
Meu nome é Eduard Tyantov, lidero a equipe da Computer Vision no Mail.ru Group. Ao longo dos vários anos de existência, nossa equipe resolveu dezenas de problemas de visão computacional, e hoje vou falar sobre os métodos que usamos para criar modelos de aprendizado de máquina que funcionam em uma ampla variedade de tarefas. Compartilharei truques que podem acelerar o modelo em todas as etapas: definição de uma tarefa, preparação de dados, treinamento e implantação na produção.
Computer Vision em Mail.ru
Para começar, o que é o Computer Vision no Mail.ru e quais projetos fazemos. Fornecemos soluções em nossos produtos, como Mail, Mail.ru Cloud (um aplicativo para armazenar fotos e vídeos), Vision (soluções B2B baseadas na visão computacional) e outros. Vou dar alguns exemplos.
O Cloud (este é o nosso primeiro e principal cliente) possui 60 bilhões de fotos. Desenvolvemos vários recursos baseados no aprendizado de máquina para o processamento inteligente, por exemplo, reconhecimento de rosto e passeios turísticos (
há um post separado sobre isso ). Todas as fotos do usuário são executadas em modelos de reconhecimento, o que permite organizar uma pesquisa e um agrupamento por pessoas, tags, cidades e países visitados e assim por diante.
Para o Mail, fizemos OCR - reconhecimento de texto de uma imagem. Hoje vou falar um pouco mais sobre ele.
Para produtos B2B, reconhecemos e contamos pessoas em filas. Por exemplo, há uma fila para o teleférico e você precisa calcular quantas pessoas estão nele. Para começar, para testar a tecnologia e jogar, implantamos um protótipo na sala de jantar do escritório. Existem várias mesas de caixa e, consequentemente, várias filas, e nós, usando várias câmeras (uma para cada uma das filas), usando o modelo, calculamos quantas pessoas estão nas filas e quantos minutos restantes restam em cada uma delas. Dessa forma, podemos equilibrar melhor as linhas na sala de jantar.

Declaração do problema
Vamos começar com a parte crítica de qualquer tarefa - sua formulação. Quase todo desenvolvimento de ML leva pelo menos um mês (isso é o melhor quando você sabe o que fazer) e, na maioria dos casos, vários meses. Se a tarefa estiver incorreta ou imprecisa, há uma grande chance no final do trabalho de ouvir do gerente de produto algo no espírito: “Está tudo errado. Isso não é bom. Eu queria outra coisa. Para impedir que isso aconteça, você precisa executar algumas etapas. O que há de especial nos produtos baseados em ML? Diferentemente da tarefa de desenvolver um site, a tarefa de aprendizado de máquina não pode ser formalizada apenas com texto. Além disso, como regra geral, parece para uma pessoa despreparada que tudo já é óbvio, e é simplesmente necessário fazer tudo "lindamente". Mas que pequenos detalhes existem, o gerente de tarefas pode nem saber, nunca pensou neles e não pensará até ver o produto final e dizer: "O que você fez?"
Os problemas
Vamos entender por exemplo quais problemas podem ser. Suponha que você tenha uma tarefa de reconhecimento de rosto. Você o recebe, se alegra e chama sua mãe: "Viva, uma tarefa interessante!" Mas é possível quebrar diretamente e começar a fazer? Se você fizer isso, no final, poderá esperar surpresas:
- Existem diferentes nacionalidades. Por exemplo, não havia asiáticos ou mais ninguém no conjunto de dados. Seu modelo, portanto, não sabe como reconhecê-los, e o produto precisa dele. Ou vice-versa, você gastou mais três meses em revisão, e o produto terá apenas caucasianos, e isso não foi necessário.
- Tem filhos Para pais sem filhos como eu, todos os filhos estão em um rosto. Estou absolutamente de acordo com o modelo, quando ela envia todos os filhos para um cluster - não está realmente claro como a maioria das crianças difere! ;) Mas as pessoas que têm filhos têm uma opinião completamente diferente. Geralmente eles também são seus líderes. Ou ainda há erros de reconhecimento engraçados quando a cabeça da criança é comparada com sucesso com o cotovelo ou a cabeça de um homem careca (história verdadeira).
- O que fazer com caracteres pintados geralmente não é claro. Preciso reconhecê-los ou não?
Tais aspectos da tarefa são muito importantes para serem identificados no início. Portanto, você precisa trabalhar e se comunicar com o gerente desde o início "nos dados". Explicações orais não podem ser aceitas. É necessário olhar para os dados. É desejável a partir da mesma distribuição na qual o modelo funcionará.
Idealmente, no processo desta discussão, será obtido algum conjunto de dados de teste no qual você pode finalmente executar o modelo e verificar se ele funciona como o gerente queria. É aconselhável fornecer parte do conjunto de dados de teste ao próprio gerente, para que você não tenha acesso a ele. Como você pode treinar facilmente neste conjunto de testes, você é um desenvolvedor de ML!
Definir uma tarefa no ML é um trabalho constante entre um gerente de produto e um especialista no ML. Mesmo que, a princípio, você defina bem a tarefa, à medida que o modelo se desenvolver, mais e mais novos problemas aparecerão, novos recursos que você aprenderá sobre seus dados. Tudo isso precisa ser discutido constantemente com o gerente. Bons gerentes sempre transmitem para suas equipes de ML que eles precisam assumir responsabilidade e ajudar o gerente a definir tarefas.
Porque O aprendizado de máquina é uma área relativamente nova. Os gerentes não têm (ou têm pouca) experiência no gerenciamento de tais tarefas. Com que frequência as pessoas aprendem a resolver novos problemas? Sobre os erros. Se você não deseja que seu projeto favorito se torne um erro, você precisa se envolver e assumir a responsabilidade, ensinar o gerente de produto a definir corretamente a tarefa, desenvolver listas de verificação e políticas; tudo isso ajuda muito. Cada vez que me retiro (ou alguém dos meus colegas me puxa) quando uma nova tarefa interessante chega, e corremos para fazê-la. Tudo o que acabei de lhe contar, eu mesmo esqueço. Portanto, é importante ter algum tipo de lista de verificação para verificar a si mesmo.
Dados
Os dados são super importantes no ML. Para aprendizado profundo, quanto mais dados você alimentar modelos, melhor. O gráfico azul mostra que geralmente os modelos de aprendizado profundo melhoram bastante quando os dados são adicionados.
E os algoritmos "antigos" (clássicos) de algum ponto não podem mais melhorar.
Geralmente nos conjuntos de dados ML estão sujos. Eles foram marcados por pessoas que sempre mentem. Os avaliadores geralmente não prestam atenção e cometem muitos erros. Usamos esta técnica: pegamos os dados que temos, treinamos o modelo neles e, com a ajuda desse modelo, limpamos os dados e repetimos o ciclo novamente.
Vamos dar uma olhada no exemplo do mesmo reconhecimento facial. Digamos que baixamos os avatares de usuários do VKontakte. Por exemplo, temos um perfil de usuário com 4 avatares. Detectamos rostos que estão nas 4 imagens e percorremos o modelo de reconhecimento de rostos. Portanto, temos casamentos de pessoas, com a ajuda das quais elas podem "colar" pessoas semelhantes em grupos (grupos). Em seguida, selecionamos o maior cluster, assumindo que os avatares do usuário contenham principalmente sua face. Dessa forma, podemos limpar todos os outros rostos (que são ruídos) dessa maneira. Depois disso, podemos repetir o ciclo novamente: nos dados limpos, treine o modelo e use-o para limpar os dados. Você pode repetir várias vezes.
Quase sempre para esse agrupamento, usamos os algoritmos CLink. Esse é um algoritmo de cluster hierárquico no qual é muito conveniente definir um valor limite para "colar" objetos semelhantes (é exatamente isso que é necessário para a limpeza). O CLink gera clusters esféricos. Isso é importante, pois geralmente aprendemos o espaço métrico dessas incorporações. O algoritmo tem uma complexidade de O (n
2 ), que, em princípio, é de aprox.
Às vezes, os dados são tão difíceis de obter ou marcar que não há mais nada a fazer assim que você começa a gerá-los. A abordagem generativa permite produzir uma enorme quantidade de dados. Mas para isso você precisa programar alguma coisa. O exemplo mais simples é OCR, reconhecimento de texto em imagens. A marcação do texto para esta tarefa é extremamente cara e barulhenta: você precisa destacar cada linha e cada palavra, assinar o texto e assim por diante. Os avaliadores (marcadores) ocuparão cem páginas de texto por um período extremamente longo e é necessário muito mais para o treinamento. Obviamente, você pode de alguma forma gerar o texto e, de alguma forma, "movê-lo" para que o modelo aprenda com ele.
Descobrimos por nós mesmos que o melhor e mais conveniente kit de ferramentas para essa tarefa é uma combinação de PIL, OpenCV e Numpy. Eles têm tudo para trabalhar com texto. Você pode complicar a imagem com o texto de qualquer maneira, para que a rede não seja treinada novamente para obter exemplos simples.

Às vezes precisamos de alguns objetos do mundo real. Por exemplo, mercadorias nas prateleiras das lojas. Uma dessas imagens é gerada automaticamente. Você acha que esquerda ou direita?

De fato, ambos são gerados. Se você não olhar para os pequenos detalhes, não perceberá diferenças da realidade. Fazemos isso usando o Blender (analógico do 3dmax).
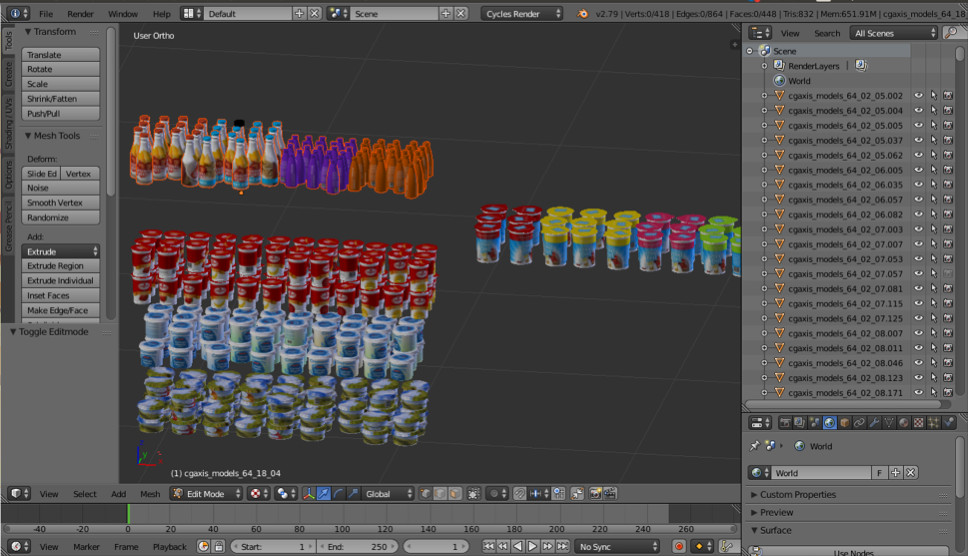
A principal vantagem importante é que é de código aberto. Possui uma excelente API Python, que permite colocar diretamente objetos no código, configurar e randomizar o processo e, finalmente, obter um conjunto de dados diversificado.
Para renderização, o traçado de raios é usado. Este é um procedimento bastante caro, mas produz um resultado com excelente qualidade. A questão mais importante: onde conseguir modelos para objetos? Como regra, eles devem ser comprados. Mas se você é um estudante pobre e quer experimentar algo, sempre há torrents. É claro que, para a produção, você precisa comprar ou pedir modelos renderizados de alguém.
Isso é tudo sobre os dados. Vamos para o aprendizado.
Aprendizado métrico
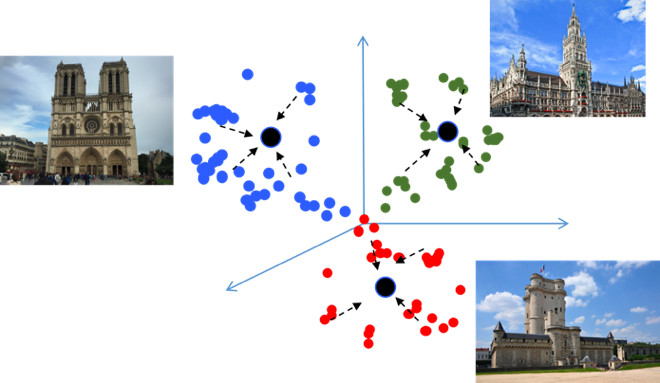
O objetivo do aprendizado do Metric é treinar a rede para converter objetos semelhantes em regiões semelhantes no espaço métrico de incorporação. Darei novamente um exemplo com as vistas, o que é incomum, pois é essencialmente uma tarefa de classificação, mas para dezenas de milhares de classes. Parece, por que aqui a aprendizagem métrica, que, por regra, é apropriada em tarefas como reconhecimento facial? Vamos tentar descobrir.
Se você usar perdas padrão ao treinar um problema de classificação, por exemplo, Softmax, as classes no espaço métrico estarão bem separadas, mas no espaço de incorporação, pontos de classes diferentes poderão estar próximos um do outro ...

Isso cria possíveis erros durante a generalização, como uma pequena diferença nos dados de origem pode alterar o resultado da classificação. Gostaríamos realmente que os pontos fossem mais compactos. Para isso, são utilizadas várias técnicas de aprendizado métrico. Por exemplo, perda de centro, cuja ideia é extremamente simples: simplesmente juntamos pontos ao centro de aprendizagem de cada classe, que eventualmente se torna mais compacto.
A perda de centro é programada literalmente em 10 linhas em Python, funciona muito rapidamente e, o mais importante, melhora a qualidade da classificação, porque compacidade leva a uma melhor capacidade de generalização.
Softmax angular
Tentamos muitos métodos diferentes de aprendizado de métricas e chegamos à conclusão de que o Angular Softmax produz os melhores resultados. Entre a comunidade de pesquisa, ele também é considerado o estado da arte.
Vejamos um exemplo de reconhecimento de rosto. Aqui temos duas pessoas. Se você usar o Softmax padrão, um plano de divisão será desenhado entre eles - com base em dois vetores de peso. Se fizermos a norma de incorporação 1, os pontos estarão no círculo, ou seja, na esfera no caso n-dimensional (figura à direita).
Então você pode ver que o ângulo entre eles já é responsável pela separação de classes e pode ser otimizado. Mas isso não basta. Se continuarmos a otimizar o ângulo, a tarefa não mudará de fato, porque nós simplesmente a reformulamos em outros termos. Nosso objetivo, lembro-me, é tornar os clusters mais compactos.
É necessário, de alguma maneira, exigir um ângulo maior entre as classes - para complicar a tarefa da rede neural. Por exemplo, de tal maneira que ela acha que o ângulo entre os pontos de uma classe é maior do que na realidade, de modo que ela tenta comprimi-los cada vez mais. Isto é conseguido através da introdução do parâmetro m, que controla a diferença nos cossenos dos ângulos.
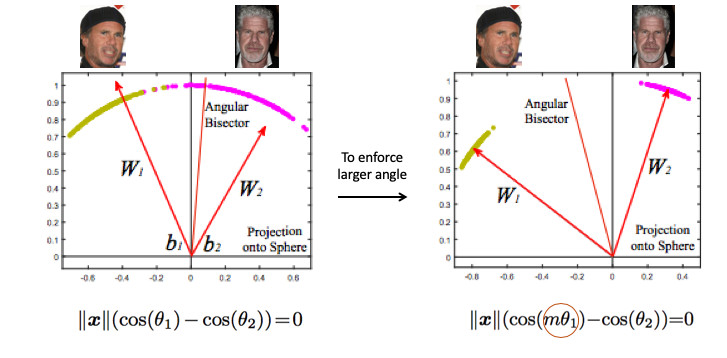
Existem várias opções para o Angular Softmax. Todos eles brincam com o fato de multiplicar por m esse ângulo ou somar, ou multiplicar e somar. Estado-da-arte - ArcFace.
De fato, é fácil integrar este na classificação de pipeline.
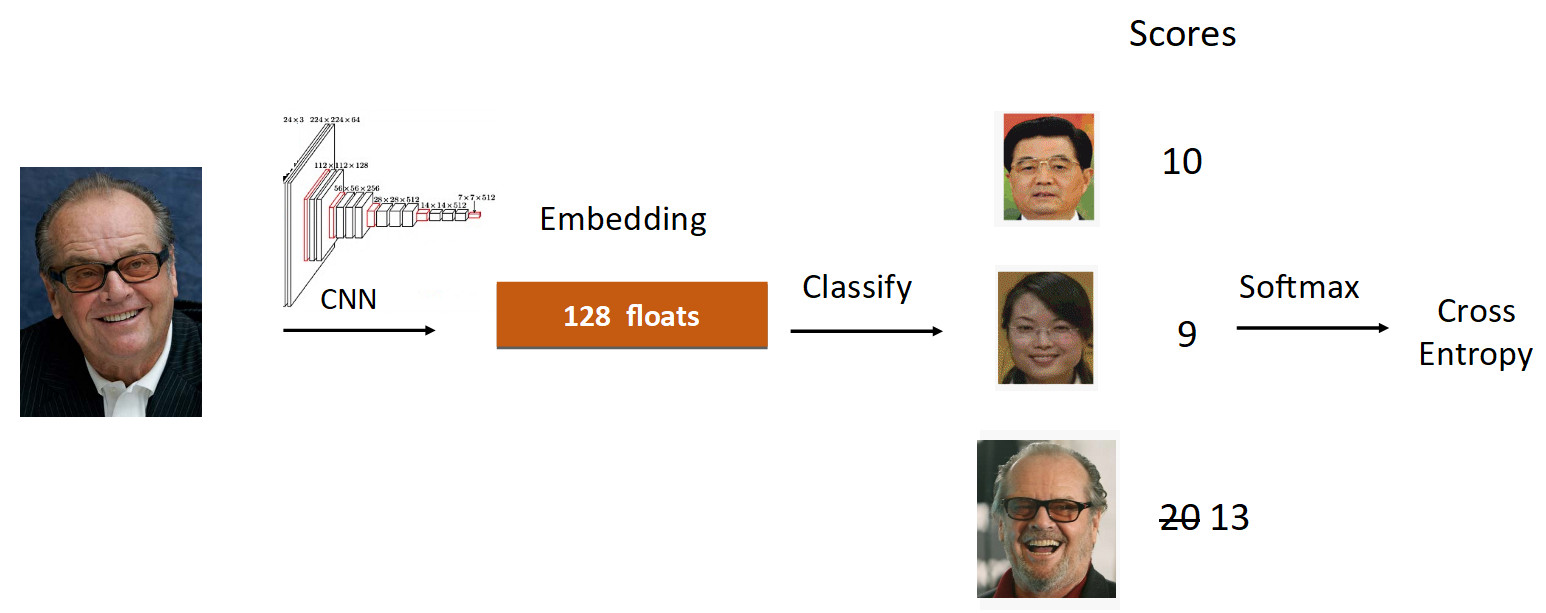
Vejamos o exemplo de Jack Nicholson. Corremos a foto dele pela grade no processo de aprendizado. Obtemos incorporação, percorremos a camada linear para classificação e obtemos pontuações na saída, que refletem o grau de pertencimento à classe. Nesse caso, a fotografia de Nicholson tem uma velocidade de 20, a maior. Além disso, de acordo com a fórmula do ArcFace, reduzimos a velocidade de 20 para 13 (feita apenas para a classe groundtruth), complicando a tarefa da rede neural. Em seguida, fazemos tudo como de costume: Softmax + Cross Entropy.
No total, a camada linear usual é substituída pela camada ArcFace, que é escrita não em 10, mas em 20 linhas, mas oferece excelentes resultados e um mínimo de sobrecarga para implementação. Como resultado, o ArcFace é melhor que a maioria dos outros métodos para a maioria das tarefas. Ele se integra perfeitamente às tarefas de classificação e melhora a qualidade.
Transferência de aprendizado
A segunda coisa que eu queria falar é sobre o aprendizado de transferência - usando uma rede pré-treinada em uma tarefa semelhante para reciclagem de uma nova tarefa. Assim, o conhecimento é transferido de uma tarefa para outra.
Fizemos nossa busca por imagens. A essência da tarefa é produzir semanticamente semelhantes a partir do banco de dados na imagem (consulta).

É lógico pegar uma rede que já estudou um grande número de imagens - nos conjuntos de dados ImageNet ou OpenImages, nos quais existem milhões de fotos, e treinar nossos dados.
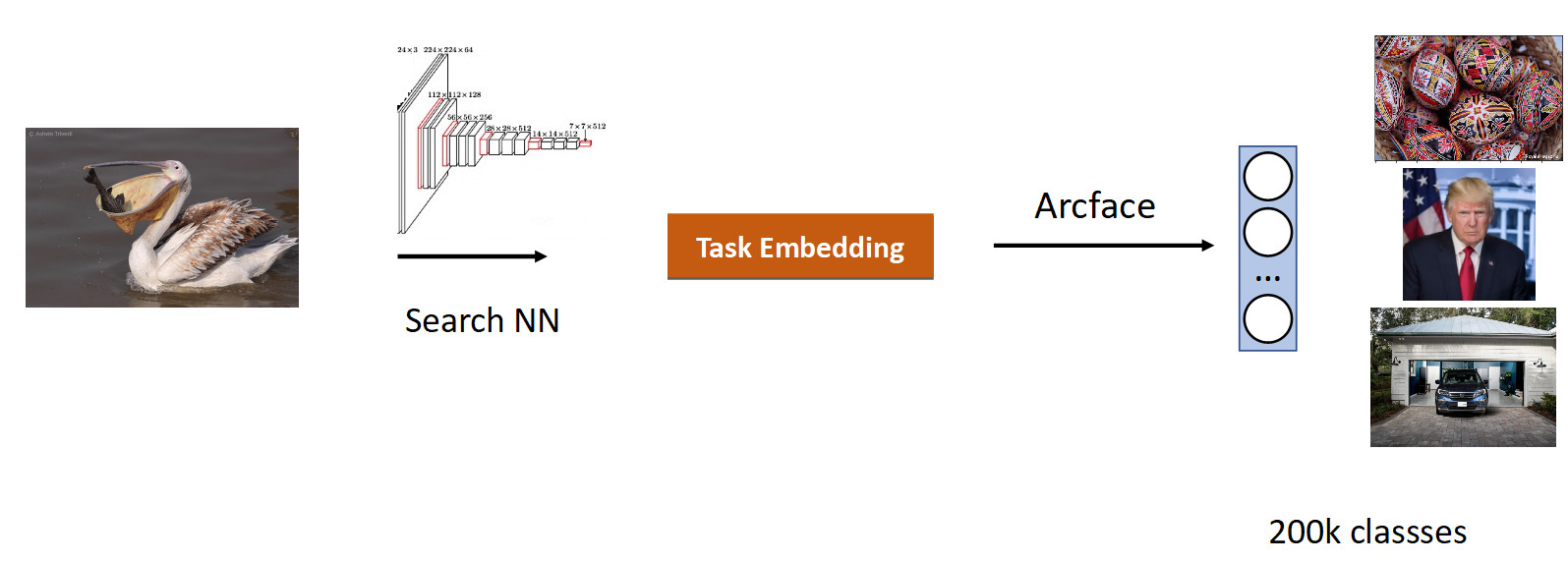
Coletamos dados para esta tarefa com base na semelhança de imagens e cliques do usuário e obtivemos 200 mil aulas. Após o treinamento com o ArFace, obtivemos o seguinte resultado.

Na foto acima, vemos que, para o pelicano solicitado, os pardais também entraram na questão. I.e. a incorporação acabou semanticamente verdadeira - é um pássaro, mas racialmente infiel. O mais irritante é que o modelo original com o qual treinamos novamente conhecia essas classes e as distinguia perfeitamente. Aqui vemos o efeito comum a todas as redes neurais, chamado esquecimento catastrófico. Ou seja, durante a reciclagem, a rede esquece a tarefa anterior, às vezes até completamente. É exatamente isso que impede nesta tarefa de obter melhor qualidade.
Destilação de conhecimento
Isso é tratado usando uma técnica chamada destilação de conhecimento, quando uma rede ensina a outra e “transfere seu conhecimento para ela”. Como está (pipeline de treinamento completo na figura abaixo).
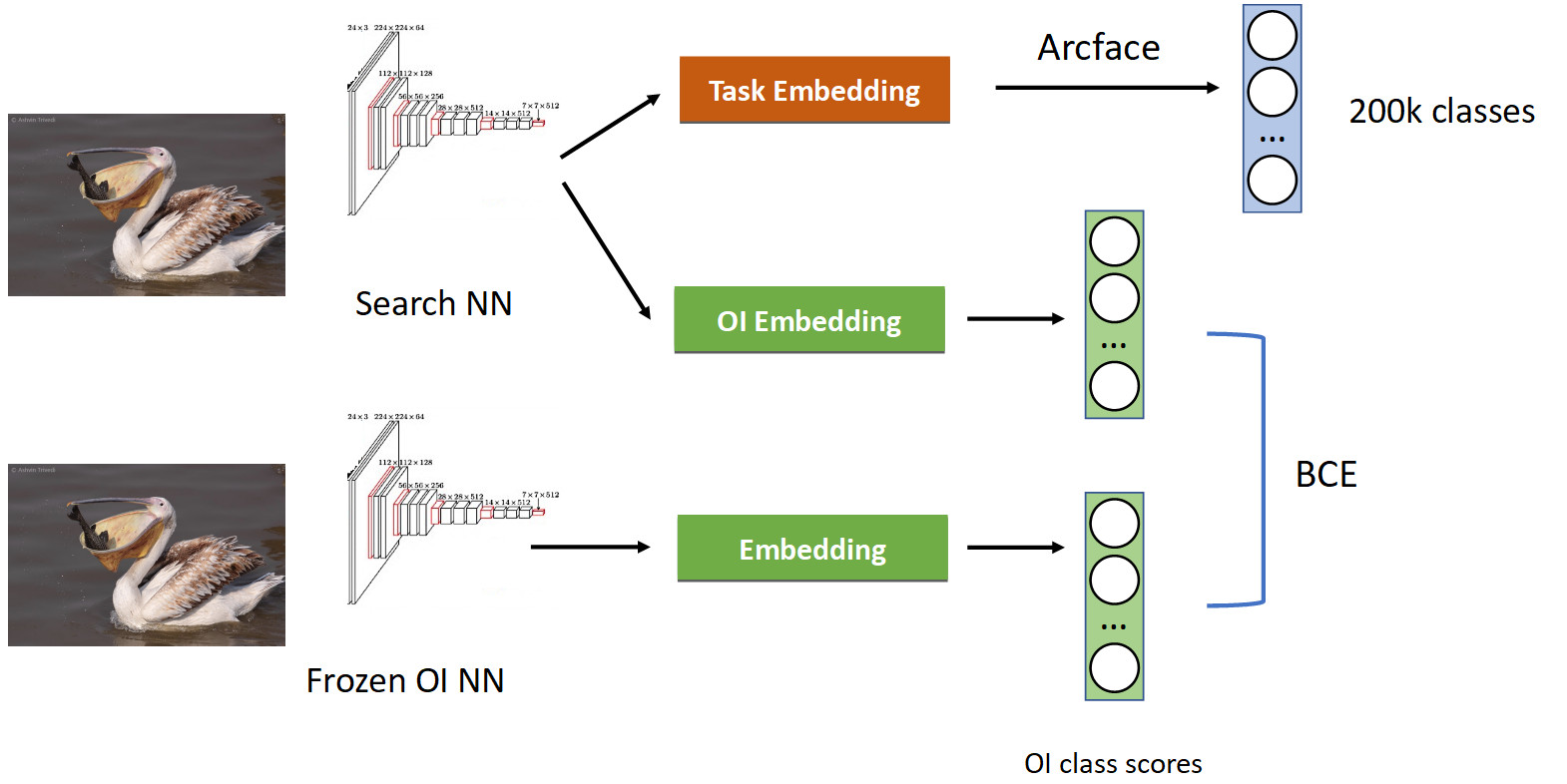
Já temos um pipeline de classificação familiar com o Arcface. Lembre-se de que temos uma rede com a qual somos fingidos. Congelamos e simplesmente calculamos seus embeddings em todas as fotos em que aprendemos nossa rede e obtemos as classes das classes OpenImages: pelicanos, pardais, carros, pessoas, etc. OpenImages, que produz pontuações semelhantes. Com o BCE, fazemos com que a rede produza uma distribuição semelhante dessas pontuações. Assim, por um lado, estamos aprendendo uma nova tarefa (na parte superior da imagem), mas também fazemos com que a rede não esqueça suas raízes (na parte inferior) - lembre-se das aulas que costumava conhecer. Se você equilibrar corretamente os gradientes em uma proporção condicional de 50/50, isso deixará todos os pelicanos no topo e jogará fora todos os pardais de lá.

Quando aplicamos isso, obtivemos uma porcentagem completa no mAP. Isso é bastante.
Portanto, se sua rede esquecer a tarefa anterior, trate-a usando a destilação de conhecimento - isso funciona bem.
Cabeças extras
A ideia básica é muito simples. Novamente no exemplo de reconhecimento de rosto. Temos um conjunto de pessoas no conjunto de dados. Mas também frequentemente nos conjuntos de dados existem outras características da face. Por exemplo, quantos anos, que cor dos olhos etc. Tudo isso pode ser adicionado como mais uma adição. sinal: ensine chefes individuais a prever esses dados. Assim, nossa rede recebe um sinal mais diversificado e, como resultado, pode ser melhor aprender a tarefa principal.
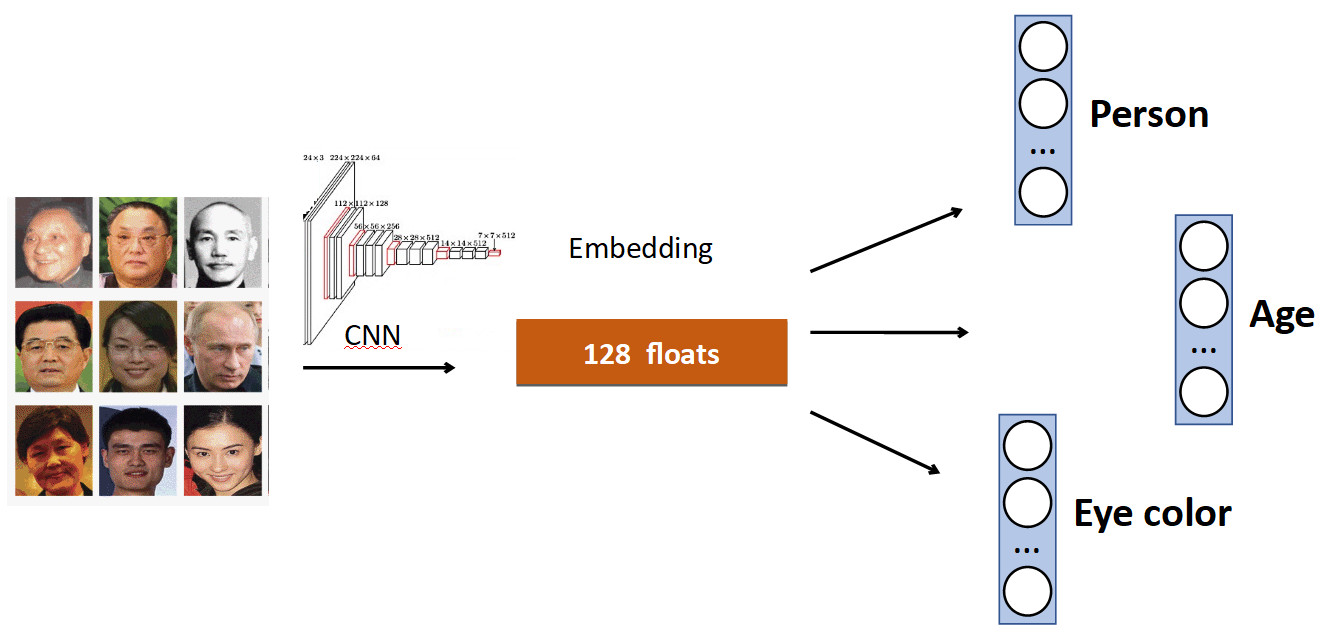
Outro exemplo: detecção de fila.

Muitas vezes, em conjuntos de dados com pessoas, além do corpo, há uma marcação separada da posição da cabeça, que, obviamente, pode ser usada. Portanto, adicionamos à rede a previsão da caixa delimitadora da pessoa e a previsão da caixa delimitadora da cabeça e obtivemos um aumento de 0,5% na precisão (mAP), o que é decente. E o mais importante - gratuito em termos de desempenho, porque na produção, a cabeça extra é "desconectada".

OCR
Um caso mais complexo e interessante é o OCR, já mencionado acima. O pipeline padrão é assim.
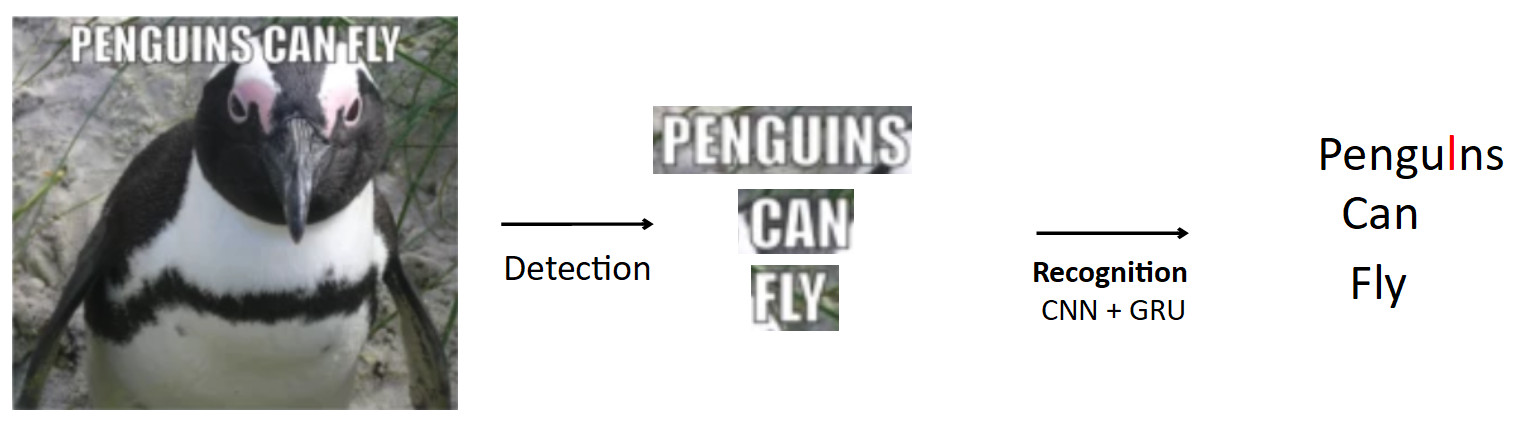
Que haja um pôster com um pinguim, o texto está escrito nele. Usando o modelo de detecção, destacamos este texto. Além disso, alimentamos esse texto com a entrada do modelo de reconhecimento, que produz o texto reconhecido. Digamos que nossa rede esteja errada e, em vez de "i", a palavra pinguins prediz "l". Na verdade, esse é um problema muito comum no OCR quando a rede confunde caracteres semelhantes. A questão é como evitar isso - traduzir pengulns em pinguins? Quando uma pessoa olha para este exemplo, é óbvio para ele que isso é um erro, porque ele tem conhecimento da estrutura da linguagem. Portanto, o conhecimento sobre a distribuição de caracteres e palavras no idioma deve ser incorporado no modelo.
Usamos uma coisa chamada BPE (codificação de pares de bytes) para isso. Esse é um algoritmo de compactação que foi geralmente inventado nos anos 90, não para aprendizado de máquina, mas agora é muito popular e é usado no aprendizado profundo. O significado do algoritmo é que as subsequências frequentes no texto são substituídas por novos caracteres. Suponha que tenhamos a string "aaabdaaabac" e desejemos obter um BPE para ela. Concluímos que o par de caracteres “aa” é o mais frequente em nossa palavra. Nós o substituímos por um novo caractere "Z", obtemos a string "ZabdZabac". Repetimos a iteração: vemos que ab é a subsequência mais frequente, substitua-a por "Y", obtemos a string "ZYdZYac". Agora “ZY” é a subsequência mais frequente, substituímos por “X”, obtemos “XdXac”. Assim, codificamos algumas dependências estatísticas na distribuição do texto. Se encontrarmos uma palavra na qual existem subsequências muito "estranhas" (raras para o corpo docente), então essa palavra é suspeita.
aaabdaaabac
ZabdZabac Z=aa
ZY d ZY ac Y=ab
X d X ac X=ZYComo tudo se encaixa no reconhecimento.
Destacamos a palavra “pinguim”, que foi enviada à rede neural convolucional, que produziu incorporação espacial (um vetor de comprimento fixo, por exemplo 512). Este vetor codifica informações de símbolos espaciais. Em seguida, usamos uma rede de recorrência (UPD: na verdade, já usamos o modelo Transformer), ela fornece alguns estados ocultos (barras verdes), em cada um dos quais a distribuição de probabilidade é costurada - que, de acordo com o modelo, o símbolo é representado em uma posição específica. Em seguida, usando CTC-Loss, desenrolamos esses estados e obtemos nossa previsão para a palavra inteira, mas com um erro: L no lugar de i.
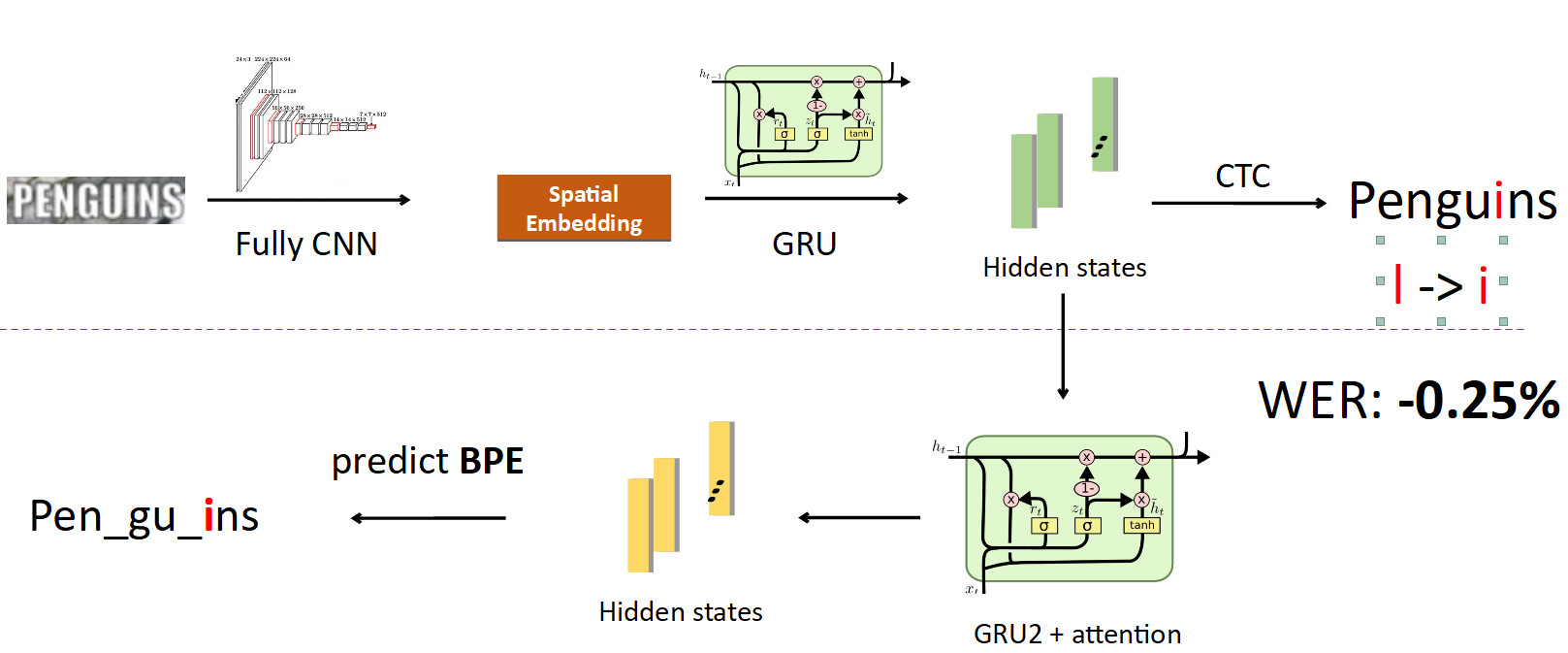
Agora integrando o BPE no pipeline. Queremos deixar de prever caracteres individuais em palavras, portanto, partimos dos estados em que as informações sobre os caracteres são costuradas e estabelecemos outra rede recursiva sobre eles; ela prevê BPE. No caso do erro descrito acima, são obtidas 3 BPEs: "peng", "ul", "ns". Isso difere significativamente da sequência correta para a palavra pinguins, ou seja, pen, gu, ins. Se você observar isso do ponto de vista do treinamento do modelo, em uma previsão de caracter por palavra, a rede cometeu um erro em apenas uma letra em oito (erro de 12,5%); e em termos de BPE, ela estava 100% enganada ao prever todos os três BPEs incorretamente. Esse é um sinal muito maior para a rede de que algo deu errado e você precisa corrigir seu comportamento. Quando implementamos isso, conseguimos corrigir erros desse tipo e reduzimos a taxa de erros do Word em 0,25% - isso é muito. Essa cabeça extra é removida quando inferência, cumprindo seu papel no treinamento.
FP16
A última coisa que eu queria dizer sobre o treinamento foi o FP16. Aconteceu historicamente que as redes foram treinadas na GPU em precisão da unidade, ou seja, FP32. Mas isso é redundante, especialmente para inferência, onde a meia precisão (FP16) é suficiente sem perda de qualidade. No entanto, este não é o caso do treinamento.
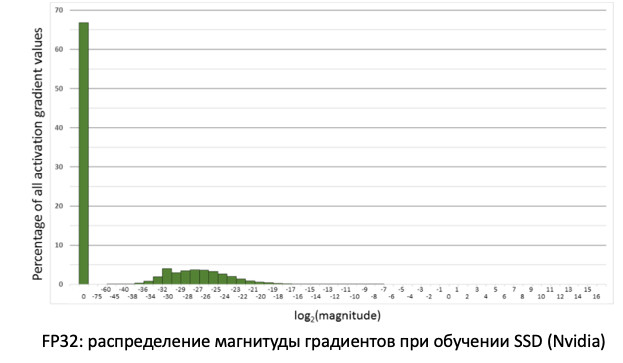
Se observarmos a distribuição dos gradientes, informações que atualizam nossos pesos ao propagar erros, veremos que existe um pico enorme em zero. E, em geral, muitos valores estão próximos de zero. Se apenas transferirmos todos os pesos para o FP16, verificamos que cortamos o lado esquerdo na região de zero (a partir da linha vermelha).
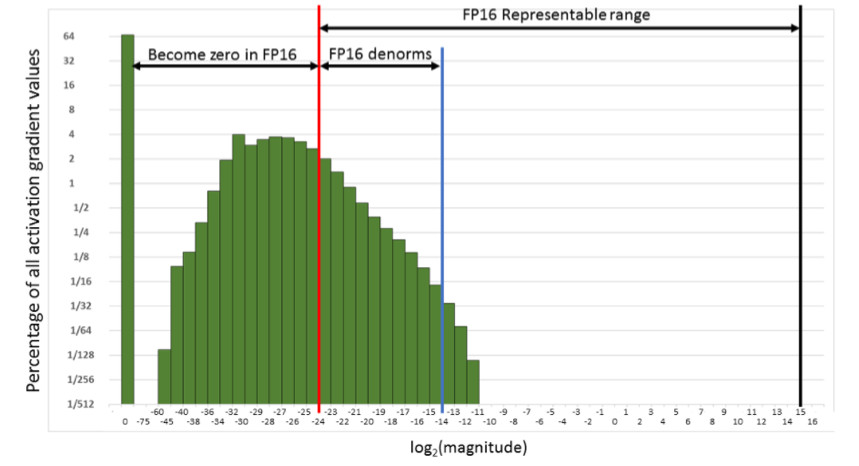
Ou seja, redefiniremos um número muito grande de gradientes. E a parte certa, na faixa de trabalho do FP16, não é usada. Como resultado, se você treinar a testa no FP16, é provável que o processo se disperse (o gráfico cinza na figura abaixo).
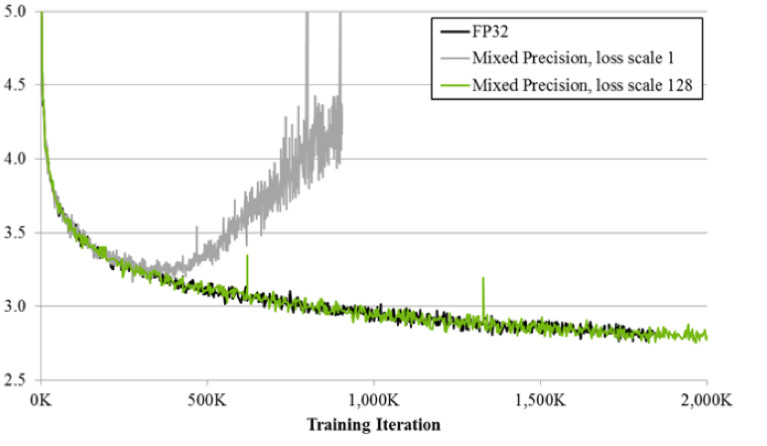
Se você treina usando a técnica de precisão mista, o resultado é quase idêntico ao FP32. A precisão mista implementa dois truques.
Primeiro: simplesmente multiplicamos a perda por uma constante, por exemplo, 128. Assim, escalamos todos os gradientes e movemos seus valores de zero para a faixa de trabalho do FP16. Segundo: armazenamos a versão principal da balança FP32, que é usada apenas para atualização, e nas operações de cálculo de redes de passagem para frente e para trás, apenas a FP16 é usada.
Usamos Pytorch para treinar redes. A NVIDIA fez uma montagem especial com o chamado APEX, que implementa a lógica descrita acima. Ele tem dois modos. O primeiro é a precisão mista automática. Veja o código abaixo para ver como é fácil usar.

Literalmente, duas linhas são adicionadas ao código de treinamento que envolve a perda e o procedimento de inicialização do modelo e otimizadores. O que o AMP faz? Ele conserta todas as funções. O que exatamente está acontecendo? Por exemplo, ele vê que existe uma função de convolução e ela recebe um lucro do FP16. Em seguida, ele o substitui pelo seu, que primeiro é lançado no FP16 e, em seguida, executa uma operação de convolução. Assim, o AMP executa todas as funções que podem ser usadas na rede. Para alguns, não. não haverá aceleração. Para a maioria das tarefas, esse método é adequado.
Segunda opção: otimizador FP16 para ventiladores de controle completo. Adequado se você deseja especificar quais camadas estarão no FP16 e quais no FP32. Mas tem uma série de limitações e dificuldades. Não começa com meio chute (pelo menos tivemos que suar para começar). O FP_optimizer também funciona apenas com o Adam, e mesmo assim com o Adam, que está no APEX (sim, eles têm o seu próprio Adam no repositório, que possui uma interface completamente diferente da do Paytorch).
Fizemos uma comparação ao aprender nos cartões Tesla T4.
Na Inference, temos a aceleração esperada duas vezes. Nos treinamentos, vemos que a estrutura do Apex fornece 20% de aceleração com o FP16 relativamente simples. Como resultado, obtemos um treino duas vezes mais rápido e consome 2 vezes menos memória, e a qualidade do treinamento não sofre de forma alguma. Freebie.
Inferência
Porque Como usamos o PyTorch, a questão é urgentemente como implantá-lo na produção.
Existem 3 opções de como fazê-lo (e todas elas que usamos).
- ONNX -> Caffe2
- ONNX -> TensorRT
- E, mais recentemente, Pytorch C ++
Vamos olhar para cada um deles.
ONNX e Caffe2
O ONNX apareceu há 1,5 anos. Essa é uma estrutura especial para converter modelos entre diferentes estruturas. E o Caffe2 é uma estrutura adjacente ao Pytorch, os quais estão sendo desenvolvidos no Facebook. Historicamente, Pytorch está se desenvolvendo muito mais rápido que Caffe2. O Caffe2 fica atrás do Pytorch em recursos, portanto, nem todo modelo que você treinou no Pytorch pode ser convertido no Caffe2. Muitas vezes, você precisa reaprender com outras camadas. Por exemplo, no Caffe2 não existe operação padrão como upsampling com a interpolação de vizinhos mais próxima. Como resultado, chegamos à conclusão de que, para cada modelo, temos uma imagem especial do docker, na qual fixamos as versões da estrutura com pregos para evitar discrepâncias durante suas futuras atualizações, de modo que, quando uma das versões é atualizada novamente, não perdemos tempo com sua compatibilidade. . Tudo isso não é muito conveniente e prolonga o processo de implantação.
Tensor rt
Há também o Tensor RT, uma estrutura da NVIDIA que otimiza a arquitetura de rede para acelerar a inferência. Fizemos nossas medições (no mapa Tesla T4).
Se você olhar para os gráficos, poderá ver que a transição do FP32 para o FP16 fornece aceleração 2x no Pytorch, e o TensorRT ao mesmo tempo fornece 4x. Uma diferença muito significativa. Nós o testamos no Tesla T4, que possui núcleos tensoriais que utilizam muito bem os cálculos de FP16, o que é obviamente excelente no TensorRT. Portanto, se houver um modelo altamente carregado em execução em dezenas de placas gráficas, todos os motivadores serão testados no Tensor RT.
No entanto, ao trabalhar com o TensorRT, há ainda mais dor do que no Caffe2: as camadas são ainda menos suportadas. Infelizmente, toda vez que usamos essa estrutura, temos que sofrer um pouco para converter o modelo. Mas para modelos muito carregados, você precisa fazer isso. ;) Observo que em mapas sem núcleos tensores, esse aumento maciço não é observado.
Pytorch C ++
E o último é o Pytorch C ++. Seis meses atrás, os desenvolvedores do Pytorch perceberam a dor das pessoas que usam sua estrutura e lançaram o
tutorial do
TorchScript , que permite rastrear e serializar o modelo Python em um gráfico estático sem gestos desnecessários (JIT). Foi lançado em dezembro de 2018, imediatamente começamos a usá-lo, capturamos imediatamente alguns bugs de desempenho e esperamos vários meses pela fixação de
Chintala . Agora, porém, é uma tecnologia bastante estável e a estamos usando ativamente em todos os modelos. A única coisa é a falta de documentação, que está sendo ativamente complementada. Claro, você sempre pode olhar para arquivos * .h, mas para pessoas que não conhecem as vantagens, é difícil. Mas existe um trabalho realmente idêntico ao Python. No C ++, o código j é executado em um interpretador Python mínimo, o que praticamente garante a identidade do C ++ com o Python.
Conclusões
- A declaração do problema é super importante. Você deve se comunicar com os gerentes de produto sobre os dados. Antes de começar a executar a tarefa, é aconselhável ter um conjunto de testes pronto no qual medimos as métricas finais antes do estágio de implementação.
- Nós mesmos limpamos os dados com a ajuda do cluster. Obtemos o modelo nos dados de origem, limpamos os dados usando o cluster CLink e repetimos o processo até a convergência.
- Aprendizado métrico: até a classificação ajuda. Estado da arte - ArcFace, fácil de integrar ao processo de aprendizado.
- Se você transferir o aprendizado de uma rede pré-treinada, para que a rede não esqueça a tarefa antiga, use a destilação de conhecimento.
- Também é útil usar várias cabeças de rede que utilizarão sinais diferentes dos dados para melhorar a tarefa principal.
- Para o FP16, você precisa usar os assemblies Apex da NVIDIA, Pytorch.
- E, por inferência, é conveniente usar o Pytorch C ++.