No banco de dados bibliográfico da Web of Science, o guia
“R: uma linguagem e um ambiente para computação estatística” ignorou recentemente outras fontes mencionadas na seção Referências das publicações indexadas por esse banco de dados. Infelizmente, o acesso a ele é limitado e é difícil fornecer um link (para cada sessão, um link é gerado), mas vários usuários ** podem reproduzir minhas observações. No corte, é descrito como e com que reservas vale a pena entender a manchete das notícias.

A ilustração mostra uma lista das fontes mais citadas nas publicações indexadas pelo WoS, que não são indexadas pelo WoS na coleção principal (Core Collection), mas estão apenas no banco de dados de referências bibliográficas.
Além do fato de que três publicações indexadas (todas em biologia) ainda estão à frente do manual R, e em muitos outros aspectos, esse é um registro bastante limitado, com várias suposições. Em primeiro lugar, trata-se apenas de WoS, no banco de dados Scopus, que é freqüentemente mencionado junto com WoS, a nomenclatura "Manual Diagnóstico e Estatístico de Transtornos Mentais" ainda está (mas, a julgar pela taxa de crescimento, não por muito tempo) à frente do manual R. Em segundo lugar, Obviamente, estou ciente de que se trata de um registro absoluto, sem normalização por campo de conhecimento, ano de publicação, etc. Em terceiro lugar, provavelmente não uso o cálculo mais honesto, ou seja, sumario citações de todas as versões do manual (assim como de outras referências bibliográficas - todas as versões do DSM, todos os volumes de receitas numéricas etc.), enquanto que no cálculo usual, sem de qualquer soma, o manual é encontrado apenas em 40º lugar (daqui em diante em 51, 61, etc. o local também está lá, mas datado de um ano diferente, para uma versão diferente do manual, o artigo a antes dos dois pontos é escrito em letras maiúsculas, etc. .).
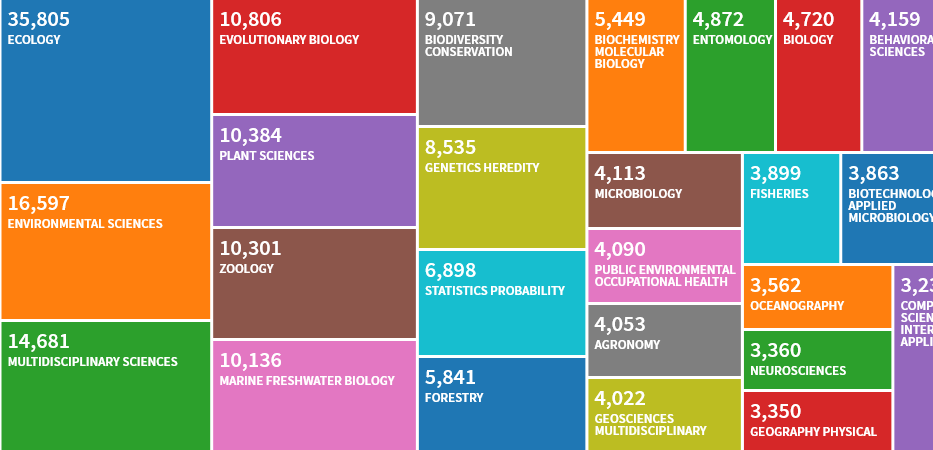 As 25 principais categorias de WoS citadas pelo manual. A situação é semelhante no Scopus.
As 25 principais categorias de WoS citadas pelo manual. A situação é semelhante no Scopus.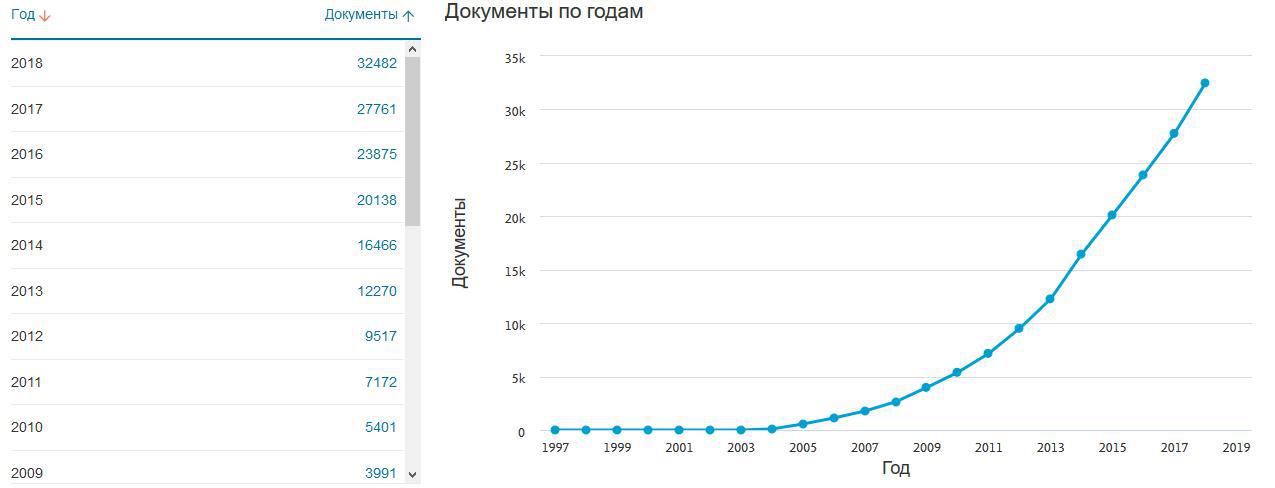 Um aumento no número de citações do manual no Scopus, com valores semelhantes para WoS.
Um aumento no número de citações do manual no Scopus, com valores semelhantes para WoS.Também é importante lembrar que nem em todos os casos, se os autores de uma publicação acadêmica usassem algum tipo de ferramenta (no sentido amplo, seja hardware ou software, ou um teorema, ou um argumento lógico etc.), eles definitivamente forneceriam um link para ele, portanto, objeto de um estudo separado, quanto essa menção frequente do manual reflete seu uso frequente na redação de artigos científicos (sabe-se que R é popular na ciência, a questão é diferente, de acordo com os números, talvez haja alguma outra fonte não acadêmica, de realmente usado frequentemente, mas não mencionado na bibliografia).
Por exemplo, de acordo com
esta revisão, de fato, ao pesquisar no banco de dados do Google Scholar e de acordo com os dados de 2018, o SPSS é usado uma vez e meia mais vezes para escrever trabalhos acadêmicos. O autor explica isso pela complexidade de dominar R. Gostaria, no entanto, de uma análise comparativa em diferentes bases, porque a seleção de publicações indexadas e, consequentemente, os indicadores de citação diferem.
Por que R é tão importante para os cientistas? Andy Wills, no Linux Journal,
escreve sobre R à luz da idéia de ciência aberta e em conexão com a relevância da crise de reprodutibilidade em psicologia. A psicóloga e cientista de dados
Evgeny Tomilov , a quem me dirigi, justificou a importância de R para a ciência na resposta:
R permite criar protocolos de pesquisa reproduzíveis, incluindo dados e seu processamento. Em condições de total falsificação e necessidade urgente de aumentar a reprodutibilidade e credibilidade dos trabalhos científicos, o uso dessa ferramenta é pelo menos útil e, pelo menos, ético.
Z.Y. Também é interessante que o Google Scholar tenha
um perfil R Core Team semelhante aos perfis de pesquisadores individuais, com um bom índice de Hirsch de 50 (para isso, você precisa ter mais de 50 publicações, para que a publicação de 50 em sequência, ao classificar pelo número de citações, tenha um número citações iguais a 50).
* É difícil fornecer uma data exata devido às peculiaridades do cálculo e detalhamento dos dados, provavelmente isso aconteceu nos últimos meses.
** ou seja, os proprietários do cartão de biblioteca da Biblioteca Nacional da Rússia, RSL, e da biblioteca Gorky e cartão de estudante da Universidade Estadual de São Petersburgo, além de várias outras universidades.
Como reproduzir o KDPV:
Na seção "Pesquisar por bibliografia de referência", é possível inserir a consulta 1000-2999 na pesquisa por ano e obter uma amostra de 264 milhões de resultados de 268 (os demais provavelmente não indicaram o ano, mas é improvável que sejam de alguma forma essenciais para manipulações subsequentes) . Classifique por número de citações. Em seguida, exporte os resultados e filtre os que possuem uma coluna Origem, mas nenhuma coluna Cabeçalho (por exemplo, no caso de um artigo de revista, o nome da revista é dado no primeiro caso e o título da publicação no segundo, depois o conteúdo ambas as colunas serão as mesmas e, somente no caso de fontes não indexadas, a coluna "Título" ficará vazia). E você pode manualmente ou através de um script para obter os resultados das citações resumidas para cada registro único (ou seja, combinar os dados nas referências bibliográficas exportadas citadas em diferentes ortografia, indicando diferentes edições, páginas individuais, etc.).