
Olá leitores do Habr! Em um artigo anterior, falamos sobre uma ferramenta simples de tolerância a desastres nos sistemas de armazenamento do AERODISK ENGINE - sobre replicação. Neste artigo, abordaremos um tópico mais complexo e interessante - o cluster metro, ou seja, um meio de proteção automatizada contra desastres para dois data centers, que permite que os data centers trabalhem no modo ativo-ativo. Vamos contar, mostrar, quebrar e consertar.
Como sempre, no começo da teoria
Um cluster metropolitano é um cluster espaçado em vários sites dentro de uma cidade ou distrito. A palavra "cluster" indica claramente que o complexo é automatizado, ou seja, a troca de nós do cluster em caso de falhas ocorre automaticamente.
É aqui que reside a principal diferença entre o cluster metro e a replicação comum. Automação de operações. Ou seja, no caso de certos incidentes (falha do datacenter, canais interrompidos etc.), o sistema de armazenamento executará independentemente as ações necessárias para manter a disponibilidade dos dados. Ao usar réplicas regulares, essas ações são executadas total ou parcialmente manualmente pelo administrador.
Para que é isso?
O principal objetivo que os clientes buscam usar uma ou outra implementação do cluster metropolitano é minimizar o RTO (Objetivo de Tempo de Recuperação). Ou seja, minimize o tempo de recuperação dos serviços de TI após uma falha. Se você usar a replicação normal, o tempo de recuperação sempre será maior que o tempo de recuperação com o cluster metropolitano. Porque Muito simples O administrador deve estar no local de trabalho e alternar a replicação manualmente, e o cluster metro faz isso automaticamente.
Se você não tiver um administrador dedicado de plantão que não durma, coma, fume ou fique doente e observe o status de armazenamento 24 horas por dia, não há como garantir que o administrador esteja disponível para troca manual durante uma falha.
Consequentemente, a RTO na ausência de um cluster metropolitano ou administrador imortal nível 99 O serviço de serviço do administrador será igual à soma do tempo de comutação de todos os sistemas e do período máximo após o qual é garantido que o administrador comece a trabalhar com sistemas de armazenamento e sistemas relacionados.
Assim, chegamos à conclusão óbvia de que o cluster metropolitano deve ser usado se o requisito de RTO for minutos, não horas ou dias, ou seja, quando, no caso da pior queda do data center, o departamento de TI deve fornecer às empresas tempo para restaurar o acesso à TI -serviços em minutos ou até segundos.
Como isso funciona?
No nível inferior, o cluster metro usa o mecanismo de replicação de dados síncrona, que descrevemos em um artigo anterior (consulte o link ). Como a replicação é síncrona, os requisitos para ela são apropriados, ou melhor:
- fibra como física, 10 gigabit Ethernet (ou superior);
- a distância entre os data centers não é superior a 40 quilômetros;
- Atraso do canal óptico entre data centers (entre sistemas de armazenamento) até 5 milissegundos (idealmente 2).
Todos esses requisitos são de natureza consultiva, ou seja, o cluster metropolitano funcionará mesmo que esses requisitos não sejam atendidos, mas deve-se entender que as conseqüências do não cumprimento desses requisitos são iguais à desaceleração de ambos os sistemas de armazenamento no cluster metropolitano.
Portanto, uma réplica síncrona é usada para transferir dados entre sistemas de armazenamento e como as réplicas são automaticamente trocadas e, o mais importante, como evitar o cérebro dividido? Para isso, no nível acima, uma entidade adicional é usada - o árbitro.
Como o árbitro trabalha e qual é a sua tarefa?
O árbitro é uma pequena máquina virtual, ou um cluster de hardware, que deve ser executado na terceira plataforma (por exemplo, no escritório) e fornecer acesso ao armazenamento via ICMP e SSH. Após o lançamento, o árbitro deve definir o IP e, em seguida, do lado do armazenamento, indicar seu endereço, além dos endereços dos controladores remotos que participam do cluster do metro. Depois disso, o árbitro está pronto para trabalhar.
O árbitro monitora constantemente todos os sistemas de armazenamento no cluster metro e, se um sistema de armazenamento estiver indisponível, após confirmar a inacessibilidade de outro membro do cluster (um dos sistemas de armazenamento "ativos"), toma a decisão de iniciar o procedimento para alternar regras e mapeamento de replicação.
Um ponto muito importante. O árbitro deve sempre estar em um site diferente daquele em que o armazenamento está localizado, ou seja, no data center-1, onde o armazenamento 1 está localizado, nem no data center-2, onde o armazenamento 2 está instalado.
Porque Porque a única maneira de um árbitro, com a ajuda de um dos sistemas de armazenamento sobreviventes, poder determinar de maneira inequívoca e precisa a queda de qualquer um dos dois sites em que os sistemas de armazenamento estão instalados. Quaisquer outras maneiras de colocar um árbitro podem resultar em um cérebro dividido.
Agora mergulhe nos detalhes do árbitro
O árbitro executa vários serviços que são constantemente interrogados por todos os controladores de armazenamento. Se o resultado da pesquisa for diferente do anterior (disponível / inacessível), ele será registrado em um pequeno banco de dados, que também funciona como árbitro.
Considere a lógica do árbitro em mais detalhes.
Etapa 1. Determinação da inacessibilidade. Um sinal de evento sobre a falha do sistema de armazenamento é a ausência de ping dos dois controladores do mesmo sistema de armazenamento por 5 segundos.
Etapa 2. Inicie o procedimento de comutação. Depois que o árbitro entende que um dos sistemas de armazenamento não está disponível, ele envia uma solicitação ao sistema de armazenamento “ativo” para garantir que o sistema de armazenamento “morto” realmente tenha morrido.
Após receber esse comando do árbitro, o segundo sistema de armazenamento (ativo) verifica adicionalmente a disponibilidade do primeiro sistema de armazenamento caído e, se não estiver, envia ao árbitro a confirmação de suas suposições. O armazenamento não está realmente disponível.
Após receber essa confirmação, o árbitro inicia o procedimento remoto para alternar a replicação e aumentar o mapeamento nas réplicas que estavam ativas (principais) no armazenamento descartado e envia um comando para o segundo armazenamento para fazer essas réplicas de secundárias para primárias e aumentar o mapeamento. Bem, o segundo sistema de armazenamento, respectivamente, executa esses procedimentos, após o qual fornece acesso às LUNs perdidas por si mesmo.
Por que preciso de verificação adicional? Para quorum. Ou seja, a maioria do número ímpar total (3) de membros do cluster deve confirmar a queda de um dos nós do cluster. Somente então essa decisão será exatamente correta. Isso é necessário para evitar a troca incorreta e, consequentemente, o cérebro dividido.
A etapa 2 leva aproximadamente de 5 a 10 segundos, portanto, levando em consideração o tempo necessário para determinar a inacessibilidade (5 segundos), dentro de 10 a 15 segundos após o acidente, os LUNs com armazenamento interrompido estarão automaticamente disponíveis para trabalhar com armazenamento ativo.
É claro que, para evitar desconectar os hosts, você também deve cuidar da configuração correta dos tempos limite nos hosts. O tempo limite recomendado é de pelo menos 30 segundos. Isso não permitirá que o host se desconecte do sistema de armazenamento durante a transferência de carga durante um acidente e será capaz de garantir que não haja interrupção da entrada-saída.
Apenas um segundo, se tudo estiver bem com o cluster metro, por que você precisa de replicação regular?
De fato, nem tudo é tão simples.
Considere os prós e os contras do cluster metro
Portanto, percebemos que as vantagens óbvias do cluster metro em comparação com a replicação convencional são:
- Automação total, proporcionando tempo mínimo de recuperação em caso de desastre;
- E é isso :-).
E agora, atenção, contras:
- O custo da decisão. Embora o cluster metro nos sistemas Aerodisk não exija licenciamento adicional (a mesma licença é usada para a réplica), o custo da solução ainda será maior do que o uso da replicação síncrona. Será necessário implementar todos os requisitos para réplica síncrona, além dos requisitos para o cluster metropolitano relacionados a comutação adicional e site adicional (consulte o planejamento do cluster metropolitano);
- A complexidade da decisão. O cluster metropolitano é muito mais complexo que uma réplica regular e requer muito mais atenção e mão-de-obra no planejamento, configuração e documentação.
No final O cluster Metro é, obviamente, uma solução muito tecnológica e boa quando você realmente precisa fornecer o RTO em segundos ou minutos. Mas se não houver essa tarefa, e o RTO em horas for bom para os negócios, não há sentido em atirar pardais no canhão. A replicação habitual dos camponeses é suficiente, porque o cluster metropolitano incorrerá em custos adicionais e complicará a infraestrutura de TI.
Planejamento do Metro Cluster
Esta seção não afirma ser um guia abrangente para o design do cluster metropolitano, mas mostra apenas as principais direções que devem ser elaboradas se você decidir construir esse sistema. Portanto, com a implementação real do cluster do metro, envolva o fabricante dos sistemas de armazenamento (ou seja, nós) e outros sistemas relacionados para consulta.
Plataformas
Conforme indicado acima, são necessários no mínimo três locais para um cluster de metrô. Dois data centers, onde os sistemas de armazenamento e sistemas relacionados funcionarão, e uma terceira plataforma, onde o árbitro funcionará.
A distância recomendada entre os data centers não é superior a 40 quilômetros. É provável que distâncias maiores causem atrasos adicionais, que no caso de um cluster metropolitano são altamente indesejáveis. Lembre-se, os atrasos devem ser de até 5 milissegundos, embora seja desejável atender a 2.
Também é recomendável verificar atrasos durante o processo de planejamento. Qualquer fornecedor mais ou menos adulto que forneça fibra entre os data centers, uma verificação de qualidade pode ser organizada rapidamente.
Quanto aos atrasos antes do árbitro (ou seja, entre a terceira plataforma e as duas primeiras), o limite de atraso recomendado é de até 200 milissegundos, ou seja, é adequada uma conexão VPN corporativa corporativa pela Internet.
Comutação e Rede
Ao contrário de um esquema de replicação, em que é suficiente interconectar sistemas de armazenamento de sites diferentes, um esquema com um cluster de metrô exige a conexão de hosts com os dois sistemas de armazenamento em sites diferentes. Para esclarecer qual é a diferença, os dois esquemas estão listados abaixo.
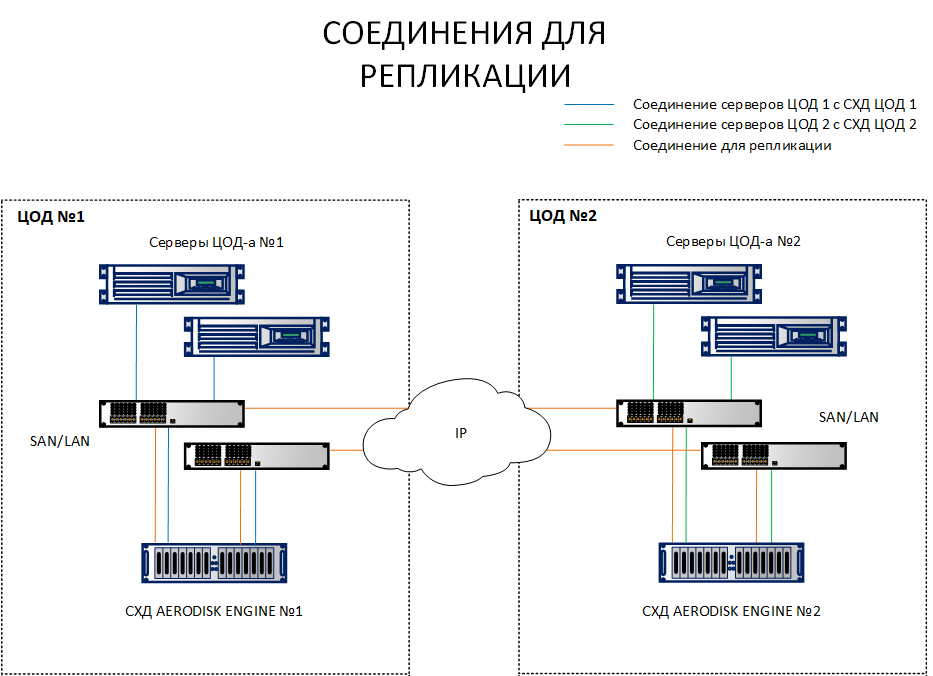

Como você pode ver no diagrama, os hosts no site 1 estão olhando para o SHD1 e o SHD 2. Além disso, pelo contrário, os hosts da plataforma 2 estão olhando para o SHD 2 e o SHD1. Ou seja, cada host vê os dois sistemas de armazenamento. Este é um pré-requisito para a operação do cluster de metrô.
Obviamente, não há necessidade de puxar cada host com um cabo óptico para um data center diferente; nenhuma porta e cadarço será suficiente. Todas essas conexões devem ser feitas através dos comutadores Ethernet 10G + ou FibreChannel 8G + (FC apenas para conectar hosts e armazenamento para E / S, o canal de replicação está atualmente disponível apenas por IP (Ethernet 10G +).
Agora, algumas palavras sobre a topologia de rede. Um ponto importante é a configuração correta das sub-redes. Você deve identificar imediatamente várias sub-redes para os seguintes tipos de tráfego:
- A sub-rede para replicação na qual os dados entre os sistemas de armazenamento serão sincronizados. Pode haver vários, neste caso, não importa, tudo depende da topologia de rede atual (já implementada). Se houver dois deles, obviamente, o roteamento entre eles deve ser configurado;
- Sub-redes de armazenamento através das quais os hosts acessarão recursos de armazenamento (se for iSCSI). Deve haver uma dessas sub-redes em cada data center;
- Sub-redes de controle, ou seja, três sub-redes roteáveis em três sites a partir dos quais o gerenciamento de armazenamento é realizado, e também há um árbitro.
Não consideramos sub-redes para acessar recursos do host aqui, pois eles são altamente dependentes de tarefas.
Separar tráfego diferente em sub-redes diferentes é extremamente importante (é especialmente importante separar a réplica da E / S), porque se você misturar todo o tráfego em uma sub-rede “espessa”, será impossível controlar esse tráfego e, nas condições de dois data centers, ainda poderá causar problemas diferentes. opções de colisão de rede. Não abordaremos muito esse assunto na estrutura deste artigo, pois você pode ler sobre o planejamento de uma rede estendida entre data centers com os recursos dos fabricantes de equipamentos de rede, onde é descrito em detalhes.
Configuração do Árbitro
O árbitro deve fornecer acesso a todas as interfaces de gerenciamento de armazenamento por meio dos protocolos ICMP e SSH. Você também deve considerar a tolerância a falhas do árbitro. Há uma nuance.
A tolerância a falhas do árbitro é muito desejável, mas opcional. E o que acontece se o árbitro falhar na hora errada?
- A operação do cluster metro no modo normal não será alterada, porque O arbtir não afeta a operação do cluster de metrô no modo normal de forma alguma (sua tarefa é alternar oportunamente a carga entre os datacenters)
- Além disso, se o árbitro, por um motivo ou outro, cair e "acordar" o acidente no data center, nenhuma troca ocorrerá, porque não haverá ninguém para dar os comandos necessários para trocar e organizar um quorum. Nesse caso, o cluster do metrô se transformará em um esquema de replicação regular, que precisará ser alternado manualmente durante um desastre, o que afetará a RTO.
O que se segue disso? Se você realmente precisa garantir um RTO mínimo, precisa garantir a tolerância a falhas do árbitro. Existem duas opções para isso:
- Execute uma máquina virtual com um árbitro em um hypervisor de failover, pois todos os hipervisores adultos suportam failover;
- Se estiver no terceiro site (em um escritório condicional)
preguiça de colocar um cluster normal Como não existe um cluster de hypervizor, fornecemos uma versão de hardware do árbitro, feita em uma caixa 2U, na qual dois servidores x-86 comuns funcionam e que podem sobreviver a uma falha local.
É altamente recomendável que o árbitro seja tolerante a falhas, apesar de o cluster metro não precisar dele no modo normal. Mas tanto a teoria quanto a prática mostram que, se você construir uma infra-estrutura à prova de desastre verdadeiramente confiável, é melhor jogar com segurança. É melhor proteger você e sua empresa da "lei da maldade", isto é, da falha do árbitro e de um dos sites onde o sistema de armazenamento está localizado.
Arquitetura da solução
Considerando os requisitos acima, obtemos a seguinte arquitetura geral da solução.

Os LUNs devem ser distribuídos igualmente em dois sites para evitar congestionamentos pesados. Ao mesmo tempo, ao dimensionar nos dois datacenters, é necessário estabelecer não apenas um volume duplo (que é necessário para armazenar dados simultaneamente em dois sistemas de armazenamento), mas também um desempenho duplo em IOPS e MB / s, para evitar a degradação de aplicativos no caso de falha de um dos datacenters - ov.
Separadamente, observamos que, com uma abordagem adequada ao dimensionamento (ou seja, desde que tenhamos fornecido os limites superiores adequados para IOPS e MB / s, bem como os recursos necessários de CPU e RAM), se um dos sistemas de armazenamento falhar no cluster do metro, não haverá redução grave no desempenho trabalho temporário em um sistema de armazenamento.
Isso ocorre pelo fato de que, nas condições de dois sites simultaneamente, o trabalho de replicação síncrona “consome” metade do desempenho da gravação, pois cada transação precisa ser gravada em dois sistemas de armazenamento (semelhante ao RAID-1/10). Portanto, se um dos sistemas de armazenamento falhar, o efeito da replicação temporariamente (até o sistema com falha no armazenamento) desaparecerá e obteremos um aumento duplo no desempenho da gravação. Depois que os LUNs do sistema de armazenamento com falha foram reiniciados em um sistema de armazenamento em funcionamento, esse aumento duplo desaparece devido à carga dos LUNs de outro sistema de armazenamento e retornamos ao mesmo nível de desempenho que tivemos antes da "queda", mas apenas dentro da estrutura de uma plataforma.
Com a ajuda do dimensionamento competente, é possível fornecer condições sob as quais os usuários não sintam a falha de todo um sistema de armazenamento. Mas, novamente, isso requer um dimensionamento muito cuidadoso, para o qual, aliás, você pode entrar em contato conosco gratuitamente :-).
Configuração do Metro Cluster
A configuração de um cluster intermediário é muito semelhante à configuração da replicação regular, descrita em um artigo anterior . Portanto, focamos apenas nas diferenças. Montamos um estande no laboratório com base na arquitetura acima, apenas na versão mínima: dois sistemas de armazenamento conectados pela Ethernet 10G entre si, dois comutadores 10G e um host que examina os comutadores nas duas portas de armazenamento com portas 10G. O árbitro é executado em uma máquina virtual.

Ao configurar IPs virtuais (VIPs) para uma réplica, selecione o tipo VIP para o cluster do metro.

Criamos dois links de replicação para dois LUNs e os distribuímos por dois sistemas de armazenamento: LUN TEST Primary no SHD1 (link METRO), LUN TEST2 Primary no SHD2 (link METRO2).

Para eles, estabelecemos dois destinos idênticos (no nosso caso, iSCSI, mas o FC também é suportado, a lógica da configuração é a mesma).
SHD1:

SHD2:

Para conexões de replicação, eles fizeram mapeamentos em cada sistema de armazenamento.
SHD1:

SHD2:

Multipath configurado e apresentado ao host.


Configure o árbitro
Você não precisa fazer nada de especial com o árbitro, apenas habilitá-lo na terceira plataforma, definir um IP para ele e configurar o acesso a ele via ICMP e SSH. A própria configuração é realizada a partir dos próprios sistemas de armazenamento. Nesse caso, basta configurar o árbitro uma vez em qualquer um dos controladores de armazenamento no cluster metro, essas configurações serão distribuídas a todos os controladores automaticamente.
Na seção Replicação Remota >> Metrocluster (em qualquer controlador) >> botão Configurar.
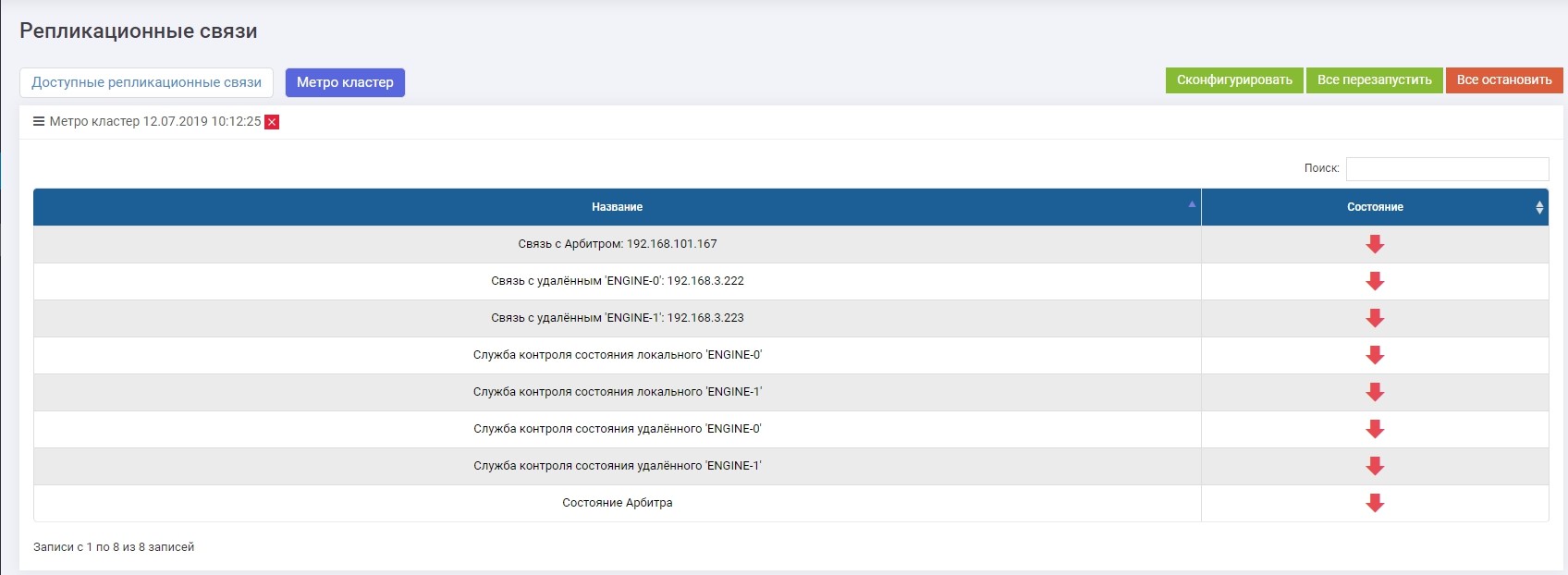
Introduzimos o IP do árbitro, bem como as interfaces de controle dos dois controladores do sistema de armazenamento remoto.

Depois disso, você precisa ativar todos os serviços (o botão "Reiniciar tudo"). No caso de uma reconfiguração no futuro, os serviços devem ser reiniciados para que as configurações tenham efeito.

Verifique se todos os serviços estão em execução.

Isso conclui a configuração do cluster do metro.
Teste de colisão
O teste de colisão no nosso caso será bastante simples e rápido, pois a funcionalidade de replicação (comutação, consistência etc.) foi considerada em um artigo anterior . Portanto, para testar a confiabilidade de um cluster de metrô, basta verificar a automação da detecção de acidentes, comutação e a ausência de perdas de registro (paradas de E / S).
Para fazer isso, simulamos a falha completa de um dos sistemas de armazenamento, desligando fisicamente os dois controladores, iniciando a cópia preliminar de um arquivo grande para o LUN, que deve ser ativado no outro sistema de armazenamento.

Desative um armazenamento. No segundo sistema de armazenamento, vemos alertas e mensagens nos logs de que a conexão com o sistema vizinho desapareceu. Se você configurou alertas para monitoramento SMTP ou SNMP, o administrador receberá alertas apropriados.

Exatamente 10 segundos depois (visto nas duas capturas de tela), o link de replicação do METRO (aquele que era Principal no sistema de armazenamento com falha) tornou-se automaticamente Principal no sistema de armazenamento em execução. Usando o mapeamento existente, o LUN TEST permaneceu disponível para o host, a gravação caiu um pouco (dentro dos 10% prometidos), mas não foi interrompida.


Teste concluído com sucesso.
Resumir
A implementação atual do metrocluster nos sistemas de armazenamento da série N do AERODISK Engine permite solucionar completamente os problemas onde é necessário eliminar ou minimizar o tempo de inatividade dos serviços de TI e garantir sua operação 24/7/365 com custos mínimos de mão-de-obra.
, , , … , , . , , , .
, .