Há algum tempo, em uma discussão sobre um dos lançamentos do SObjectizer, perguntaram-nos: "É possível criar uma DSL para descrever um pipeline de processamento de dados?" Em outras palavras, é possível escrever algo assim:
A | B | C | D
e obtenha um pipeline de trabalho no qual as mensagens vão de A para B, depois para C e depois para D. Com o controle, B recebe exatamente o tipo que A retorna. E C recebe exatamente o tipo que B retorna. E assim por diante
Foi uma tarefa interessante, com uma solução surpreendentemente simples. Por exemplo, é assim que a criação de um pipeline pode parecer:
auto pipeline = make_pipeline(env, stage(A) | stage(B) | stage(C) | stage(D));
Ou, em um caso mais complexo (que será discutido abaixo):
auto pipeline = make_pipeline( sobj.environment(), stage(validation) | stage(conversion) | broadcast( stage(archiving), stage(distribution), stage(range_checking) | stage(alarm_detector{}) | broadcast( stage(alarm_initiator), stage( []( const alarm_detected & v ) { alarm_distribution( cerr, v ); } ) ) ) );
Neste artigo, falaremos sobre a implementação desse DSL de pipeline. Discutiremos principalmente partes relacionadas às funções stage() , broadcast() e operator|() com vários exemplos de uso de modelos C ++. Espero que seja interessante, mesmo para os leitores que não conhecem o SObjectizer (se você nunca ouviu falar do SObjectizer, aqui está uma visão geral dessa ferramenta).
Algumas palavras sobre a demonstração usada
O exemplo usado no artigo foi influenciado pela minha experiência antiga (e um tanto esquecida) na área do SCADA.
A idéia da demonstração é o tratamento dos dados lidos por algum sensor. Os dados são adquiridos de um sensor por um período e, em seguida, esses dados precisam ser validados (dados incorretos devem ser ignorados) e convertidos em alguns valores reais. Por exemplo, os dados brutos lidos de um sensor podem ser dois valores inteiros de 8 bits e esses valores devem ser convertidos em um número de ponto flutuante.
Em seguida, os valores válidos e convertidos devem ser arquivados, distribuídos em algum lugar (em diferentes nós para visualização, por exemplo), verificados quanto a "alarmes" (se os valores estiverem fora dos intervalos seguros, isso deverá ser tratado especialmente). Essas operações são independentes e podem ser executadas em paralelo.
As operações relacionadas ao alarme detectado também podem ser executadas em paralelo: um "alarme" deve ser iniciado (para que a parte do SCADA no nó atual possa reagir) e as informações sobre o "alarme" devem ser distribuídas em outro local (por exemplo, : armazenado em um banco de dados histórico e / ou visualizado no visor do operador SCADA).
Essa lógica pode ser expressa em forma de texto dessa maneira:
optional(valid_raw_data) = validate(raw_data); if valid_raw_data is not empty then { converted_value = convert(valid_raw_data); do_async archive(converted_value); do_async distribute(converted_value); do_async { optional(suspicious_value) = check_range(converted_value); if suspicious_value is not empty then { optional(alarm) = detect_alarm(suspicious_value); if alarm is not empty then { do_async initiate_alarm(alarm); do_async distribute_alarm(alam); } } } }
Ou, em forma gráfica:

É um exemplo bastante artificial, mas tem algumas coisas interessantes que quero mostrar. A primeira é a presença de estágios paralelos em um pipeline (a operação broadcast() existe apenas por causa disso). O segundo é a presença de um estado em algumas etapas. Por exemplo, alarm_detector é um estágio stateful.
Recursos de pipeline
Um pipeline é construído a partir de estágios separados. Cada estágio é uma função ou um functor do seguinte formato:
opt<Out> func(const In &);
ou
void func(const In &);
Os estágios que retornam void só podem ser usados como o último estágio de um pipeline.
As etapas são vinculadas a uma cadeia. Cada próximo estágio recebe um objeto retornado pelo estágio anterior. Se o estágio anterior retornar o valor vazio opt<Out> , o próximo estágio não será chamado.
Há um estágio de broadcast especial. É construído a partir de vários oleodutos. Um estágio de broadcast recebe um objeto do estágio anterior e o transmite a todos os pipeline subsidiários.
Do ponto de vista do pipeline, o estágio de broadcast parece uma função do seguinte formato:
void func(const In &);
Como não há valor de retorno do estágio de broadcast , um estágio de broadcast pode ser apenas o último estágio de um pipeline.
Por que o estágio do pipeline retorna um valor opcional?
É porque é necessário eliminar alguns valores recebidos. Por exemplo, o estágio validate não retorna nada se um valor bruto estiver incorreto e não faz sentido lidar com isso.
Outro exemplo: o estágio alarm_detector não retorna nada se o valor suspeito atual não produzir um novo caso de alarme.
Detalhes da implementação
Vamos começar com tipos de dados e funções relacionadas à lógica do aplicativo. No exemplo discutido, os seguintes tipos de dados são usados para passar informações de um estágio para outro:
Uma instância de raw_value está indo para o primeiro estágio do nosso pipeline. Este raw_value contém informações adquiridas de um sensor na forma de objeto raw_measure . Em seguida, raw_value é transformado em valid_raw_value . Em seguida, valid_raw_value transformado em sensor_value com o valor real do sensor na forma de calulated_measure . Se uma instância de sensor_value contiver um valor suspeito, será sensor_value uma instância de sensor_value . E esse suspicious_value pode ser transformado em instância alarm_detected por alarm_detected posteriormente.
Ou, na forma gráfica:

Agora podemos dar uma olhada na implementação de nossos estágios de pipeline:
Apenas pule coisas como stage_result_t , make_result e make_empty , discutiremos sobre isso na próxima seção.
Espero que o código dessas etapas seja trivial. A única parte que requer alguma explicação adicional é a implementação do estágio alarm_detector .
Nesse exemplo, um alarme é iniciado apenas se houver pelo menos dois valores suspicious_values em uma janela de tempo de 25 ms. Portanto, temos que lembrar a hora da instância anterior suspicious_value no estágio alarm_detector . Isso ocorre porque o alarm_detector é implementado como um functor stateful com um operador de chamada de função.
Os estágios retornam o tipo de SObjectizer em vez de std :: optional
Eu disse anteriormente que o estágio poderia retornar um valor opcional. Mas std::optional não é usado no código, o tipo diferente stage_result_t pode ser visto na implementação de estágios.
Isso ocorre porque alguns dos itens específicos do SObjectizer desempenham seu papel aqui. Os valores retornados serão distribuídos como mensagens entre os agentes do SObjectizer (também conhecidos como atores). Toda mensagem no SObjectizer é enviada como um objeto alocado dinamicamente. Portanto, temos algum tipo de "otimização" aqui: em vez de retornar std::optional e alocar um novo objeto de mensagem, apenas alocamos um objeto de mensagem e retornamos um ponteiro inteligente para ele.
De fato, stage_result_t é apenas um typedef para o analógico shared_ptr do SObjectizer:
template< typename M > using stage_result_t = message_holder_t< M >;
E make_result e make_empty são apenas funções auxiliares para construir stage_result_t com ou sem um valor real dentro:
template< typename M, typename... Args > stage_result_t< M > make_result( Args &&... args ) { return stage_result_t< M >::make(forward< Args >(args)...); } template< typename M > stage_result_t< M > make_empty() { return stage_result_t< M >(); }
Para simplificar, é seguro dizer que o estágio de validation pode ser expresso dessa maneira:
std::shared_ptr< valid_raw_value > validation( const raw_value & v ) { if( 0x7 >= v.m_data.m_high_bits ) return std::make_shared< valid_raw_value >( v.m_data ); else return std::shared_ptr< valid_raw_value >{}; }
Porém, devido à especificidade do SObjectizer, não podemos usar std::shared_ptr e precisamos lidar com o tipo so_5::message_holder_t . E stage_result_t esse específico por trás dos stage_result_t , make_result e make_empty .
separação stage_handler_t e stage_builder_t
Um ponto importante da implementação do pipeline é a separação dos conceitos de manipulador de estágio e construtor de estágio . Isso é feito para simplificar. A presença desses conceitos me permitiu ter duas etapas na definição do pipeline.
Na primeira etapa, um usuário descreve os estágios do pipeline. Como resultado, recebo uma instância de stage_t que contém todos os estágios do pipeline dentro.
Na segunda etapa, um conjunto de agentes subjacentes do SObjectizer é criado. Esses agentes recebem mensagens com resultados dos estágios anteriores e chamam os manipuladores de estágios reais e os enviam para os próximos estágios.
Mas, para criar esse conjunto de agentes, todos os estágios precisam ter um construtor de estágios . O construtor Stage pode ser visto como uma fábrica que cria o agente de um SObjectizer subjacente.
Portanto, temos a seguinte relação: todo estágio de pipeline produz dois objetos: manipulador de palco que contém lógica relacionada ao palco e construtor de palco que cria um agente do SObjectizer subjacente para chamar o manipulador de palco no momento apropriado:

O manipulador de palco é representado da seguinte maneira:
template< typename In, typename Out > class stage_handler_t { public : using traits = handler_traits_t< In, Out >; using func_type = function< typename traits::output(const typename traits::input &) >; stage_handler_t( func_type handler ) : m_handler( move(handler) ) {} template< typename Callable > stage_handler_t( Callable handler ) : m_handler( handler ) {} typename traits::output operator()( const typename traits::input & a ) const { return m_handler( a ); } private : func_type m_handler; };
Onde handler_traits_t são definidos da seguinte maneira:
O construtor Stage é representado por apenas std::function :
using stage_builder_t = function< mbox_t(coop_t &, mbox_t) >;
Tipos auxiliares lambda_traits_t e callable_traits_t
Como os estágios podem ser representados por funções ou functors livres (como instâncias da classe alarm_detector ou classes geradas por compiladores anônimos que representam lambdas), precisamos de alguns auxiliares para detectar tipos de argumento e valor de retorno do estágio. Eu usei o seguinte código para esse fim:
Espero que este código seja bastante compreensível para leitores com bom conhecimento de C ++. Caso contrário, fique à vontade para me perguntar nos comentários. lambda_traits_t feliz em explicar a lógica por trás de lambda_traits_t e callable_traits_t em detalhes.
funções stage (), broadcast () e operator | ()
Agora podemos examinar as principais funções de construção de tubulações. Mas antes disso, é necessário dar uma olhada na definição de uma classe de modelo stage_t :
template< typename In, typename Out > struct stage_t { stage_builder_t m_builder; };
É uma estrutura muito simples que contém apenas a instância stage_bulder_t . Os parâmetros do modelo não são usados dentro do stage_t , então por que eles estão presentes aqui?
Eles são necessários para a verificação em tempo de compilação da compatibilidade de tipos entre os estágios do pipeline. Veremos isso em breve.
Vejamos a função mais simples de construção de pipeline, o stage() :
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( Callable handler ) { stage_builder_t builder{ [h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent< a_stage_point_t<In, Out> >( std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
Ele recebe um manipulador de estágio real como um único parâmetro. Pode ser um ponteiro para uma função ou função lambda ou functor. Os tipos de entrada e saída do estágio são deduzidos automaticamente devido à "mágica do modelo" por trás do modelo callable_traits_t .
Uma instância do construtor de estágio é criada dentro e ela é retornada em um novo objeto stage_t como resultado da função stage() . Um manipulador de palco real é capturado pelo construtor de palco lambda, depois será usado para a construção do agente do SObjectizer subjacente (falaremos sobre isso na próxima seção).
A próxima função a ser operator|() é o operator|() que concatena dois estágios e retorna um novo estágio:
template< typename In, typename Out1, typename Out2 > stage_t< In, Out2 > operator|( stage_t< In, Out1 > && prev, stage_t< Out1, Out2 > && next ) { return { stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } } }; }
A maneira mais simples de explicar a lógica do operator|() é tentar desenhar uma imagem. Vamos supor que temos a expressão:
stage(A) | stage(B) | stage(C) | stage(B)
Esta expressão será transformada dessa maneira:

Também podemos ver como a verificação de tipo em tempo de compilação está funcionando: a definição de operator|() exige que o tipo de saída do primeiro estágio seja a entrada do segundo estágio. Se não for esse o caso, o código não será compilado.
E agora podemos dar uma olhada na função de construção de pipeline mais complexa, a broadcast() . A função em si é bastante simples:
template< typename In, typename Out, typename... Rest > stage_t< In, void > broadcast( stage_t< In, Out > && first, Rest &&... stages ) { stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)] ( coop_t & coop, mbox_t ) -> mbox_t { vector< mbox_t > mboxes; mboxes.reserve( broadcasts.size() ); for( const auto & b : broadcasts ) mboxes.emplace_back( b( coop, mbox_t{} ) ); return broadcast_mbox_t::make( coop.environment(), std::move(mboxes) ); } }; return { std::move(builder) }; }
A principal diferença entre um estágio comum e um estágio de transmissão é que o estágio de transmissão deve conter um vetor de construtores de estágio subsidiários. Portanto, temos que criar esse vetor e passá-lo para o construtor do estágio principal do estágio de transmissão. Por isso, podemos ver uma chamada para collect_sink_builders na lista de capturas de um lambda na função broadcast() :
stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)]
Se olharmos para collect_sink_builder , veremos o seguinte código:
A verificação de tipo em tempo de compilação também funciona aqui: é porque uma chamada para move_sink_builder_to explicitamente parametrizada pelo tipo 'In'. Isso significa que uma chamada no formato collect_sink_builders(stage_t<In1, Out1>, stage_t<In2, Out2>, ...) levará a erro de compilação porque o compilador proíbe uma chamada move_sink_builder_to<In1>(receiver, stage_t<In2, Out2>, ...) .
Também posso observar que, como a contagem de pipelines subsidiários para broadcast() é conhecida em tempo de compilação, podemos usar std::array vez de std::vector e evitar algumas alocações de memória. Mas std::vector é usado aqui apenas por simplicidade.
Relação entre estágios e agentes / mboxes do SObjectizer
A idéia por trás da implementação do pipeline é a criação de um agente separado para cada estágio do pipeline. Um agente recebe uma mensagem recebida, passa para o manipulador de estágio correspondente, analisa o resultado e, se o resultado não estiver vazio, envia o resultado como uma mensagem recebida para o próximo estágio. Pode ser ilustrado pelo seguinte diagrama de sequência:

Algumas coisas relacionadas ao SObjectizer precisam ser discutidas, pelo menos brevemente. Se você não tem interesse em tais detalhes, pode pular as seções abaixo e ir diretamente para a conclusão.
Coop é um grupo de agentes para trabalhar juntos
Os agentes são introduzidos no SObjectizer não individualmente, mas em grupos denominados coops. Uma cooperativa é um grupo de agentes que devem trabalhar juntos e não faz sentido continuar o trabalho se um dos agentes do grupo estiver ausente.
Portanto, a introdução de agentes no SObjectizer parece com a criação da instância de cooperação, preenchendo essa instância com os agentes apropriados e registrando a cooperação no SObjectizer.
Por isso, o primeiro argumento para um construtor de estágios é uma referência a uma nova cooperativa. Essa cooperação é criada na função make_pipeline() (discutida abaixo), depois é preenchida por construtores de estágio e depois registrada (novamente na função make_pipeline() ).
Caixas de mensagem
O SObjectizer implementa vários modelos relacionados à concorrência. O modelo do ator apenas um deles. Por isso, o SObjectizer pode diferir significativamente de outras estruturas de atores. Uma das diferenças é o esquema de endereçamento das mensagens.
As mensagens no SObjectizer não são endereçadas aos atores, mas às caixas de mensagens (mboxes). Os atores precisam se inscrever nas mensagens de uma mbox. Se um ator se inscrevesse em um tipo de mensagem específico de uma mbox, ele receberia mensagens desse tipo:
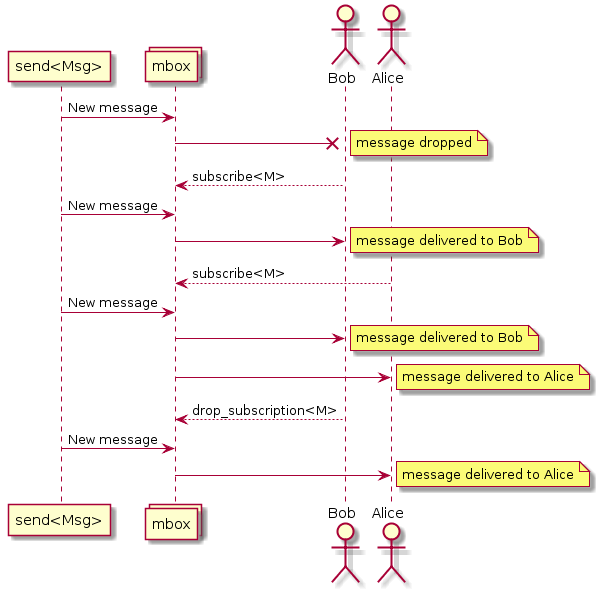
Esse fato é crucial porque é necessário enviar mensagens de um estágio para outro. Isso significa que cada estágio deve ter sua mbox e esse mbox deve ser conhecido para o estágio anterior.
Todo ator (aka agente) no SObjectizer possui a mbox direta . Essa mbox está associada apenas ao agente proprietário e não pode ser usada por outros agentes. As mboxes diretas de agentes criadas para estágios serão usadas para a interação dos estágios.
O recurso específico deste SObjectizer determina alguns detalhes de implementação de pipeline.
O primeiro é o fato de o construtor de palco ter o seguinte protótipo:
mbox_t builder(coop_t &, mbox_t);
Isso significa que o construtor de estágio recebe uma mbox do próximo estágio e deve criar um novo agente que enviará os resultados do estágio para essa mbox. Uma mbox do novo agente deve ser retornada pelo construtor de palco . Essa mbox será usada para a criação de um agente para o estágio anterior.
O segundo é o fato de que agentes para estágios são criados em ordem de reserva. Isso significa que se tivermos um pipeline:
stage(A) | stage(B) | stage(C)
Um agente para o estágio C será criado primeiro, então sua mbox será usada para a criação de um agente para o estágio B e, em seguida, a mbox do agente do estágio B será usada para a criação de um agente para o estágio A.
Também vale ressaltar que o operator|() não cria agentes:
stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } }
O operator|() cria um construtor que chama apenas outros construtores, mas não apresenta agentes adicionais. Então, para o caso:
stage(A) | stage(B)
apenas dois agentes serão criados (para os estágios A e B) e, em seguida, serão vinculados no construtor de estágios criado pelo operator|() .
Não há agente para implementação de broadcast()
Uma maneira óbvia de implementar um estágio de transmissão é criar um agente especial que receberá uma mensagem recebida e, em seguida, reenvie essa mensagem para uma lista de mboxes de destino. Dessa maneira, foi usada na primeira implementação do DSL de pipeline descrito.
Mas nosso projeto complementar, so5extra , agora possui uma variante especial da mbox: a transmissão de uma. Essa mbox faz exatamente o que é necessário aqui: pega uma nova mensagem e a entrega a um conjunto de mboxes de destino.
Por esse motivo, não há necessidade de criar um agente de transmissão separado, podemos apenas usar a transmissão mbox do so5extra:
Implementação do agente de estágio
Agora podemos dar uma olhada na implementação do agente do estágio:
É bastante trivial se você entender o básico do SObjectizer. Caso contrário, será muito difícil explicar em poucas palavras (sinta-se à vontade para fazer perguntas nos comentários).
A principal implementação do agente a_stage_point_t cria uma assinatura para uma mensagem do tipo In. Quando uma mensagem desse tipo chega, o manipulador de palco é chamado. Se o manipulador de estágio retornar um resultado real, o resultado será enviado para o próximo estágio (se esse estágio existir).
Há também uma versão de a_stage_point_t para o caso em que o estágio correspondente é o estágio terminal e não pode haver o próximo estágio.
A implementação de a_stage_point_t pode parecer um pouco complicada, mas acredite, é um dos agentes mais simples que escrevi.
função make_pipeline ()
É hora de discutir a última função de construção de pipeline, o make_pipeline() :
template< typename In, typename Out, typename... Args > mbox_t make_pipeline(
Não há mágica nem surpresas aqui. Nós apenas precisamos criar uma nova cooperativa para agentes subjacentes do pipeline, preencher essa cooperativa com agentes chamando um construtor de estágio de nível superior e depois registrá-la no SObjectizer. Isso tudo.
O resultado de make_pipeline() é a mbox do estágio mais à esquerda (o primeiro) do pipeline. Essa mbox deve ser usada para enviar mensagens para o pipeline.
A simulação e experimentos com ela
Portanto, agora temos tipos de dados e funções para nossa lógica de aplicativo e as ferramentas para encadear essas funções em um pipeline de processamento de dados. Vamos fazer isso e ver um resultado:
int main() {
Se executarmos esse exemplo, veremos a seguinte saída:
archiving (0,0) distributing (0,0) archiving (0,5) distributing (0,5) archiving (0,10) distributing (0,10) archiving (0,15) distributing (0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,30) distributing (0,30) ... archiving (0,105) distributing (0,105) archiving (0,110) distributing (0,110) === alarm (0) === alarm_distribution (0) archiving (0,115) distributing (0,115) archiving (0,120) distributing (0,120) === alarm (0) === alarm_distribution (0)
Isso funciona.
Mas parece que os estágios do nosso pipeline funcionam sequencialmente, um após o outro, não é?
É sim. Isso ocorre porque todos os agentes de pipeline estão vinculados ao expedidor do SObjectizer padrão. E esse expedidor usa apenas um segmento de trabalho para servir o processamento de mensagens de todos os agentes.
Mas isso pode ser facilmente alterado. Basta passar um argumento adicional para a chamada make_pipeline() :
Isso cria um novo conjunto de encadeamentos e liga todos os agentes de pipeline a esse conjunto. Cada agente será atendido pelo pool independentemente de outros agentes.
Se rodarmos o exemplo modificado, podemos ver algo assim:
archiving (0,0) distributing (0,0) distributing (0,5) archiving (0,5) archiving (0,10) distributing (0,10) distributing (archiving (0,15) 0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,distributing (030) ,30) ... archiving (0,distributing (0,105) 105) archiving (0,alarm_distribution (0) distributing (0,=== alarm (0) === 110) 110) archiving (distributing (0,0,115) 115) archiving (distributing (=== alarm (0) === 0alarm_distribution (0) 0,120) ,120)
Portanto, podemos ver que diferentes estágios do pipeline funcionam em paralelo.
Mas é possível ir além e ter a capacidade de vincular estágios a diferentes expedidores?
Sim, é possível, mas temos que implementar outra sobrecarga para a função stage() :
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( disp_binder_shptr_t disp_binder, Callable handler ) { stage_builder_t builder{ [binder = std::move(disp_binder), h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent_with_binder< a_stage_point_t<In, Out> >( std::move(binder), std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
This version of stage() accepts not only a stage handler but also a dispatcher binder. Dispatcher binder is a way to bind an agent to the particular dispatcher. So to assign a stage to a specific working context we can create an appropriate dispatcher and then pass the binder to that dispatcher to stage() function. Let's do that:
In that case stages archiving , distribution , alarm_initiator and alarm_distribution will work on own worker threads. All other stages will work on the same single worker thread.
The conclusion
This was an interesting experiment and I was surprised how easy SObjectizer could be used in something like reactive programming or data-flow programming.
However, I don't think that pipeline DSL can be practically meaningful. It's too simple and, maybe not flexible enough. But, I hope, it can be a base for more interesting experiments for those why need to deal with different workflows and data-processing pipelines. At least as a base for some ideas in that area. C++ language a rather good here and some (not so complicated) template magic can help to catch various errors at compile-time.
In conclusion, I want to say that we see SObjectizer not as a specialized tool for solving a particular problem, but as a basic set of tools to be used in solutions for different problems. And, more importantly, that basic set can be extended for your needs. Just take a look at SObjectizer , try it, and share your feedback. Maybe you missed something in SObjectizer? Perhaps you don't like something? Tell us , and we can try to help you.
If you want to help further development of SObjectizer, please share a reference to it or to this article somewhere you want (Reddit, HackerNews, LinkedIn, Facebook, Twitter, ...). The more attention and the more feedback, the more new features will be incorporated into SObjectizer.
And many thanks for reading this ;)
PS. The source code for that example can be found in that repository .