Se seus lançamentos são extremamente rápidos, automatizados e confiáveis, você não pode ler este artigo.
Anteriormente, nosso processo de lançamento era manual, lento e com bugs.
Falhamos no sprint após o sprint, porque não tivemos tempo para criar e apresentar os recursos para a próxima revisão do sprint. Nós odiamos nossos lançamentos. Muitas vezes eles duravam de três a quatro dias.
Neste artigo, descreveremos a prática Stop the Line, que nos ajudou a focar na correção de problemas de layout. Em apenas três meses, conseguimos aumentar a taxa de implantação em 10 vezes. Hoje, nossa implantação é totalmente automatizada e o lançamento do monólito leva apenas 4-5 horas.
Pare a linha. Prática inventada pela equipe
Lembro-me de como criamos Stop the Line. Em uma retrospectiva geral, discutimos lançamentos longos que nos impediam de atingir objetivos de sprint. Um de nossos desenvolvedores sugeriu:
- [Sergey] Vamos limitar o volume do lançamento. Isso nos ajudará a testar, corrigir erros e implantar mais rapidamente.
- [Dima] Podemos introduzir uma restrição ao trabalho em andamento (limite WIP)? Por exemplo, assim que tivermos completado 10 tarefas, paramos o desenvolvimento.
- [Desenvolvedores] Mas as tarefas podem ter tamanhos diferentes. Isso não resolverá o problema de grandes versões.
- [I] Vamos introduzir uma restrição com base na duração do lançamento, e não no número de tarefas. Pararemos o desenvolvimento se o lançamento demorar muito.
Decidimos que, se o lançamento durar mais de 48 horas, acenderemos a luz intermitente e interromperemos o trabalho de todas as equipes nos recursos de negócios do monólito. Todas as equipes que trabalham no monólito devem interromper o desenvolvimento e se concentrar em promover o lançamento atual na venda ou eliminar os motivos que causaram o atraso no lançamento. Quando o lançamento está parado, não faz sentido criar novos recursos, porque eles ainda estarão disponíveis em breve. No momento, é proibido escrever um novo código, mesmo em ramificações separadas.
Também introduzimos “Stop the Line Board” em um simples flip chart. Nele, escrevemos tarefas que ajudam a enviar a versão atual ou a evitar os motivos de seu atraso.
Obviamente, Stop The Line não é uma decisão fácil, mas essa prática é um passo importante em direção à entrega contínua e DevOps genuíno.
História do Dodo IS (Preâmbulo Técnico)O Dodo IS é escrito principalmente na estrutura .Net com uma interface do usuário no React / Redux, no jQuery e intercalado no Angular. Ainda existem aplicativos para iOS e Android no Swift e Kotlin.
A arquitetura Dodo IS é uma mistura de um monólito herdado e cerca de 20 microsserviços. Desenvolvemos novos recursos de negócios em microsserviços separados, que são implantados a cada confirmação (implantação contínua) ou mediante solicitação, quando a empresa precisar, pelo menos a cada cinco minutos (entrega contínua).
Mas ainda temos uma grande parte de nossa lógica de negócios implementada em uma arquitetura monolítica. O monólito é o mais difícil de implantar. Leva tempo para montar o sistema inteiro (o artefato de construção pesa cerca de 1 GB), executar testes de unidade e integração e executar a regressão manual antes de cada release. O lançamento em si também é lento. Cada país tem sua própria cópia do monólito, portanto, devemos distribuir 12 cópias para 12 países.
A Integração Contínua (IC) é uma prática que ajuda os desenvolvedores a manter constantemente o código em condições de trabalho, aumentando o produto em pequenas etapas, integrando pelo menos diariamente em uma ramificação com o suporte da criação do IC com muitos autotestes.
Quando várias equipes trabalham no mesmo produto e praticam o IC, o número de mudanças no ramo geral cresce rapidamente. Quanto mais alterações você acumular, mais essa alteração conterá defeitos ocultos e possíveis problemas. É por isso que as equipes preferem implantar alterações com freqüência, o que leva à prática da Entrega Contínua (CD) como o próximo passo lógico após o IC.
A prática do CD permite implantar código no prod a qualquer momento. Essa prática é baseada em um pipeline de implantação - um conjunto de etapas automáticas ou manuais que verificam o incremento de um produto a caminho de um produto.
Nosso pipeline de implantação é assim:
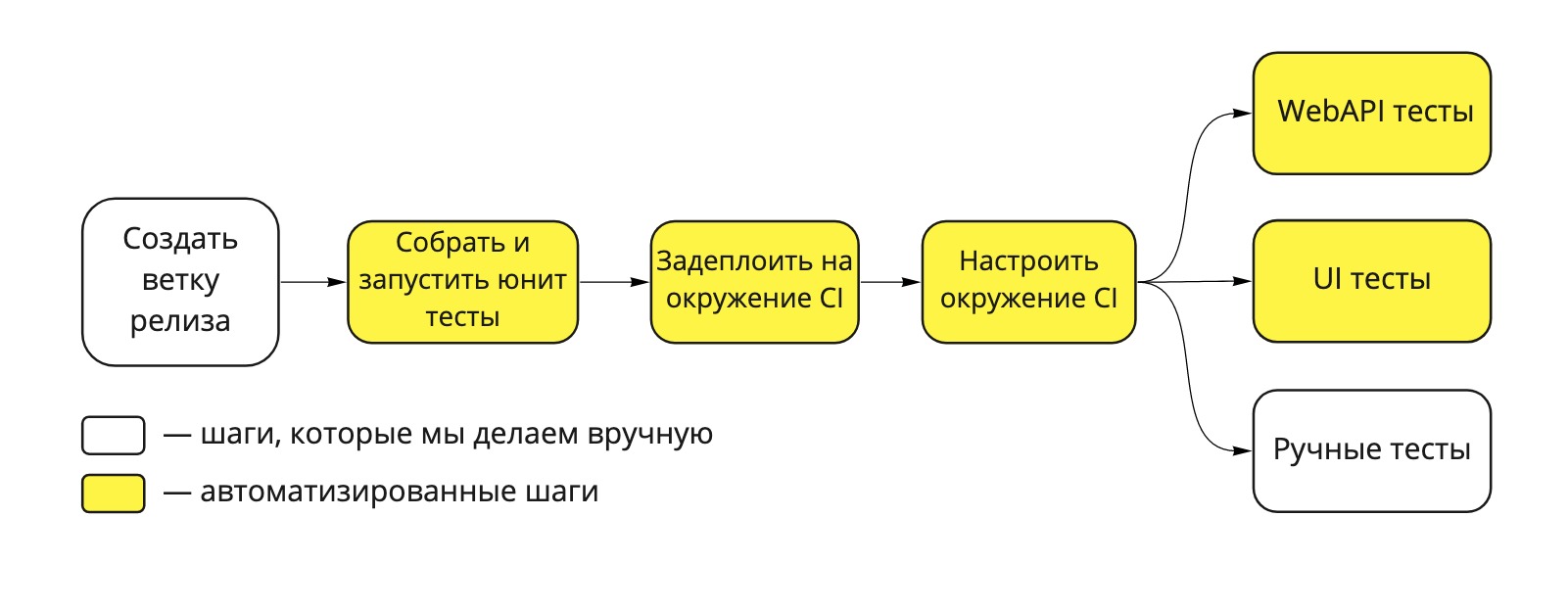
Fig. 1. Dodo IS Deployment Pipeline
Vamos liberar rapidamente: do problema para a prática Stop the line adaptada
A dor de lançamentos lentos. Por que eles são tão longos? Análise
A programação extrema (XP) tem uma regra de ouro: se algo machuca, faça o mais rápido possível. Nossos lançamentos sempre foram uma dor. Passamos vários dias para implantar o ambiente de teste, restaurar o banco de dados, executar os testes (geralmente várias vezes), descobrir por que eles caíram, corrigir bugs e, finalmente, liberar.
O Sprint dura 2 semanas e o lançamento rola por três dias. Para poder lançá-lo antes da Sprint Review na sexta-feira, inicie o lançamento na segunda-feira de uma maneira boa. Isso significa que estamos trabalhando com o objetivo de correr apenas 50% das vezes. E se pudéssemos liberar todos os dias, o período produtivo de trabalho aumentaria para 80-90%.
Nossa liberação média geralmente levava dois a três dias. Inicialmente, seis equipes trabalharam no código no ramo de desenvolvimento geral (e com o crescimento da empresa, o número de equipes aumentou para nove). Pouco antes do lançamento, criamos o ramo de lançamento. Enquanto esse ramo está sendo testado e regredido, as equipes continuam a se desenvolver no ramo de desenvolvimento geral. Antes que o ramo de lançamento atinja as vendas, as equipes escrevem bastante código.
Quanto mais alterações no incremento, maior a probabilidade de que as alterações feitas por equipes diferentes se afetem, o que significa que, com mais cuidado, o incremento deve ser testado e mais tempo será necessário para liberá-lo. Este é um ciclo de auto-reforço (veja a Fig. 2). Quanto mais alterações na liberação (liberação "cavalo"), maior o tempo de regressão. Quanto maior o tempo de regressão, mais tempo entre os lançamentos e mais mudanças a equipe faz antes do próximo lançamento. Nós chamamos de "cavalos dão à luz cavalos". O seguinte diagrama CLD (diagrama de loop causal) ilustra esse relacionamento:
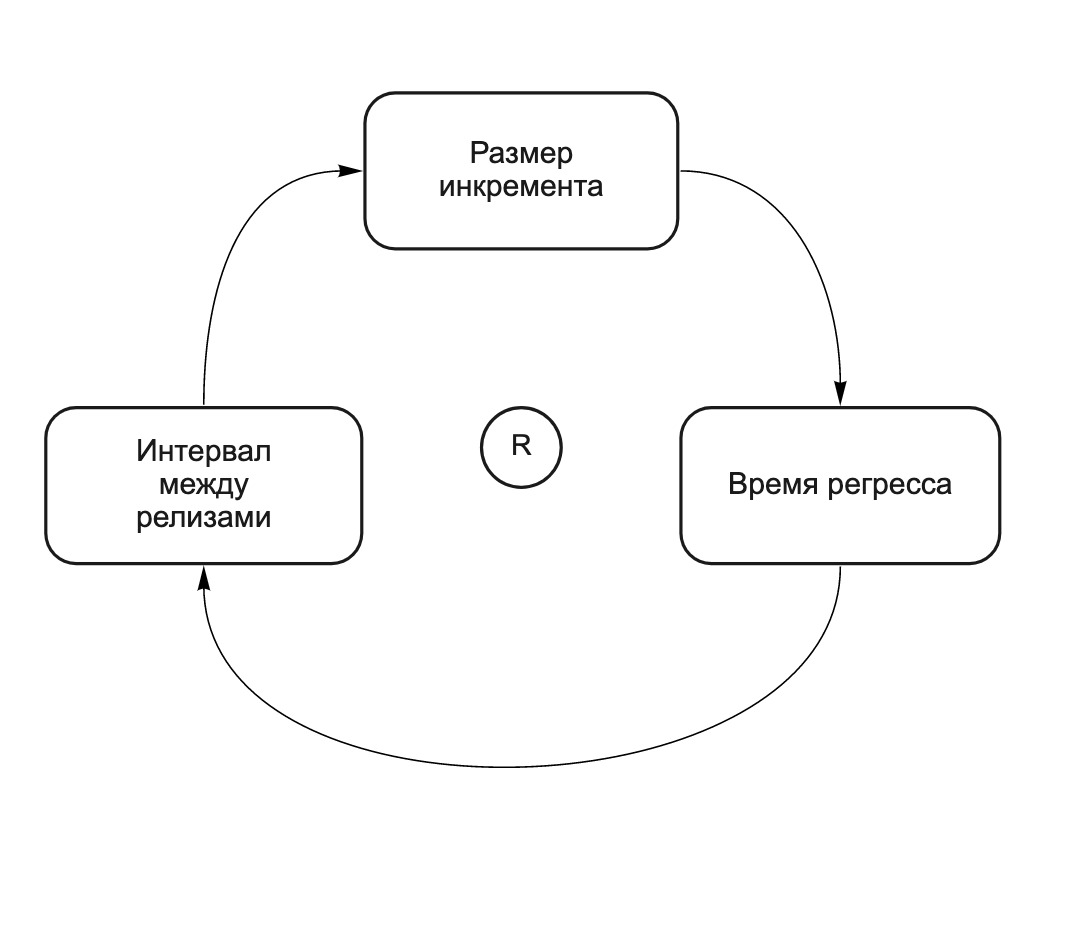
Fig. 2. Diagrama CLD: lançamentos longos levam a lançamentos ainda mais longos
Automação de regressão com comando QA
As etapas que compõem um release- Configuração do ambiente. Restauramos a base de vendas (675 GB), criptografamos dados pessoais e limpamos as filas do RabbitMQ. A criptografia de dados é uma operação muito demorada e leva cerca de 1 hora.
- Execute testes automáticos. Alguns testes de interface do usuário são instáveis, portanto somos forçados a executá-los várias vezes até que eles passem. A correção de testes intermitentes requer muita atenção e disciplina.
- Testes de aceitação manual. Algumas equipes preferem fazer a aceitação final antes que o código seja produzido. Isso pode levar várias horas. Se eles encontrarem erros, damos às equipes duas horas para corrigi-las, caso contrário, elas devem reverter suas alterações.
- Implantar no prod. Como temos cópias separadas do Dodo IS para cada país, o processo de implantação leva algum tempo. Após a conclusão da implantação no primeiro país, observamos os logs por algum tempo, procuramos erros e continuamos a implantação em outros países. Todo o processo geralmente leva cerca de duas horas, mas às vezes pode demorar mais, especialmente se você precisar reverter o lançamento.
Inicialmente, decidimos nos livrar do teste de regressão manual, mas o caminho para isso foi longo e difícil. Dois anos atrás, a regressão manual do Dodo IS durou uma semana inteira. Em seguida, tivemos uma equipe inteira de testadores manuais que testaram os mesmos recursos em 10 países, semana após semana. Você não invejará esse trabalho.
Em junho de 2017, formamos a equipe de controle de qualidade. O principal objetivo da equipe era automatizar a regressão das operações comerciais mais importantes: receber pedidos e fabricar produtos. Assim que tivemos testes suficientes para começar a confiar em nós, abandonamos completamente os testes manuais. Mas isso aconteceu apenas 1,5 anos após o início da automação de regressão. Depois disso, dissolvemos a equipe de controle de qualidade e a equipe de controle de qualidade se juntou às equipes de desenvolvimento.
No entanto, os testes de interface do usuário têm desvantagens significativas. Como eles dependem dos dados reais no banco de dados, esses dados devem ser configurados. Um teste pode corromper os dados para outro teste. O teste pode falhar não apenas porque alguma lógica está quebrada, mas também devido a uma rede lenta ou a dados desatualizados no cache. Tivemos que fazer um grande esforço para nos livrar dos testes intermitentes e torná-los confiáveis e reproduzíveis.
Um passo para parar a linha. #IReleaseEveryDay Initiative
Criamos uma comunidade semelhante à #IReleaseEveryDay e discutimos como acelerar o pipeline de implantação. As primeiras ações foram as seguintes:
- reduzimos significativamente o conjunto de testes de interface do usuário, lançando testes repetidos e desnecessários. Isso reduziu o tempo de teste em várias dezenas de minutos;
- Reduzimos significativamente o tempo de configuração do ambiente devido à recuperação preliminar do banco de dados e à criptografia de dados. Por exemplo, agora criamos uma cópia de backup do banco de dados à noite e, assim que o lançamento começa, mudamos o ambiente de teste para o banco de dados de backup em alguns segundos.
Graças às soluções acima, reduzimos o tempo médio de lançamento, mas ainda era irritantemente longo. É hora de mudanças no sistema.
E se ...
Introduzimos a regra de que, se o lançamento durar mais de 48 horas, acenderemos a luz intermitente e interromperemos o trabalho de todas as equipes nos recursos de negócios do monólito. Todas as equipes que trabalham no monólito devem interromper o desenvolvimento e se concentrar em lançar o lançamento atual para a venda ou eliminar os motivos que atrasaram o lançamento.
Quando o lançamento está parado, não faz sentido criar novos recursos, porque eles ainda estarão disponíveis em breve. No momento, é proibido escrever um novo código, mesmo em ramificações separadas. Esse princípio é descrito no artigo de Entrega contínua de Martin Fowler: "Em caso de problemas com o layout, sua equipe deve priorizar a solução desses problemas acima de trabalhar em novos recursos".
Entourage pisca-pisca
Durante Stop the line, um pisca-pisca laranja acende no escritório. Quem chega ao terceiro andar, onde os desenvolvedores do Dodo IS trabalham, vê esse sinal visual. Decidimos não enlouquecer nossos desenvolvedores com o som de uma sirene e deixamos apenas uma luz irritante. Tão concebido. Como podemos nos sentir confortáveis quando uma versão está com problemas?

Fig. 3. Blinker Stop the Line
Resistência da equipe e pequena sabotagem
No começo, a Stop the Line gostava de todos os times, porque era divertido. Todo mundo ficou feliz quando criança e colocou fotos de nossas luzes de emergência. Mas quando queima 3-4 dias seguidos, não se torna engraçado. Um dia, uma das equipes quebrou as regras e carregou o código no ramo de desenvolvimento durante o Stop the Line para salvar seu objetivo de sprint. É mais fácil quebrar uma regra se estiver impedindo você de trabalhar. Essa é uma maneira rápida e suja de executar um recurso de negócios, ignorando um problema no sistema.
Como Scrum Master, não pude tolerar violações das regras, então levantei essa questão em uma retrospectiva geral. Tivemos uma conversa difícil. A maioria das equipes concordou que as regras se aplicam a todos. Concordamos que cada equipe deve cumprir as regras, mesmo que não concorde com elas. E, ao mesmo tempo, sobre como você pode alterar as regras sem esperar pela próxima retrospectiva.
O que não deu certo como pretendido?
Inicialmente, os desenvolvedores não se concentraram em resolver problemas do sistema com o pipelint de implantação. Quando a liberação travou, em vez de ajudar a eliminar as causas do atraso, eles preferiram desenvolver microsserviços que não estavam sujeitos à regra Stop the Line. Os microsserviços são bons, mas os problemas do monólito não se resolverão. Para resolver esses problemas, introduzimos o backlog Stop The Line.
Algumas soluções eram soluções rápidas que escondiam problemas em vez de resolvê-los. Por exemplo, muitos testes foram reparados aumentando o tempo limite ou adicionando repetições. Um desses testes foi executado por 21 minutos. O teste procurou o funcionário criado mais recentemente em uma tabela sem um índice. Em vez de corrigir a lógica da solicitação, o programador adicionou 3 tentativas. Como resultado, o teste lento tornou-se ainda mais lento. Quando a Stop The Line criou uma equipe de proprietários focada em problemas de teste, nos três sprints seguintes, eles conseguiram acelerar nossos testes 2-3 vezes.
Como foi o comportamento das equipes após praticar o Stop the Line?
Anteriormente, apenas uma equipe tinha problemas com um lançamento - um que o apoiava. As equipes tentaram se livrar desse dever desagradável o mais rápido possível, em vez de investir em melhorias de longo prazo. Por exemplo, se os testes no ambiente de teste tiverem caído, eles poderão ser reiniciados localmente e, se os testes forem aprovados, continue com a liberação. Com a introdução do Stop The Line, as equipes agora têm tempo para estabilizar os testes. Reescrevemos o código de preparação do teste, substituímos alguns testes da interface do usuário por testes da API e removemos tempos limite desnecessários. Agora, quase todos os testes passam rapidamente e em qualquer ambiente.
Anteriormente, as equipes não se envolviam sistematicamente em dívidas técnicas. Agora temos uma lista de pendências de melhorias técnicas que analisamos durante o Stop the Line. Por exemplo, reescrevemos testes no .Net Core, o que nos permitiu executá-los no Docker. A execução de testes no Docker nos permitiu usar a Selenium Grid para paralelizar testes e reduzir ainda mais o tempo de execução.
Anteriormente, as equipes contavam com uma equipe de controle de qualidade para testes e uma equipe de infraestrutura para implantação. Agora não há ninguém em quem confiar, exceto eles mesmos. As próprias equipes testam e liberam o código na Produção. Estes são DevOps genuínos, não falsos.
A evolução do método Stop the line
Em uma retrospectiva geral do sprint, estamos revisando experimentos. Nas próximas retrospectivas, fizemos muitas alterações nas regras Stop the Line, por exemplo:
- Canal de lançamento. Todas as informações sobre a versão atual estão em um canal Slack separado. O canal possui todas as equipes cujas alterações estão incluídas no release. Nesse canal, o lançador pede ajuda.
- Revista de Lançamento. A pessoa responsável pela liberação registra suas ações. Isso ajuda a encontrar os motivos do atraso na liberação e a descobrir padrões.
- A regra de cinco minutos. Cinco minutos após o anúncio do Stop the Line, os representantes da equipe se reúnem em torno da luz de emergência.
- Lista de pendências Pare a linha. Há um flipchart na parede com a lista de pendências Stop The Line - uma lista de tarefas que as equipes podem executar enquanto a linha para.
- Não leve em consideração a última sexta-feira do sprint. É injusto comparar dois lançamentos, por exemplo, um que começou na segunda-feira e outro que começou na sexta-feira. A primeira equipe pode passar dois dias inteiros apoiando o lançamento, e durante o segundo lançamento haverá muitos eventos na sexta-feira (Revisão da Sprint, Retrospectiva da Equipe, Retrospectiva Geral) e na próxima segunda-feira (Planejamento Geral e da Sprint da Equipe), para que a equipe da sexta-feira tenha menos tempo para liberar suporte. A liberação de sexta-feira será interrompida com mais probabilidade do que segunda-feira. Portanto, decidimos excluir a última sexta-feira do sprint da equação.
- Eliminação de dívida técnica. Depois de alguns meses, as equipes decidiram que, durante a parada, poderiam trabalhar com dívidas técnicas, e não apenas com a aceleração do pipeline de implantação.
- Proprietário para a linha. Um dos desenvolvedores se ofereceu para se tornar o proprietário da Stop The Line. Ele está profundamente imerso nas razões do atraso nas liberações e gerencia o backlog da Stop the Line. Quando a linha para, o proprietário pode atrair qualquer equipe para trabalhar nos elementos da lista de pendências Stop the Line.
- Post mortem. O proprietário da Stop the Line mantém um post mortem após cada parada.
Custo de perdas
Devido ao Stop the Line, não cumprimos vários objetivos de sprint. Os representantes comerciais não ficaram muito satisfeitos com o nosso progresso e fizeram muitas perguntas na Sprint Review. Seguindo o princípio da transparência, falamos sobre o que é Stop the Line e por que você deve esperar mais alguns sprints. Em cada revisão da Sprint, mostramos às equipes e partes interessadas quanto dinheiro perdemos devido ao Stop the Line. O custo é calculado como o salário total das equipes de desenvolvimento durante o tempo de inatividade.
• novembro - 2 106 000 p.
• dezembro - 503 504 p.
• janeiro - 1 219 767 p.
• fevereiro - 2 002 278 p.
• março - 0 p.
• abril - 0 p.
• Maio - 361 138 p.
Essa transparência cria uma pressão saudável e motiva as equipes a resolver imediatamente os problemas do pipeline de implantação. Observando esses números, nossas equipes entendem que nada sai de graça e cada Stop the Line nos dá um belo centavo.
Resultados
De fato, a prática Stop the Line converte um ciclo de auto-reforço (Fig. 2) em dois ciclos de balanceamento (Fig. 4). O Stop the Line nos ajuda a focar na melhoria do pipeline de implantação quando ele fica muito lento. Em apenas 4 sprints, nós:
- Lançadas 12 versões estáveis
- Tempo de construção reduzido em 30%
- Testes de interface do usuário e API estabilizados. Agora eles transmitem todos os ambientes e até localmente.
- Livre-se dos testes intermitentes
- Começou a confiar em nossos testes.
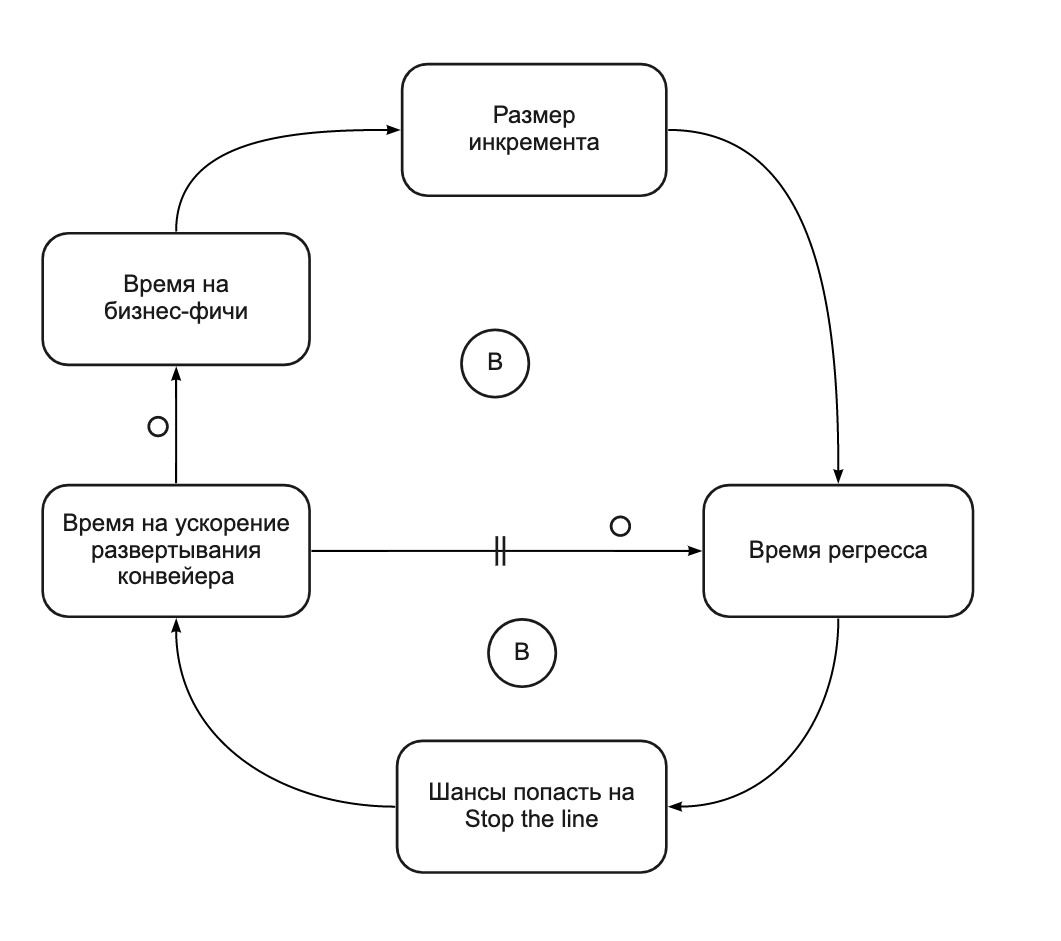
Fig. 4. Gráfico CLD: interrompe o tempo de liberação dos saldos da linha
Conclusões do Scrum Masters
Stop The Line é um excelente exemplo de uma solução poderosa inventada pelas próprias equipes de desenvolvimento. O Scrum Master não pode apenas levar e levar às equipes uma nova prática brilhante. A prática só funcionará se as próprias equipes vierem com ela. Isso requer condições favoráveis: uma atmosfera de confiança e uma cultura de experimentação.
Certamente, são necessários a confiança e o suporte dos negócios, o que é possível apenas com total transparência. O feedback, como uma retrospectiva geral e regular com todos os representantes da equipe, ajuda a inventar, implementar e modificar novas práticas.
Com o tempo, a prática de Stop the Line deve se matar. Quanto mais frequentemente paramos a linha, mais investimos no pipeline de implantação, mais estável e rápida a liberação se torna, menos razão para parar. No final, a linha nunca para, a menos que decida diminuir o limite, por exemplo, de 48 para 24 horas. Mas, graças a essa prática, aprimoramos bastante o procedimento de liberação. As equipes ganharam experiência não apenas no desenvolvimento, mas também na rápida entrega de valor aos produtos. Esses são DevOps genuínos.
O que vem a seguir? Eu não sei Talvez em breve abandonemos essa prática. As equipes decidirão. Mas é óbvio que continuaremos avançando em direção à Entrega contínua e DevOps. Um dia, meu sonho de lançar um monólito várias vezes ao dia se tornará realidade.