
Imagine que você discutiu com um amigo o que aconteceu antes - uma
galinha ou um ovo, algum aumento de impostos, por exemplo, ou notícias sobre esse tópico, ou um evento importante que abafou completamente uma nuvem de notícias sobre uma nova música, por exemplo, Kirkorov. Seria conveniente calcular a quantidade de notícias sobre cada tópico em um determinado momento e visualizá-las. Na verdade, é com isso que o projeto “Runet News Radar” lida. Abaixo, mostramos o que o aprendizado de máquina tem a ver com ele e como qualquer voluntário pode participar disso.
Referência rápida
O aprendizado de máquina para o bem social (ML4SG) é uma iniciativa da comunidade ODS que visa criar as condições para os projetos, como o nome sugere, que usam o aprendizado de máquina para trazer algum benefício à sociedade. A criação de condições aqui refere-se principalmente a recursos organizacionais. Parece algo assim: alguém formula a idéia do projeto e incentiva os voluntários, enquanto alguém simplesmente se junta ao projeto, por uma idéia, experiência ou algum outro interesse. Tudo depende do entusiasmo, na maioria das vezes no tempo livre do trabalho principal. O radar de notícias sobre runas, ou como chamamos brevemente na equipe de notícias, é um dos projetos do ML4SG.
Isenção de responsabilidade
Em algumas ilustrações deste artigo, alguns eventos ou pessoas políticas serão mencionados. Vamos deixar opiniões sobre eles para nós mesmos. Habr não é para política.
O que fazemos
Em poucas palavras sobre motivação
Agora, o projeto está posicionado como uma ferramenta para analisar a mídia como um todo. Se houver alguma hipótese sobre como a atenção nas notícias se desenvolveu para vários tópicos, eventos, pessoas etc., podemos falar com base em números específicos, não na especulação.
A idéia inicial era a seguinte: pegamos todos os dados de notícias que encontramos, aplicamos modelagem temática, apresentamos os resultados a tempo e desenhamos o resultado.
O que é modelagem temáticaDefinição de machinelearning.ru:
Um modelo de tópico é uma coleção de documentos de texto que determina a quais tópicos cada documento de coleção pertence. O algoritmo para construir um modelo temático recebe uma coleção de documentos de texto na entrada. A saída para cada documento é um vetor numérico composto por estimativas do grau de pertença deste documento a cada um dos tópicos. A dimensão desse vetor, igual ao número de tópicos, pode ser configurada na entrada ou determinada automaticamente pelo modelo.
Mais detalhes
aqui .
É claro que isso requer as notícias em si, e nós as baixamos. E como teremos um grande corpo de notícias, você pode fazer muitas coisas mais interessantes, não se limitando a temas. Mas levando em conta as condições reais, das quais falaremos, a saber, que a multidão de voluntários, e não uma equipe bem trabalhada de especialistas pagos, implementará o projeto, primeiro ainda resolvemos o problema quase inalterado.

Agora chegamos a esse formato de visualização, chamado de ridgeline plot. A propósito, no slide, esses tópicos são uma tela de uma antiga demonstração interna. Ou seja, aqui temos tempo no eixo das abcissas, a espessura da faixa é proporcional ao quanto o tópico naquele momento é representado entre outras notícias. Nesse caso, agregação por mês.
No plano básico, temos uma fonte de notícias e uma forma de mostrar um gráfico. Você também pode selecionar dados adicionais que não sejam das notícias, por exemplo, como o preço do petróleo ou qualquer outro indicador se comportou naquele momento no mesmo período. A escolha de um cabeçalho e um conjunto de tópicos nele. Além disso, há muito mais idéias, mas mais sobre isso mais tarde.
Projetos similares
Existem muitos outros projetos relacionados à visualização de notícias. Eu gosto
desses dois . O primeiro compara como as mesmas notícias são apresentadas em diferentes fontes e, ao mesmo tempo, uma forma muito boa de apresentação e interatividade. O segundo simplesmente tem uma atitude muito boa de informatividade em relação à simplicidade. Ele compara o quanto é dito sobre as diferentes causas de morte nas notícias, com que frequência as causas de morte são mencionadas nas consultas de pesquisa e como é estatisticamente. Bem, nas conclusões sobre como o terrorismo é superestimado catastroficamente e como as doenças cardíacas e o câncer são subestimados.
Como fazemos
O projeto é bastante direto. Primeiro, baixamos os dados, depois os processamos, fazemos qualquer aprendizado de máquina e desenhamos gráficos. Então criamos um site e todos assistem. Tudo está claro (bem, sim, é claro).

Coleta de dados
Para começar, tivemos um conjunto de dados de fita ru por 20 anos. Basicamente, fizemos todos os experimentos nele. Agora, coletamos várias outras fontes e continuamos coletando tudo o que alcançamos. Existem muitos materiais detalhados sobre raspagem e aranhas, portanto não iremos nos aprofundar neste tópico aqui em detalhes.
PNL
Eu estava mais preocupado com a parte da PNL, porque é difícil formalizar os requisitos para o resultado da temática. Além disso, existem muitas subtarefas laterais. Agora, fizemos várias experiências com diferentes ferramentas para modelagem temática, antes disso, nos livramos do pré-processamento, fizemos muitos benchmarks e comparações. No momento, o bigARTM acabou sendo o líder incontestável em temas em termos de recursos e qualidade. Agora esta é a nossa opção de trabalho, até que alguém mostre algo melhor.
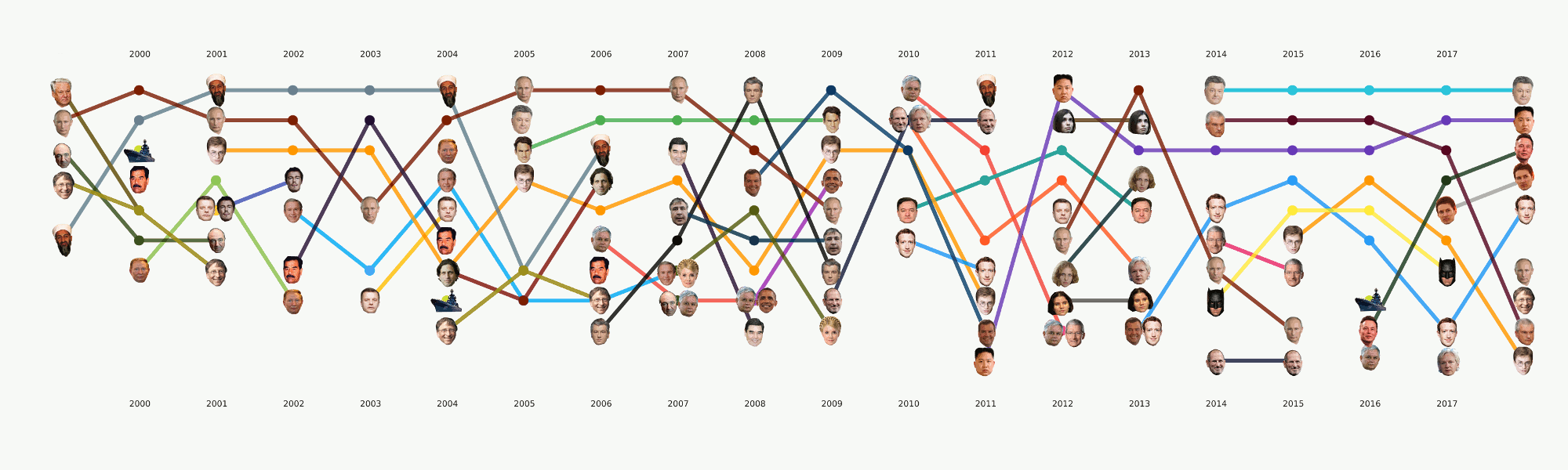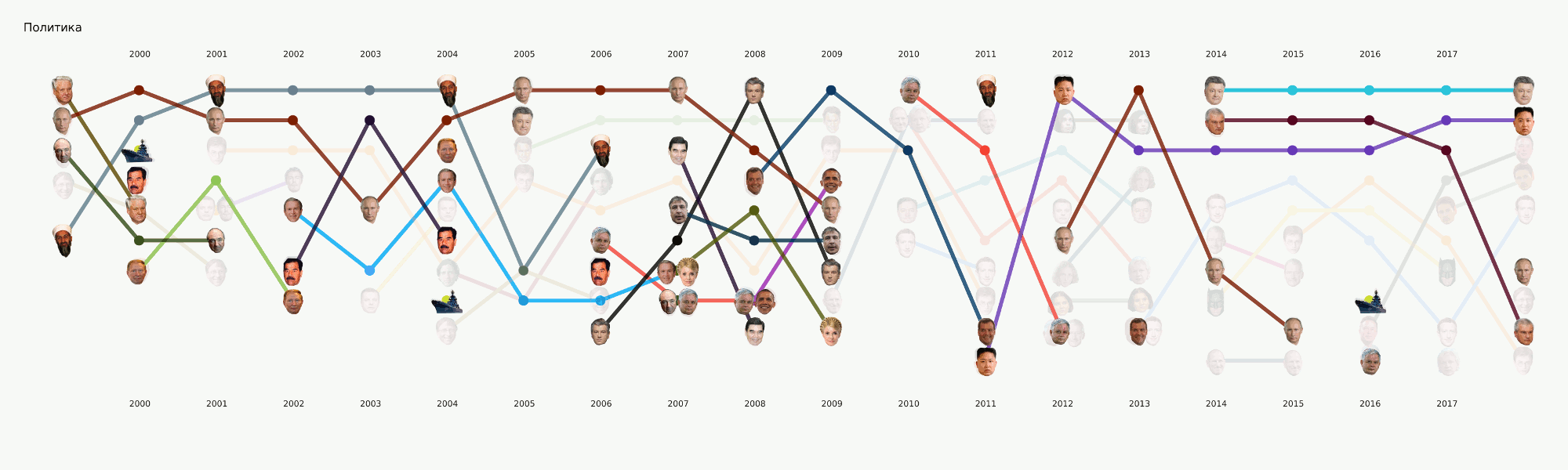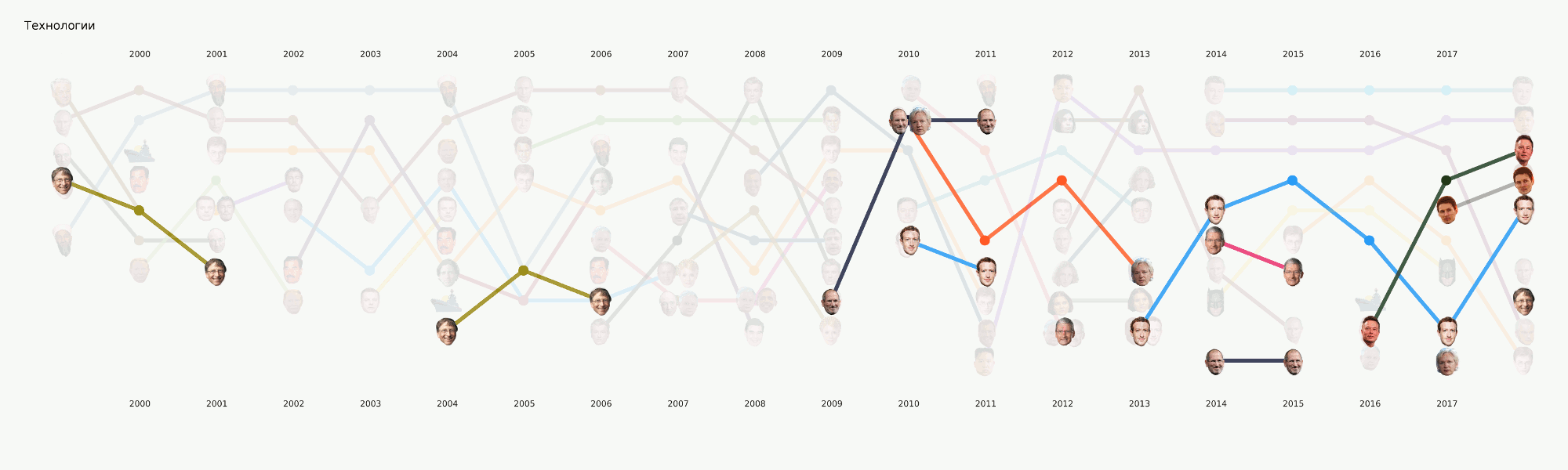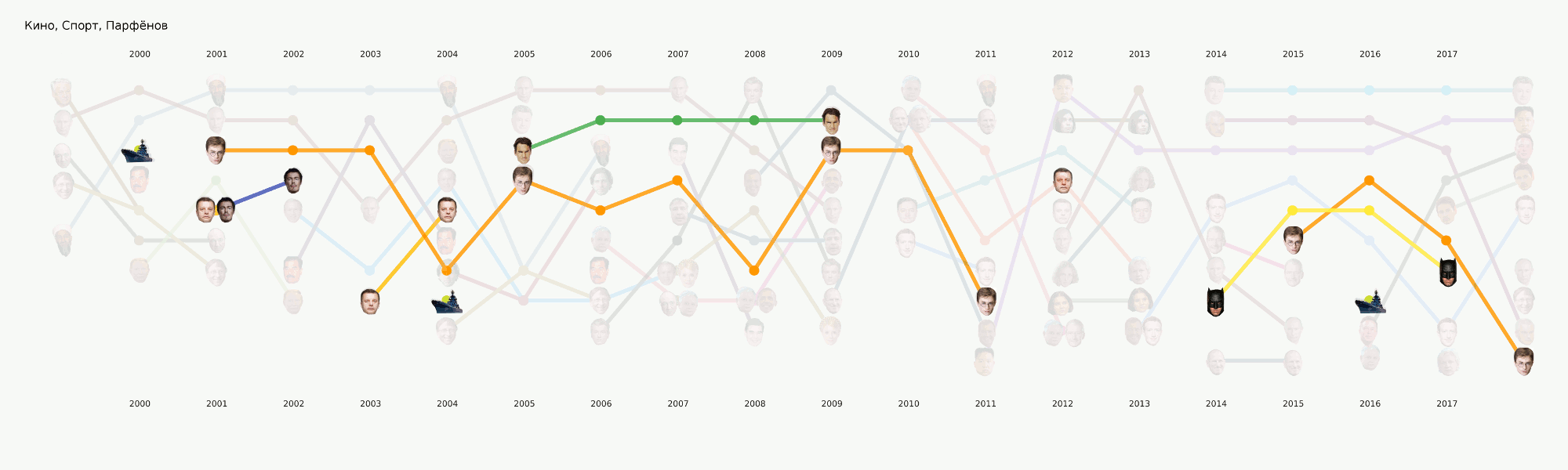
Em geral, todo o aprendizado de máquina está concentrado principalmente nesta seção. Além da principal tarefa de tema originalmente definida, há muitas outras que também trarão conclusões interessantes. Por exemplo, NER. Já retiramos todos os nomes dos dados que compilamos, dicionários compilados, contados a quem mencionamos muitas vezes. Descobriu-se, por exemplo, que por Poroshenko no Lente.ru o tempo todo eles escreviam quatro vezes mais do que Putin. Tornou-se interessante para mim que Assange fosse sincronizado com Magnitsky, e tudo isso exatamente depois que Bush foi embora. Mas o Batman é mais popular que o Medvedev.
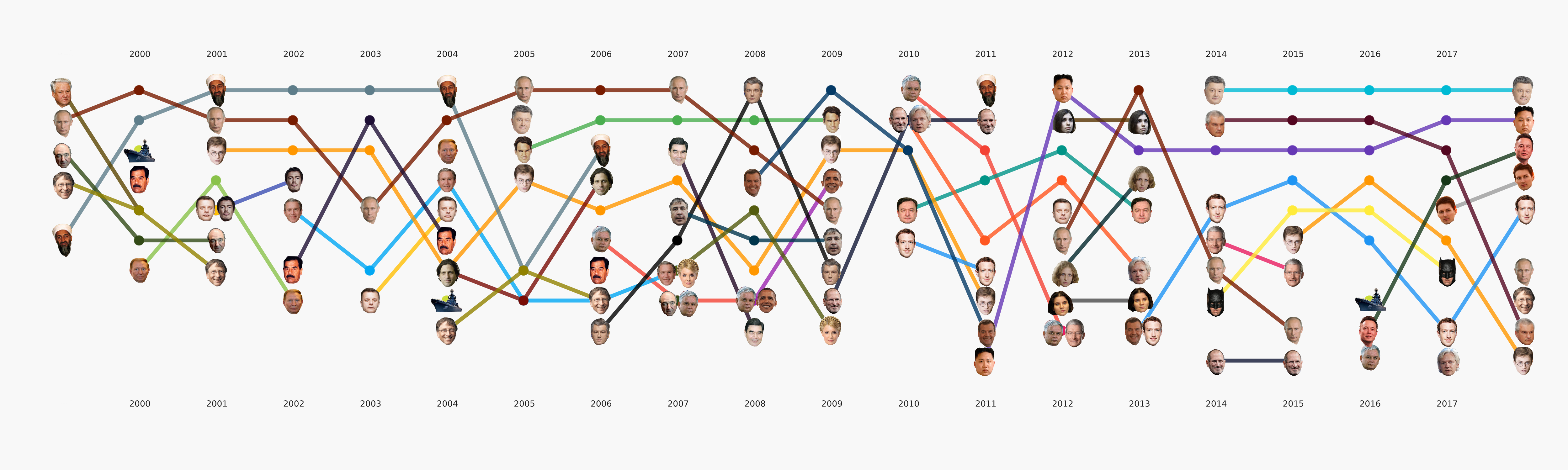

Animação dividida em categoriasEste é um tipo de provocação para os próximos artigos, onde falaremos mais detalhadamente sobre como esse quadro foi apresentado e quais conclusões podem ser tiradas dele.
Embora esse estágio ainda esteja em processo, fizemos um grande número de experimentos e comparamos muitas ferramentas e abordagens. No processo, um grande tutorial sobre várias tarefas da PNL com exemplos de código e benchmarks das ferramentas mais populares e incomuns.
Visualização
Esse estágio não parecia muito complicado, mas por algum motivo quase ninguém estava pronto para lidar com isso. Os requisitos de visualização vão um pouco além da abordagem usual da EDA no sentido de dados. Desenhar um gráfico para você ou para outro datacenter é muito mais fácil do que desenhar para o público em geral. Ficamos muito tempo ocupados com formatos e ferramentas e agora chegamos a algumas abordagens que parecem mais razoáveis, mas ainda há muito trabalho pela frente, já que praticamente não existem ferramentas prontas para nossas tarefas. Por exemplo, o gráfico com as faces acima foi feito em dois estágios - os principais elementos foram gerados no código e, em seguida, seguiu-se um longo estágio de redesenho manual, para que pelo menos alguma coisa fosse lida. Em termos de uma análise detalhada dessa visualização em um artigo separado, ela reflete, em certa medida, a história da Rússia nos últimos 20 anos.
A equipe
É condicionalmente possível dividir os participantes em dois grupos: iniciantes e profissionais. Para iniciantes, a motivação é simples - coloque em um cofrinho algum tipo de projeto para mostrar aos empregadores, ou apenas ganhar experiência, aprender alguma coisa. E eu já estava informado de que as diferentes coisas que fizemos no âmbito do projeto foram úteis no trabalho dos participantes, avaliaram as autoridades. Os profissionais vêm por causa do próprio objetivo do projeto, porque estão interessados em aderir à ideia ou porque querem experimentar algumas de suas idéias nas notícias.
De fato, há outro grupo de participantes - esses são os ninjas indescritíveis que se encaixam e não fazem nada ou apenas começam e depois desaparecem. Mas, como eu já expliquei, ninguém trabalha no projeto por dinheiro, então a desorganização dos recursos humanos é inevitável. A observação do lado da curiosidade também é possível.

Agora, formalmente, existem cerca de 80 pessoas, das quais 10 a 20 são ativas e 2-4 são ativas quase constantemente. Nesse formato, você pode compensar a falta de experiência ao longo do tempo. Muitas pessoas escrevem que não há conhecimento de como fazê-lo, há um medo de falhar por causa da falta de atitude, mas, na verdade, é importante fazê-lo e não esperar um momento. Porque ml4sg é uma atividade muito legal. Você pode ser útil e, ao mesmo tempo, obter lucro na forma de experiência e portfólio, enquanto o risco é apenas o tempo, o gerente também tem uma reputação, é claro, mas o principal recurso aqui é o tempo, que acaba valendo a pena.
Planos adicionais
Agora estou tentando posicioná-lo como uma ferramenta de pesquisa. Planejamos adicionar uma pesquisa "exploratória" que possa avaliar o tópico da solicitação e fornecer estatísticas sobre as notícias deste tópico, gráficos de vários dados não noticiosos, mas relevantes para o tópico do projeto. Então será possível testar todos os tipos de hipóteses sobre como a mídia se comporta, como eventos e outros indicadores arbitrários, sociais ou econômicos, estão relacionados. Tal ferramenta para pesquisar a mídia como um todo.
Quem precisa de um projeto
- Temos muito poucas pessoas envolvidas na visualização. Vamos além das ferramentas usuais do datacenter, como matplotlib ou plotly, portanto precisamos de pessoas que realmente gostem da visualização de dados e que queiram se aprofundar nela.
- Precisamos de pessoas que entendam algo no desenvolvimento da web.
- Precisamos de pessoas que nos digam o que procurar. De fato, devem ser nossos clientes que estão interessados em conduzir um estudo e descobrir algumas coisas sobre como a mídia em língua russa mudou recentemente.
- Sempre precisamos de especialistas em PNL, acho que não há necessidade de explicar aqui. E há algo a fazer para quem quer aprender e para caras experientes, uma vez que existem muitos problemas interessantes nessa área.
- E, é claro, precisamos criar um projeto decente para que tudo não funcione com fita isolante; portanto, se você estiver se atrapalhando na arquitetura dos projetos, poderá montar uma série de experimentos em um pipeline e estar pronto para compartilhar sua experiência. Se você quiser aprender em qualquer lugar, também seja bem-vindo.