Em grandes projetos, consistindo em dezenas e centenas de serviços em interação, uma abordagem à documentação como código - documentos como código - está se tornando cada vez mais obrigatória.
Mostrarei como você pode aplicar essa filosofia nas realidades do serviço classificado, ou melhor, começarei a partir do primeiro estágio de sua implementação: automação da atualização de dados na documentação.
Kit de ferramentas
O princípio de “documentação como código” implica o uso das mesmas ferramentas ao escrever documentação e ao criar código: linguagens de marcação de texto, sistemas de controle de versão, revisão de código e testes automáticos. O objetivo principal: criar condições para que toda a equipe trabalhe em conjunto no resultado final - uma base de conhecimento completa e instruções para o uso de serviços de produtos individuais. A seguir, falarei sobre ferramentas específicas que escolhemos para resolver esse problema.
Como uma linguagem de marcação de texto, decidimos usar o mais universal - reStructuredText . Além de um grande número de diretivas que fornecem todas as funções básicas para estruturar o texto, essa linguagem suporta os principais formatos finais, incluindo o HTML necessário para o nosso projeto.
Os arquivos são convertidos de .rst para .html através do gerador de documentação do Sphinx . Permite criar sites estáticos para os quais você pode criar seus próprios ou usar temas prontos. Nosso projeto usa dois temas prontos - stanford-theme e bootstrap-theme . O segundo contém subtópicos que permitem definir diferentes esquemas de cores para os principais elementos da interface.
Para acesso rápido e conveniente à versão atual da documentação, usamos um site estático, cujo host é uma máquina virtual, acessível a partir da rede local da equipe de desenvolvimento.
Os arquivos de origem do projeto são armazenados no repositório do Bitbucket e o site é gerado apenas a partir dos arquivos contidos na ramificação principal. A atualização dos dados só é possível através de solicitação por solicitação, que permite verificar todas as novas seções da documentação antes de serem publicadas em domínio público.
Como entre a conclusão de uma nova seção da documentação e o envio ao site, é necessário verificar seu conteúdo, a chave em toda a cadeia é o processo de construção do site e atualização dos dados no host. Este procedimento deve ser repetido sempre que a solicitação de recebimento com a atualização for mesclada com a ramificação principal do projeto.
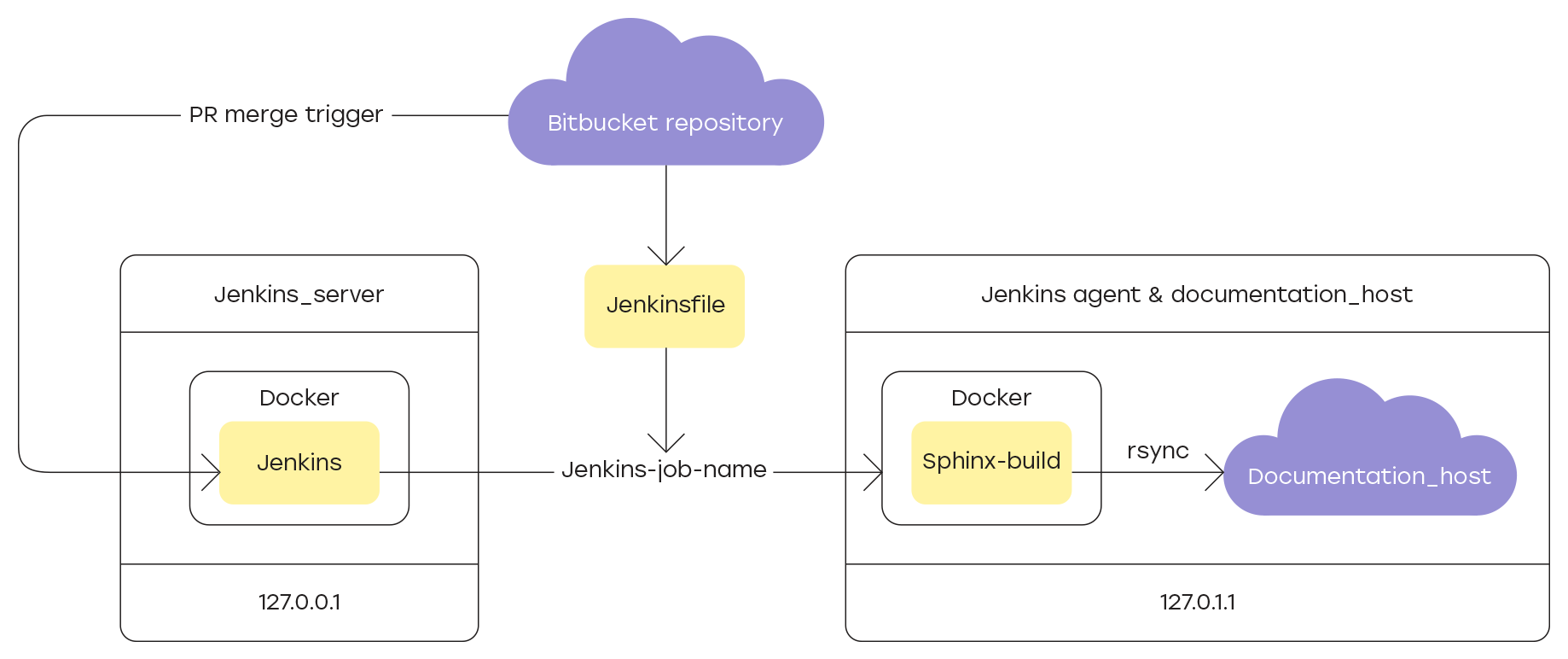
A implementação dessa lógica permite ao Jenkins - um sistema de integração contínua de desenvolvimento, no nosso caso - a documentação. Vou falar mais sobre as configurações nas seções:
- Adicionando um novo nó ao Jenkins
- Descrição do Jenkinsfile
- Integração Jenkins e Bitbucket
Adicionando um novo nó ao Jenkins
Para criar e atualizar a documentação no site, você deve registrar uma máquina previamente preparada como agente da Jenkins .
Preparação da máquina
De acordo com os requisitos da Jenkins , todos os componentes incluídos no sistema, incluindo a máquina principal e todos os nós do agente registrado, devem ter o JDK ou o JRE instalado. No nosso caso, o JDK 8 será usado, cuja instalação é suficiente para executar o comando:
sudo apt-get -y install java-1.8.0-openjdk git
A máquina principal se conectará ao agente para executar tarefas atribuídas nela. Para fazer isso, você precisa criar um usuário no agente sob o qual todas as operações serão executadas e no qual todos os arquivos gerados pelo Jenkins serão armazenados na pasta pessoal. Nos sistemas Linux, basta executar o comando:
sudo adduser jenkins \--shell /bin/bash su jenkins
Para estabelecer uma conexão entre a máquina principal e o agente, você deve configurar o SSH e adicionar as chaves de autorização necessárias. Geraremos as chaves no agente, após o que adicionaremos a chave pública ao arquivo allowed_keys para o usuário jenkins .
Criaremos o site com a documentação em um contêiner do Docker usando uma imagem python pronta : 3.7 . Siga as instruções na documentação oficial para instalar o Docker no agente. Para concluir o processo de instalação, você deve se reconectar ao agente. Verifique a instalação executando o comando que carrega a imagem de teste:
docker run hello-world
Para não precisar executar comandos do Docker em nome do superusuário (sudo), basta adicionar o grupo de janelas do usuário criado no estágio de instalação, em nome do qual os comandos serão executados.
sudo usermod -aG docker $USER
Configuração do novo nó Jenkins
Como a conexão ao agente requer autorização, você deve adicionar as credenciais apropriadas nas configurações do Jenkins. Instruções detalhadas sobre como fazer isso em máquinas Windows são fornecidas na documentação oficial do Jenkins .
IMPORTANTE: O identificador especificado na seção Configurar Jenkins -> Gerenciar ambientes de construção -> Nome do nó -> Configurar no parâmetro Tags é usado no Jenkinsfile para indicar o agente no qual todas as operações serão executadas.
Descrição do Jenkinsfile
A raiz do repositório do projeto contém o Jenkinsfile , que contém instruções para:
- Preparando o Ambiente de Construção e Instalando Dependências
- Crie um site usando o Sphinx
- atualizando informações do host.
As instruções são definidas usando diretivas especiais, cuja aplicação consideraremos mais adiante no exemplo do arquivo usado no projeto.
Indicação do agente
No início do arquivo Jenkins, especifique o rótulo do agente em Jenkins , no qual todas as operações serão executadas. Para fazer isso, use a diretiva de agente :
agent { label '-' }
Preparação do ambiente
Para executar o comando sphinx-build site build, é necessário definir variáveis de ambiente nas quais os caminhos de dados reais serão armazenados. Além disso, para atualizar as informações no host, você deve especificar antecipadamente os caminhos em que os dados do site com a documentação estão armazenados. A diretiva de ambiente permite atribuir esses valores a variáveis:
environment { SPHINX_DIR = '.' //, Sphinx BUILD_DIR = 'project_home_built' // SOURCE_DIR = 'project_home_source' // .rst .md DEPLOY_HOST = 'username@127.1.1.0:/var/www/html/' //@IP__:__ }
Principais ações
As principais instruções que serão executadas no Jenkinsfile estão contidas na diretiva estágios , que consiste nas diferentes etapas descritas pelas diretivas do estágio . Um exemplo simples de um pipeline de IC em três estágios:
pipeline { agent any stages { stage('Build') { steps { echo 'Building..' } } stage('Test') { steps { echo 'Testing..' } } stage('Deploy') { steps { echo 'Deploying....' } } } }
Inicie o contêiner do Docker e instale dependências
Primeiro, execute o contêiner do Docker com a imagem python concluída : 3.7 . Para fazer isso, use o comando docker run com os sinalizadores --rm e -i . Em seguida, faça o seguinte:
- instale o python virtualenv ;
- criar e ativar um novo ambiente virtual;
- instalar nele todas as dependências necessárias listadas no arquivo
requirements.txt, que é armazenado na raiz do repositório do projeto.
stage('Install Dependencies') { steps { sh ''' docker run --rm -i python:3.7 python3 -m pip install --user --upgrade pip python3 -m pip install --user virtualenv python3 -m virtualenv pyenv . pyenv/bin/activate pip install -r \${SPHINX\_DIR}/requirements.txt ''' } }
Construa um site com documentação
Agora vamos construir um site. Para fazer isso, execute o comando sphinx-build com os seguintes sinalizadores:
-q : apenas avisos e erros de log;
-w : escreve um log no arquivo especificado após o sinalizador;
-b : nome do construtor do site;
-d : especifique o diretório para armazenar arquivos em cache - pickles da doctree.
Antes de iniciar a montagem, usando o rm -rf exclua a montagem e os logs anteriores do site. Em caso de erro em um dos estágios, o log de execução do sphinx-build aparecerá no console do Jenkins .
stage('Build') { steps { // clear out old files sh 'rm -rf ${BUILD_DIR}' sh 'rm -f ${SPHINX_DIR}/sphinx-build.log' sh ''' ${WORKSPACE}/pyenv/bin/sphinx-build -q -w ${SPHINX_DIR}/sphinx-build.log \ -b html \ -d ${BUILD_DIR}/doctrees ${SOURCE\_DIR} ${BUILD\_DIR} ''' } post { failure { sh 'cat ${SPHINX_DIR}sphinx-build.log' } } }
Atualização do site host
E, finalmente, atualizaremos as informações no host que atende o site com a documentação do produto disponível no ambiente local. Na implementação atual, o host é a mesma máquina virtual registrada como um agente Jenkins para a tarefa de montar e atualizar a documentação.
Como ferramenta de sincronização, usamos o utilitário rsync . Para que funcione corretamente, é necessário configurar uma conexão SSH entre o contêiner do Docker, no qual estava indo o site com a documentação, e o host.
Para configurar a conexão SSH usando o Jenkinsfile , os seguintes plug-ins devem ser instalados no Jenkins :
- SSH Agent Plugin - permite que você use a etapa
sshagent nos scripts para fornecer credenciais no formulário nome de usuário / chave . - Plug - in de credenciais do SSH - permite salvar credenciais do nome de usuário / chave do formulário nas configurações do Jenkins .
Após instalar os plug-ins, você deve especificar as credenciais atuais para se conectar ao host, preenchendo o formulário na seção Credenciais :
- ID : identificador que será usado no arquivo Jenkins na etapa
sshagent para indicar credenciais específicas ( docs-deployer ); - Nome de usuário : o nome do usuário sob o qual as operações de atualização de dados do site serão executadas (o usuário deve ter acesso de gravação à pasta
/var/html do host); - Chave privada : uma chave privada para acessar o host;
- Senha : senha da chave, se ela tiver sido definida no estágio de geração.
Abaixo está o código de script que se conecta via SSH e atualiza as informações no host usando as variáveis do sistema especificadas no estágio de preparação do ambiente com os caminhos para os dados necessários. O resultado do comando rsync é gravado no log, que será exibido no console do Jenkins em caso de erros de sincronização.
stage('Deploy') { steps { sshagent(credentials: ['docs-deployer']) { sh ''' #!/bin/bash rm -f ${SPHINX_DIR}/rsync.log RSYNCOPT=(-aze 'ssh -o StrictHostKeyChecking=no') rsync "${RSYNCOPT[@]}" \ --delete \ ${BUILD_DIR_CI} ${DEPLOY_HOST}/ ''' } } post { failure { sh 'cat ${SPHINX_DIR}/rsync.log' } } }
Integração Jenkins e Bitbucket
Existem várias maneiras de organizar a interação de Jenkins e Bitbucket , mas em nosso projeto, decidimos usar o plug-in Parameterized Builds for Jenkins . A documentação oficial contém instruções detalhadas para a instalação do plug - in, bem como as configurações que devem ser especificadas para os dois sistemas. Para trabalhar com este plug-in, você precisa criar um usuário Jenkins e gerar um token especial para ele, que permitirá que esse usuário efetue login no sistema.
Criando um Usuário e um Token de API
Para criar um novo usuário no Jenkins , vá para Jenkins Configurações -> Gerenciamento de usuários -> Criar usuário e preencha todas as credenciais necessárias no formulário.
O mecanismo de autenticação que permite que scripts ou aplicativos de terceiros usem a API do Jenkins sem transmitir a senha do usuário é um token de API especial que pode ser gerado para cada usuário do Jenkins . Para fazer isso:
- efetue login no console de gerenciamento usando os detalhes do usuário criado anteriormente;
- vá para Configurar Jenkins -> Gerenciamento de Usuário ;
- clique no ícone de engrenagem à direita do nome do usuário sob o qual eles estão autorizados no sistema;
- encontre a API de token na lista de parâmetros e clique no botão Adicionar novo token ;
- no campo exibido, especifique o identificador do token da API e clique no botão Gerar ;
- seguindo o prompt na tela, copie e salve o token da API gerado.
Agora, nas configurações do servidor Bitbucket , você pode especificar o usuário padrão para se conectar ao Jenkins .
Conclusão
Se anteriormente, o processo consistia em várias etapas:
- Faça o download da atualização para o repositório
- aguarde confirmação de correção;
- montar um site com documentação;
- atualizar informações no host;
agora basta clicar em um botão Mesclar no Bitbucket. Se, após a verificação, não for necessário fazer alterações nos arquivos de origem, a versão atual da documentação será atualizada imediatamente após a confirmação da correção dos dados.
Isso simplifica bastante a tarefa do redator técnico, poupando-o de um grande número de ações manuais e os gerentes de projeto obtêm uma ferramenta conveniente para rastrear adições e comentários da documentação.
Automatizar esse processo é o primeiro passo na construção de uma infraestrutura de gerenciamento de documentação. No futuro, planejamos adicionar testes automáticos que verificarão a correção dos links externos usados na documentação e também queremos criar objetos de interface interativa que são incorporados a temas prontos para o Sphinx .
Obrigado a quem leu isso por atenção, em breve continuaremos compartilhando os detalhes da criação de documentação em nosso projeto!