Agora, o framework Vision é capaz de reconhecer texto de verdade, e não como antes. Esperamos ansiosamente quando podemos aplicar isso ao Dodo IS. Enquanto isso, uma tradução de um artigo sobre o reconhecimento de cartas do jogo de tabuleiro Magic The Gathering e a extração de informações textuais delas.
A estrutura do Vision foi introduzida pela primeira vez ao público em geral na WWDC em 2017, juntamente com o iOS 11.
O Vision foi criado para ajudar os desenvolvedores a classificar e identificar objetos, planos horizontais, códigos de barras, expressões faciais e texto.
No entanto, houve um problema com o reconhecimento de texto: a Vision conseguiu encontrar o local onde o texto está, mas o reconhecimento de texto real não ocorreu. Obviamente, foi bom ver a caixa delimitadora em torno de fragmentos de texto individuais, mas eles tiveram que ser retirados e reconhecidos independentemente.
Esse problema foi resolvido na atualização do Vision, incluída no iOS 13. Agora, a estrutura do Vision fornece reconhecimento de texto real.
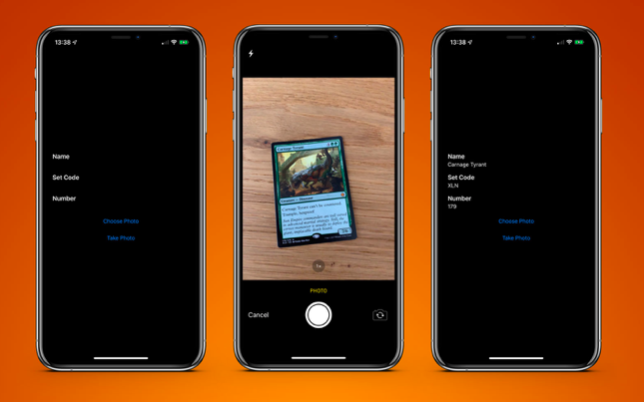
Para testar isso, criei um aplicativo muito simples que pode reconhecer um cartão do jogo de tabuleiro Magic The Gathering e extrair dele informações de texto:
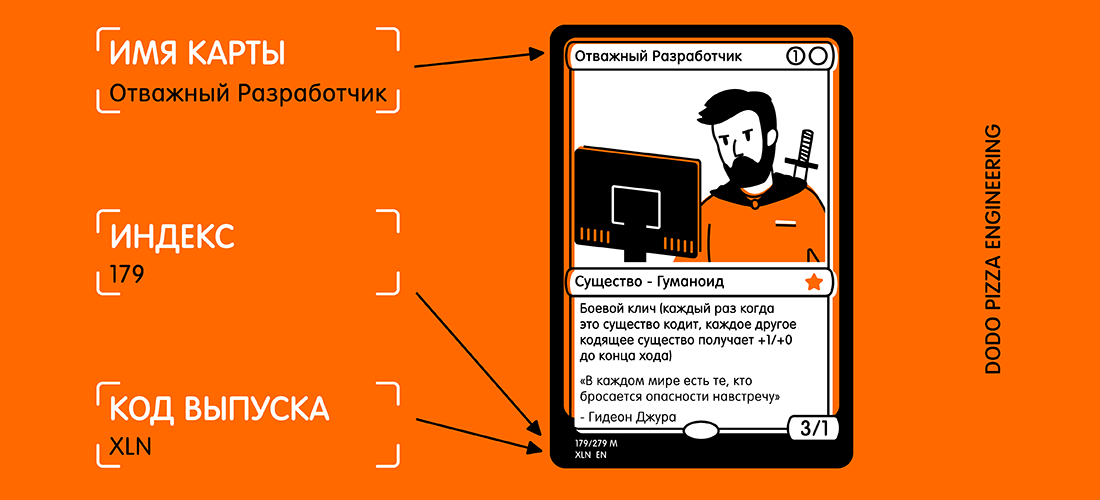
- nome do cartão;
- código de liberação;
- número da coleção (também conhecido como código postal).
Aqui está um exemplo de mapa e texto selecionado que eu gostaria de receber.

Olhando para o cartão, você pode pensar: "Este texto é bastante pequeno, e há muitos outros textos no cartão que podem interferir". Mas para a Vision, isso não é um problema.
Primeiro, precisamos criar um
VNRecognizeTextRequest . Em essência, esta é uma descrição do que esperamos reconhecer, além de uma configuração de idioma de reconhecimento e nível de precisão:
let request = VNRecognizeTextRequest(completionHandler: self.handleDetectedText) request.recognitionLevel = .accurate request.recognitionLanguages = ["en_GB"]
O bloco de conclusão possui o formato
handleDetectedText(request: VNRequest?, error: Error?) . Passamos para o construtor
VNRecognizeTextRequest e, em seguida, definimos as propriedades restantes.
Dois níveis de precisão de reconhecimento estão disponíveis:
.accurate e
.accurate . Como nosso cartão tem um texto bastante pequeno na parte inferior, escolhi uma precisão maior. A opção mais rápida provavelmente é mais adequada para grandes volumes de texto.
Limitei o reconhecimento ao inglês britânico, pois todos os meus cartões estão nele.Você pode especificar vários idiomas, mas precisa entender que a digitalização e o reconhecimento podem demorar um pouco mais para cada idioma adicional.
Há mais duas propriedades que vale a pena mencionar:
customWords - customWords : você pode adicionar uma matriz de seqüências de caracteres a serem usadas na parte superior do léxico interno. Isso é útil se houver alguma palavra incomum no seu texto. Eu não usei a opção para este projeto. Mas se eu fizesse o aplicativo comercial de reconhecimento de cartão Magic The Gathering, adicionaria alguns dos cartões mais complexos (por exemplo, Fblthp, The Lost ) para evitar problemas.minimumTextHeight : este é um valor flutuante. Indica o tamanho relativo à altura da imagem na qual o texto não deve mais ser reconhecido. Se eu criei esse scanner apenas para obter o nome do mapa, seria útil excluir todos os outros textos desnecessários. Mas eu preciso dos menores pedaços de texto, então, por enquanto, eu ignorei essa propriedade. Obviamente, ao ignorar textos pequenos, a velocidade de reconhecimento será maior.
Agora que temos nosso pedido, devemos transmiti-lo junto com a imagem ao manipulador de pedidos:
let requests = [textDetectionRequest] let imageRequestHandler = VNImageRequestHandler(cgImage: cgImage, orientation: .right, options: [:]) DispatchQueue.global(qos: .userInitiated).async { do { try imageRequestHandler.perform(requests) } catch let error { print("Error: \(error)") } }
Eu uso a imagem diretamente da câmera, convertendo-a de
UIImage para
CGImage . Isso é usado no
VNImageRequestHandler junto com o sinalizador de orientação para ajudar o manipulador a entender qual texto ele deve reconhecer.
Como parte desta demonstração, uso o telefone apenas na orientação retrato. Então, naturalmente, eu adiciono a orientação. Então padaji!
Acontece que a orientação da câmera no seu dispositivo é completamente separada da rotação do dispositivo e é sempre considerada à esquerda (como era padrão em 2009, para tirar fotos, você precisa manter o telefone na orientação paisagem). Obviamente, os tempos mudaram, e basicamente tiramos fotos e vídeos em formato retrato, mas a câmera ainda está alinhada à esquerda.
Assim que nosso manipulador é configurado, entramos no fluxo com a prioridade
.userInitiated e tentamos atender às nossas solicitações. Você pode perceber que essa é uma matriz de consultas. Isso acontece porque você pode tentar extrair vários dados em uma única passagem (ou seja, identificar rostos e texto da mesma imagem). Se não houver erros, o retorno de chamada criado usando nossa solicitação será chamado depois que o texto for detectado:
func handleDetectedText(request: VNRequest?, error: Error?) { if let error = error { print("ERROR: \(error)") return } guard let results = request?.results, results.count > 0 else { print("No text found") return } for result in results { if let observation = result as? VNRecognizedTextObservation { for text in observation.topCandidates(1) { print(text.string) print(text.confidence) print(observation.boundingBox) print("\n") } } } }
Nosso manipulador retorna nossa consulta, que agora tem a propriedade results. Cada resultado é uma
VNRecognizedTextObservation , que para nós tem várias opções para o resultado (daqui em diante - os candidatos).
Você pode obter até 10 candidatos para cada unidade de texto reconhecido e eles são classificados em ordem decrescente de confiança. Isso pode ser útil se você tiver certa terminologia que o analisador reconhece incorretamente na primeira tentativa. Mas determina corretamente mais tarde, mesmo se ele estiver menos confiante na exatidão do resultado.
Neste exemplo, precisamos apenas do primeiro resultado, então percorremos o arquivo
observation.topCandidates(1) e extraímos texto e confiança. Embora o próprio candidato tenha um texto e uma confiança diferentes, o
.boundingBox permanece o mesmo.
.boundingBox usa um sistema de coordenadas normalizado com a origem no canto inferior esquerdo; portanto, se ele for usado no UIKit no futuro, para sua conveniência, ele precisará ser convertido.
Isso é quase tudo que você precisa. Se eu executar uma
foto do cartão com isso, obtenho o seguinte resultado em menos de 0,5 segundos no iPhone XS Max:
Carnage Tyrant 1.0 (0.2654155572255453, 0.6955686092376709, 0.18710780143737793, 0.019915008544921786) Creature 1.0 (0.26317582130432127, 0.423814058303833, 0.09479101498921716, 0.013565015792846635) Dinosaur 1.0 (0.3883238156636556, 0.42648010253906254, 0.10021591186523438, 0.014479541778564364) Carnage Tyrant can't be countered. 1.0 (0.26538230578104655, 0.3742666244506836, 0.4300231456756592, 0.024643898010253906) Trample, hexproof 0.5 (0.2610074838002523, 0.34864263534545903, 0.23053167661031088, 0.022259855270385653) Sun Empire commanders are well versed 1.0 (0.2619712670644124, 0.31746063232421873, 0.45549616813659666, 0.022649812698364302) in advanced martial strategy. Still, the 1.0 (0.2623249689737956, 0.29798884391784664, 0.4314465204874674, 0.021180248260498136) correct maneuver is usually to deploy the 1.0 (0.2620727062225342, 0.2772137641906738, 0.4592740217844645, 0.02083740234375009) giant, implacable death lizard. 1.0 (0.2610833962758382, 0.252408218383789, 0.3502468903859457, 0.023736238479614258) 7/6 0.5 (0.6693102518717448, 0.23347826004028316, 0.04697717030843107, 0.018937730789184593) 179/279 M 1.0 (0.24829587936401368, 0.21893787384033203, 0.08339192072550453, 0.011646795272827193) XLN: EN N YEONG-HAO HAN 0.5 (0.246867307027181, 0.20903720855712893, 0.19095951716105145, 0.012227916717529319) TN & 0 2017 Wizards of the Coast 1.0 (0.5428387324015299, 0.21133480072021482, 0.19361832936604817, 0.011657810211181618)
Isso é inacreditável! Cada pedaço de texto foi reconhecido, colocado em sua própria caixa delimitadora e retornado como resultado com uma classificação de confiança de 1,0.
Mesmo um copyright muito pequeno está correto. Tudo isso foi feito em uma imagem de 3024x4032 com 3,1 MB. O processo seria ainda mais rápido se eu reduzisse a imagem pela primeira vez. Também é importante notar que esse processo é muito mais rápido nos novos chips biônicos A12, que possuem um mecanismo neural especial.
Quando o texto é reconhecido, a última coisa a fazer é retirar as informações de que preciso. Não colocarei todo o código aqui, mas a lógica da chave é
.boundingBox sobre cada
.boundingBox determinar o local, para que eu possa selecionar o texto no canto inferior esquerdo e no canto superior esquerdo, ignorando qualquer coisa mais à direita.
O resultado final é um aplicativo de cartão de digitalização e o retorno para mim em menos de um segundo.
PS Na verdade, eu só preciso de um código de liberação e um número de coleção (é um índice). Em seguida, eles podem ser usados na API do serviço Scryfall para obter todas as informações possíveis sobre este mapa, incluindo as regras do jogo e o custo.
Um aplicativo de amostra está disponível no
GitHub .