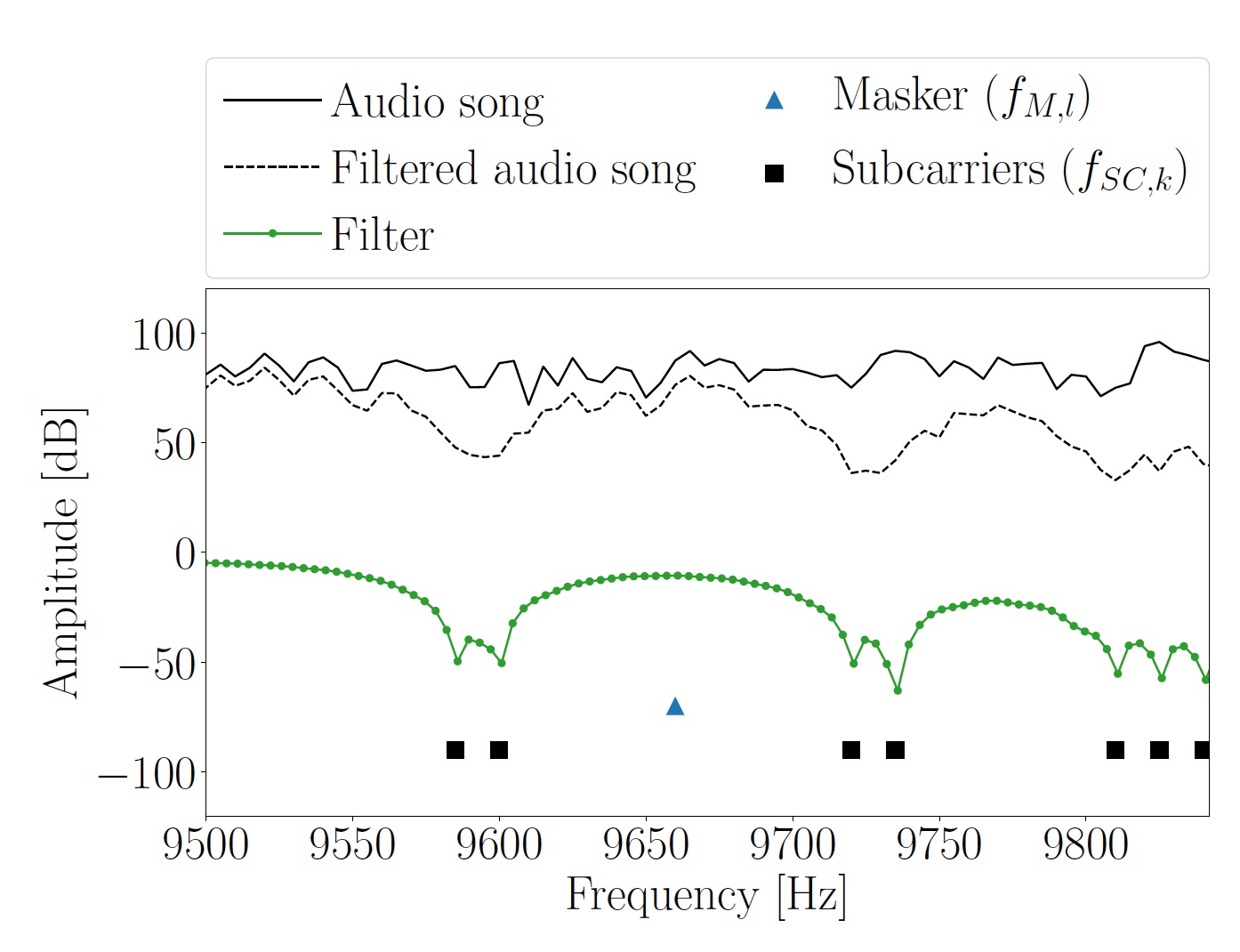 Imagem 3: gráfico do espectro e frequência das subportadoras do segmento Hi da melodia original.
Imagem 3: gráfico do espectro e frequência das subportadoras do segmento Hi da melodia original.Quando um sinal de áudio com a informação codificada nele é reproduzido pelos alto-falantes, o microfone do dispositivo receptor o grava. Para encontrar as posições iniciais dos símbolos OFDM incorporados, as entradas devem primeiro ser puladas pela filtragem de banda. Dessa maneira, a faixa de frequência superior é extraída onde não há sinal de interferência musical entre as subportadoras. Você pode encontrar o início dos símbolos OFDM usando um prefixo cíclico.
Após detectar o início dos símbolos OFDM, o receptor obtém informações sobre as notas mais dominantes decodificando o domínio da frequência superior. Além disso, o OFDM é suficientemente robusto contra fontes de interferência em banda estreita, pois afeta apenas algumas das subportadoras.
Testes práticos
O alto-falante do KRK Rokit 8 atuou como a fonte das melodias alteradas, e o smartphone Nexus 5X tocou no lado do host.
 Imagem 4: A diferença entre as manifestações reais do OFDM e os picos de correlação medidos em ambientes fechados a uma distância de 5 m entre o alto-falante e o microfone.
Imagem 4: A diferença entre as manifestações reais do OFDM e os picos de correlação medidos em ambientes fechados a uma distância de 5 m entre o alto-falante e o microfone.A maioria dos pontos OFDM varia de 0 a 25 ms, para que você possa encontrar uma partida válida dentro do prefixo cíclico de 66,6 ms. Os pesquisadores observam que o receptor (neste experimento, um smartphone) leva em consideração que os símbolos OFDM são reproduzidos periodicamente, o que melhora sua detecção.
A primeira coisa a verificar foi o efeito da distância na taxa de erro de bits (BER). Para isso, foram realizados três testes em diferentes tipos de salas: corredor com carpete, escritório com linóleo no chão e público com piso de madeira.
A música "And The Cradle Will Rock", de Van Halen, foi escolhida como o "assunto do teste".O volume do som foi ajustado para que o nível de som medido pelo smartphone a uma distância de 2 m do alto-falante fosse de 63 dB.
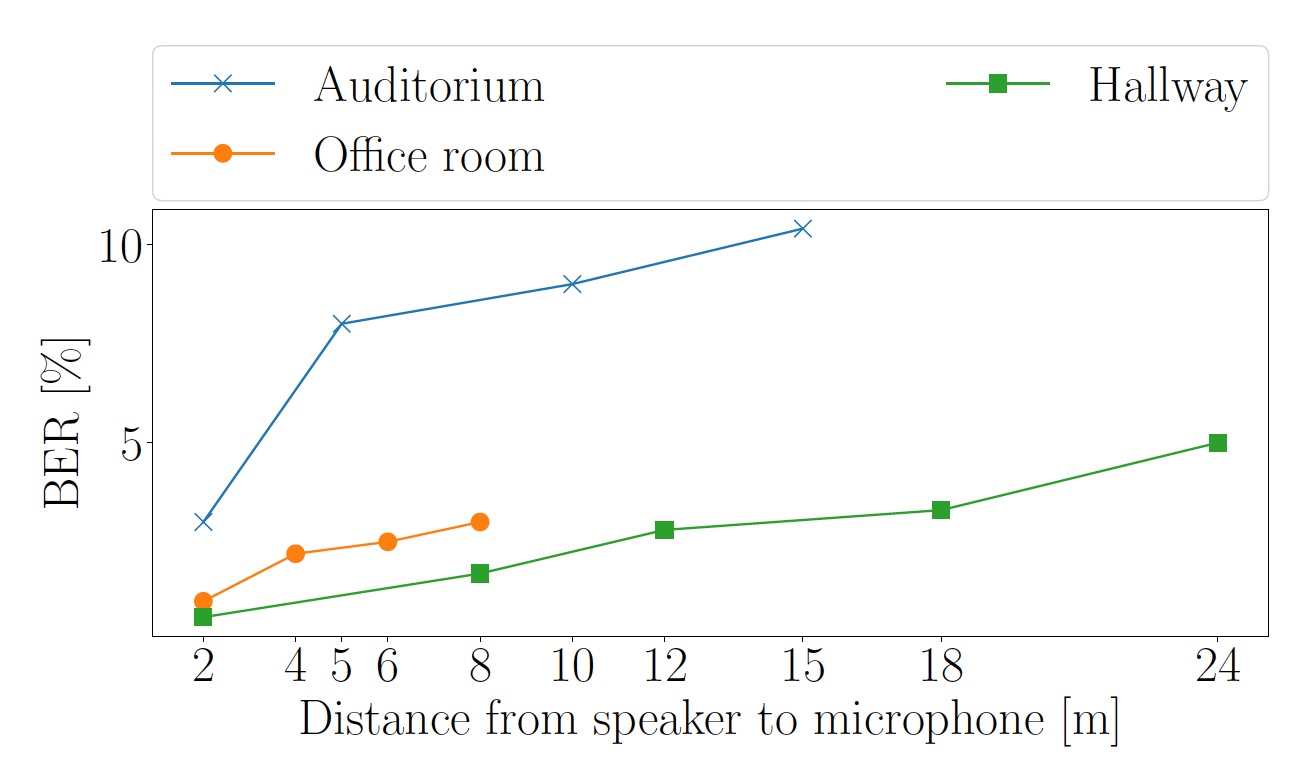 Imagem Nº 5: Indicadores BER dependendo da distância entre o alto-falante e o microfone (linha azul - audiência, corredor verde, escritório laranja).
Imagem Nº 5: Indicadores BER dependendo da distância entre o alto-falante e o microfone (linha azul - audiência, corredor verde, escritório laranja).No corredor, um som de 40 dB foi captado por um smartphone a uma distância de até 24 metros do alto-falante. Na audiência a uma distância de 15 m, o som era de 55 dB, e no escritório, a uma distância de 8 metros, o nível de som percebido pelo smartphone atingiu 57 dB.
Devido ao fato de que o público e o escritório são mais reverberantes, os ecos tardios do símbolo OFDM excedem a duração do prefixo cíclico e aumentam o BER.
Reverb * - uma diminuição gradual na intensidade do som devido à sua reflexão múltipla.
Além disso, os pesquisadores demonstraram a versatilidade de seu sistema, aplicando-o em 6 músicas diferentes de três gêneros (tabela abaixo).
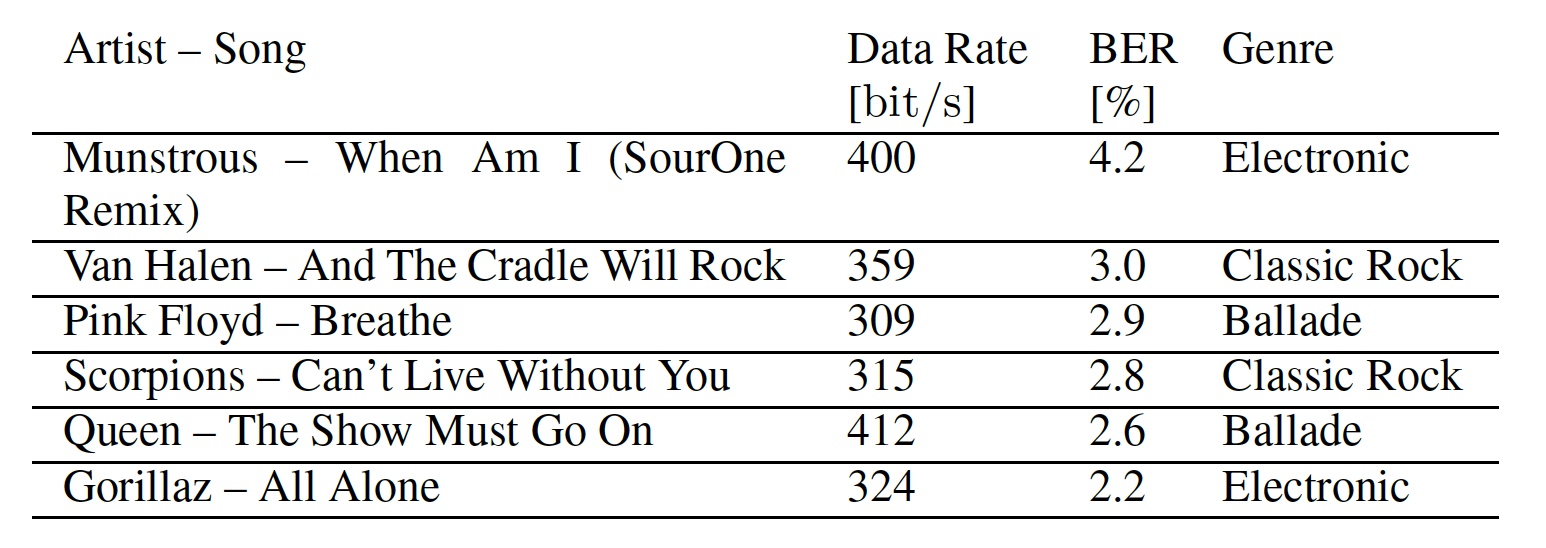 Tabela 1: músicas utilizadas nos testes.
Tabela 1: músicas utilizadas nos testes.Além disso, através dos dados da tabela, podemos ver a taxa de bits e as taxas de erro de bits de cada música. A velocidade de transferência de dados é diferente porque o BPSK diferencial (chaveamento com deslocamento de fase) funciona melhor quando os mesmos subportadores são usados. E isso é possível quando segmentos adjacentes contêm os mesmos elementos de máscara. Músicas continuamente altas fornecem uma base ideal para ocultar dados, pois as frequências de mascaramento são mais pronunciadas em uma ampla faixa de frequências. A música que muda rapidamente pode mascarar os símbolos OFDM apenas parcialmente devido ao comprimento fixo da janela de análise.
Em seguida, as pessoas começaram a testar o sistema, que deveria determinar qual melodia era original e qual foi modificada pelas informações nele contidas. Para isso, trechos de 12 segundos das músicas da tabela nº 1 foram publicados em um site especial.
No primeiro experimento (E1), cada participante recebeu um fragmento modificado ou original para ouvir, e ele teve que decidir se esse fragmento era original ou alterado. No segundo experimento (E2), os participantes puderam ouvir as duas opções quantas vezes quisessem e depois decidir qual era a original e qual foi alterada.
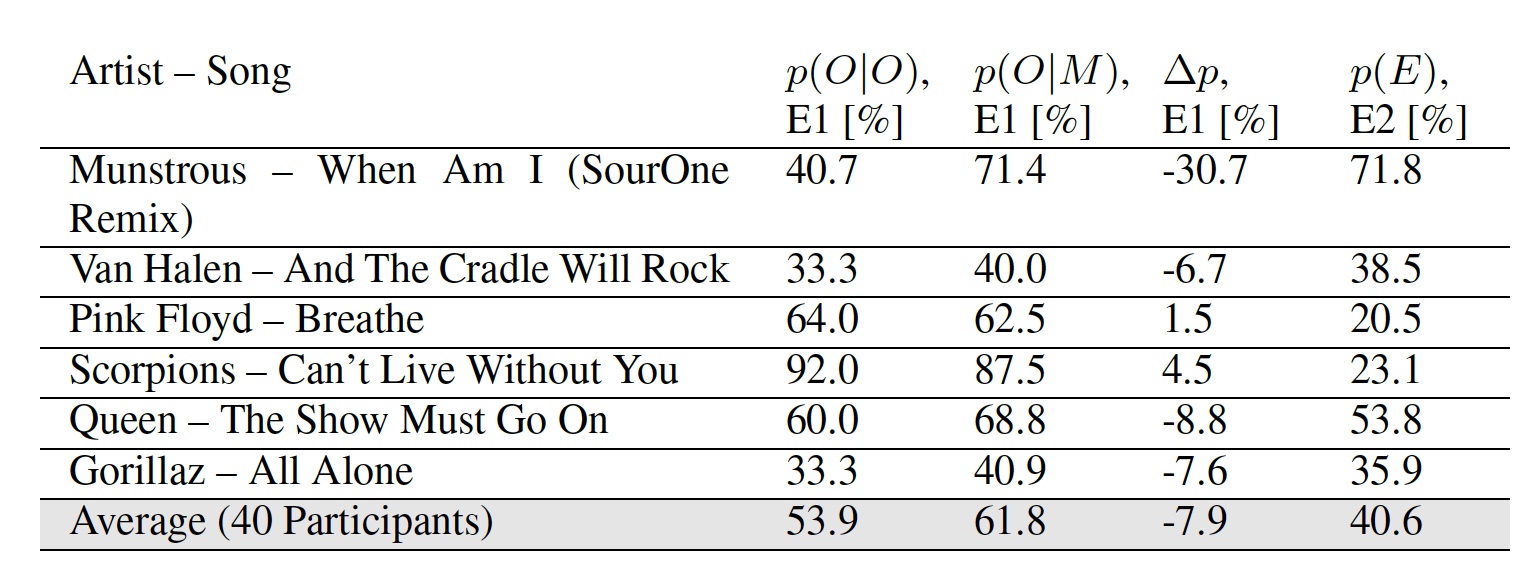 Tabela No. 2: resultados das experiências E1 e E2.
Tabela No. 2: resultados das experiências E1 e E2.Os resultados do primeiro experimento têm dois indicadores: p ( | ) - porcentagem de participantes que marcaram corretamente a melodia original ep ( | ) - porcentagem de participantes que marcaram a versão alterada da melodia como original.
É curioso que alguns participantes, segundo os pesquisadores, considerem certas melodias modificadas mais originais que as originais. O indicador médio de ambos os experimentos sugere que o ouvinte médio não notará a diferença entre uma melodia regular e aquela na qual os dados foram incorporados.
Naturalmente, os conhecedores de música e os músicos serão capazes de captar algumas imprecisões e elementos suspeitos nas melodias alteradas, mas esses elementos não são tão significativos que causam desconforto.
E agora nós mesmos podemos participar do experimento. Abaixo estão duas opções para a mesma melodia - original e modificada. Você ouve a diferença?
A versão original da melodiavs
Versão modificada da melodiaPara um conhecimento mais detalhado das nuances do estudo, recomendo que você analise o
relatório do grupo de pesquisa.
Você também pode fazer o download do arquivo ZIP dos arquivos de áudio das melodias originais e modificadas usadas no estudo
neste link .
Epílogo
Neste trabalho, estudantes de pós-graduação da Escola Técnica Superior Suíça de Zurique descreveram um incrível sistema de transferência de dados dentro da música. Para fazer isso, eles usaram o mascaramento de frequência, o que permitiu incorporar dados em uma melodia tocada pelo alto-falante. Essa melodia é percebida pelo microfone do dispositivo, que reconhece os dados ocultos e os decodifica, enquanto o ouvinte médio nem percebe a diferença. No futuro, os caras planejam desenvolver seu sistema, escolhendo métodos mais avançados para incorporar dados em áudio.
Quando alguém cria algo incomum e, o mais importante, trabalha, estamos sempre felizes. Mas ainda mais alegria é que esta invenção foi criada por jovens. A ciência não tem restrições de idade. E se os jovens consideram a ciência chata, ela é apresentada no ângulo errado, por assim dizer. Afinal, como sabemos, a ciência é um mundo incrível que nunca deixa de surpreender.
Sexta-feira off-top:
Já que estamos falando de música, e mais especificamente sobre rock, aqui está uma jornada maravilhosa pelas extensões do rock.
Queen, Radio Ga Ga (1984).
Obrigado pela atenção, continuem curiosos e tenham um ótimo final de semana a todos, pessoal! :)
Obrigado por ficar conosco. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando a seus amigos, um
desconto de 30% para os usuários da Habr em um análogo exclusivo de servidores básicos que inventamos para você: Toda a verdade sobre o VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de US $ 20 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).
Dell R730xd 2 vezes mais barato? Somente temos
2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre
Como criar um prédio de infraestrutura. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo?