
Em um certo estágio de maturidade da segurança da informação, muitas empresas começam a pensar em como obter e usar informações sobre ameaças cibernéticas que são relevantes para elas. Dependendo das especificidades do setor da organização, diferentes tipos de ameaças podem causar interesse. A abordagem para o uso de tais informações foi formada por Lockheed Martin no material
Defense Driven Intelligence .
Felizmente, os serviços de segurança da informação têm muitas fontes para obtê-los e até uma classe separada de soluções - Threat Intelligence Platform (TIP), que permite gerenciar os processos de recebimento, geração e integração em ferramentas de segurança.
Como um centro para monitorar e responder a incidentes de segurança da informação, é extremamente importante para nós que as informações sobre as ameaças cibernéticas que recebemos e geramos sejam relevantes, aplicáveis e, principalmente, gerenciáveis. Afinal, a segurança das organizações que nos confiaram a proteção de sua infraestrutura depende disso.
Decidimos compartilhar nossa visão de TI no Jet CSIRT e conversar sobre a tentativa de adaptar várias abordagens potencialmente úteis para gerenciar a inteligência de ameaças cibernéticas.
No campo da cibersegurança, pouco funciona sobre o princípio do 'esquecimento'. O firewall não bloqueará pacotes até que os filtros sejam configurados, o IPS não encontre sinais de atividade maliciosa no tráfego, até que as assinaturas sejam baixadas para ele e o SIEM comece a escrever regras de correlação por conta própria e determinar falsos positivos. A inteligência sobre ameaças não é exceção.
A complexidade de implementar uma solução que realmente reflita o conceito de Inteligência contra ameaças está em sua própria definição.
A Inteligência de ameaças é um processo de pesquisa e análise de
certas fontes de informações para obter e acumular
informações sobre ameaças cibernéticas atuais , a fim de executar medidas para aprimorar a segurança cibernética e aumentar a conscientização sobre segurança de informações de uma
determinada comunidade de segurança da informação .
Certas fontes podem incluir:
- Fontes abertas de informação. Tudo isso pode ser encontrado usando o Google, Yandex, Bing e ferramentas mais especializadas, como Shodan, Censys, nmap. O processo de análise dessas fontes é chamado de Open Source Intelligence (OSINT). Note-se que as informações obtidas através do OSINT vêm de fontes abertas (não classificadas). Se a fonte for paga, isso pode não torná-la secreta, o que significa que a análise dessa fonte também é OSINT.
- A mídia. Tudo o que pode ser encontrado na mídia e nas plataformas sociais Sosial Media Intelligence (SOCMINT). Esse tipo de aquisição de dados é essencialmente parte integrante do OSINT.
- Locais e fóruns fechados que discutem os detalhes dos próximos crimes cibernéticos (deepweb, darknet). Principalmente nas áreas de sombra, você pode obter informações sobre ataques DDoS ou sobre a criação de um novo malware que os hackers estão tentando vender lá.
- Pessoas com acesso à informação. "Colegas" e pessoas que sucumbem aos métodos de engenharia social também são fontes que podem compartilhar informações.
Existem métodos mais sérios disponíveis apenas para serviços especializados. Nesse caso, os dados podem vir de agentes trabalhando disfarçados em um ambiente de crime cibernético ou de pessoas envolvidas no crime cibernético e colaborando com a investigação. Em uma palavra, tudo isso é chamado de HUMan Intelligence (HUMINT). Obviamente, não praticamos o HUMINT no Jet CSIRT.
Colocar todos esses processos em uma "caixa" que funcionará autonomamente é impossível. Portanto, quando se trata da solução de TI, provavelmente, sua principal proposta de valor para o consumidor é a própria
informação sobre ameaças cibernéticas e como gerenciá-las, acesso ao qual de uma forma ou de outra obtém a
comunidade de IB .
Informações sobre ameaças cibernéticas
Em 2015, a MWR Infosecurity, juntamente com o CERT e o Centro Nacional de Proteção de Infra-estrutura da Grã-Bretanha, publicou uma
brochura informativa que destacava quatro categorias de informações resultantes do processo de TI. Esta classificação agora é aplicada universalmente:
- Operação Informações sobre ataques cibernéticos futuros e em andamento, obtidos, em regra, por serviços especiais como resultado do processo HUMINT ou pelo uso de escutas telefônicas nos canais de comunicação dos atacantes.
- Estratégico. Informações relacionadas à avaliação de riscos para uma organização se tornar vítima de um ataque cibernético. Eles não contêm nenhuma informação técnica e de forma alguma podem ser usados em equipamentos de proteção.
- Tático. Informações sobre as técnicas, táticas, procedimentos (TTP) e ferramentas que os cibercriminosos usam como parte de uma campanha maliciosa.
Caso em questão - LockerGoga recentemente aberto- Ferramenta : cmd.exe.
- Técnica : um crypto-locker é iniciado, que criptografa todos os arquivos no computador da vítima (incluindo arquivos de kernel do Windows) usando o algoritmo AES no modo de criptografia CTR (block) (CTR) com um comprimento de chave de 128 bits. A chave do arquivo e o vetor de inicialização (IV) são criptografados usando o algoritmo RSA-1024, usando a função de geração de máscara MGF1 (SHA-1). Por sua vez, para aumentar a força criptográfica dessa função, o esquema de preenchimento da OAEP é usado. As chaves criptografadas do arquivo e IV são armazenadas no cabeçalho do próprio arquivo criptografado.
- Procedimento : Além disso, o malware inicia vários processos filhos paralelos, criptografando apenas a cada 80.000 bytes de cada arquivo, pulando os próximos 80.000 bytes para acelerar a criptografia.
- Táticas : então, é necessário um resgate em bitcoins para que a chave descriptografe os arquivos novamente.
Leia mais
aqui .
Essas informações aparecem como resultado de uma investigação completa de uma campanha maliciosa, que pode levar um longo tempo. Os resultados desses estudos são boletins e relatórios de empresas comerciais, como Cisco Talos, FireEye, Symantec, Group-IB, Kaspersky GREAT, organizações e órgãos governamentais (FinCERT, NCCCI, US-CERT, FS-ISAC), além de pesquisadores independentes.
Informações táticas podem e devem ser usadas em equipamentos de segurança e na construção de uma arquitetura de rede.
- Técnico Informações sobre os sinais e essências de atividades maliciosas ou sobre como identificá-los.
Por exemplo, ao analisar malware, verificou-se que ele se espalha como um arquivo .pdf com os seguintes parâmetros:
- chamado price_december.pdf ,
- iniciando o processo pureevil.exe ,
- ter um hash MD5 de 81a284a2b84dde3230ff339415b0112a ,
- que está tentando estabelecer conexões com o servidor C&C em 123.45.67.89 na porta TCP 1337 .
Neste exemplo, as entidades são os nomes de arquivo e processo, o valor do hash, o endereço do servidor e o número da porta. Sinais são a interação dessas entidades entre si e os componentes da infraestrutura: iniciando o processo, interagindo com a rede de saída com o servidor, alterando chaves do registro etc.
Esta informação está intimamente relacionada ao conceito de indicador de compromisso (IoC). Tecnicamente, desde que a entidade não seja encontrada na infraestrutura, ela ainda não diz nada. Mas se, por exemplo, você encontrar na rede o fato de tentar conectar o host ao servidor C&C em
123.45.67.89:1337 ou o início do processo
pureevil.exe e mesmo com a soma
MDa 81a284a2b84dde3230ff339415b0112a , esse já é um indicador de comprometimento.
Ou seja, o indicador de comprometimento é uma combinação de certas entidades, sinais de atividade maliciosa e informações contextuais que exigem resposta dos serviços de segurança da informação.
Ao mesmo tempo, na esfera da segurança da informação, é habitual chamar indicadores de comprometimento apenas entidades que foram notadas por alguém em atividade maliciosa (endereços IP, nomes de domínio, valores de hash, URLs, nomes de arquivos, chaves de registro etc.).
A detecção de um indicador de comprometimento sinaliza apenas que esse fato deve ser prestado atenção e analisado para determinar outras ações. Não é categoricamente recomendado bloquear imediatamente o indicador no SZI sem esclarecer todas as circunstâncias. Mas falaremos mais sobre isso.
Os indicadores de compromisso também são convenientemente divididos em:
- Atômica. Eles contêm apenas um recurso que não pode mais ser dividido, por exemplo:
- Endereço IP do servidor C e C - 123.45.67.89
- O valor do hash é 81a284a2b84dde3230ff339415b0112a
- Composto Eles contêm duas ou mais entidades vistas em atividades maliciosas, por exemplo:
- Soquete - 123.45.67.89:5900
- O arquivo price_december.pdf gerará o processo pureevil.exe com um hash 81a284a2b84dde3230ff339415b0112a
Obviamente, a detecção de um indicador composto provavelmente indicará um comprometimento do sistema.
As informações técnicas também podem incluir várias entidades para detectar e bloquear indicadores de comprometimento, por exemplo, regras Yara, regras de correlação para SIEM, várias assinaturas para detectar ataques e malware. Assim, as informações técnicas podem ser claramente aplicadas aos equipamentos de proteção.
Problemas de uso eficiente de informações técnicas de TI
Mais rapidamente, os provedores de serviços de TI podem obter exatamente as informações técnicas sobre ameaças cibernéticas, e como aplicá-las é totalmente uma questão para o consumidor. É aqui que estão a maioria dos problemas.
Por exemplo, indicadores de comprometimento podem ser aplicados em vários estágios de resposta a um incidente de SI:
- na fase de preparação (Preparação), bloqueio proativo do indicador no SIS (é claro, após a exceção falso-positiva);
- no estágio de detecção, rastreando a operação das regras para identificação do indicador em tempo real, por meio de ferramentas de monitoramento (SIEM, SIM, LM);
- na fase de investigação do incidente, usando o indicador em verificações retrospectivas;
- no estágio de uma análise mais aprofundada dos ativos afetados, por exemplo, ao analisar o código-fonte de uma amostra maliciosa.
Quanto mais trabalho manual estiver envolvido em um estágio ou outro, mais análises (enriquecendo a essência do indicador com informações contextuais) serão necessárias para os fornecedores de indicadores de comprometimento. Nesse caso, estamos falando de informações contextuais externas, ou seja, sobre o que os outros já sabem sobre esse indicador.
Normalmente, os indicadores de comprometimento são entregues na forma dos chamados
feeds ou
feeds de ameaças . Essa é uma lista estruturada de dados de ameaças em vários formatos.
Por exemplo, a seguir, um hash feed malicioso no formato json:

Este é um exemplo de um bom feed rico em contexto:
- contém um link para análise de ameaças;
- nome, tipo e categoria de ameaça;
- carimbo de data e hora da publicação.
Tudo isso permite que você gerencie os indicadores de comprometimento desse feed ao fazer o upload para ferramentas de proteção e monitoramento de informações, além de reduzir o tempo para analisar os incidentes que trabalharam neles.
Mas existem outros feeds de qualidade (geralmente de código aberto). Por exemplo, a seguir, é apresentado um exemplo dos endereços de servidores supostamente C&C de um código-fonte aberto:

Como você pode ver, as informações contextuais estão completamente ausentes aqui. Qualquer um desses endereços IP pode hospedar um serviço legítimo, alguns dos quais podem ser rastreadores Yandex ou Google que indexam sites. Não podemos dizer nada sobre esta lista.
A ausência ou insuficiência de contexto nos feeds de ameaças é um dos principais problemas para os consumidores de informações técnicas. Sem contexto, a entidade do feed não é aplicável e, de fato, não é um indicador de comprometimento. Em outras palavras, o bloqueio de qualquer endereço IP no SZI, bem como o upload desse feed para ferramentas de monitoramento, provavelmente levará a um grande número de falsos positivos (falso positivo - FP).
Se considerarmos o uso de indicadores de comprometimento do ponto de vista da detecção nas ferramentas de monitoramento, simplificar esse processo é uma sequência:
- integração de indicadores em ferramentas de monitoramento;
- acionando a regra de detecção de indicador;
- Análise de resposta de serviço de SI.
Devido à presença de recursos humanos nessa sequência, estamos interessados em analisar apenas os casos de identificação de indicadores que realmente indiquem uma ameaça à organização e reduzam o número de FPs.
Basicamente, os falsos positivos são desencadeados pela detecção da essência dos recursos populares (Google, Microsoft, Yandex, Adobe etc.) como potencialmente maliciosos.
Um exemplo simples: examina malware que atingiu o host. Foi descoberto que ele verifica o acesso à Internet pesquisando
update.googleapis.com . O ativo
update.googleapis.com está
listado no feed de ameaças como um indicador de comprometimento e chama FP. Da mesma forma, a soma de hash de uma biblioteca ou arquivo legítimo usada por malware, endereços DNS públicos, endereços de vários rastreadores e aranhas, recursos para verificar certificados CRL revogados (lista de revogação de certificados) e abreviações de URL (bit.ly, goo) podem entrar no feed. gl, etc.).
Testar esse tipo de resposta, não enriquecido em um contexto externo, pode levar um tempo bastante grande para o analista, durante o qual um incidente real pode ser perdido.
A propósito, existem feeds de indicadores que podem acionar o FP. Um exemplo é o
recurso misp-warninglist .
Priorização de indicadores de compromisso
Outro problema é a priorização de respostas. Em termos relativos, que tipo de SLA teremos ao detectar um indicador específico de comprometimento. De fato, os provedores de feeds de ameaças não priorizam as entidades que eles contêm. Para ajudar os consumidores, eles podem adicionar um certo grau de confiança à nocividade de uma entidade, como é feito nos feeds da Kaspersky Lab:

No entanto, priorizar os eventos de identificação de indicadores é tarefa do consumidor.
Para resolver esse problema no Jet CSIRT, adaptamos a
abordagem descrita por Ryan Kazanciyan em COUNTERMEASURE 2016. Sua essência é que todos os indicadores de comprometimento que podem ser encontrados na infraestrutura são considerados do ponto de vista de pertencer a
domínios de sistema e
domínios de dados .
Os domínios de dados estão em 3 categorias:
- Atividade em tempo real na fonte (o que atualmente armazena na memória; detectada por meio da análise de eventos de segurança da informação em tempo real):
- iniciar processos, alterar chaves do registro, criar arquivos;
- atividade de rede, conexões ativas;
- outros eventos acabados de gerar.
Se um indicador desta categoria for detectado, o tempo de resposta dos serviços de IS é mínimo .
- Atividade histórica (o que já aconteceu; revelado durante verificações retrospectivas):
- toras históricas;
- telemetria;
- alertas acionados.
Se um indicador desta categoria for detectado, o tempo de reação dos serviços de SI é permitido .
- Dados em repouso (o que já existia antes de conectarmos a fonte ao monitoramento; eles são revelados como parte de verificações retrospectivas de fontes não utilizadas há muito tempo):
- arquivos que há muito são armazenados na fonte;
- chaves de registro;
- outros objetos não utilizados.
Se um indicador dessa categoria for detectado, o tempo de reação dos serviços de SI será limitado pela duração da investigação completa do incidente .
Geralmente, relatórios e boletins detalhados são compilados com base nessas investigações, com uma análise detalhada das ações dos atacantes, mas a relevância desses dados é relativamente pequena.
Ou seja
, domínios de dados são o estado dos dados analisados nos quais um indicador de comprometimento foi detectado.
Os domínios do sistema são a afiliação da fonte do indicador de comprometimento a um dos subsistemas de infraestrutura:
- Estações de trabalho. Fontes usadas diretamente pelo usuário para realizar o trabalho diário: estações de trabalho, laptops, tablets, smartphones, terminais (VoIP, VKS, IM), programas aplicativos (CRM, ERP, etc.).
- Servidores. Refere-se a outros dispositivos que atendem à infraestrutura, ou seja, dispositivos para a operação do complexo de TI: SZI (FW, IDS / IPS, AV, EDR, DLP), dispositivos de rede, servidores de arquivos / web / proxy, sistemas de armazenamento, ACS, controle ambiental. ambiente etc.

Combinando essas informações com a composição dos sinais de um indicador de comprometimento
(átomo, composto) , dependendo do tempo de reação aceitável, você pode formular a prioridade do incidente quando for detectado:
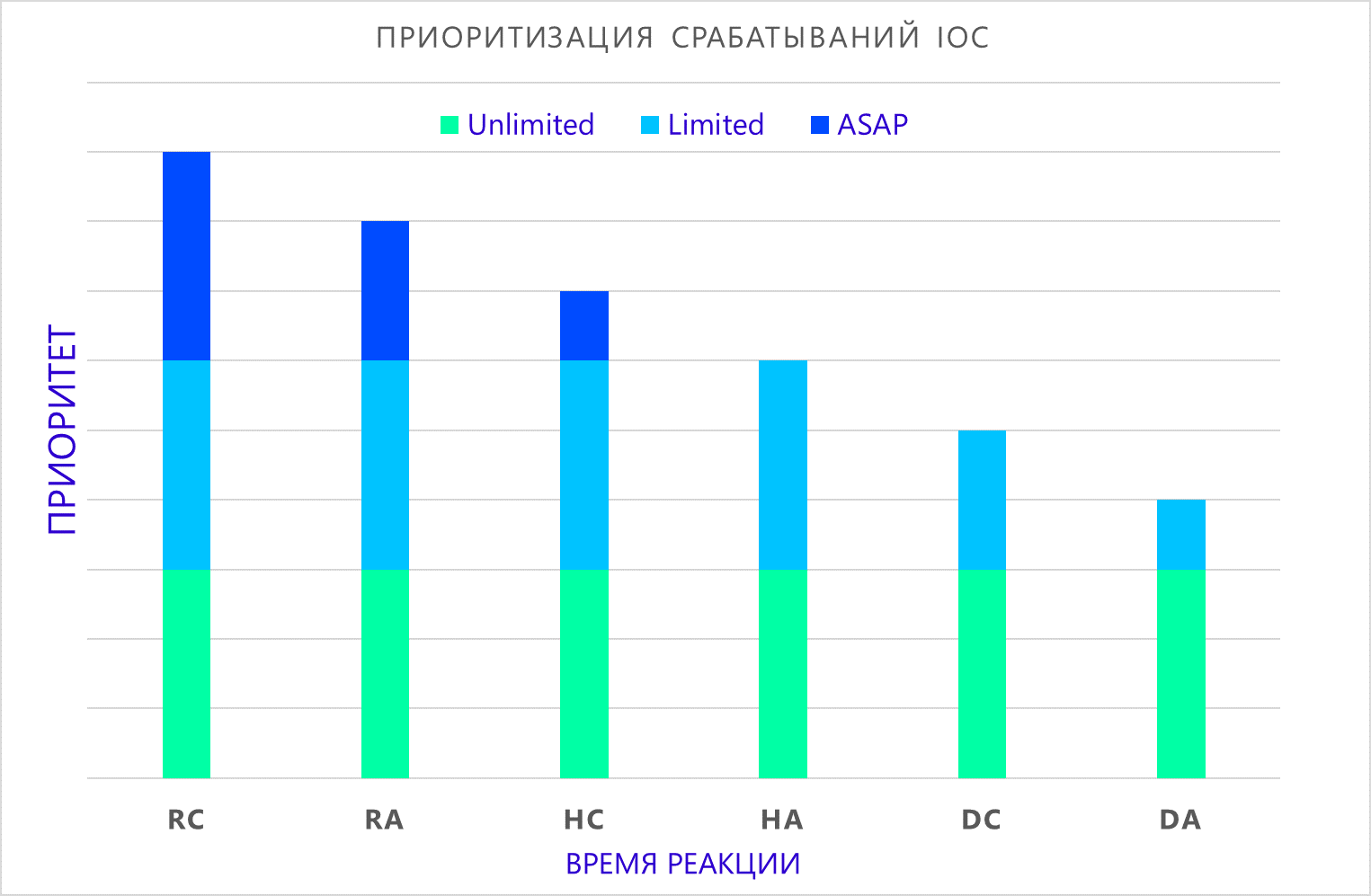
- O mais rápido possível A detecção de um indicador requer uma resposta imediata da equipe de resposta.
- Limitada A detecção do indicador requer uma análise adicional para esclarecer as circunstâncias do incidente e decidir sobre outras ações.
- Ilimitado A detecção do indicador requer uma investigação completa e a preparação de um relatório sobre as atividades dos atacantes. Normalmente, essas descobertas são investigadas no âmbito da investigação forense, que pode durar anos.
Onde:
- RC - detecção de indicadores compostos em tempo real;
- RA - detecção de um indicador atômico em tempo real;
- HC - detecção de um indicador composto como parte de uma verificação retrospectiva;
- HA - detecção de um indicador atômico como parte de uma verificação retrospectiva;
- DC - detecção de um indicador composto em fontes longas não utilizadas;
- DA - detecção de um indicador atômico em fontes longas não utilizadas.
Devo dizer que a prioridade não diminui a importância de detectar um indicador, mas mostra o tempo aproximado que temos para evitar um possível comprometimento da infraestrutura.
Também é justo observar que tal abordagem não pode ser usada isoladamente da infraestrutura observada, retornaremos a isso.
Monitorando a vida dos indicadores de compromisso
Existem algumas entidades maliciosas que deixam o indicador de comprometimento para sempre. Excluir essas informações, mesmo após um longo período de tempo, não é recomendado. Isso geralmente se torna relevante nas auditorias retrospectivas
(NA / HA) e na verificação de fontes longas e não utilizadas
(DC / DA) .
Alguns centros de monitoramento e fornecedores de indicadores de comprometimento consideram desnecessário controlar o tempo de vida de todos os indicadores em geral. No entanto, na prática, essa abordagem se torna ineficaz. De fato, indicadores de comprometimento como, por exemplo, hashes de arquivos maliciosos, chaves de registro geradas por malware e URLs através dos quais um nó está infectado nunca se tornarão entidades legítimas, ou seja, sua validade não é limitada.Caso em questão: análise SHA-256 da soma de um arquivo RAT Vermin com um protocolo SOAP encapsulado para troca de dados com um servidor C & C. A análise mostra que o arquivo foi criado em 2015. Recentemente, o encontramos em um dos servidores de arquivos de nossos clientes.
De fato, indicadores de comprometimento como, por exemplo, hashes de arquivos maliciosos, chaves de registro geradas por malware e URLs através dos quais um nó está infectado nunca se tornarão entidades legítimas, ou seja, sua validade não é limitada.Caso em questão: análise SHA-256 da soma de um arquivo RAT Vermin com um protocolo SOAP encapsulado para troca de dados com um servidor C & C. A análise mostra que o arquivo foi criado em 2015. Recentemente, o encontramos em um dos servidores de arquivos de nossos clientes.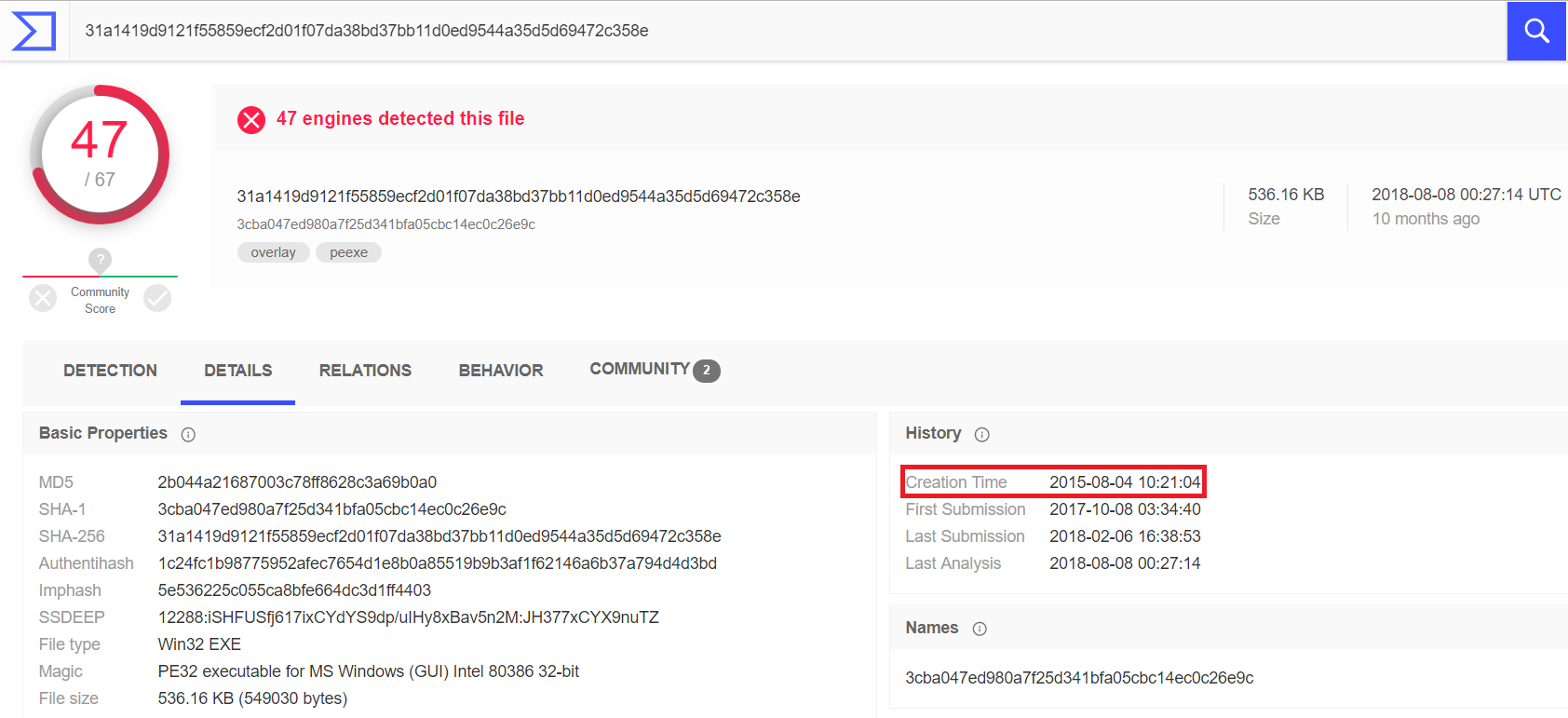 No entanto, uma imagem completamente diferente será do tipo de entidades que foram criadas ou "emprestadas" por um tempo para uma campanha maliciosa. Na verdade, são pontos finais sob o controle de intrusos.Essas entidades podem se tornar legítimas novamente depois que seus proprietários limparem os nós comprometidos ou quando os invasores deixarem de usar a próxima infraestrutura.Levando em consideração esses fatores, é possível criar uma tabela aproximada de indicadores de comprometimento com referência aos domínios de dados, o período de sua relevância e a necessidade de controlar seu ciclo de vida:
No entanto, uma imagem completamente diferente será do tipo de entidades que foram criadas ou "emprestadas" por um tempo para uma campanha maliciosa. Na verdade, são pontos finais sob o controle de intrusos.Essas entidades podem se tornar legítimas novamente depois que seus proprietários limparem os nós comprometidos ou quando os invasores deixarem de usar a próxima infraestrutura.Levando em consideração esses fatores, é possível criar uma tabela aproximada de indicadores de comprometimento com referência aos domínios de dados, o período de sua relevância e a necessidade de controlar seu ciclo de vida: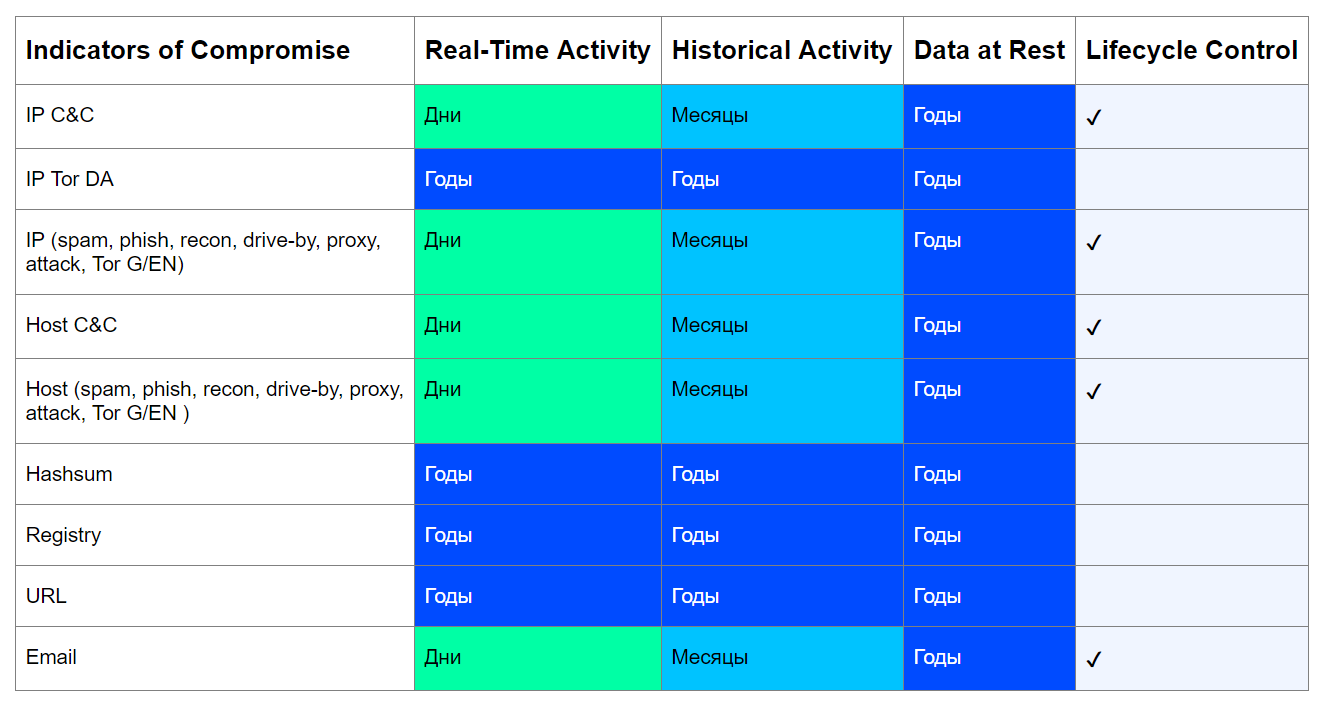 O objetivo desta tabela é responder a três perguntas:
O objetivo desta tabela é responder a três perguntas:- Esse indicador pode se tornar legítimo ao longo do tempo?
- Qual o período mínimo de relevância de um indicador, dependendo do estado dos dados analisados?
- Preciso controlar a vida deste indicador?
Considere esta abordagem usando o exemplo de um servidor IP C & C. Hoje, os atacantes preferem aumentar uma infraestrutura distribuída, alterando frequentemente os endereços para passar despercebidos e evitar possíveis bloqueios do provedor. Ao mesmo tempo, o C&C é frequentemente implantado em nós hackeados, como, por exemplo, no caso do Emotet . No entanto, as botnets estão sendo eliminadas, os vilões estão sendo capturados, portanto, um indicador como o endereço IP do servidor C & C certamente pode se tornar uma entidade legítima, o que significa que sua vida útil pode ser controlada.Se encontrarmos chamadas para o servidor IP C & C em tempo real (RA / RC), o período de sua relevância para nós será calculado em dias. Afinal, é improvável que, no dia seguinte à descoberta, esse endereço não hospede mais o C&C.A detecção desse indicador em verificações retrospectivas (HA / HC), que geralmente têm intervalos mais longos (uma vez a cada poucas semanas / meses), também indicará um período mínimo de relevância igual ao intervalo correspondente. Ao mesmo tempo, a própria C&C pode não estar mais ativa, mas se encontrarmos um fato de circulação em nossa infraestrutura, o indicador será relevante para nós.A mesma lógica se aplica a outros tipos de indicadores. As exceções são valores de hash, chaves do Registro, nós da rede Directory Authority (DA) Tor e URLs.Com hashes e valores de registro, tudo é simples - eles não podem ser removidos da natureza; portanto, não faz sentido controlar sua vida útil. Mas os URLs maliciosos podem ser removidos, é claro que não serão legítimos, mas ficarão inativos. No entanto, eles também são únicos e são criados especificamente para uma campanha maliciosa, portanto, não podem se tornar legítimos.Os endereços IP dos nós DA da rede Tor são conhecidos e inalterados, sua vida útil é limitada apenas pela vida útil da rede Tor, portanto, esses indicadores são sempre relevantes.Como você pode ver, para a maioria dos tipos de indicadores da tabela, é necessário o controle de sua vida útil.Nós da Jet CSIRT defendemos essa abordagem pelos seguintes motivos.- , - , - , , , .
, Microsoft 99 , APT35. - Microsoft .
IP- , -. , IP- «», , . - , .
, , , . - .
, . 1 MS Office, -, . , , , .
É por isso que consideramos importante agora nos esforçar para adaptar processos e desenvolver abordagens para controlar a vida útil dos indicadores integrados aos meios de proteção.Uma dessas abordagens é descrita nos Indicadores de comprometimento em decomposição do Centro de Resposta a Emergências Informáticas do Luxemburgo (CIRCL), cuja equipe criou uma plataforma para o intercâmbio de informações sobre ameaças MISP . É no MISP que está planejado aplicar idéias deste material. Para fazer isso, basicamente os repositórios do projeto já abriram o ramo apropriado , o que mais uma vez prova a relevância desse problema para a comunidade de segurança da informação.Essa abordagem pressupõe que o tempo de vida de alguns indicadores não seja homogêneo e pode mudar conforme:- os invasores param de usar sua infraestrutura em ataques cibernéticos;
- ele aprende sobre o ataque cibernético cada vez mais especialistas em segurança da informação e coloca indicadores no bloco do SZI, forçando os invasores a alterar os elementos usados.
Assim, a vida útil de tais indicadores pode ser descrita na forma de uma determinada função que caracteriza a taxa de saída da data de vencimento de cada indicador ao longo do tempo.Os colegas do CIRCL constroem seu modelo usando as condições usadas no MISP; no entanto, a ideia geral do modelo pode ser usada fora do produto:- o indicador de compromisso (a) recebe uma determinada avaliação básica (
No material CIRCL, isso é levado em consideração pela confiabilidade / confiança no fornecedor do indicador e nas taxonomias relacionadas. Ao mesmo tempo, após a detecção repetida do indicador, a avaliação básica pode mudar - aumentar ou diminuir, dependendo dos algoritmos do provedor.- Hora é inserida
- É introduzido o conceito da taxa de saída da taxa de expiração do indicador (decay_rate).
- Registros de data e hora inseridos
Dadas todas as condições acima, os colegas do CIRCL fornecem a seguinte fórmula para calcular a pontuação geral (1):
Onde.
O material CIRCL fornece um exemplo do chamado tempo de cortesia - um tempo fixo para correção, que o provedor fornece ao proprietário do recurso, observado em atividades suspeitas, antes de desconectá-lo. Mas para a maioria dos tipos de indicadoresPortanto, tentamos vincular cada tipo de indicador, para o qual é possível o monitoramento do ciclo de vida, com sua taxa de vencimento (decay_rate), o tipo de infraestrutura observada e seu nível de maturidade em segurança da informação.Ao fazer um inventário da infraestrutura protegida específica, descobrindo a idade do software e do equipamento que ela usa, determinamos decay_rate para cada tipo de indicador de comprometimento. Um resultado aproximado desse trabalho pode ser apresentado na forma de uma tabela: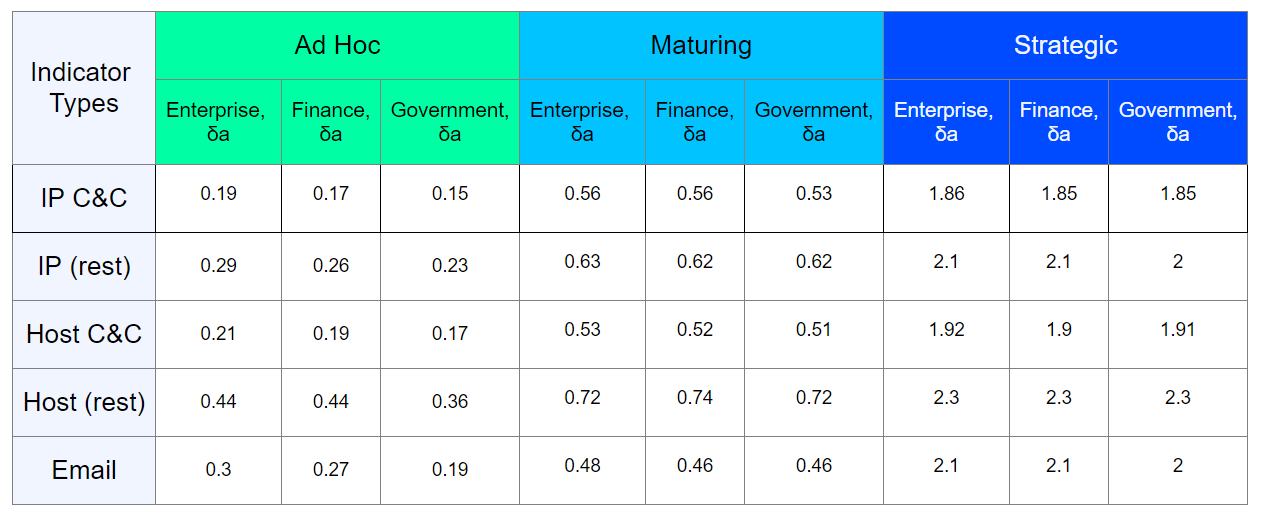 enfatizo mais uma vez que o resultado na tabela é aproximado; na realidade, a avaliação deve ser realizada individualmente para uma infraestrutura específica.Com o advento das datas de vencimento de cada indicador, podemos determinar o tempo aproximado em que eles podem ser baixados. Também é importante notar que o cálculo do tempo de baixa deve ser realizado apenas quando houver uma tendência a uma diminuição na pontuação do indicador base.Por exemplo, considere um indicador com uma classificação básica de 80, tempo
enfatizo mais uma vez que o resultado na tabela é aproximado; na realidade, a avaliação deve ser realizada individualmente para uma infraestrutura específica.Com o advento das datas de vencimento de cada indicador, podemos determinar o tempo aproximado em que eles podem ser baixados. Também é importante notar que o cálculo do tempo de baixa deve ser realizado apenas quando houver uma tendência a uma diminuição na pontuação do indicador base.Por exemplo, considere um indicador com uma classificação básica de 80, tempo A abordagem descrita é bastante difícil de implementar, mas seu charme é que podemos realizar testes sem afetar os processos estabelecidos de segurança da informação e a infraestrutura dos clientes. Agora, estamos executando o algoritmo para monitorar o tempo de vida de uma determinada amostra de indicadores, que, hipoteticamente, podem cair no descomissionamento. No entanto, esses indicadores permanecem em operação no SZI. Relativamente falando, pegamos uma amostra de indicadores, consideramos para eles
A abordagem descrita é bastante difícil de implementar, mas seu charme é que podemos realizar testes sem afetar os processos estabelecidos de segurança da informação e a infraestrutura dos clientes. Agora, estamos executando o algoritmo para monitorar o tempo de vida de uma determinada amostra de indicadores, que, hipoteticamente, podem cair no descomissionamento. No entanto, esses indicadores permanecem em operação no SZI. Relativamente falando, pegamos uma amostra de indicadores, consideramos para elesConclusão
O Treat Intelligence é, é claro, um conceito de segurança da informação necessário e útil que pode aumentar significativamente a segurança da infraestrutura da empresa. Para alcançar o uso efetivo da TI, você precisa entender como podemos usar as várias informações obtidas por esse processo.Falando sobre as informações técnicas da Inteligência de Ameaças, como feeds de ameaças e indicadores de comprometimento, devemos lembrar que o método de seu uso não deve se basear em listas negras ocultas. Na aparência, um algoritmo simples para detectar e subsequentemente bloquear uma ameaça tem muitas “armadilhas”; portanto, para usar efetivamente as informações técnicas, é necessário avaliar corretamente sua qualidade, determinar a prioridade das detecções e também controlar seu tempo de vida para reduzir a carga no SPI.No entanto, confie apenas no conhecimento técnico da Inteligência contra ameaças. É muito mais importante adaptar as informações táticas aos processos de defesa. De fato, é muito mais difícil para os invasores mudarem de tática, técnicas e ferramentas, em vez de nos forçar a perseguir outra porção de indicadores de comprometimento, que foi descoberta após um ataque de hackers. Mas falaremos sobre isso em nossos próximos artigos.Autor: Alexander Akhremchik, especialista no Centro de resposta e monitoramento a jato de infraestrutura a jato Infosystems, Jet CSIRT