Neste artigo, veremos como criar um programa Go, como um compilador ou analisador estático, que interaja com a estrutura de compilação do LLVM usando a linguagem de montagem do LLVM IR.
TL; DR , escrevemos uma biblioteca para interagir com o LLVM IR no Go puro, consulte os links para o código e um exemplo de projeto.
Um exemplo simples de LLVM IR
(Aqueles que você conhece o LLVM IR podem pular para a próxima seção).
LLVM IR é a representação intermediária de baixo nível usada pela estrutura de compilação do LLVM. Você pode pensar no LLVM IR como um montador independente de plataforma com um número infinito de registros locais.
Ao projetar um compilador, há uma enorme vantagem em compilar o idioma de origem em uma representação intermediária (IR, representação intermediária) em vez de compilá-lo na arquitetura de destino (por exemplo, x86).
SpoilerA idéia de usar uma linguagem intermediária nos compiladores é generalizada. O GCC usa o GIMPLE, o Roslyn usa o CIL, o LLVM usa o LLVM IR.
Como muitas técnicas de otimização são comuns (por exemplo, remoção de código não utilizado, distribuição de constantes), essas passagens de otimização podem ser realizadas diretamente no nível de IR e usadas por todas as plataformas de destino.
SpoilerO uso de uma linguagem intermediária (IR) reduz o número de combinações necessárias para n idiomas de origem e m arquiteturas de destino (back-end) de n * m para n + m.
Assim, os compiladores geralmente consistem em três partes: frontend, middleland e backend, cada um deles executa sua própria tarefa, aceitando entrada e / ou fornecendo saída IR.
- Frontend: compila o idioma de origem no IR
- Middleland: otimiza RI
- Back-end: compila RI em código de máquina
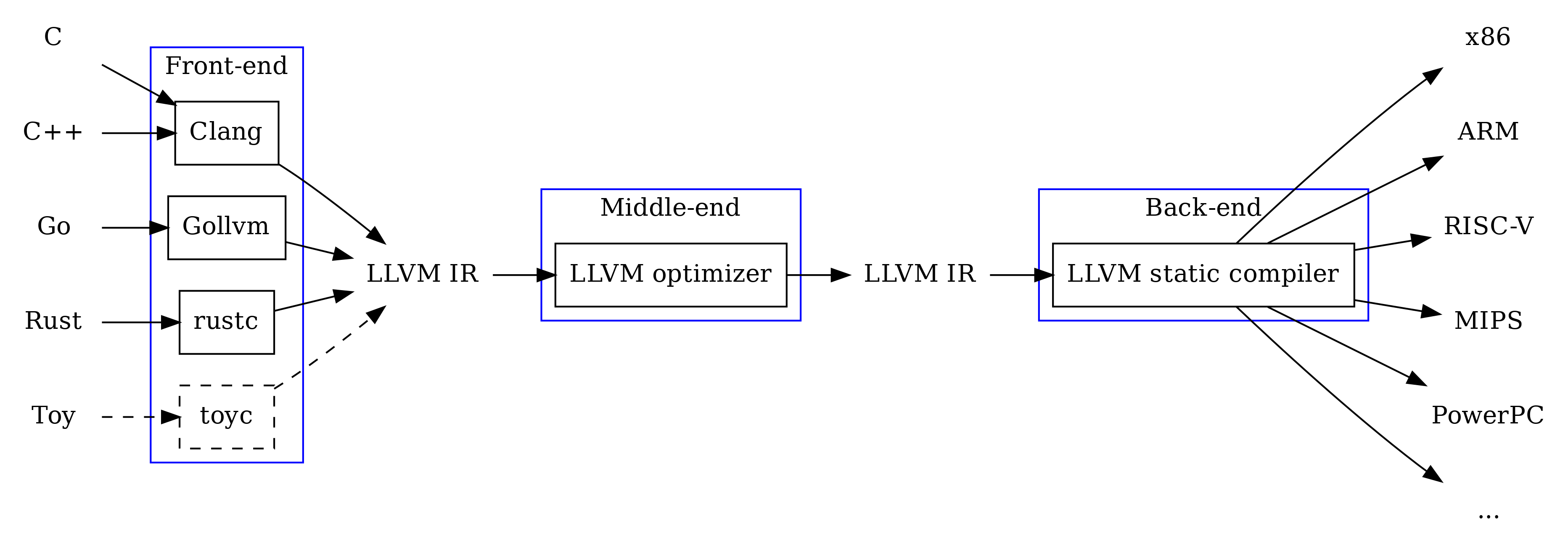
Programa de amostra do assembler LLVM IR
Para ter uma ideia da aparência do assembler de LLVM IR, considere o seguinte programa.
int f(int a, int b) { return a + 2*b; } int main() { return f(10, 20); }
Usamos Clang e compilamos o código C acima no assembler LLVM IR.
Clangclang -S -emit-llvm -o foo.ll foo.c.
define i32 @f(i32 %a, i32 %b) { ; <label>:0 %1 = mul i32 2, %b %2 = add i32 %a, %1 ret i32 %2 } define i32 @main() { ; <label>:0 %1 = call i32 @f(i32 10, i32 20) ret i32 %1 }
Observando o código do assembler de LLVM IR acima, podemos observar alguns recursos dignos de nota de LLVM IR, a saber:
O IR LLVM é estaticamente tipado (ou seja, números inteiros de 32 bits são cruzados pelo tipo i32).
Variáveis locais têm escopo dentro da função (ou seja,% 1 em
main é diferente de% 1 em @f).
Sem nome (registros temporários) recebem identificadores locais (por exemplo,% 1,% 2), em ordem crescente, em cada uma das funções. Cada função pode usar um número infinito de registros (não limitado a 32 registros de uso geral). Identificadores globais (por exemplo, @f) e identificadores locais (por exemplo,% a,% 1) são diferenciados por um prefixo (@ e%, respectivamente).
A maioria dos comandos faz o que você espera, assim o mul faz a multiplicação, adiciona adição, etc.
Os comentários começam com, como é habitual nas linguagens assembly.
Estrutura do montador de LLMV IR
O conteúdo do arquivo de montagem do LLVM IR é um módulo. O módulo contém declarações de alto nível, como variáveis e funções globais.
Uma declaração de função não contém blocos base, uma definição de função contém um ou mais blocos básicos (isto é, um corpo de função).
Um exemplo mais detalhado do módulo LLVM IR é dado abaixo. incluindo a definição da variável global @foo e a definição da função @f que contém três blocos base (% de entrada,% de bloco_1 e% de bloco_2).
; , 32- 21 @foo = global i32 21 ; f 42, cond , 0 define i32 @f(i1 %cond) { ; , ; entry: ; br block_1, %cond ; , block_2 . br i1 %cond, label %block_1, label %block_2 ; , , block_1: %tmp = load i32, i32* @foo %result = mul i32 %tmp, 2 ret i32 %result ; , , block_2: ret i32 0 }
Unidade base
Uma unidade base é uma sequência de comandos que não são comandos de transição (comandos de finalização). A idéia principal da unidade base é que, se um comando da unidade base for executado, todos os outros comandos da unidade base serão executados. Isso simplifica a análise do fluxo de execução.
A equipe
Um comando que não é um comando de salto geralmente executa cálculos ou acesso à memória (por exemplo, adicionar, carregar), mas não altera o fluxo de controle do programa.
Equipe de rescisão
O comando de término está localizado no final de cada unidade base e determina onde a transição será feita no final da unidade base. Por exemplo, o comando ret finalizador retorna o fluxo de controle da função de chamada e br executa a transição, condicional ou incondicional.
Formulário SSA
Uma propriedade muito importante do LLVM IR é que ele é escrito no formulário SSA (Static Single Assignment), o que significa essencialmente que cada registro é atribuído apenas uma vez. Esta propriedade simplifica a análise estática do fluxo de dados.
Para processar variáveis atribuídas mais de uma vez no código fonte original, o comando phi é usado no LLVM IR. O comando phi essencialmente retorna um valor único de um conjunto de valores de entrada, dependendo do caminho de execução em que este comando foi alcançado. Cada valor de entrada é, portanto, associado a um bloco de entrada anterior.
Como exemplo, considere a seguinte função LLVM IR:
define i32 @f(i32 %a) { ; <label>:0 switch i32 %a, label %default [ i32 42, label %case1 ] case1: %x.1 = mul i32 %a, 2 br label %ret default: %x.2 = mul i32 %a, 3 br label %ret ret: %x.0 = phi i32 [ %x.2, %default ], [ %x.1, %case1 ] ret i32 %x.0 }
O comando phi (também chamado de nó phi) no exemplo acima simula várias atribuições usando um conjunto de possíveis valores de entrada, um para cada caminho possível no encadeamento de execução, levando à atribuição de variáveis. Por exemplo, um dos caminhos correspondentes no fluxo de dados é o seguinte:
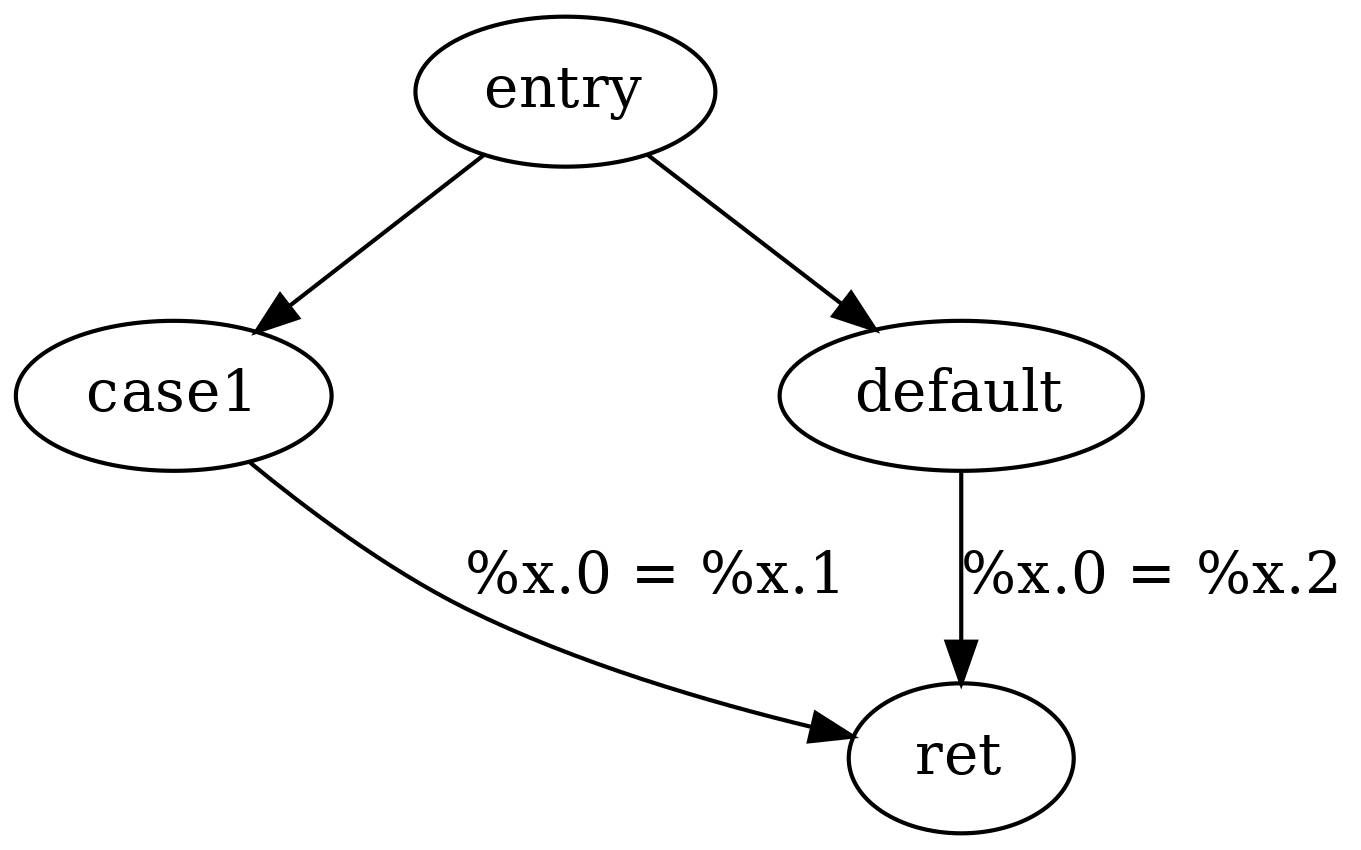
Em geral, ao desenvolver um compilador que converte o código-fonte em LLVM IR, todas as variáveis de código-fonte local podem ser convertidas para o formato SSA, com exceção das variáveis para as quais seu endereço é utilizado.
Para simplificar a implementação do front-end do LLVM, recomenda-se modelar variáveis locais no idioma de origem como variáveis alocadas na memória (usando alloca), simulando atribuições a variáveis locais como gravações na memória e usando uma variável local como leituras da memória. O motivo é que pode ser uma tarefa não trivial traduzir diretamente o idioma de origem para o LLVM IR no formato SSA. Desde que o acesso à memória siga certos padrões, podemos confiar no passo de otimização do mem2reg como parte do LLVM para converter variáveis locais alocadas na memória em registradores no formato SSA (usando nós phi, quando necessário).
Biblioteca LLVM IR no Go puro
Existem duas bibliotecas principais para trabalhar com o LLVM IR no Go:
https://godoc.org/llvm.org/llvm/bindings/go/llvm : ligações oficiais do LLVM para o idioma Go.
github.com/llir/llvm : uma biblioteca Go limpa para interagir com o LLVM IR.
As ligações oficiais do LLVM para a linguagem Go usam o Cgo para fornecer acesso às APIs ricas e poderosas da estrutura do compilador LLVM, enquanto o projeto llir / llvm é inteiramente escrito em Go e usa o LLVM IR para interagir com a estrutura LLVM.
Este artigo se concentra no llir / llvm, mas pode ser generalizado para trabalhar com outras bibliotecas.
Por que escrever uma nova biblioteca?
A principal motivação para o desenvolvimento de uma biblioteca Go limpa para interagir com o LLVM IR foi tornar os compiladores de escrita e as ferramentas de análise estática, baseados na estrutura de compilação do LLVM IR, uma tarefa mais divertida. Também foi influenciado pelo fato de que o tempo de compilação de um projeto baseado em ligações oficiais do LLVM com o Go pode ser significativo (graças a @aykevl, o autor do TinyGo, agora é possível acelerar a compilação devido à vinculação dinâmica, em oposição à versão padrão do LLVM 4).
Outra grande motivação foi tentar desenvolver a API Go a partir do zero. A principal diferença entre as APIs de ligação do LLVM para Go e llir / llvm é como os valores do LLVM são modelados. Nos ligantes LLVM para Go, os valores LLVM são modelados como um tipo estrutural concreto, que, em essência, contém todos os métodos possíveis para todos os valores LLVM possíveis. Minha experiência pessoal usando essa API sugere que é difícil saber qual subconjunto de métodos pode chamar um determinado valor. Por exemplo, para obter um opcode de instrução, chame o método InstructionOpcode, que é intuitivo. No entanto, se você chamar o método Opcode, que é projetado para obter o código de operação de uma expressão constante, você receberá um erro de tempo de execução: “argumento cast () de tipo incompatível!” (conversão de argumento para tipo incompatível).
A biblioteca llir / llvm foi projetada para verificar os tipos em tempo de compilação e garantir que eles sejam usados corretamente com o sistema de tipos Go. Os valores LLVM em llir / llvm são modelados como tipos de interface. Essa abordagem disponibiliza apenas um conjunto mínimo de métodos, compartilhado por todos os valores e, se você deseja acessar métodos ou campos específicos, use a alternância de tipos (conforme mostrado no exemplo abaixo).
Exemplo de uso
Agora, vamos ver alguns exemplos de usos específicos. vamos ter uma biblioteca, mas o que devemos fazer com o RLVM RI?
Primeiro, podemos analisar o IR LLVM gerado por outra ferramenta, como Clang e o otimizador LLVM opt (consulte a amostra de entrada abaixo).
Em segundo lugar, podemos querer processar o IR LLVM e executar nossa própria análise, fazer nossas próprias otimizações, implementar um intérprete ou um compilador JIT (veja o exemplo de análise abaixo).
Em terceiro lugar, podemos querer gerar um IR LLVM, que será uma entrada para outros instrumentos. Essa abordagem pode ser escolhida se estivermos desenvolvendo um frontend para uma nova linguagem de programação (veja o código de saída de exemplo abaixo).
Código de entrada de amostra - análise LLVM IR
Exemplo de análise - Processando LLVM IR
Código de Saída de Amostra - Geração LLVM IR
Conclusão
O desenvolvimento e a implementação do llir / llvm foram realizados e liderados por uma comunidade de colaboradores que não apenas escreveram código, mas também lideraram discussões, sessões de programação emparelhadas, depuraram, criaram perfis e mostraram curiosidade no processo de aprendizagem.
Uma das partes mais difíceis do projeto llir / llvm foi a construção de uma gramática EBNF para LLVM IR, cobrindo toda a linguagem IR LLVM até a versão LLVM 7.0. A dificuldade aqui não está no processo em si, mas no fato de que não há gramática publicada oficialmente cobrindo todo o idioma. Algumas comunidades de código aberto tentaram definir uma gramática formal para o assembler do LLVM, mas elas abrangem, até onde sabemos, apenas subconjuntos do idioma.
A gramática LLVM IR abre caminho para projetos interessantes. Por exemplo, a geração de assembler LLVM IR sintaticamente válido pode ser usada para várias ferramentas e bibliotecas usando o LLVM IR, uma abordagem semelhante é usada no GoSmith. Isso pode ser usado para validação cruzada de projetos LLVM implementados em outros idiomas, bem como para verificar vulnerabilidades e bugs de implementação.
O futuro é maravilhoso, hackers felizes!
Referências
1. Um
capítulo muito bem escrito sobre LLVM, escrito por Chris Lattner, autor do projeto inicial do LLVM, no livro "Arquitetura de aplicativos de código aberto".
2.
O tutorial Implementar uma linguagem com LLVM - geralmente também chamado de Guia de Linguagem Kaleidoscope - descreve em detalhes como implementar uma linguagem de programação simples compilada no LLVM IR. O artigo descreve todos os principais estágios da criação de um front-end, incluindo um analisador lexical, um analisador e geração de código.
3. Para quem estiver interessado em escrever um compilador da linguagem de entrada no LLVM IR, é recomendado o livro "
Mapeando Construções de Alto Nível para o LLVM IR ".
Um bom conjunto de slides é o
LLVM, em Grande Detalhe , que descreve os conceitos importantes do LLVM IR, fornece uma introdução à API do LLVM C ++ e descreve algumas passagens de otimização do LLVM muito úteis.
As ligações oficiais do Go para LLVM são adequadas para muitos projetos, elas representam a API C do LLVM, poderosa e estável.
Uma boa adição ao post é
uma introdução ao LLVM no Go.