O desejo de se afastar dos testes de regressão manual é uma boa razão para introduzir autotestes. A questão é quais? Os desenvolvedores de interface Natalya Stus e Aleksey Androsov lembraram como sua equipe passou por várias iterações e construiu testes de front-end no Auto.ru com base em Jest e Puppeteer: testes de unidade, testes de componentes individuais do React, testes de integração. O mais interessante dessa experiência é o teste isolado dos componentes React em um navegador sem o Selenium Grid, Java e outras coisas.

Alexey:
- Primeiro você precisa contar um pouco o que é Automotive News. Este é um site de venda de carros. Há uma pesquisa, conta pessoal, serviços de automóveis, peças de reposição, revisões, concessionárias e muito mais. O Auto.ru é um projeto muito grande, muito código. Escrevemos todo o código em um grande monorepe, porque está tudo misturado. As mesmas pessoas realizam tarefas semelhantes, por exemplo, para dispositivos móveis e computadores. Acontece muito código, e a monorepa é vital para nós. A questão é como testá-lo?

Temos o React e o Node.js, que executam a renderização do lado do servidor e solicitam dados do back-end. Peças remanescentes e pequenas no BEM.

Natalya:
- Começamos a pensar em automação. O ciclo de lançamento de nossos aplicativos individuais incluiu várias etapas. Primeiro, o recurso é desenvolvido pelo programador em um ramo separado. Depois disso, no mesmo ramo separado, o recurso é testado por testadores manuais. Se tudo estiver bem, a tarefa cai no candidato à liberação. Caso contrário, retorne à iteração de desenvolvimento novamente, teste novamente. Até que o testador diga que está tudo bem nesse recurso, ele não cairá no candidato a lançamento.
Depois de montar o candidato a lançamento, há uma regressão manual - não apenas o Auto.ru, mas apenas o pacote que lançaremos. Por exemplo, se vamos rolar a Web da área de trabalho, há uma regressão manual da Web da área de trabalho. Esses são muitos casos de teste manuais. Essa regressão levou cerca de um dia útil de um testador manual.
Quando a regressão é concluída, ocorre uma liberação. Depois disso, o ramo de liberação é mesclado no mestre. Nesse ponto, podemos apenas injetar o código mestre, que testamos apenas para a Web para desktop, e esse código pode quebrar a Web para dispositivos móveis, por exemplo. Isso não é verificado imediatamente, mas apenas na próxima regressão manual - a Web para dispositivos móveis.

Naturalmente, o lugar mais doloroso nesse processo foi a regressão manual, que levou muito tempo. Todos os testadores manuais, naturalmente, estão cansados de fazer a mesma coisa todos os dias. Portanto, decidimos automatizar tudo. A primeira solução que foi executada foi os autotestes Selenium e Java, escritos por uma equipe separada. Estes foram os testes de ponta a ponta, e2e, que testaram todo o aplicativo. Eles escreveram cerca de 5 mil desses testes. Com o que acabamos?
Naturalmente, aceleramos a regressão. Os testes automáticos passam muito mais rápido do que um testador manual, cerca de 10 vezes mais rápido do que o esperado. Consequentemente, as ações de rotina que eles executavam todos os dias foram removidas dos testadores manuais. Os erros encontrados nos autotestes são mais fáceis de reproduzir. Apenas reinicie este teste ou observe as etapas que ele executa - ao contrário do testador manual, que dirá: "Cliquei em algo e tudo quebrou".
Forneceu estabilidade do revestimento. Sempre executamos os mesmos testes de execução - em contraste, novamente, a partir de testes manuais, quando o testador pode considerar que não tocamos nesse lugar e não vou verificá-lo desta vez. Adicionamos testes para comparar capturas de tela, melhoramos a precisão dos testes na interface do usuário - agora verificamos a discrepância em alguns pixels que o testador não vê com os olhos. Tudo graças a testes de captura de tela.
Mas havia contras. O maior deles - para testes do e2e, precisamos de um ambiente de teste totalmente consistente com o produto. Ele deve sempre ser atualizado e operacional. Isso requer quase tanta força quanto vender suporte de estabilidade. Naturalmente, nem sempre podemos pagar. Portanto, geralmente tivemos situações em que o ambiente de teste está em algum lugar ou algo está quebrado e os testes falham, embora não haja problemas no pacote mais avançado.
Esses testes também estão sendo desenvolvidos por uma equipe separada, que tem suas próprias tarefas, sua própria vez no rastreador de tarefas e novos recursos são cobertos com algum atraso. Eles não podem vir imediatamente após o lançamento de um novo recurso e escrever imediatamente autotestes nele. Como os testes são caros e difíceis de escrever e manter, não cobrimos todos os cenários com eles, mas apenas os mais críticos. Ao mesmo tempo, é necessária uma equipe separada e ela terá ferramentas separadas, uma infraestrutura separada e toda sua. E a análise dos testes reprovados também é uma tarefa não trivial para testadores manuais ou para desenvolvedores. Vou mostrar alguns exemplos.
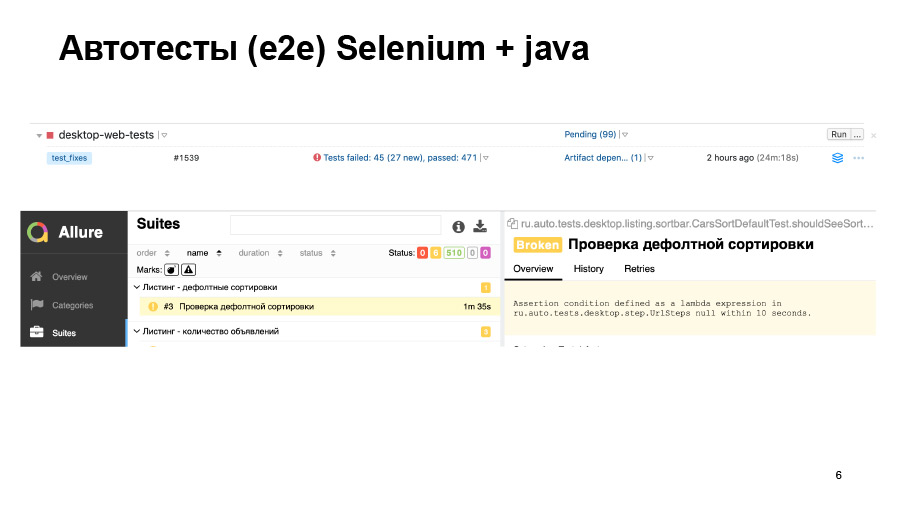
Nós executamos testes. 500 testes passaram, dos quais alguns caíram. Podemos ver isso no relatório. Aqui o teste simplesmente não começou, e não está claro se tudo está bom lá ou não.
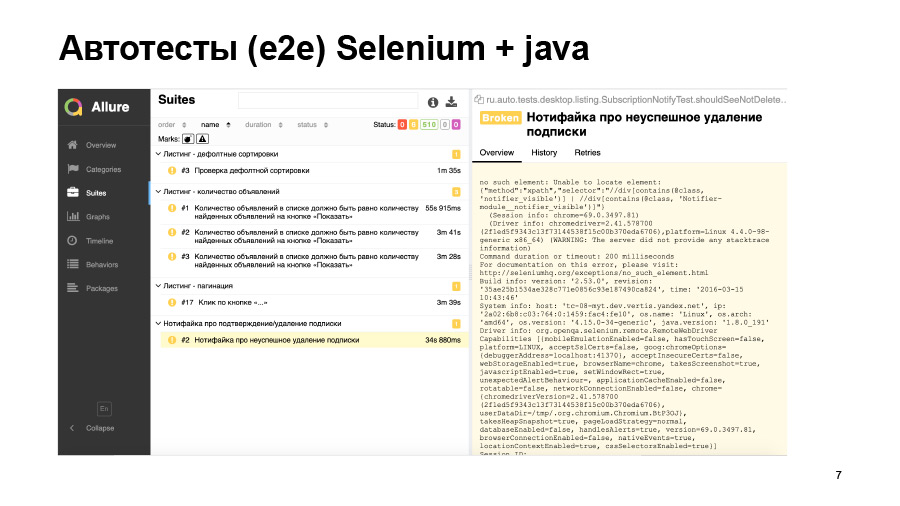
Outro exemplo - o teste começou, mas caiu com esse erro. Ele não conseguiu encontrar nenhum elemento na página, mas por que - não sabemos. Esse elemento simplesmente não apareceu, ou acabou na página errada ou o localizador foi alterado. Tudo o que você precisa para ir e debilitar as mãos.
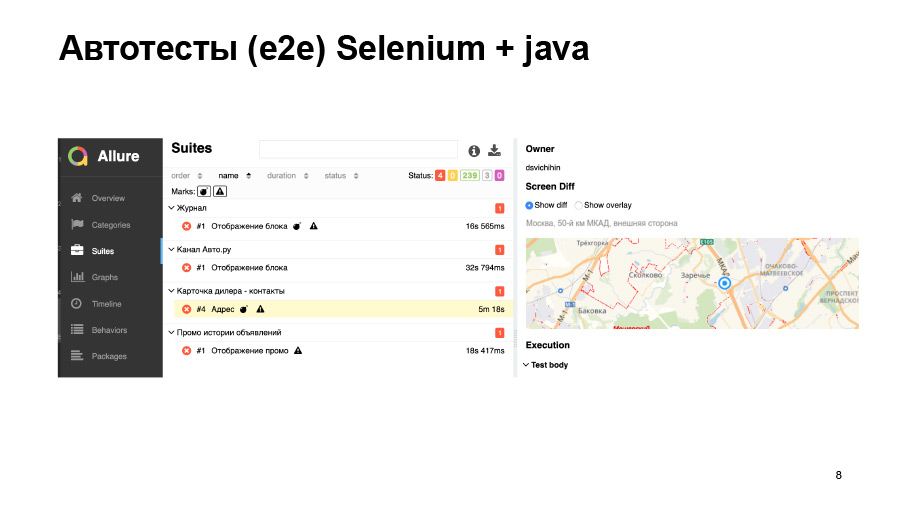
Os testes de captura de tela também nem sempre oferecem uma boa precisão. Aqui carregamos algum tipo de cartão, ele se moveu levemente, nosso teste caiu.

Tentamos resolver vários desses problemas. Começamos a executar parte dos testes no produto - aqueles que não afetam os dados do usuário não alteram nada no banco de dados. Ou seja, na prod fabricamos uma máquina separada que examina o ambiente da prod. Apenas instalamos um novo pacote de front-end e executamos testes lá. O produto é pelo menos estável.
Transferimos alguns dos testes para os mokeys, mas temos vários back-ends, APIs diferentes, e bloquear tudo isso é uma tarefa muito difícil, especialmente para 5 mil testes. Para isso, foi criado um serviço especial chamado mockritsa, que ajuda a fazer os mokas necessários para o frontend com bastante facilidade e é bastante fácil procurá-los.
Também tivemos que comprar um monte de ferro para que nossa grade de dispositivos Selenium, a partir da qual esses testes são lançados, fosse maior para que não caíssem, porque não podiam elevar o navegador e, consequentemente, iriam mais rápido. Mesmo depois de tentarmos resolver esses problemas, ainda chegamos à conclusão de que esses testes não são adequados para o IC, eles demoram muito tempo. Não podemos executá-los em todas as solicitações de pool. Simplesmente, nunca em nossa vida analisaremos posteriormente esses relatórios, que serão gerados para cada solicitação de pool.

Portanto, para o IC, precisamos de testes rápidos e estáveis que não falhem por alguns motivos aleatórios. Queremos executar testes para solicitação de pool sem qualquer teste, back-end, banco de dados, sem nenhum caso de usuário complicado.
Queremos que esses testes sejam gravados simultaneamente com o código e que os resultados dos testes deixem imediatamente claro em qual arquivo algo deu errado.
Alexey:
- Sim, e decidimos tentar tudo o que queremos, arrumar tudo do começo ao fim na mesma infraestrutura Jest. Por que escolhemos Jest? Já escrevemos testes de unidade no Jest, gostamos. Esta é uma ferramenta popular e suportada, que já possui várias integrações prontas: React render render test, Enzyme. Tudo funciona imediatamente, nada precisa ser construído, tudo é simples.

E Jest ganhou pessoalmente por mim, ao contrário de qualquer moka, é difícil filmar o efeito colateral de algum tipo de teste de terceiros em sua perna se eu me esqueci de limpá-lo ou de qualquer outra coisa. No moka, isso é feito uma ou duas vezes, mas no Jest é difícil fazê-lo: é constantemente lançado em threads separados. É possível, mas difícil. E para o e2e lançado Puppeteer, também decidimos experimentá-lo. Foi o que conseguimos.

Natalya:
"Eu também vou começar com um exemplo de testes de unidade." Quando escrevemos testes simplesmente para alguma função, não há problemas especiais. Chamamos essa função, passamos alguns argumentos, comparamos o que aconteceu com o que deveria ter acontecido.
Se estamos falando sobre componentes React, tudo se torna um pouco mais complicado. Precisamos de alguma forma renderizá-los. Existe um renderizador de teste React, mas não é muito conveniente para testes de unidade, porque não nos permitirá testar componentes isoladamente. Ele renderizará o componente completamente até o final, para o layout.
E quero mostrar como com o Enzyme é possível escrever testes de unidade para componentes React usando um exemplo de um componente em que temos um determinado MyComponent. Ele recebe algum tipo de suporte, ele tem algum tipo de lógica. Então ele retorna o componente Foo, que, por sua vez, retornará o componente bar, que já no componente bar retorna para nós, de fato, o layout.

Podemos usar uma ferramenta de enzima como renderização superficial. É exatamente isso que precisamos para testar o componente MyComponent isoladamente. E esses testes não dependerão do que os componentes foo e bar conterão dentro de si. Apenas testaremos a lógica do componente MyComponent.
Jest tem algo como Instantâneo, e eles também podem nos ajudar aqui. “Esperar algo para o MatchSnapshot” criará essa estrutura para nós, apenas um arquivo de texto que armazena, de fato, o que esperávamos, o que acontece e, quando esses testes são executados pela primeira vez, esse arquivo é gravado. Com outras execuções dos testes, o que for obtido será comparado com o padrão contido no arquivo MyComponent.test.js.snap.
Aqui vemos apenas que toda a renderização retorna exatamente o que o método render do MyComponent retorna e o que é foo, em geral, não se importa. Podemos escrever esses dois testes para nossos dois casos, para nossos dois casos para o componente MyComponent.

Em princípio, podemos testar a mesma coisa sem um instantâneo, apenas verificando os scripts necessários, por exemplo, verificando qual prop é passada para o componente foo. Mas essa abordagem tem um sinal de menos. Se adicionarmos outro elemento ao MyComponent, nosso novo teste, isso não será exibido de forma alguma.

Portanto, afinal, os testes de instantâneo são aqueles que nos mostrarão quase todas as alterações dentro do componente. Mas se escrevermos os dois testes no Snapshot e fizermos as mesmas alterações no componente, veremos que os dois testes cairão. Em princípio, os resultados desses testes falados nos dirão a mesma coisa: adicionamos algum tipo de "alô" lá.

E isso também é redundante, portanto, acredito que é melhor usar um teste de instantâneo para a mesma estrutura. Verifique o restante da lógica de alguma maneira diferente, sem o Snapshot, porque o Snapshot não é muito indicativo. Quando você vê o Instantâneo, vê que algo foi renderizado, mas não está claro qual lógica você testou aqui. Isso é completamente inadequado para o TDD, se você quiser usá-lo. E não funcionará como documentação. Ou seja, quando você examinar esse componente, verá que sim, o Instantâneo corresponde a alguma coisa, mas que tipo de lógica existia não é muito claro.


Da mesma forma, escreveremos testes de unidade no componente foo, no componente bar, por exemplo, Snapshot.

Temos 100% de cobertura para esses três componentes. Acreditamos que verificamos tudo, estamos bem.
Mas digamos que mudamos algo no componente da barra, adicionamos um novo suporte a ele e fizemos um teste para o componente da barra, obviamente. Corrigimos o teste e todos os três testes foram aprovados conosco.

Mas, de fato, se coletarmos toda essa história, nada funcionará, porque o MyComponent não se unirá a esse erro. Na verdade, não passamos o suporte que ele espera para o componente bar. Portanto, estamos falando do fato de que, neste caso, também precisamos de testes de integração que verifiquem, incluindo se chamamos corretamente seu componente filho do nosso componente.

Tendo esses componentes e alterando um deles, você vê imediatamente quais alterações nesse componente afetaram.
Que oportunidades temos na Enzyme para realizar testes de integração? A renderização rasa em si retorna essa estrutura. Possui um método de mergulho, se for chamado em algum componente React, falhará nele. Conseqüentemente, chamando-o de componente foo, obtemos o que o componente foo renderiza, isso é bar; se fizermos o mergulho novamente, obteremos, de fato, o layout que o componente bar retorna para nós. Este será apenas um teste de integração.

Ou você pode renderizar tudo de uma vez usando o método mount, que implementa a renderização completa do DOM. Mas eu não aconselho fazer isso, porque será um instantâneo muito difícil. E, como regra, você não precisa verificar toda a estrutura. Você só precisa verificar a integração entre o componente pai e o filho em cada caso.

E para o MyComponent, adicionamos um teste de integração; portanto, no primeiro teste, adiciono apenas mergulho, e verifica-se que testamos não apenas a lógica do próprio componente, mas também sua integração com o componente foo. Da mesma forma, adicionamos o teste de integração para o componente foo que ele chama corretamente de componente bar e, em seguida, verificamos toda essa cadeia e temos certeza de que nenhuma alteração nos interromperá, de fato, a renderização do MyComponent

Outro exemplo, já de um projeto real. Apenas brevemente sobre o que mais Jest e Enzyme podem fazer. Jest pode fazer moki. Você pode, se você usar alguma função externa em seu componente, poderá bloqueá-lo. Por exemplo, neste exemplo, chamamos algum tipo de API, naturalmente não queremos entrar em nenhuma API no teste de unidade; portanto, apenas limpamos a função getResource com algum objeto jest.fn. De fato, a função simulada. Depois, podemos verificar se foi chamado ou não, quantas vezes foi chamado, com quais argumentos. Tudo isso permite que você faça Jest.

Na renderização superficial, você pode passar o armazenamento para um componente. Se você precisar de uma loja, basta transferi-la para lá e ela funcionará.

Você também pode alterar State e prop em um componente já renderizado.

Você pode chamar o método simular em algum componente. Apenas chama o manipulador. Por exemplo, se você simular o clique, ele chamará o Clique aqui para o componente do botão. Tudo isso pode ser lido, é claro, na documentação da enzima, muitas peças úteis. Estes são apenas alguns exemplos de um projeto real.

Alexey:
- Chegamos à pergunta mais interessante. Podemos testar o Jest, podemos escrever testes de unidade, verificar componentes, verificar quais elementos respondem incorretamente a um clique. Podemos verificar o html deles. Agora precisamos verificar o layout do componente, css.

E é aconselhável fazer isso para que o princípio do teste não seja diferente do que eu descrevi anteriormente. Se eu verificar o html, chamei a renderização superficial, ela pegou e processou o html para mim. Quero verificar css, basta chamar algum tipo de renderização e apenas verificar - sem levantar nada, sem configurar nenhuma ferramenta.

Comecei a procurá-lo e, em quase todos os lugares, a mesma resposta foi dada a essa coisa toda chamada Puppeteer, ou grade Selenium. Você abre uma aba, acessa alguma página html, tira uma captura de tela e a compara com a opção anterior. Se não mudou, está tudo bem.
A questão é: o que é html de página se eu apenas quiser verificar um componente isoladamente? É desejável - em diferentes condições.

Não quero escrever um monte desses html de página para cada componente, para cada estado. Avito tem uma boa corrida. Roma Dvornov publicou um artigo sobre Habré, e ele, aliás, fez um discurso. O que eles fizeram? Eles pegam componentes, montam html através de uma renderização padrão. Então, com a ajuda de plugins e todo tipo de truque, eles coletam todos os ativos que possuem - fotos, css. Insira tudo no html e eles obterão o html certo.

E então eles criaram um servidor especial, enviam html para lá, renderizam e retornam algum resultado. Um artigo muito interessante, leia, no entanto, você pode desenhar muitas idéias interessantes a partir daí.

O que eu não gosto lá. A montagem de um componente é diferente de como vai para a produção. Por exemplo, temos o webpack, e lá ele será coletado por alguns ativos da babel, e será retirado de uma maneira diferente. Não posso garantir que testei o que vou baixar agora.
E, novamente, um serviço separado para capturas de tela. Eu quero fazer isso de alguma forma mais fácil. E havia, de fato, a ideia de que, vamos colecioná-lo exatamente da mesma maneira que iremos colecioná-lo. E tente usar algo como o Docker, porque é uma coisa dessas, pode ser colocado em um computador, localmente, será simples, isolado, não toca em nada, está tudo bem.

Mas esse problema é com o html da página, ele permanece o mesmo que realmente é. E uma ideia nasceu. Você tem um webpack.conf tão simplificado e, a partir dele, existe algum EntryPoint para o cliente js. Os módulos são descritos, como montá-los, o arquivo de saída, todos os plugins que você descreveu, tudo está configurado, tudo está bem.

E se eu fizer assim? Ele entrará no meu componente e o coletará isoladamente. E haverá exatamente um componente. Se eu adicionar o webpack html lá, ele também fornecerá html, e esses recursos serão coletados lá, e isso, no entanto, já poderá ser testado automaticamente.
E eu estava prestes a escrever tudo isso, mas descobri.

Jest-puppeteer-React, um jovem plugin. E comecei a contribuir ativamente para isso. Se você quiser experimentar de repente, pode, por exemplo, me procurar, de alguma forma posso ajudar. O projeto, de fato, não é meu.
Você escreve um arquivo regular como test.js e esses arquivos precisam ser escritos um pouco separadamente para ajudar a encontrá-los, para não compilar todo o projeto, mas compilar apenas os componentes necessários. De fato, você aceita a configuração do webpack. E os pontos de entrada mudam para esses arquivos browser.js, ou seja, exatamente o que queremos testar será empacotado em html, e com a ajuda do Puppeteer, serão exibidas capturas de tela.

O que ele pode fazer? , jest-image-snapshot. . , , js, media-query, , .
headless-, , , , , headless-, Chrome . web-, , , , .
Docker. . . , Docker, . . Docker , , , Linux, - , - . Docker , .

? , . , . before-after, , . , . , Chrome, Firefox. .
. pixelmatch. , looksame, «», . , .

— . , , . , : - , — Enzyme. Redux store . . viewport, , . , , .

. , . ? , .

: 5-10 . Selenium . , , , . .

Puppeteer, e2e-. , e2e- — , Selenium.
:
— , Selenium Java , . - JS Puppeteer, , .
, . , , .

— Selenium Java, — JS Puppeteer. . 18 . , , Java. , , Java Selenium.

:
— ? . , html-, css . e2e. . , .

, , . . , , — , . , . - , , : , .
, , . git hook, -, . green master — , , , . Obrigada